platform for preparing tabular data for machine learning

Project description
Automunge

Table of Contents
- Default Transformations
- Library of Transformations
- Custom Transformation Functions
- Custom ML Infill Functions
- Final Model Training
Introduction
Automunge is an open source python library that has formalized and automated the data preparations for tabular learning in between the workflow boundaries of received “tidy data” (one column per feature and one row per sample) and returned dataframes suitable for the direct application of machine learning. Under automation numeric features are normalized, categoric features are binarized, and missing data is imputed. Data transformations are fit to properties of a training set for a consistent basis on any partitioned “validation data” or additional “test data”. When preparing training data, a compact python dictionary is returned recording the steps and parameters of transformation, which then may serve as a key for preparing additional data on a consistent basis.
In other words, put simply:
- automunge(.) prepares tabular data for machine learning with encodings, missing data infill, and may channel stochastic perturbations into features
- postmunge(.) consistently prepares additional data very efficiently
We make machine learning easy.
In addition to data preparations under automation, Automunge may also serve as a platform for engineering data pipelines. An extensive internal library of univariate transformations includes options like numeric translations, bin aggregations, date-time encodings, noise injections, categoric encodings, and even “parsed categoric encodings” in which categoric strings are vectorized based on shared grammatical structure between entries. Feature transformations may be mixed and matched in sets that include generations and branches of derivations by use of our “family tree primitives”. Feature transformations fit to properties of a training set may be custom defined from a very simple template for incorporation into a pipeline. Dimensionality reductions may be applied, such as by principal component analysis, feature importance rankings, or categoric consolidations. Missing data receives “ML infill”, in which models are trained for a feature to impute missing entries based on properties of the surrounding features. Random sampling may be channeled into features as stochastic perturbations.
Be sure to check out our Tutorial Notebooks. If you are looking for something to cite, our paper Tabular Engineering with Automunge was accepted to the Data-Centric AI workshop at NeurIPS 2021.
Install, Initialize, and Basics
Automunge is now available for pip install:
pip install Automunge
Or to upgrade:
pip install Automunge --upgrade
Once installed, run this in a local session to initialize:
from Automunge import *
am = AutoMunge()
Where e.g. for train set processing with default parameters run:
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train)
Importantly, if the df_train set passed to automunge(.) includes a column intended for use as labels, it should be designated with the labels_column parameter.
Or for subsequent consistent processing of train or test data, using the dictionary returned from original application of automunge(.), run:
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test)
I find it helpful to pass these functions with the full range of arguments included for reference, thus a user may simply copy and past this form.
#for automunge(.) function on original train and test data
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train, df_test = False,
labels_column = False, trainID_column = False, testID_column = False,
valpercent=0.0, floatprecision = 32, cat_type = False, shuffletrain = True, noise_augment = 0,
dupl_rows = False, TrainLabelFreqLevel = False, powertransform = False, binstransform = False,
MLinfill = True, infilliterate=1, randomseed = False, eval_ratio = .5,
numbercategoryheuristic = 255, pandasoutput = 'dataframe', NArw_marker = True,
featureselection = False, featurethreshold = 0., inplace = False, orig_headers = False,
Binary = False, PCAn_components = False, PCAexcl = [], excl_suffix = False,
ML_cmnd = {'autoML_type':'randomforest',
'MLinfill_cmnd':{'RandomForestClassifier':{}, 'RandomForestRegressor':{}},
'PCA_type':'default',
'PCA_cmnd':{}},
assigncat = {'1010':[], 'onht':[], 'ordl':[], 'bnry':[], 'hash':[], 'hsh2':[],
'DP10':[], 'DPoh':[], 'DPod':[], 'DPbn':[], 'DPhs':[], 'DPh2':[],
'nmbr':[], 'mnmx':[], 'retn':[], 'DPnb':[], 'DPmm':[], 'DPrt':[],
'bins':[], 'pwr2':[], 'bnep':[], 'bsor':[], 'por2':[], 'bneo':[],
'ntgr':[], 'srch':[], 'or19':[], 'tlbn':[], 'excl':[], 'exc2':[]},
assignparam = {'global_assignparam' : {'(parameter)': 42},
'default_assignparam' : {'(category)' : {'(parameter)' : 42}},
'(category)' : {'(column)' : {'(parameter)' : 42}}},
assigninfill = {'stdrdinfill':[], 'MLinfill':[], 'zeroinfill':[], 'oneinfill':[],
'adjinfill':[], 'meaninfill':[], 'medianinfill':[], 'negzeroinfill':[],
'interpinfill':[], 'modeinfill':[], 'lcinfill':[], 'naninfill':[]},
assignnan = {'categories':{}, 'columns':{}, 'global':[]},
transformdict = {}, processdict = {}, evalcat = False, ppd_append = False,
entropy_seeds = False, random_generator = False, sampling_dict = False,
privacy_encode = False, encrypt_key = False, printstatus = 'summary', logger = {})
Please remember to save the automunge(.) returned object postprocess_dict such as using pickle library, which can then be later passed to the postmunge(.) function to consistently prepare subsequently available data.
#Sample pickle code:
#sample code to download postprocess_dict dictionary returned from automunge(.)
import pickle
with open('filename.pickle', 'wb') as handle:
pickle.dump(postprocess_dict, handle, protocol=pickle.HIGHEST_PROTOCOL)
#to upload for later use in postmunge(.) in another notebook
import pickle
with open('filename.pickle', 'rb') as handle:
postprocess_dict = pickle.load(handle)
#Please note that if you included externally initialized functions in an automunge(.) call
#like for custom_train transformation functions or customML inference functions
#they will need to be reinitialized prior to uploading the postprocess_dict with pickle.
We can then apply the postprocess_dict saved from a prior application of automunge for consistent processing of additional data.
#for postmunge(.) function on additional available train or test data
#using the postprocess_dict object returned from original automunge(.) application
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test,
testID_column = False,
pandasoutput = 'dataframe', printstatus = 'summary',
dupl_rows = False, TrainLabelFreqLevel = False,
featureeval = False, traindata = False, noise_augment = 0,
driftreport = False, inversion = False,
returnedsets = True, shuffletrain = False,
entropy_seeds = False, random_generator = False, sampling_dict = False,
randomseed = False, encrypt_key = False, logger = {})
The functions accept pandas dataframe or numpy array input and return encoded dataframes with consistent order of columns between train and test data. (For input numpy arrays any label column should be positioned as final column in set.) The functions return data with categoric features translated to numerical encodings and normalized numeric such as to make them suitable for direct application to a machine learning model in the framework of a user's choice, including sets for the various activities of a generic machine learning project such as training (train), validation (val), and inference (test). The automunge(.) function also returns a python dictionary (the "postprocess_dict") that can be used as a key to prepare additional data with postmunge(.).
When left to automation, automunge(.) evaluates properties of a feature to select the type of encoding, for example whether a column is numeric, categoric, high cardinality, binary, date time, etc. Alternately, a user can assign specific processing functions to distinct columns (via assigncat parameter) - which may be pulled from the internal Library of Transformations or alternately custom defined.
The feature engineering transformations are recorded with suffixes appended to the column header title in the returned sets, for one example the application of z-score normalization returns a column with header origname + '_nmbr'. As another example, for binary encoded sets the set of columns are returned with header origname + '_1010_#' where # is integer to distinguish columns in same set. In most cases, the suffix appenders are derived from the transformation category identifier (which is by convention a 4 letter string).
The default transforms applied under automation are detailed below in section Default Transforms. Missing data receives ML infill (defaulting to random forest models) and missing marker aggregation. Other features of the library are detailed in the tutorial notebooks and with their associated parameters below.
Other options available in the library include feature importance (via featureselection parameter), oversampling (via the TrainLabelFreqLevel parameter), dimensionality reductions (via PCAn_components, Binary, or featurethreshold parameters), and stochastic perturbations (by the DP family of transformations detailed in the library of transformations and tutorials). Further detail provided with parameter writeups below.
Note that there is a potential source of error if the returned column header title strings, which will include suffix appenders based on transformations applied, match any of the original column header titles passed to automunge. This is an edge case not expected to occur in common practice and will return error message at conclusion of printouts and a logged validation result as postprocess_dict['miscparameters_results']['suffixoverlap_aggregated_result']. This channel can be eliminated by omitting the underscore character in received column headers.
Please note that we consider the postmunge(.) latency a key performance metric since it is the function that may be called under repetition in production. The automunge(.) latency can be improved by manual assignment of root categories with the assigncat parameter or by deactivating ML infill with the MLinfill parameter.
automunge(.)
The application of the automunge and postmunge functions requires the assignment of the function to a series of named sets. We suggest using consistent naming convention as follows:
#first you'll need to initialize
from Automunge import *
am = AutoMunge()
#then to run with default parameters
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train)
The full set of parameters available to be passed are given here, with explanations provided below:
#first you'll need to initialize
from Automunge import *
am = AutoMunge()
#then if you want you can copy paste following to view all of parameter options
#where df_train is the target training data set to be prepared
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train, df_test = False,
labels_column = False, trainID_column = False, testID_column = False,
valpercent=0.0, floatprecision = 32, cat_type = False, shuffletrain = True, noise_augment = 0,
dupl_rows = False, TrainLabelFreqLevel = False, powertransform = False, binstransform = False,
MLinfill = True, infilliterate=1, randomseed = False, eval_ratio = .5,
numbercategoryheuristic = 255, pandasoutput = 'dataframe', NArw_marker = True,
featureselection = False, featurethreshold = 0., inplace = False, orig_headers = False,
Binary = False, PCAn_components = False, PCAexcl = [], excl_suffix = False,
ML_cmnd = {'autoML_type':'randomforest',
'MLinfill_cmnd':{'RandomForestClassifier':{}, 'RandomForestRegressor':{}},
'PCA_type':'default',
'PCA_cmnd':{}},
assigncat = {'1010':[], 'onht':[], 'ordl':[], 'bnry':[], 'hash':[], 'hsh2':[],
'DP10':[], 'DPoh':[], 'DPod':[], 'DPbn':[], 'DPhs':[], 'DPh2':[],
'nmbr':[], 'mnmx':[], 'retn':[], 'DPnb':[], 'DPmm':[], 'DPrt':[],
'bins':[], 'pwr2':[], 'bnep':[], 'bsor':[], 'por2':[], 'bneo':[],
'ntgr':[], 'srch':[], 'or19':[], 'tlbn':[], 'excl':[], 'exc2':[]},
assignparam = {'global_assignparam' : {'(parameter)': 42},
'default_assignparam' : {'(category)' : {'(parameter)' : 42}},
'(category)' : {'(column)' : {'(parameter)' : 42}}},
assigninfill = {'stdrdinfill':[], 'MLinfill':[], 'zeroinfill':[], 'oneinfill':[],
'adjinfill':[], 'meaninfill':[], 'medianinfill':[],
'interpinfill':[], 'modeinfill':[], 'lcinfill':[], 'naninfill':[]},
assignnan = {'categories':{}, 'columns':{}, 'global':[]},
transformdict = {}, processdict = {}, evalcat = False, ppd_append = False,
entropy_seeds = False, random_generator = False, sampling_dict = False,
privacy_encode = False, encrypt_key = False, printstatus = 'summary', logger = {})
Or for the postmunge function:
#for postmunge(.) function on additional or subsequently available test (or train) data
#using the postprocess_dict object returned from original automunge(.) application
#first you'll need to initialize
from Automunge import *
am = AutoMunge()
#then to run with default parameters
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test)
With the full set of arguments available to be passed as:
#first you'll need to initialize
from Automunge import *
am = AutoMunge()
#then if you want you can copy paste following to view all of parameter options
#here postprocess_dict was returned from corresponding automunge(.) call
#and df_test is the target data set to be prepared
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test,
testID_column = False,
pandasoutput = 'dataframe', printstatus = 'summary', inplace = False,
dupl_rows = False, TrainLabelFreqLevel = False,
featureeval = False, traindata = False, noise_augment = 0,
driftreport = False, inversion = False,
returnedsets = True, shuffletrain = False,
entropy_seeds = False, random_generator = False, sampling_dict = False,
randomseed = False, encrypt_key = False, logger = {})
Note that the only required argument to the automunge function is the train set dataframe, the other arguments all have default values if nothing is passed. The postmunge function requires as minimum the postprocess_dict object (a python dictionary returned from the application of automunge) and a dataframe test set consistently formatted as those sets that were originally applied to automunge.
...
Here now are descriptions for the returned sets from automunge, which will be followed by descriptions of the parameters which can be passed to the function, followed by similar treatment for postmunge returned sets and arguments. Further below is documentation for the library of transformations.
...
automunge(.) returned sets:
Automunge defaults to returning data sets as pandas dataframes, or for single column sets as pandas series.
For dataframes, data types of returned columns are based on the transformation applied, for example columns with boolean integers are cast as int8, ordinal encoded columns are given a conditional type based on the size of encoding space as either uint8, uint16, or uint32. Continuous sets are cast as float16, float32, or float64 based on the automunge(.) floatprecision parameter. And direct passthrough columns via excl transform retain the received data type.
-
train: a numerically encoded set of data intended to be used to train a downstream machine learning model in the framework of a user's choice
-
train_ID: the set of ID values corresponding to the train set if a ID column(s) was passed to the function. This set may be useful if the shuffle option was applied. Note that an ID column may serve multiple purposes such as row identifiers or for pairing tabular data rows with a corresponding image file for instance. Also included in this set is a derived column titled 'Automunge_index', this column serves as an index identifier for order of rows as they were received in passed data, such as may be beneficial when data is shuffled. If the received df_train had a non-ranged integer index, it is extracted and returned in this set. For more information please refer to writeup for the trainID_column parameter.
-
labels: a set of numerically encoded labels corresponding to the train set if a label column was passed. Note that the function assumes the label column is originally included in the train set. Note that if the labels set is a single column a returned dataframe is flattened to a pandas Series or a returned Numpy array is also flattened (e.g. [[1,2,3]] converted to [1,2,3] ).
-
val: a set of training data carved out from the train set that is intended for use in hyperparameter tuning of a downstream model.
-
val_ID: the set of ID values corresponding to the val set. Comparable to columns returned in train_ID.
-
val_labels: the set of labels corresponding to the val set
-
test: the set of features, consistently encoded and normalized as the training data, that can be used to generate predictions from a downstream model trained with train. Note that if no test data is available during initial address this processing will take place in the postmunge(.) function.
-
test_ID: the set of ID values corresponding to the test set. Comparable to columns returned in train_ID unless otherwise specified. For more information please refer to writeup for the testID_column parameter.
-
test_labels: a set of numerically encoded labels corresponding to the test set if a label column was passed.
-
postprocess_dict: a returned python dictionary that includes normalization parameters and trained ML infill models used to generate consistent processing of additional train or test data such as may not have been available at initial application of automunge. It is recommended that this dictionary be externally saved on each application used to train a downstream model so that it may be passed to postmunge(.) to consistently process subsequently available test data, such as demonstrated with the pickle library above.
A few useful entries in the postprocess_dict include:
- postprocess_dict['finalcolumns_train']: list of returned column headers for train set including suffix appenders
- postprocess_dict['columntype_report']: a report classifying the returned column types, including lists of all categoric and all numeric returned columns
- postprocess_dict['column_map']: a report mapping the input columns to their associated returned columns (excluding those consolidated as part of a dimensionality reduction). May be useful to inspect sets returned for a specific feature e.g. train[postprocess_dict['column_map']['input_column_header']]
- postprocess_dict['FS_sorted]: sorted results of feature importance evaluation if elected
- postprocess_dict['miscparameters_results']: reporting results of validation tests performed on parameters and passed data
...
automunge(.) passed parameters
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train, df_test = False,
labels_column = False, trainID_column = False, testID_column = False,
valpercent=0.0, floatprecision = 32, cat_type = False, shuffletrain = True, noise_augment = 0,
dupl_rows = False, TrainLabelFreqLevel = False, powertransform = False, binstransform = False,
MLinfill = True, infilliterate=1, randomseed = False, eval_ratio = .5,
numbercategoryheuristic = 255, pandasoutput = 'dataframe', NArw_marker = True,
featureselection = False, featurethreshold = 0., inplace = False, orig_headers = False,
Binary = False, PCAn_components = False, PCAexcl = [], excl_suffix = False,
ML_cmnd = {'autoML_type':'randomforest',
'MLinfill_cmnd':{'RandomForestClassifier':{}, 'RandomForestRegressor':{}},
'PCA_type':'default',
'PCA_cmnd':{}},
assigncat = {'1010':[], 'onht':[], 'ordl':[], 'bnry':[], 'hash':[], 'hsh2':[],
'DP10':[], 'DPoh':[], 'DPod':[], 'DPbn':[], 'DPhs':[], 'DPh2':[],
'nmbr':[], 'mnmx':[], 'retn':[], 'DPnb':[], 'DPmm':[], 'DPrt':[],
'bins':[], 'pwr2':[], 'bnep':[], 'bsor':[], 'por2':[], 'bneo':[],
'ntgr':[], 'srch':[], 'or19':[], 'tlbn':[], 'excl':[], 'exc2':[]},
assignparam = {'global_assignparam' : {'(parameter)': 42},
'default_assignparam' : {'(category)' : {'(parameter)' : 42}},
'(category)' : {'(column)' : {'(parameter)' : 42}}},
assigninfill = {'stdrdinfill':[], 'MLinfill':[], 'zeroinfill':[], 'oneinfill':[],
'adjinfill':[], 'meaninfill':[], 'medianinfill':[], 'negzeroinfill':[],
'interpinfill':[], 'modeinfill':[], 'lcinfill':[], 'naninfill':[]},
assignnan = {'categories':{}, 'columns':{}, 'global':[]},
transformdict = {}, processdict = {}, evalcat = False, ppd_append = False,
entropy_seeds = False, random_generator = False, sampling_dict = False,
privacy_encode = False, encrypt_key = False, printstatus = 'summary', logger = {})
-
df_train: a pandas dataframe or numpy array containing a structured dataset intended for use to subsequently train a machine learning model. The set at a minimum should be 'tidy' meaning a single column per feature and a single row per observation, with all unique string column headers. If desired the set may include one are more "ID" columns (intended to be carved out and consistently shuffled or partitioned such as an index column) and zero or one column intended to be used as labels for a downstream training operation. The tool supports the inclusion of non-index-range column as index or multicolumn index (requires named index columns). Such index types are added to the returned "ID" sets which are consistently shuffled and partitioned as the train and test sets. For passed numpy array any label column should be the final column.
-
df_test: a pandas dataframe or numpy array containing a structured dataset intended for use to generate predictions from a downstream machine learning model trained from the automunge returned sets. The set must be consistently formatted as the train set with consistent column headers and order of columns. (This set may optionally contain a labels column if one was included in the train set although its inclusion is not required). If desired the set may include one or more ID column(s) or column(s) intended for use as labels. A user may pass False if this set is not available. The tool supports the inclusion of non-index-range column as index or multicolumn index (requires named index columns). Such index types are added to the returned "ID" sets which are consistently shuffled and partitioned as the train and test sets.
-
labels_column: a string of the column title for the column from the df_train set intended for use as labels in training a downstream machine learning model. The function defaults to False for cases where the train set does not include a label column. An integer column index may also be passed such as if the source dataset was a numpy array. A user can also pass True in which case the label set will be taken from the final column of the train set (including cases of single column in train set). A label column for df_train data is partitioned and returned in the labels set. Note that a designated labels column will automatically be checked for in corresponding df_test data and partitioned to the returned test_labels set when included. Note that labels_column can also be passed as a list of multiple label columns. Note that when labels_column is passed as a list, a first entry set bracket specification comparable to as available for the Binary parameter can be applied to designate that multiple categoric labels in the list may be consolidated to a single categoric label, such as to train a single classification model for multiple classification targets, which form may then be recovered in a postmunge inversion='labels' operation, such as to convert the consolidated form after an inference operation back to the form of separate inferred labels. When passing data as numpy arrays the label column needs to be the final column (on far right of dataframe).
-
trainID_column: defaults to False, user can pass a column header or list of column headers for columns that are to be segregated from the df_train set for return in the train_ID set (consistently shuffled and partitioned when applicable). For example this may be desired for an index column or any other column that the user wishes to exclude from the ML infill basis. Defaults to False for cases where no ID columns are desired. Note that when designating ID columns for df_train if that set of ID columns is present in df_test they will automatically be given comparable treatment unless otherwise specified. An integer column index or list of integer column indexes may also be passed such as if the source dataset was a numpy array. Note that the returned ID sets (such as train_ID, val_ID, and test_ID) are automatically populated with an additional column with header 'Automunge_index' which may serve as an index column in cases of shuffling, validation partitioning, or oversampling. In cases of unnamed non-range integer indexes, they are automatically extracted and returned in the ID sets as 'Orig_index'. If a user would like to include a column both in the features for encoding and the ID sets for original form retention, they can pass trainID_column as a list of two lists, e.g. [list1, list2], where the first list may include ID columns to be struck from the features and the second list may include ID columns to be retained in the features.
-
testID_column: defaults to False, user can pass a column header or list of column headers for columns that are to be segregated from the df_test set for return in the test_ID set (consistently shuffled and partitioned when applicable). For example this may be desired for an index column or any other column that the user wishes to exclude from the ML infill basis. Defaults to False, which can be used for cases where the df_test set does not contain any ID columns, or may also be passed as the default of False when the df_test ID columns match those passed in the trainID_column parameter, in which case they are automatically given comparable treatment. Thus, the primary intended use of the testID_column parameter is for cases where a df_test has ID columns different from those passed with df_train. Note that an integer column index or list of integer column indexes may also be passed such as if the source dataset was a numpy array. (When passing data as numpy arrays one should match ID partitioning between df_test and df_train.) In cases of unnamed non-range integer indexes, they are automatically extracted and returned in the ID sets as 'Orig_index'. If a user would like to include a column both in the features for encoding and the ID sets for original form retention, they can pass testID_column as a list of two lists, e.g. [list1, list2], where the first list may include ID columns to be struck from the features and the second list may include ID columns to be retained in the features. (We recommend only using testID_column specification for cases where df_test includes columns that aren't present in df_train, otehrwise it is automatic.)
-
valpercent: a float value between 0 and 1 which designates the percent of the training data which will be set aside for the validation set (generally used for hyperparameter tuning of a downstream model). This value defaults to 0 for no validation set returned. Note that when shuffletrain parameter is activated (which is default for train sets) validation sets will contain random rows. If shuffletrain parameter is set to False then any validation set will be pulled from the bottom sequential rows of the df_train dataframe.
valpercent can also be passed as a two entry tuple in the form valpercent=(start, end), where start is a float in the range 0<=start<1, end is a float in the range 0<end<=1, and start < end. For example, if specified as valpercent=(0.2, 0.4), the returned training data would consist of the first 20% of rows and the last 60% of rows, while the validation set would consist of the remaining rows, and where the train and validation sets may then be subsequently individually shuffled when activated by the shuffletrain parameter. The purpose of this valpercent tuple option is to support integration into a cross validation operation, for example for a cross validation with k=3, automunge(.) could be called three times with valpercent passed for each as (0,0.33), (0.33,0.66), (0.66,1) respectively. Please note that when using automunge(.) in a cross-validation operation, we recommend using the postprocess_dict['final_assigncat'] entry populated in the first automunge(.) call associated with the first train/validation split as the assigncat entry passed to the automunge(.) assigncat parameter in each subsequent automunge(.) call associated with the remaining train/validation splits, which will speed up the remaining calls by eliminating the automated evaluation of data properties as well as mitigate risk of (remote) edge case when category assignment to a column under automation may differ between different validation set partitions due to deviations in aggregate data properties associated with a column.
#example of preparing k folds in a cross validation:
k=3
for i in range(k):
print('processing fold #', i)
#valpercent accepts a tuple of float ratios to set boundaries of validation split
valpercent = (i/k, (i+1)/k)
if i == 0:
#can also populate any manual assignments here
assigncat = {}
elif i > 0:
#after first fold use the final assigncat from prior
#to turn off automated category assignments
#which will speed it up and eliminate an edge case
assigncat = postprocess_dict['final_assigncat']
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train,
labels_column = labels_column,
valpercent = valpercent,
assigncat = assigncat)
#train and evaluate model with train/labels and val/val_labels
#note that in edge case number of columns may vary between folds
#which could arrise from e.g. 1010 binarization exposed to different range of entries in a feature
#if this becomes an obstacle can manually specify the range of activation targets in assignparam
#e.g. assignparam = {'1010' : {'<targetfeature>' : {'all_activations' : list_of_unique_values_for_targetfeature}}}
#or by just manually specifying ordinal encoding to categoric features in assigncat
#e.g. assigncat = {'ordl' : list_of_categoric_features}
#it is also possible to process folds for i>0 with train and validation data prepared seperately in postmunge
#this would run faster e.g. by eliminating redundant ML infill model training
#and ensure that each fold has same number of columns
#albeit with tradeoff of not strictly adhering to segregation of train/validation basis
#for avoidance of data leakage
-
floatprecision: an integer with acceptable values of 16/32/64 designating the memory precision for returned float values. (A tradeoff between memory usage and floating point precision, smaller for smaller footprint.) This currently defaults to 32 for 32-bit precision of float values. Note that there may be energy efficiency benefits at scale to basing this to 16. Note that integer data types are still retained with this option.
-
cat_type: accepts boolean defaulting to False, when True returned integer encoded categoric features are converted to pandas categorical data type based on the transform's MLinfill_type. In some cases this may actually slightly increase dataframe memory usage and is redundant with information stored in the postprocess_dict, however we expect there are potential downstream workflows where a user may prefer categoric data type which is the reason for the option. Note that for cases where a categoric transform feature did not have full representation in the training data set (e.g. as could be the case for fixed width bins with bnwd/bnwo/variants), it is possible that this option will result in test data returned with missing values designated as NaN entries (which is partly why this is not the default). Note that this same basis is carried through to postmunge.
-
shuffletrain: can be passed as one of {True, False, 'traintest'} which indicates if the returned sets will have their rows shuffled. Defaults to True for shuffling the train data but not the test data. False deactivates. To shuffle both train and test data can pass as 'traintest'. Note that this impacts the validation split if a valpercent was passed, where under the default of True validation data will be randomly sampled and shuffled, or when shuffletrain is deactivated validation data will be based on a partition of sequential rows from the bottom of the train set. Note that row correspondence with shuffling is maintained between train / ID / label sets. Note that we recommend deactivating shuffletrain for sequential (time-series) data.
-
noise_augment: accepts type int or float(int) >=0, defaults to 0. Used to specify a count of additional duplicates of training data prepared and concatenated with the original train set. Intended for use in conjunction with noise injection, such that the increased size of training corpus can be a form of data augmentation. (Noise injection still needs to be assigned, e.g. by assigning root categories in assigncat or could turn on automated noise with powertransform = 'DP1'). Note that injected noise will be uniquely randomly sampled with each duplicate. When noise_augment is received as a dtype of int, one of the duplicates will be prepared without noise. When noise_augment is received as a dtype of float(int), all of the duplicates will be prepared with noise. When shuffletrain is activated the duplicates are collectively shuffled, and can distinguish between duplicates by the original df_train.shape in comparison to the ID set's Automunge_index. Please be aware that with large dataframes a large duplicate count may run into memory constraints, in which case additional duplicates can be prepared separately in postmunge(.). Note that the entropy seed budget only accounts for preparing one set of data, for the noise_augment option with entropy seeding we recommend passing a custom extra_seed_generator with a sampling_type specification, which will result in internal samplings of additional entropy seeds for each additional noise_augment duplicate (or for the bulk_seeds case with external sampling can increase entropy_seed budget proportional to the number of additional duplicates with noise).
-
dupl_rows: can be passed as (True/False/'traintest'/'test') which indicates if duplicate rows will be consolidated to single instance in returned sets. (In other words, if same row included more than once, it will only be returned once.) Defaults to False for not activated. True applies consolidation to train set only, 'test' applies consolidation to test set only, 'traintest' applies consolidation to both train and test sets separately. Note this is applied prior to TrainLabelFreqLevel if elected. As implemented this does not take into account duplicate rows in train/test data which have different labels, only one version of features/label pair is returned.
-
TrainLabelFreqLevel: can be passed as (True/False/'traintest'/'test') which indicates if the TrainLabelFreqLevel method will be applied to prepare for oversampling training data associated with underrepresented labels (aka class imbalance). The method adds multiples of training data rows for those labels with lower frequency resulting in an (approximately) levelized frequency. This defaults to False. Note that this feature may be applied to numerical label sets if the processing applied to the set includes aggregated bins, such as for example by passing a label column to the 'exc3' category in assigncat for pass-through force to numeric with inclusion of standard deviation bins or to 'exc4' for inclusion of powers of ten bins. For cases where labels are included in the test set, this may also be passed as 'traintest' to apply levelizing to both train and test sets or be passed as 'test' to only apply levelizing to test set. (If a label set includes multiple configurations of the labels, the levelizing will be based on the first categoric / binned set (either one-hot or ordinal) based on order of columns.) For more on the class imbalance problem see "A systematic study of the class imbalance problem in convolutional neural networks" - Buda, Maki, Mazurowski.
-
powertransform: (False/True/'excl'/'exc2'/'infill'/'infill2'/'DP1'/'DP2'/'DT1'/'DT2'/'DB1'/'DB2'), defaults to False. The powertransform parameter is used to select between options for derived category assignments under automation based on received feature set properties.
- Under the default scenario, category assignments under automation are consistent with section Default Transformations.
- Under the True scenario, an evaluation will be performed of distribution properties to select between box-cox (bxcx), z-score (nmbr), min-max scaling (mnmx), or mean absolute deviation scaling (MAD3) normalization of numerical data. Please note that under automation label columns do not receive this treatment, if desired they can be assigned to category ptfm in assigncat.
- Under the 'excl' scenario, columns not explicitly assigned in assigncat are subject to excl transform for full pass-through, including data type retention and exclusion from ML infill basis.
- Under the 'exc2' scenario, columns not explicitly assigned in assigncat are subject to exc2 transform for pass-through with force to numeric and adjinfill, and included in ML infill basis.
- The 'infill' scenario may be used when data is already numerically encoded and user just desires ML infill without transformations. 'infill' treats sets with any non-integer floats with exc2 (pass-through numeric), integer sets with any negative entries or unique ratio >0.75 with exc8 (for pass-through continuous integer sets subject to ml infill regression), and otherwise integer sets with exc5 (pass-through integer subject to ml infill classification). Of course the rule of treating integer sets with >0.75 ratio of unique entries as targets for ML infill regression or otherwise for classification is an imperfect heuristic. If some particular feature set has integers intended for regression below this threshold, the defaults under automation can be overwritten to a specific column with the assigncat parameter, such as to assign the column to exc8 instead of exc5. Note that 'infill' includes support for NArw aggregation with NArw_marker parameter.
- The 'infill2' scenario is similar to the 'infill' scenario, with added allowance for inclusion of non-numeric sets, which are given an excl pass-through and excluded from ML infill basis. (May return sets not suitable for direct application of ML.) DP1 and DP2 are used for defaulting to noise injection for numeric and (non-hashed) categoric
- 'DP1' is similar to the defaults but default numerical replaced with DPnb, categoric with DP10, binary with DPbn, hash with DPhs, hsh2 with DPh2 (labels do not receive noise in this configuration)
- 'DP2' is similar to the defaults but default numerical replaced with DPrt, categoric with DPod, binary with DPbn, hash with DPhs, hsh2 with DPh2 (labels do not receive noise in this configuration)
- 'DT1'/'DT2' are comparable to 'DP1'/'DP2' but inject noise to just test data instead of just train data
- 'DB1'/'DB2' are comparable to 'DP1'/'DP2' but inject noise to both train and test data instead of just train data
-
binstransform: a boolean identifier (True/False) which indicates if all default numerical sets will receive bin processing such as to generate child columns with boolean identifiers for number of standard deviations from the mean, with groups for values <-2, -2-1, -10, 01, 12, and >2. This value defaults to False.
-
MLinfill: a boolean identifier (True/False) defaulting to True which indicates if the ML infill method will be applied (to columns not otherwise designated in assigninfill) to predict infill for missing or improperly formatted data using machine learning models trained on the rest of the df_train set. ML infill may alternatively be assigned to distinct columns in assigninfill when MLinfill passed as False. Note that even if sets passed to automunge(.) have no points needing infill, when activated ML infill models will still be trained for potential use to subsequent data passed through postmunge(.). ML infill by default applies scikit-learn random forest machine learning models to predict infill, which may be changed to other available auto ML frameworks via the ML_cmnd parameter. Parameters and tuning may also be passed to the model training as demonstrated with ML_cmnd parameter below. Order of infill model training is based on a reverse sorting of columns by count of missing entries in the df_train set. (As a helpful hint, if data is already numerically encoded and just want to perform ML infill without preprocessing transformations, can pass in conjunction parameter powertransform = 'infill')
To bidirectionally exclude particular features from each other's imputation model bases (such as may be desired in expectation of data leakage), a user can designate via entries to ML_cmnd['leakage_sets'], documented further below with ML_cmnd parameter. Or to unidirectionally exclude features from another's basis, a user can designate via entries to ML_cmnd['leakage_dict'], also documented below. To exclude a feature from all ML infill and PCA basis, can pass as entries to a list in ML_cmnd['full_exclude']. Please note that columns returned from transforms with MLinfilltype 'totalexclude' (such as for the excl passthrough transform) are automatically excluded from ML infill basis.
Please note that an assessment is performed to evaluate for cases of a kind of data leakage across features associated with correlated presence of missing data across rows for exclusion, documented further below with ML_cmnd parameter. This assessment can be deactivated by passing ML_cmnd['leakage_tolerance'] = False.
Please note that for incorporating stochastic injections into the derived imputations, an option is on by default which is further documented below in the ML_cmnd entries for 'stochastic_impute_categoric' and 'stochastic_impute_numeric'. Please note that by default the random seed passed to model training is stochastic between applications, as further documented below in the ML_cmnd entry for 'stochastic_training_seed'.
Further detail on ML infill provided in the paper Missing Data Infill with Automunge.
- infilliterate: an integer indicating how many applications of the ML infill processing are to be performed for purposes of predicting infill. The assumption is that for sets with high frequency of missing values that multiple applications of ML infill may improve accuracy although note this is not an extensively tested hypothesis. This defaults to 1. Note that due to the sequence of model training / application, a comparable set prepared in automunge and postmunge with this option may vary slightly in output (as automunge(.) will train separate models on each iteration and postmunge will just apply the final model on each iteration).
Please note that early stopping is available for infilliterate based on a comparison on imputations of a current iteration to the preceding, with a halt when reaching both of tolerances associated with numeric features in aggregate and categoric features in aggregate. Early stopping evaluation can be activated by passing to ML_cmnd ML_cmnd['halt_iterate']=True. The tolerances can be updated from the shown defaults as ML_cmnd['categoric_tol']=0.05 and ML_cmnd['numeric_tol']=0.03. Further detail on early stopping criteria is that the numeric halting criteria is based on comparing for each numeric feature the ratio of mean(abs(delta)) between imputation iterations to the mean(abs(entries)) of the current iteration, which are then weighted between features by the quantity of imputations associated with each feature and compared to a numeric tolerance value, and the categoric halting criteria is based on comparing the ratio of number of inequal imputations between iterations to the total number of imputations across categoric features to a categoric tolerance value. Early stopping is applied as soon as the tolerances are met for both numeric and categoric features. If early stopping criteria is not reached the specified infilliterate will serve as the maximum number of iterations. (Be aware that stochastic noise from stochastic_impute_numeric and stochastic_impute_categoric has potential to interfere with early stopping criteria. Each of these can be deactivated in ML_cmnd if desired.)
-
randomseed: defaults as False, also accepts integers within 0:2**31-1. When not specified, randomseed is based on a uniform randomly sampled integer within that range using an entropy_seeds when available. Can be manually specified such as for repeatable data set shuffling, feature importance, and other algorithms. Although ML infill by default samples a new random seed with each model training, to apply this random seed to all model training operations can set a ML_cmnd entry as ML_cmnd['stochastic_training_seed']=False.
-
eval_ratio: a 0-1 float or integer for number of rows, defaults to 0.5, serves to reduce the overhead of the category evaluation functions under automation by only evaluating this sampled ratio of rows instead from the full set. Makes automunge faster. To accommodate small data sets, the convention is that eval_ratio is only applied when training set has > 2,000 rows.
-
numbercategoryheuristic: an integer used as a heuristic. When a categorical set has more unique values than this heuristic, it defaults to categorical treatment via hashing processing via 'hsh2', otherwise categorical sets default to binary encoding via '1010'. This defaults to 255. Heuristic can be deactivated by passing as False.
-
pandasoutput: selects format of returned sets. Defaults to 'dataframe' for returned pandas dataframe for all sets. Dataframes index is not always preserved, non-integer indexes are extracted to the ID sets, and automunge(.) generates an application specific range integer index in ID sets corresponding to the order of rows as they were passed to function). If set to True, features and ID sets are comparable, and single column label sets are converted to Pandas Series instead of dataframe. If set to False returns numpy arrays instead of dataframes. Note that the dataframes will have column specific data types, or returned numpy arrays will have a single data type.
-
NArw_marker: a boolean identifier (True/False) which indicates if the returned sets will include columns with markers for source column entries subject to infill (columns with suffix '_NArw'). This value defaults to True. Note that the properties of cells qualifying as candidate for infill are based on the 'NArowtype' of the root category of transformations associated with the column, see Library of Transformations section below for catalog, the various NArowtype options (such as justNaN, numeric, positivenumeric, etc) are also further clarified below in discussion around the processdict parameter.
-
featureselection: applied to activate a feature importance evaluation. Defaults to False, accepts {False, True, 'pct', 'metric', 'report'}. If selected automunge will return a summary of feature importance findings in the featureimportance returned dictionary. False turns off, True turns on, 'pct' performs the evaluation followed by a dimensionality reduction based on the featurethreshold parameter to retain a % of top features. 'metric' performs the evaluation followed by a dimensionality reduction to retain features above a metric value based on featurethreshold parameter. 'report' performs the evaluation and returns a report with no further processing of data. Feature importance evaluation requires the inclusion of a designated label column in the train set. Note that sorted feature importance results are returned in postprocess_dict['FS_sorted'], including columns sorted by metric and metric2. Note that feature importance model training inspects same ML_cmnd parameters as ML infill. (Note that any user-specified size of validationratios if passed are used in this method, otherwise defaults to 0.2.) Note that as currently implemented feature selection does not take into account dimensionality reductions (like PCA or Binary). Permutation importance method was inspired by a fast.ai lecture and more information can be found in the paper "Beware Default Random Forest Importances" by Terrence Parr, Kerem Turgutlu, Christopher Csiszar, and Jeremy Howard. This method currently makes use of Scikit-Learn's Random Forest predictors.
-
featurethreshold: defaults to 0., accepts float in range of 0-1. Inspected when featureselection passed as 'pct' or 'metric'. Used to designate the threshold for feature importance dimensionality reduction. Where e.g. for 'pct' 0.9 would retain 90% of top features, or e.g. for 'metric' 0.03 would retain features whose metric was >0.03. Note that NArw columns are only retained for those sets corresponding to columns that "made the cut".
-
inplace: defaults to False, when True the df_train (and df_test) passed to automunge(.) are overwritten with the returned train and test sets. This reduces memory overhead. For example, to take advantage with reduced memory overhead you could call automunge(.) as:
df_train, train_ID, labels, \
val, val_ID, val_labels, \
df_test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train, df_test=df_test, inplace=True)
Note that this "inplace" option is not to be confused with the default inplace conduction of transforms that may impact grouping coherence of columns derived from same feature. That other inplace option can be deactivated in assignparam, as may be desired for grouping coherence. Note that all custom_train transforms have built in support for optional deactivating of inplace parameter through assignparam which is applied external to function call. Further detail on this other inplace option is provided in the essay Automunge Inplace.
assignparam = {'global_assignparam' : {'inplace' : False}}
- Binary: a dimensionality reduction technique whereby the set of columns from categoric encodings are collectively encoded with binary encoding such as may reduce the column count. This has many benefits such as memory bandwidth and energy cost for inference I suspect, however, there may be tradeoffs associated with ability of the model to handle outliers, as for any new combination of boolean set in the test data the collection will be subject to zeroinfill. Defaults to False, can be passed as one of {False, True, 'retain', 'ordinal', 'ordinalretain', 'onehot', 'onehotretain', [list of column headers]}.
- False: the default, Binary dimensionality reduction not performed
- True: consolidates Boolean integer sets into a single common binarization encoding with replacement
- 'retain': comparable to True, but original columns are retained instead of replaced
- 'ordinal': comparable to True, but consolidates into an ordinal encoding instead of binarization
- 'ordinalretain': comparable to 'ordinal', but original columns are retained instead of replaced
- 'onehot': comparable to True, but consolidates into a one hot encoding instead of binarization
- 'ordinalretain': comparable to 'onehot', but original columns are retained instead of replaced A user can also pass a list of target column headers if consolidation is only desired on a subset of the categoric features. The column headers may be as received column headers or returned column headers with suffix appenders included. To allow distinguishing between the other conventions such as 'retain', 'ordinal', etc. in conjunction with passing a subset list of column headers, a user may optionally include the specification embedded in set brackets {} as the first entry to the list, e.g. [{'ordinal'}, 'targetcolumn', ...], where specification may be one of True, 'retain', 'ordinal', etc. Otherwise when the first value in list is just a column header string the binarization convention consistent with Binary=True is applied. In order to separately consolidate multiple sets of categoric features, one can pass Binary as a list of lists, with the sub lists matching criteria noted preceding (such as allowance for first entry to embed specification in set brackets). For cases where a consolidation with replacement is performed these sets should be nonoverlapping. Note that each sub list may include a distinct specification convention. Note that postmunge(.) inversion is supported in conjunction with any of these Binary options. When applying inversion based on a specified list of columns (as opposed to inversion='test' for instance), if the specification includes a Binary returned column it should include the entire set of Binary columns associated with that consolidation, and if the Binary application was in the retain convention the inversion list should specify the Binary input columns instead of the Binary output columns. (One may wish to abstain from stochastic_impute_categoric in conjunction with Binary since it may interfere with the extent of contraction by expanding the number of activation sets.) Some additional detail on Binary provided in the essay Tabular Engineering with Automunge.
-
PCAn_components: defaults to False for no PCA dimensionality reduction performed. A user can pass an integer to define the number of PCA returned features for purposes of dimensionality reduction, such integer to be less than the otherwise returned number of sets. Function will default to kernel PCA for all non-negative sets or otherwise Sparse PCA. Also if this value is passed as a float <1.0 then linear PCA will be applied such that the returned number of sets are the minimum number that can reproduce that percent of the variance. Note this can also be passed in conjunction with assigned PCA type or parameters in the ML_cmnd object. Note that by default boolean integer and ordinal encoded returned columns are excluded from PCA, which convention can be updated in ML_cmnd if desired. These methods apply PCA with the scikit-learn library. As a special convention, if PCAn_components passed as None PCA is performed when # features exceeds 0.5 # rows (as a heuristic). (The 0.5 value can also be updated in ML_cmnd by passing to ML_cmnd['PCA_cmnd']['col_row_ratio'].) Note that inversion as can be performed with postmunge(.) is not currently supported for columns returned from PCA.
-
PCAexcl: a list of column headers for columns that are to be excluded from any application of PCA, defaults to [] (an empty list) for cases where no numeric columns are desired to be excluded from PCA. Note that column headers can be passed as consistent with the passed df_train to exclude from PCA all columns derived from a particular input column or alternatively can be passed with the returned column headers which include the suffix appenders to exclude just those specific columns from PCA.
-
orig_headers: accepts boolean defaults to False, when activated the returned columns have suffix appenders stripped to return consistent column headers as input. Note that this may result in redundent column headers in the returned dataframe and privacy_encode when activated takes precedence. Was created for use in workflows supporting integration of noise injection into existing data pipelines. Consistent basis applied in postmunge.
-
excl_suffix: boolean selector {True, False} for whether columns headers from 'excl' transform are returned with suffix appender '_excl' included. Defaults to False for no suffix. For advanced users setting this to True makes navigating data structures a little easier at small cost of aesthetics of any 'excl' pass-through column headers. ('excl' transform is for direct pass-through with no transforms, no infill, and no data type conversion. Note that 'excl' can be cast as the default category under automation to columns not otherwise assigned by setting powertransform='excl'.)
-
ML_cmnd: The ML_cmnd allows a user to set options or pass parameters to model training operations associated with ML infill, feature importance, or PCA. ML_cmnd is passed as a dictionary with first tier valid keys of: {'autoML_type', 'MLinfill_cmnd', 'customML', 'PCA_type', 'PCA_cmnd', 'PCA_retain', 'leakage_tolerance', 'leakage_sets', 'leakage_dict', 'full_exclude', 'hyperparam_tuner', 'randomCV_n_iter', 'stochastic_training_seed', 'stochastic_impute_numeric', 'stochastic_impute_numeric_mu', 'stochastic_impute_numeric_sigma', 'stochastic_impute_numeric_flip_prob', 'stochastic_impute_numeric_noisedistribution', 'stochastic_impute_categoric', 'stochastic_impute_categoric_flip_prob', 'stochastic_impute_categoric_weighted', 'halt_iterate', 'categoric_tol', 'numeric_tol', 'automungeversion', 'optuna_n_iter', 'optuna_timeout', 'optuna_kfolds', 'optuna_fasttune', 'optuna_early_stop', 'optuna_max_depth_tuning_stepsize', 'xgboost_gpu_id'}
When a user passed ML_cmnd as an empty dictionary, any default values are populated internally.
The most relevant entries here are 'autoML_type' to choose the autoML framework for predictive models, and ML_cmnd to pass parameters to the models. The default option for 'autoML_type' is 'randomforest' which uses a Scikit-learn Random Forest implementation, other options are supported as one of {'randomforest', 'customML', 'catboost', 'flaml'}, each discussed further below. The customML scenario is for user defined machine learning algorithms, and documented separately later in this document in the section Custom ML Infill Functions.
(Other ML_cmnd options beside autoML_type, like for early stopping through iterations, stochastic noise injections, hyperparpameter tuning, leakage assessment, etc, are documented a few paragraphs down after discussing the autoML_type scenarios.)
Here is an example of the core components of specification, which include the autoML_type to specify the learning library, the MLinfill_cmnd to pass parameters to the learning library, and similar options for PCA via PCA_type and PCA_cmnd.
ML_cmnd = {'autoML_type':'randomforest',
'MLinfill_cmnd':{'RandomForestClassifier':{}, 'RandomForestRegressor':{}},
'PCA_type':'default',
'PCA_cmnd':{}}
For example, a user who doesn't mind a little extra training time for ML infill could increase the passed n_estimators beyond the scikit default of 100.
ML_cmnd = {'autoML_type':'randomforest',
'MLinfill_cmnd':{'RandomForestClassifier':{'n_estimators':1000},
'RandomForestRegressor':{'n_estimators':1000}}}
A user can also perform hyperparameter tuning of the parameters passed to the predictive algorithms by instead of passing distinct values passing lists or range of values. This is currently supported for randomforest. The hyperparameter tuning defaults to grid search for cases where user passes any of fit parameters as lists or ranges, for example:
ML_cmnd = {'autoML_type':'randomforest',
'hyperparam_tuner':'gridCV',
'MLinfill_cmnd':{'RandomForestClassifier':{'max_depth':range(4,6)},
'RandomForestRegressor' :{'max_depth':[3,6,12]}}}
A user can also perform randomized search via ML_cmnd, and pass parameters as distributions via scipy stats module such as:
from scipy import stats
ML_cmnd = {'autoML_type':'randomforest',
'hyperparam_tuner' : 'randomCV',
'randomCV_n_iter' : 15,
'MLinfill_cmnd':{'RandomForestClassifier':{'max_depth':stats.randint(3,6)},
'RandomForestRegressor' :{'max_depth':[3,6,12]}}}
Other autoML options besides random forest are also supported, each of which requires installing the associated library (which aren't listed in the automunge dependencies). Citations associated with each of these libraries are provided for reference.
One autoML option for ML infill and feature importance is by the CatBoost library. Requires externally installing CatBoost library. Uses early stopping by default for regression and no early stopping by default for classifier. Note that the random_seed parameter is already passed based on the automunge(.) randomseed. Further information on the CatBoost library is available on arxiv as Anna Veronika Dorogush, Vasily Ershov, Andrey Gulin. CatBoost: gradient boosting with categorical features support arXiv:1810.11363.
#CatBoost available by passing ML_cmnd as
ML_cmnd = {'autoML_type':'catboost'}
Can pass parameters to model initialization and fit operation as:
#example of turning on early stopping for classifier
#by passing a eval_ratio for validation set which defaults to 0.15 for regressor
#note eval_ratio is an Automunge parameter, other parameters accepted are those from CatBoost library
ML_cmnd = {'autoML_type':'catboost',
'MLinfill_cmnd' : {'catboost_classifier_model' : {},
'catboost_classifier_fit' : {'eval_ratio' : 0.15 },
'catboost_regressor_model' : {},
'catboost_regressor_fit' : {}}}
Another ML infill option is available by the FLAML library. Further information on the FLAML library is available on arxiv as Chi Wang, Qingyun Wu, Markus Weimer, Erkang Zhu. FLAML: A Fast and Lightweight AutoML Library arXiv:1911.04706.
#FLAML available by passing ML_cmnd as
ML_cmnd = {'autoML_type':'flaml'}
Can pass parameters to fit operation as:
#example of setting time budget in seconds for training
ML_cmnd = {'autoML_type':'flaml',
'MLinfill_cmnd' : {'flaml_classifier_fit' : {'time_budget' : 15 },
'flaml_regressor_fit' : {'time_budget' : 15}}}
Another option is available for gradient boosting via the XGBoost library. Further information on the XGBoost library is available on arxiv as Tianqi Chen, Carlos Guestrin. XGBoost: A Scalable Tree Boosting System arXiv:1603.02754.
#XGboost available by passing ML_cmnd as
ML_cmnd = {'autoML_type':'xgboost'}
The XGBoost implementation has Bayesian hyperparameter tuning available by way of the Optuna library by activating ML_cmnd['hyperparam_tuner'] = 'optuna_XGB1'. Optuna tuning accepts parameters for designating the max number of tuning iterations ('optuna_n_iter'), max tuning time in seconds ('optuna_timeout'), selecting a count for k-fold cross validation for tuning ('optuna_kfolds'), activating only evaluating one k-fold per trial ('optuna_fasttune'), selecting an early stopping criteria for max number of tuning cycles without improved performance ('optuna_early_stop'), and selecting a step size for max_depth tuning (with longer tuning times it may be beneficial to change from 2 to 1) ('optuna_max_depth_tuning_stepsize'). The early stopping criteria optuna_n_iter/optuna_timeout/optuna_early_stop are the values applied per target feature (tuning for a feature is halted when one of these conditions are met). Can pass specific parameters (such as selecting whether to run inference with GPU or CPU with 'predictor'), activate GPU training, tune other hyperparameters with optuna, and set tuning options from the shown defaults as:
ML_cmnd = {'autoML_type' : 'xgboost',
'MLinfill_cmnd' : {'xgboost_classifier_fit' : {'predictor' : 'cpu_predictor' },
'xgboost_regressor_fit' : {'predictor' : 'cpu_predictor' }},
'xgboost_gpu_id' : 0,
'hyperparam_tuner' : 'optuna_XG1',
'optuna_n_iter' : 100,
'optuna_timeout' : 600,
'optuna_kfolds' : 5,
'optuna_fasttune' : True,
'optuna_early_stop': 50,
'optuna_max_depth_tuning_stepsize' : 2,
}
The implementation makes of XGBoost's "scikit-learn API", so accepted parameters are consistent with XGBClassifier and XGBRegressor. Please note that we recommend setting the gpu_id with ML_cmnd['xgboost_gpu_id'] (rather than passing through parameters) for consistent treatment between tuning and training, which automatically sets tree_method as gpu_hist. (If you intend to put the automunge(.) returned postprocess_dict into production you may want to set the predicter to cpu_predictor as shown so can run ML infill inference without a GPU.) If you don't know your gpu device id, they are usually integers (e.g. if you have one CUDA gpu the device id is usually the integer 0, you can verify this by passing "nvidia-smi" in a terminal window). 'xgboost_gpu_id' defaults to False when not specified, meaning training and inference are conducted on CPU.
Further information on the Optuna library is available on arxiv as Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, Masanori Koyama. Optuna: A Next-generation Hyperparameter Optimization Framework. arXiv:1907.10902. Our tuning implementation owes a thank you to a tutorial provided by Optuna.
Please note that model training by default incorporates a random random seed with each application, as can be deactivated by passing ML_cmnd['stochastic_training_seed'] = False to defer to the automunge(.) randomseed parameter.
Please note that there is a defaulted option to inject stochastic noise into derived imputations that can be deactivated for numeric features by passing ML_cmnd['stochastic_impute_numeric'] = False and/or categoric features by passing ML_cmnd['stochastic_impute_categoric'] = False.
Numeric noise injections sample from either a default laplace distribution or optionally a normal distribution. Default noise profile is mu=0, sigma=0.03, and flip_prob=0.06 (where flip_prob is ratio of a feature set's imputations receiving injections). Please note that this scale is based on a min/max scaled representation of the imputations. Parameters can be configured by passing ML_cmnd entries as floats to ML_cmnd['stochastic_impute_numeric_mu'], ML_cmnd['stochastic_impute_numeric_sigma'], ML_cmnd['stochastic_impute_numeric_flip_prob'] or as a string to ML_cmnd['stochastic_impute_numeric_noisedistribution'] as one of {'normal', 'laplace', 'abs_normal', 'negabs_normal', 'abs_laplace', 'negabs_laplace'}.
Categoric noise injections sample from a uniform random draw from the set of unique activation sets in the training data (as may include one or more columns for categoric representations), such that for a ratio of a feature's set's imputations based on the flip_prob (defaulting to 0.03 for categoric), each target imputation activation set is replaced with the randomly drawn activation set. Parameter can be configured by passing an ML_cmnd entry as a float to ML_cmnd['stochastic_impute_categoric_flip_prob']. Categoric noise injections by default weight injections per distribution of activations as found in train set. This can be deactivated by setting ML_cmnd['stochastic_impute_categoric_weighted'] as False.
(Please note that we suspect stochastic injections to imputations may have potential to interfere with infilliterate early stopping criteria associated with ML_cmnd['halt_iterate'] documented above with the infilliterate parameter.)
To bidirectionally exclude particular features from each other's imputation model bases (such as may be desired in expectation of data leakage), a user can designate via entries to ML_cmnd['leakage_sets'], which accepts entry of a list of column headers or as a list of lists of column headers, where for each list of column headers, entries will be excluded from each other's imputation model basis. We suggest populating with column headers in form of data passed to automunge(.) (before suffix appenders) although specific returned column headers can also be included if desired.
To unidirectionally exclude particular features from another feature's imputation model basis, a user can designate via entries to ML_cmnd['leakage_dict'], which accepts entry of a dictionary with target feature keys and values of a set of features to exclude from the target feature's basis. This also accepts headers in either of input or returned convention.
To exclude a feature from ML infill basis of all other features, can pass as a list of entries to ML_cmnd['full_exclude']. This also accepts headers in either of input or returned convention. Please note that columns returned from transforms with MLinfilltype 'totalexclude' (such as for the excl passthrough transform) are automatically excluded from model training basis. Note that entries to 'full_exclude' are also excluded from PCA.
Please note that an operation is performed to evaluate for cases of a kind of data leakage across features associated with correlated presence of missing data across rows. Leakage tolerance is associated with an automated evaluation for a potential source of data leakage across features in their respective imputation model basis. The method compares aggregated NArw activations from a target feature in a train set to the surrounding features in a train set and for cases where separate features share a high correlation of missing data based on the shown formula we exclude those surrounding features from the imputation model basis for the target feature.
((Narw1 + Narw2) == 2).sum() / NArw1.sum() > leakage_tolerance
Where target features are those input columns with some returned column serving as target for ML infill. ML_cmnd['leakage_tolerance'] defaults to 0.85 when not specified, and can be set as 1 or False to deactivate the assessment.
If no ML infill model is trained due to insufficient features remaining after leakage carveouts for a target feature, a validation result is recorded in postprocess_dict['miscparameters_results']['not_enough_samples_or_features_for_MLinfill_result']['(feature)'].
A user can also assign specific methods for PCA transforms. Current PCA_types supported include one of {'PCA', 'SparsePCA', 'KernelPCA'}, all via Scikit-Learn. Note that the n_components are passed separately with the PCAn_components argument noted above. A user can also pass parameters to the PCA functions through the PCA_cmnd, for example one could pass a kernel type for KernelPCA as:
ML_cmnd = {'PCA_type':'KernelPCA',
'PCA_cmnd':{'kernel':'sigmoid'}}
Note that for the default of ML_cmnd['PCA_type'] = 'default', PCA will default to KernelPCA for all non-negative sets or otherwise Sparse PCA (unless PCAn_components was passed as float between 0-1 in which case will apply as 'PCA'.
By default, ML_cmnd['PCA_cmnd'] is initialized internal to library with {'bool_ordl_PCAexcl':True}, which designates that returned ordinal and boolean encoded columns are to be excluded from PCA. This convention by be turned off by passing as False, or to only exclude boolean integer but not ordinal encoded columns can pass ML_cmnd['PCA_cmnd'] as {'bool_PCA_excl':True}.
For the PCA aggregation to be performed without replacement, can pass ML_cmnd['PCA_retain']=True.
- assigncat: assigncat accepts a dictionary used to assign root categories of transformation to input features. The keys of the dictionary accept root transformation categories and the corresponding values should be assigned as a string or list of strings representing column headers of input features.
#Here are a few representative root categories.
#first row: categoric encodings
#second row: corresponding categoric encodings with noise injection
#third row: numeric normalizaitons and corresponding normalizations with noise
#fourth row: examples of binning transforms (as could be added to a normalization family tree)
#fifth row: miscellaneous, including integer sets, search, string parsing, explainability support, and passthrough
assigncat = {'1010':[], 'onht':[], 'ordl':[], 'bnry':[], 'hash':[], 'hsh2':[],
'DP10':[], 'DPoh':[], 'DPod':[], 'DPbn':[], 'DPhs':[], 'DPh2':[],
'nmbr':[], 'mnmx':[], 'retn':[], 'DPnb':[], 'DPmm':[], 'DPrt':[],
'bins':[], 'pwr2':[], 'bnep':[], 'bsor':[], 'por2':[], 'bneo':[],
'ntgr':[], 'srch':[], 'or19':[], 'tlbn':[], 'excl':[], 'exc2':[]}
Full options are provided in document below (in section titled "Library of Transformations"). Library of Transformations
A user may add column header identifier strings to each of these lists to assign a distinct specific processing approach to any column (including labels). Note that this processing category will serve as the "root" of the tree of transforms as defined in the transformdict. Note that additional categories may be passed if defined in the passed transformdict and processdict. An example of usage here could be to assign the numeric noise injection transform 'DPnb' to two input features we'll call 'input_column_1' and 'input_column_2'.
assigncat = {'DPnb':['input_column_1', 'input_column_2']}
Note that for single entry column assignments a user can just pass the string or integer of the column header without the list brackets.
Note tht a small number of transforms, such as DPmp or DPse, support assigncat specification with multiple input columns treated as a single feature, available by in the assigncat specification replacing a single input header string with a {set} of input header strings.
assigncat = {'DPmp':[{'input_column_1', 'input_column_2'}]}
- assignparam: A user may pass column-specific or category specific parameters to those transformation functions that accept parameters. Any parameters passed to automunge(.) will be saved in the postprocess_dict and consistently applied in postmunge(.). assignparam is a dictionary that should be formatted per following example:
#template:
assignparam = {'global_assignparam' : {'(parameter)': 42},
'default_assignparam' : {'(category)' : {'(parameter)' : 42}},
'(category)' : {'(column)' : {'(parameter)' : 42}}}
#example:
assignparam = {'category1' : {'column1' : {'param1' : 123}, 'column2' : {'param1' : 456}},
'category2' : {'column3' : {'param2' : 'abc', 'param3' : 'def'}}}
In other words: The first layer keys are the transformation category for which parameters are intended. The second layer keys are string identifiers for the columns for which the parameters are intended. The third layer keys are the parameters whose values are to be passed. To specify new default parameters for a given transformation category 'default_assignparam' can be applied, or to specify global parameters for all transformation functions 'global_assignparam' can be applied. Transforms that do not accept a particular parameter will just ignore the specification.
As an example with actual parameters, consider the transformation category 'splt' intended for 'column1', which accepts parameter 'minsplit' for minimum character length of detected overlaps. If we wanted to pass 4 instead of the default of 5:
assignparam = {'splt' : {'column1' : {'minsplit' : 4}}}
Note that the category identifier should be the category entry to the family tree primitive associated with the transform, which may be different than the root category of the family tree assigned in assigncat. The set of family tree definitions for root categories are included below for reference. Generally speaking, the transformation category to serve as a target for asisgnparam assignment will match the recorded suffix appender of the returned column headers.
As an example, to demonstrate edge case for cases where the transformation category does not match the transformation function (based on entries to transformdict and processdict), if we want to pass a parameter to turn off UPCS transform included in or19 family tree and associated with the or19 transformation category for instance, we would pass the parameter to or19 instead of UPCS because assignparam inspects the transformation category associated with the transformation function, and UPCS function is the processdict entry for or19 category entry in the family tree primitives associated with the or19 root category, even though 'activate' is an UPCS transformation function parameter. A helpful rule of thumb to help distinguish is that the suffix appender recorded in the returned column associated with an applied transformation function should match the transformation category serving as target for assignparam assignment, as in this case the UPCS transform records a 'or19' suffix appender. (This clarification intended for advanced users to avoid ambiguity.)
assignparam = {'or19' : {'column1' : {'activate' : False}}}
Note that column string identifiers may just be the source column string or may include the suffix appenders for downstream columns serving as input to the target transformation function, such as may be useful if multiple versions of the same transformation are applied within the same family tree. If more than one column identifier matches a column in assignparam entry to a transformation category (such as both the source column and the derived column serving as input to the transformation function), the derived column (such as may include suffix appenders) will take precedence.
Note that if a user wishes to overwrite the default parameters associated with a particular category for all columns without specifying them individually they can pass a 'default_assignparam' entry as follows (this only overwrites those parameters that are not otherwise specified in assignparam).
assignparam = {'category1' : {'column1' : {'param1' : 123}, 'column2' : {'param1' : 456}},
'category2' : {'column3' : {'param2' : 'abc', 'param3' : 'def'}},
'default_assignparam' : {'category3' : {'param4' : 789}}}
Or to pass the same parameter to all transformations to all columns, can use the 'global_assignparam'. The global_assignparam may be useful for instance to turn off inplace transformations such as to retain family tree column grouping correspondence in returned set. Transformations that do not accept a particular parameter will just ignore.
assignparam = {'global_assignparam' : {'inplace' : False}}
In order of precedence, parameter assignments may be designated targeting a transformation category as applied to a specific column header with suffix appenders, a transformation category as applied to an input column header (which may include multiple instances), all instances of a specific transformation category, all transformation categories, or may be initialized as default parameters when defining a transformation category.
See the Library of Transformations section below for those transformations that accept parameters.
- assigninfill
#Here are the current infill options built into our library, which
#we are continuing to build out.
assigninfill = {'stdrdinfill':[], 'MLinfill':[], 'zeroinfill':[], 'oneinfill':[],
'adjinfill':[], 'meaninfill':[], 'medianinfill':[], 'negzeroinfill':[],
'modeinfill':[], 'lcinfill':[], 'naninfill':[]}
A user may add column identifier strings to each of these lists to designate the column-specific infill approach for missing or improperly formatted values. The source column identifier strings may be passed for assignment of common infill approach to all columns derived from same source column, or derived column identifier strings (including the suffix appenders from transformations) may be passed to assign infill approach to a specific derived column. Note that passed derived column headers take precedence in case of overlap with passed source column headers. Note that infill defaults to MLinfill if nothing assigned and the MLinfill argument to automunge is set to True. Note that for single entry column assignments a user can just pass the string or integer of the column header without the list brackets. Note that the infilled cells are based on the rows corresponding to activations from the NArw_marker parameter.
# - stdrdinfill : the default infill specified in the library of transformations for
# each transform below.
# - MLinfill : for MLinfill to distinct columns when MLinfill parameter not activated
# - zeroinfill : inserting the integer 0 to missing cells.
# - oneinfill : inserting the integer 1.
# - negzeroinfill : inserting the float -0.
# - adjinfill : passing the value from the preceding row to missing cells.
# - meaninfill : inserting the mean derived from the train set to numeric columns.
# - medianinfill : inserting the median derived from the train set to numeric columns.
# (Note currently boolean columns derived from numeric are not supported
# for mean/median and for those cases default to those infill from stdrdinfill.)
# - interpinfill : performs linear interpolation to numeric sets, based on pandas interpolate
# - modeinfill : inserting the most common value for a set, note that modeinfill
# supports multi-column boolean encodings, such as one-hot encoded sets or
# binary encoded sets.
# - lcinfill : comparable to modeinfill but with least common value instead of most.
# - naninfill : inserting NaN to missing cells.
#an example of passing columns to assign infill via assigninfill:
#for source column 'column1', which hypothetically is returned through automunge(.) as
#'column1_nmbr', 'column1_mnmx', 'column1_bxcx_nmbr'
#we can assign MLinfill to 'column1_bxcx_nmbr' and meaninfill to the other two by passing
#to an automunge call:
assigninfill = {'MLinfill':['column1_bxcx_nmbr'], 'meaninfill':['column1']}
- assignnan: for use to designate data set entries that will be targets for infill, such as may be entries not covered by NArowtype definitions from processdict. For example, we have general convention that NaN (as np.nan) is a target for infill, but a data set may be passed with a custom string signal for infill, such as 'unknown'. This assignment operator saves the step of manual munging prior to passing data to functions by allowing user to specify custom targets for infill.
assignnan accepts following form, populated in first tier with any of 'categories'/'columns'/'global'
assignnan = {'categories':{}, 'columns':{}, 'global':[]}
Note that global takes entry as a list, while categories and columns take entries as a dictionary with values of the target assignments and corresponding lists of terms, which could be populated with entries as e.g.:
assignnan = {'categories' : {'cat1' : ['unknown1']},
'columns' : {'col1' : ['unknown2']},
'global' : ['unknown3']}
Where 'cat1' is example of root category, 'col1' is example of source column header, and 'unknown1'/2/3 are examples of entries intended for infill corresponding to each. In cases of redundant specification, global takes precedence over columns which takes precedence over categories. Note that lists of terms can also be passed as single values such as string / number for internal conversion to list.
assignnan also supports stochastic and range based injections, such as to target for infill specific segments of a set's distribution. 'injections' can be passed to assignnan as:
assignnan = {'injections' : {'(column)' : {'inject_ratio' : (float),
'range' : {'ratio' : (float),
'ranges' : [[min1, max1], [min2, max2]]},
'minmax_range' : {'ratio' : (float),
'ranges' : [[min1, max1], [min2, max2]]},
'entries' : ['(entry1)', '(entry2)'],
'entry_ratio' : {'(entry1)' : (float),
'(entry2)' : (float)}
}
}
}
#where injections may be specified for each source column passed to automunge(.)
#- inject_ratio is uniform randomly injected nan points to ratio of entries
#- range is injection within a specified range based on ratio float defaulting to 1.0
#- minmax_range is injection within scaled range (accepting floats 0-1 based on received
#column max and min (returned column is not scaled)
#- entries are full replacement of specific entries to a categoric set
#- entry_ratio are partial injection to specific entries to a categoric set per specified float ratio
- transformdict: a dictionary allowing a user to pass a custom tree of transformations or to overwrite family trees defined in the transform_dict internal to the library. Defaults to {} (an empty dictionary). Note that a user may define their own (traditionally 4 character) string "root categories" by populating a "family tree" of transformation categories associated with that root category, which are a way of specifying the type and order of transformation functions to be applied. Each category populated in a family tree requires its own transformdict root category family tree definition as well as an entry in the processdict described below for assigning associated transformation functions and data properties. Note that the library has an internally defined library of transformation categories prepopulated in the internal transform_dict which are detailed below in the Library of Transformations section of this document. For clarity transformdict refers to the user passed data structure which is subsequently consolidated into the internal "transform_dict" (with underscore) data structure. The returned version in postprocess_dict['transform_dict'] records entries that were inspected in the associated automunge(.) call.
#transform_dict is for purposes of populating
#for each transformation category's use as a root category
#a "family tree" set of associated transformation categories
#which are for purposes of specifying the type and order of transformation functions
#to be applied when a transformation category is assigned as a root category
#we'll refer to the category key to a family as the "root category"
#we'll refer to a transformation category entered into
#a family tree primitive as a "tree category"
#a transformation category may serve as both a root category
#and a tree category
#each transformation category will have a set of properties assigned
#in the corresponding process_dict data structure
#including associated transformation functions, data properties, and etc.
#a root category may be assigned to a column with the user passed assigncat
#or when not specified may be determined under automation via _evalcategory
#when applying transformations
#the transformation functions associated with a root category
#will not be applied unless that same category is populated as a tree category
#the family tree primitives are for purposes of specifying order of transformations
#as may include generations and branches of derivations
#as well as for managing column retentions in the returned data
#(as in some cases intermediate stages of transformations may or may not have desired retention)
#the family tree primitives can be distinguished by types of
#upstream/downstream, supplement/replace, offsping/no offspring
#___________
#'parents' :
#upstream / first generation / replaces column / with offspring
#'siblings':
#upstream / first generation / supplements column / with offspring
#'auntsuncles' :
#upstream / first generation / replaces column / no offspring
#'cousins' :
#upstream / first generation / supplements column / no offspring
#'children' :
#downstream parents / offspring generations / replaces column / with offspring
#'niecesnephews' :
#downstream siblings / offspring generations / supplements column / with offspring
#'coworkers' :
#downstream auntsuncles / offspring generations / replaces column / no offspring
#'friends' :
#downstream cousins / offspring generations / supplements column / no offspring
#___________
#each of the family tree primitives associated with a root category
#may have entries of zero, one, or more transformation categories
#when a root category is assigned to a column
#the upstream primitives are inspected
#when a tree category is found
#as an entry to an upstream primitive associated with the root category
#the transformation functions associated with the tree category are performed
#if any tree categories are populated in the upstream replacement primitives
#their inclusion supersedes supplement primitive entries
#and so the input column to the transformation is not retained in the returned set
#with the column replacement either achieved by an inplace transformation
#or subsequent deletion operation
#when a tree category is found
#as an entry to an upstream primitive with offspring
#after the associated transformation function is performed
#the downstream primitives of the family tree of the tree category is inspected
#and those downstream primitives are treated as a subsequent generation's upstream primitives
#where the input column to that subsequent generation is the column returned
#from the transformation function associated with the upstream tree category
#this is an easy point of confusion so as further clarification on this point
#the downstream primitives associated with a root category
#will not be inspected when root category is applied
#unless that root category is also entered as a tree category entry
#in one of the root category's upstream primitives with offspring
Once a root category has been defined, it can be assigned to a received column in assigncat. For example, a user wishing to define a new set of transformations for a numerical set can define a new root category 'newt' that combines NArw, min-max, box-cox, z-score, and standard deviation bins by passing a transformdict as:
transformdict = {'newt' : {'parents' : ['bxc4'],
'siblings': [],
'auntsuncles' : ['mnmx', 'bins'],
'cousins' : ['NArw'],
'children' : [],
'niecesnephews' : [],
'coworkers' : [],
'friends' : []}}
#Where since bxc4 is passed as a parent, this will result in pulling
#offspring keys from the bxc4 family tree, which has a nbr2 key as children.
#from automunge internal library:
transform_dict.update({'bxc4' : {'parents' : ['bxcx'],
'siblings': [],
'auntsuncles' : [],
'cousins' : ['NArw'],
'children' : [],
'niecesnephews' : [],
'coworkers' : ['nbr2'],
'friends' : []}})
#note that 'nbr2' is passed as a coworker primitive meaning no downstream
#primitives would be accessed from the nbr2 family tree. If we wanted nbr2 to
#incorporate any offspring from the nbr2 tree we could instead assign as children
#or niecesnephews.
#Having defined this root category 'newt', we can then assign to a column in assigncat
#(Noting that we still need a corresponding processdict entry unless overwriting an internal transform_dict entry.)
assigncat = {'newt':['targetcolumn']}
#Note that optionally primitives without entries can be omitted,
#and list brackets can be omitted for single entries to a primitive
#the following is an equivalent specification to the 'newt' entry above
transformdict = {'newt' : {'parents' : 'bxc4',
'auntsuncles' : ['mnmx', 'bins'],
'cousins' : 'NArw'}}
Basically here 'newt' is the root category key and once defined can be assigned as a root category in assigncat to be applied to a column or can also be passed to one of the family primitives associated with itself or some other root category to apply the corresponding transformation functions populated in the processdict entry. Once a transformation category is accessed based on an entry to a family tree primitive associated with a root category assigned to a column, the corresponding processdict transformation function is applied, and if it was accessed as a family tree primitive with downstream offspring then those offspring keys are pulled from that key's family tree. For example, here mnmx is passed as an auntsuncles which means the mnmx processing function is applied with no downstream offspring. The bxc4 key is passed as a parent which means the transform associated with the bxc4 category is applied followed by any downstream transforms from the bxc4 key family tree, which we also show. Note the family primitives tree can be summarized as:
'parents' : upstream / first generation / replaces column / with offspring
'siblings': upstream / first generation / supplements column / with offspring
'auntsuncles' : upstream / first generation / replaces column / no offspring
'cousins' : upstream / first generation / supplements column / no offspring
'children' : downstream parents / offspring generations / replaces column / with offspring
'niecesnephews' : downstream siblings / offspring generations / supplements column / with offspring
'coworkers' : downstream auntsuncles / offspring generations / replaces column / no offspring
'friends' : downstream cousins / offspring generations / supplements column / no offspring
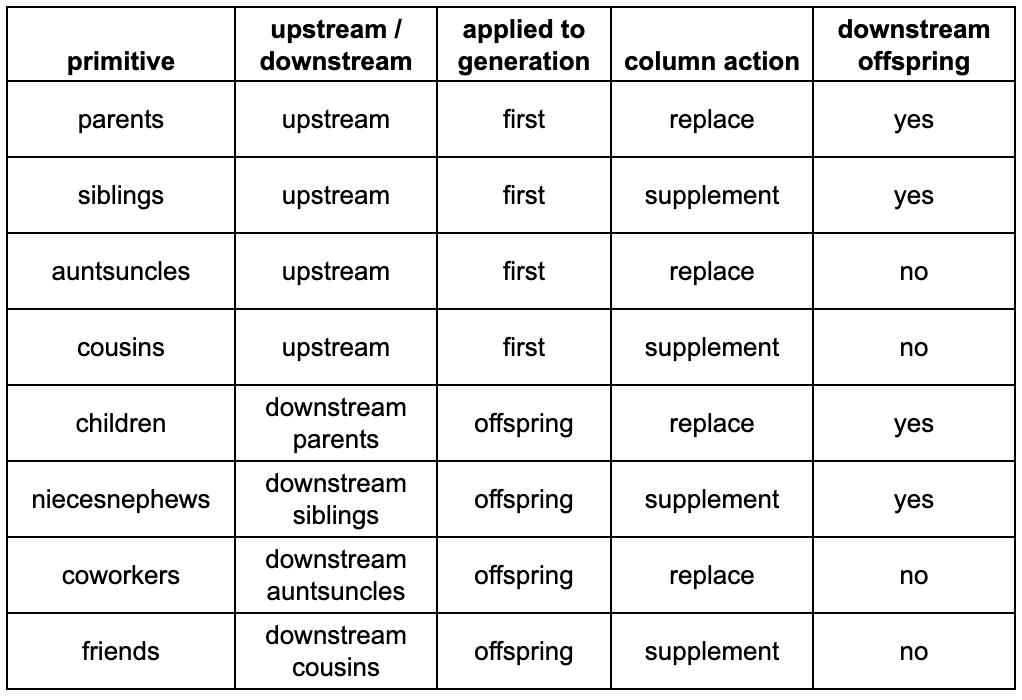
Note that a user should avoid redundant entries across a set of upstream or downstream primitives. If a redundant transformation function is desired to a distinct upstream or downstream inputcolumn (such as may be desired to apply same transform but with different parameters), each of the redundant applications needs a distinct transformation category defined in the processdict (and a distinct suffix appender which is automatic based on the transformation category). Since there is recursion involved a user should be careful of creating infinite loops from passing downstream primitive entries with offspring whose own offspring coincide with an earlier generation. (The presence of infinite loops is tested for to a max depth of 1111 offspring, an arbitrary figure.)
Note that transformdict entries can be defined to overwrite existing root category entries defined in the internal library. For example, if we wanted our default numerical scaling to be by min-max instead of z-score normalization, one way we could accomplish that is to overwrite the 'nmbr' family tree which is the default root category applied to numeric sets under automation. (Other default root categories under automation are detailed further below in the "Default Tranformations" section.) An alternate approach could be to overwrite the nmbr processdict entry which we'll demonstrate shortly.
transformdict = {'nmbr' : {'auntsuncles' : 'mnmx',
'cousins' : 'NArw'}}
Note that when we define a new root category family tree such as the 'newt' example shown above, we also need to define a corresponding processdict entry for the new category, which we detail next.
Further detail on the transformdict data format provided in the essay Data Structure. For tutorials on defining a family tree, see also the essay Specification of Derivations with Automunge.
- processdict: a dictionary allowing a user to specify transformation category properties corresponding to new categories defined in transformdict or to overwrite process_dict entries defined internal to the library. Defaults to {} (an empty dictionary). The types of properties specified include the associated transformation functions, types of data that will be targets for infill, a classification of data types (such as between numeric, integer, categoric, etc), and more detailed below. All transformation categories used in transformdict, including those used as root categories as well as transformation category entries to family tree primitives associated with a root category, require a corresponding entry in the processdict to define transformation category properties. Only in cases where a transformdict entry is being passed to overwrite an existing category internal to the library is a corresponding processdict entry not required. However note that a processdict entry can be passed without a corresponding root category definition in transformdict, which may be used when passing a custom transformation category to a family tree primitive without offspring.
We'll describe the options for processdict entries here. For clarity processdict refers to the user passed data structure which is subsequently consolidated into the internal "process_dict" (with underscore) data structure. The returned version in postprocess_dict['process_dict'] records entries that were inspected in the associated automunge(.) call.
#A user should pass either a pair of processing functions to both
#dualprocess and postprocess, or alternatively just a single processing
#function to singleprocess, and omit or pass None to those not used.
#A user can also pass an inversion function to inverseprocess if available.
#Most of the transforms defined internal to the library follow this convention.
#dualprocess: for passing a processing function in which normalization
# parameters are derived from properties of the training set
# and jointly process the train set and if available corresponding test set
#singleprocess: for passing a processing function in which no normalization
# parameters are needed from the train set to process the
# test set, such that train and test sets processed separately
#postprocess: for passing a processing function in which normalization
# parameters originally derived from the train set are applied
# to separately process a corresponding test set
# An entry should correspond to the dualprocess entry.
#inverseprocess: for passing a processing function used to invert
# a corresponding forward pass transform
# An entry should correspond to the dualprocess or singleprocess entry.
#__________________________________________________________________________
#Alternative streamlined processing function conventions are also available
#which may be populated as entries to custom_train / custom_test / custom_inversion.
#These conventions are documented in the readme section "Custom Transformation Functions".
#In cases of redundancy custom_train entry specifications take precedence
#over dualprocess/singleprocess/postprocess entries.
#custom_train: for passing a train set processing function in which normalization parameters
# are derived from properties of the training set. Will be used to process both
# train and test data when custom_test not provided (in which case similar to singleprocess convention).
#custom_test: for passing a test set processing function in which normalization parameters
# that were derived from properties of the training set are used to process the test data.
# When omitted custom_train will be used to process both the train and test data.
# An entry should correspond to the custom_train entry.
#custom_inversion: for passing a processing function used to invert
# a corresponding forward pass transform
# An entry should correspond to the custom_train entry.
#___________________________________________________________________________
#The processdict also specifies various properties associated with the transformations.
#At a minimum, a user needs to specify NArowtype and MLinfilltype or otherwise
#include a functionpointer entry.
#___________________________________________________________________________
#NArowtype: classifies the type of entries that are targets for infill.
# can be entries of {'numeric', 'integer', 'justNaN', 'exclude',
# 'positivenumeric', 'nonnegativenumeric',
# 'nonzeronumeric', 'parsenumeric', 'datetime'}
# Note that in the custom_train convention this is used to apply data type casting prior to the transform.
# - 'numeric' for source columns with expected numeric entries
# - 'integer' for source columns with expected integer entries
# - 'justNaN' for source columns that may have expected entries other than numeric
# - 'binary' similar to justNaN but only the top two most frequent entries are considered valid
# - 'exclude' for source columns that aren't needing NArow columns derived
# - 'totalexclude' for source columns that aren't needing NArow columns derived,
# also excluded from assignnan global option and nan conversions for missing data
# - 'positivenumeric' for source columns with expected positive numeric entries
# - 'nonnegativenumeric' for source columns with expected non-negative numeric (zero allowed)
# - 'nonzeronumeric' for source columns with allowed positive and negative but no zero
# - 'parsenumeric' marks for infill strings that don't contain any numeric characters
# - 'datetime' marks for infill cells that aren't recognized as datetime objects
# ** Note that NArowtype also is used as basis for metrics evaluated in drift assessment of source columns
# ** Note that by default any np.inf values are converted to NaN for infill
# ** Note that by default python None entries are treated as targets for infill
#___________________________________________________________________________
#MLinfilltype: classifies data types of the returned set,
# as may determine what types of models are trained for ML infill
# can be entries {'numeric', 'singlct', 'binary', 'multirt', 'concurrent_act', 'concurrent_nmbr',
# '1010', 'exclude', 'boolexclude', 'ordlexclude', 'totalexclude'}
# 'numeric' single columns with numeric entries for regression (signed floats)
# 'singlct' for single column sets with ordinal entries (nonnegative integer classification)
# 'integer' for single column sets with integer entries (signed integer regression)
# 'binary' single column sets with boolean entries (0/1)
# 'multirt' categoric multicolumn sets with boolean entries (0/1), up to one activation per row
# '1010' for multicolumn sets with binary encoding via 1010, boolean integer entries (0/1),
# with distinct encoding representations by the set of activations
# 'concurrent_act' for multicolumn sets with boolean integer entries as may have
# multiple entries in the same row, different from 1010
# in that columns are independent
# 'concurrent_ordl' for multicolumn sets with ordinal encoded entries (nonnegative integer classification)
# 'concurrent_nmbr' for multicolumn sets with numeric entries (signed floats)
# 'exclude' for columns which will be excluded from infill, included in other features' ML infill bases
# returned data should be numerically encoded
# 'boolexclude' boolean integer set suitable for Binary transform but excluded from all infill
# (e.g. NArw entries), included in other features' ML infill bases
# 'ordlexclude' ordinal set excluded from infill (note that in some cases in library
# ordlexclude may return a multi-column set), included in other features' ML infill bases
# 'totalexclude' for complete passthroughs (excl) without datatype conversions, infill,
# excluded from other features' ML infill bases
#___________________________________________________________________________
#Other optional entries for processdict include:
#info_retention, inplace_option, defaultparams, labelctgy,
#defaultinfill, dtype_convert, functionpointer, and noise_transform.
#___________________________________________________________________________
#info_retention: boolean marker associated with an inversion operation that helps inversion prioritize
#transformation paths with full information recovery. (May pass as True when there is no information loss.)
#___________________________________________________________________________
#inplace_option: boolean marker indicating whether a transform supports the inplace parameter received in params.
# When not specified this is assumed as True (which is always valid for the custom_train convention).
# In other words, in dualprocess/singleprocess convention, if your transform does not support inplace,
# need to specify inplace_option as False
#___________________________________________________________________________
#defaultparams: a dictionary recording any default assignparam assignments associated with the category.
# Note that deviations in user specifications to assignparam as part of an automunge(.) call
# take precedence over defaultparams. Note that when applying functionpointer defaultparams
# from the pointer target are also populated when not previously specified.
#___________________________________________________________________________
#defaultinfill: this option serves to specify a default infill
# applied after NArowtype data type casting and preceding the transformation function.
# (defaultinfill is a precursor to ML infill or other infills applied based on assigninfill)
# defaults to 'adjinfill' when not specified, can also pass as one of
# {'adjinfill', 'meaninfill', 'medianinfill', 'modeinfill', 'lcinfill',
# 'interpinfill', 'zeroinfill', 'oneinfill', 'naninfill', 'negzeroinfill'}
# Note that 'meaninfill' and 'medianinfill' only work with numeric data (based on NArowtype).
# Note that for 'datetime' NArowtype, defaultinfill only supports 'adjinfill' or 'naninfill'
# Note that 'naninfill' is intended for cases where user wishes to apply their own default infill
# as part of a custom_train entry
#___________________________________________________________________________
#dtype_convert: this option is intended for the custom_train convention, accepts boolean entries,
# defaults to True when not specified, False turns off a data type conversion
# that is applied after custom_train transformation functions based on MLinfilltype.
# May also be used to deactivate a floatprecision conversion for any category.
# This option primarily included to support special cases and not intended for wide use.
#___________________________________________________________________________
#labelctgy: an optional entry, should be a string entry of a single transformation category
# as entered in the family tree when the category of the processdict entry is used as a root category.
# Used to determine a basis of feature selection for cases where root
# category is applied to a label set resulting in a set returned in multiple configurations.
# Also used in label frequency levelizer.
# Note that since this is only used for small edge case populating a labelctgy entry is optional.
# If one is not assigned, an arbitrary entry will be accessed from the family tree.
# This option primarily included to support special cases.
#___________________________________________________________________________
#functionpointer: A functionpointer entry
# may be entered in lieu of any or all of these other entries **.
# The functionpointer should be populated with a category that has its own processdict entry
# (or a category that has its own process_dict entry internal to the library)
# The functionpointer inspects the pointer target and passes those specifications
# to the origin processdict entry unless previously specified.
# The functionpointer is intended as a shortcut for specifying processdict entries
# that may be helpful in cases where a new entry is very similar to some existing entry.
# (**As the exception labelctgy not accessed from functionpointer
# since it is specific to a root category's family tree.)
#___________________________________________________________________________
#noise_transform: this option serves to specify the noise injection types for noise transforms
# used to support an entropy seeding based on sampling_dict['sampling_type'] specification
# defaults to False when not specified, can also pass as one of
# {'numeric', 'categoric', 'binary', False}
# numeric is for transforms similar to DPnb/DPmm/DPrt which have a binomial and distribution sampling
# categoric is for transforms similar to DPod/DPmc which have a binomial and a choice sampling
# binary is for transforms similar to an alternate DPbn configuration which only have a binomial sampling
# False is for transforms without sampling_dict['sampling_type'] specification support
#___________________________________________________________________________
#Other clarifications:
#Note that NArowtype is associated with transformation inputs
#including for a category's use as a root category and as a tree category
#MLinfilltype is associated with transformation outputs
#for a category's use as a tree category
For example, to populate a custom transformation category 'newt' that uses internally defined transformation functions _process_mnmx and _postprocess_mnmx:
processdict = {'newt' : {'dualprocess' : am._process_mnmx,
'singleprocess' : None,
'postprocess' : am._postprocess_mnmx,
'NArowtype' : 'numeric',
'MLinfilltype' : 'numeric'}}
Note that these processing functions won't be applied when 'newt' is assigned as a root category to a column in assigncat, unless the category is also populated as an entry to one of the associated family tree primitives in the transformdict entry.
Note that all of the processing functions can be omitted or populated with values of None, as may be desired when the category is primarily intended for use as a root category and not a tree category. (If in such case the category is applied as a tree category when accessed no transforms will be applied and no downstream offspring will be inspected when applicable).
Optionally, some additional values can be incorporated into the processdict to support inversion for a transformation category:
#for example
processdict = {'newt' : {'dualprocess' : am._process_mnmx,
'singleprocess' : None,
'postprocess' : am._postprocess_mnmx,
'inverseprocess' : am._inverseprocess_mnmx,
'info_retention' : True,
'NArowtype' : 'numeric',
'MLinfilltype' : 'numeric'}}
#Where 'inverseprocess' is a function to invert the forward pass transformation.
#And 'info_retention' is boolean to signal True when there is full information retention
#in recovered data from inversion.
Optionally, a user can set alternate default assignparam parameters to be passed to the associated transformation functions by including the 'defaultparams' key. These updates to default parameters will still be overwritten if user manually specifies parameters in assignparam.
#for example to default to an alternate noise profile for DPmm
processdict = {'DLmm' : {'dualprocess' : am._process_DPmm,
'singleprocess' : None,
'postprocess' : am._postprocess_DPmm,
'inverseprocess' : am._inverseprocess_UPCS,
'info_retention' : True,
'defaultparams' : {'noisedistribution' : 'laplace'},
'NArowtype' : 'numeric',
'MLinfilltype' : 'numeric'}}
Since specification of transformation functions and other processdict entries can be kind of cumbersome in order to dig out from the codebase naming conventions e.g. for internally defined functions, a simplification is available when populating a processdict for a user passed entry by way of the 'functionpointer' entry. When a functionpointer category entry is included, the transformation functions and other entries that are not already specified are automatically populated based on entries found in processdict entries of the pointer. For cases where a functionpointer points to a processdict entry that itself has a functionpointer entry, chains of pointers are followed until an entry without functionpointer is reached. defaultparams entries of each pointer link are also accessed for update, and if the prior category specification contains any redundant defaultparams entries with those found in a pointer target category the prior category entries take precedence. Similarly for chains of pointers the entries specified in nearer links take precedence over entries further down the chain.
In other words, if you are populating a new processdict transformation category and you want the transformation functions and other entries to match an existing category, you can simply pass the existing category as a functionpointer entry to the new category. Here is an example if we want to match the DLmm category demonstrated above for a new category 'newt' but with an alternate 'NArowtype' as an arbitrary example, such as would be useful if we wanted to define an alternate DLmm family tree in a corresponding newt transformdict entry.
processdict = {'newt' : {'functionpointer' : 'DLmm',
'NArowtype' : 'positivenumeric'}}
Or an even simpler approach if no overwrites are desired could just be to copy everything.
processdict = {'newt' : {'functionpointer' : 'DLmm'}}
We can also use functionpointer when overwriting a category defined internal to library. For example, if we wanted to change the default parameters applied with the mnmx category, we could overwrite the mnmx process_dict entry such as to match the current entry but with updated defaultparams.
processdict = {'mnmx' : {'functionpointer' : 'mnmx',
'defaultparams' : {'floor' : True}}}
Note that processdict entries can be defined to overwrite existing category entries defined in the internal library. For example, if we wanted our default numerical scaling to be by min-max instead of z-score normalization, one way we could accomplish this is to overwrite the 'nmbr' transformation functions accessed from processdict, where nmbr is the default root category applied to numeric sets under automation, whose family tree has nmbr as a tree category entry for accessing the transformation functions. (Other default root categories under automation are detailed further below in the "Default Tranformations" section.) This approach differs from overwriting the nmbr transformdict entry as demonstrated above in that the update would be carried through to all instances where nmbr is accessed as a tree category across the library of family trees.
processdict = {'nmbr' : {'functionpointer' : 'mnmx'}}
Processing functions following the conventions of those defined internal to the library can be passed to dualprocess / singleprocess / postprocess / inverseprocess
Or for the greatly simplified conventions available for custom externally defined transformation functions can be passed to custom_train / custom_test / custom_inversion. Demonstrations for custom transformation functions are documented further below in the section Custom Transformation Functions. (Note that in cases of redundancy, populated custom_train functions take precedence over the dualprocess / singleprocess conventions). Note that the defaultinfill option is specific to the custom_train convention and also documented below.
Note that many of the transformation functions in the library have support for distinguishing between inplace operations vs returning a column copied from the input. Inplace operations are expected to reduce memory overhead. When not specified the library assumes a function supports the inplace option. Function passed in the custom_train convention automatically support inplace so specification is not required with user defined functions. For functions following the dualprocess/singleprocess conventions, some transforms may not support inplace, in which case a user will need to specify (although if using functionpointer to access the transforms this will be automatic).
#for example
processdict = {'newt' : {'dualprocess' : am._process_text,
'singleprocess' : None,
'postprocess' : am._postprocess_text,
'inverseprocess' : am._inverseprocess_text,
'info_retention' : True,
'inplace_option' : False,
'NArowtype' : 'justNaN',
'MLinfilltype' : 'multirt'}}
The optional labelctgy specification for a category's processdict entry is intended for use in featureselection when the category is applied as a root category to a label set and the category's family tree returns the labels in multiple configurations. The labelcty entry serves as a specification of a specific primitive entry category either as entered in the upstream primitives of the root category or one of the downstream primitives of subsequent generations, which primitive entry category will serve as the label basis when applying feature selection. (labelctgy is also inspected with oversampling in current implementation.)
Further detail on the processdict data format provided in the essay Data Structure.
- evalcat: modularizes the automated evaluation of column properties for assignment of root transformation categories, allowing user to pass custom functions for this purpose. Passed functions should follow format:
def evalcat(df, column, randomseed, eval_ratio, numbercategoryheuristic, powertransform, labels = False):
"""
#user defined function that takes as input a dataframe df and column id string column
#evaluates the contents of cells and classifies the column for root category of
#transformation (e.g. comparable to categories otherwise assigned in assigncat)
#returns category id as a string
"""
...
return category
And could then be passed to automunge function call such as:
evalcat = evalcat
I recommend using the _evalcategory function defined in master file as starting point. (Minus the 'self' parameter since defining external to class.) Note that the parameters eval_ratio, numbercategoryheuristic, powertransform, and labels are passed as user parameters in automunge(.) call and only used in _evalcategory function, so if user wants to repurpose them totally can do so. (They default to .5, 255, False, False.) Note evalcat defaults to False to use built-in _evalcategory function. Note evalcat will only be applied to columns not assigned in assigncat. (Note that columns assigned to 'eval' / 'ptfm' in assigncat will be passed to this function for evaluation with powertransform = False / True respectively.) Note that function currently uses python collections library and datetime as dt.
-
ppd_append: defaults to False, accepts as input a prior populated postprocess_dict for purposes of adding new features to a prior trained model. Basically the intent is that there are some specialized workflows where models in decision tree paradigms may have new features incorporated without retraining the model with the prior training data. In such cases a user may desire to add new features to a prior populated postprocess_dict to enable pushbutton preprocessing including the original training data basis coupled with basis of newly added features. In order to do so, automunge(.) should be called with just the new features passed as df_train, and the prior populated postprocess_dict passed to ppd_append. This will result in the newly populated postprocess_dict being saved as a new subentry in the returned original postprocess_dict, such that to prepare additional data including the original features and new features, they combined features can be colletively passed as df_test to postmunge(.) (which should have new features appended on right side of original features). postmunge(.) will prepare the original features and new features seperately, including a seperate basis for ML infill, Binary, and etc, and will return a combined prepared test data. Includes inversion support and support for performing more than one round of new feature appendings. Note that newly added features are limited to training features, labels and ID input should be excluded. Note that inversion numpy support not available with combined features and test feature inversion support is limited to the inversion='test' case. (If it is desired to include new features in the prior features' ML infill basis and visa versa, instead of applying ppd_append just pass everything to automunge(.) and populate a new postprocess_dict - noting this might justify retraining the original model due to a new ML infill basis of original features). (Note that when applied in conjunction with entropy_seeding for noise injection the same seeds will be applied with each set, for sampling_type's other than default we recommend sampling internally with a custom generator as opposed to passing externally sampled seeds.). Please note that ppd_append not supported in conjunction with activating dupl_rows postmunge parameter.
-
entropy_seeds: defaults to False, accepts integer or list / flattened array of integers which may serve as supplemental sources of entropy for noise injections with DP transforms, we suggest integers in range {0:(2 ** 31 - 1)} to align with int32 dtype. entropy_seeds are specific to an automunge(.) or postmunge(.) call, in other words they are not returned in the populated postprocess_dict. Please note that for determinatino of how many entropy seeds are needed for various sampling_dict['sampling_type'] scenarios, can inspect postprocess_dict['sampling_report_dict'], where if insufficient seeds are available for these scenarios additional seeds will be derived with the extra_seed_generator. Note that the sampling_report_dict will report requirements separately for train and test data and in the bulk_seeds case will have a row count basis. (If not passing test data to automunge(.) the test budget can be omitted.) Note that the entropy seed budget only accounts for preparing one set of data, for the noise_augment option we recommend passing a custom extra_seed_generator with a sampling_type specification, which will result in internal samplings of additional entropy seeds for each additional noise_augment duplicate (or for the bulk_seeds case with external sampling can increased entropy_seed budget proportional to the number of additional duplicates with noise).
-
random_generator: defaults to False, accepts numpy.random.Generator formatted random samplers which are applied for noise injections with DP transforms. Note that random_generator may optionally be applied in conjunction with entropy_seeds. When not specified applies numpy.random.PCG64. Examples of alternate generators could be a generator initialized with the QRAND library to sample from a quantum circuit. Or if the alternate library does not have numpy.random support, their output can be channeled as entropy_seeds for a similar benefit. random_generator is specific to an automunge(.) or postmunge(.) call, in other words it is not returned in the populated postprocess_dict. Please note that numpy formatted generators of both forms e.g. np.random.PCG64 or np.random.PCG64() may be passed, in the latter case any entropy seeding to this generator will be turned off automatically.
-
sampling_dict: defaults to False, accepts a dictionary including possible keys of {sampling_type, seeding_type, sampling_report_dict, stochastic_count_safety_factor, extra_seed_generator, sampling_generator}. sampling_dict is specific to an automunge(.) or postmunge(.) call, in other words they are not returned in the populated postprocess_dict.
- sampling_dict['sampling_type'] accepts a string as one of {'default', 'bulk_seeds', 'sampling_seed', 'transform_seed'}
- default: every sampling receives a common set of entropy_seeds per user specification which are shuffled and passed to each call
- bulk_seeds: every sampling receives a unique supplemental seed for every sampled entry for sampling from sampling_generator (expended seed counts dependent on train/test/both configuration and numbers of rows). This scenario also defaults to sampling_dict['seeding_type'] = 'primary_seeds'
- sampling_seed: every sampling operation receives one supplemental seed for sampling from sampling_generator (expended seed counts dependent on train/test/both configuration)
- transform_seed: every noise transform receives one supplemental seed for sampling from sampling_generator (expended seed counts are the same independant of train/test/both configuration)
- sampling_dict['seeding_type'] defaults to 'supplemental_seeds' or 'primary_seeds' as described below, where 'supplemental_seeds' means that entropy seeds are integrated into np.random.SeedSequence with entropy seeding from the operating system. Also accepts 'primary_seeds', in which user passed entropy seeds are the only source of seeding. Please note that 'primary_seeds' is used as the default for the bulk_seeds sampling_type and 'supplemental_seeds' is used as the default for other sampling_type options.
- sampling_dict['sampling_report_dict'] defaults as False, accepts a prior populated postprocess_dict['sampling_report_dict'] from an automunge(.), call if this is not received it will be generated internally. sampling_report_dict is a resource for determining how many entropy_seeds are needed for various sampling_type scnearios.
- sampling_dict['stochastic_count_safety_factor']: defaults to 0.15, accepts float 0-1, is associated with the bulk_seeds sampling_type case and is used as a multiplier for number of seeds populated for sampling operations with a stochastic number of entries
- sampling_dict['sampling_generator']: used to specify which generator will be used for sampling operations other than generation of additional entropy_seeds. defaults to 'custom' (meaning the passed random_generator or when unspecified the default PCG64), and accepts one of {'custom', 'PCG64', 'MersenneTwister'}
- sampling_dict['extra_seed_generator']: used to specify which generator will be used to sample additional entropy_seeds when more are needed to meet requirements of sampling_report_dict, defaults to 'custom' (meaning the passed random_generator or when unspecified the default PCG64), and accepts one of {'custom', 'PCG64', 'MersenneTwister', 'off', 'sampling_generator'}, where sampling_generator matches specification for sampling_generator, and 'off' turns off sampling of additional entropy seeds.
- sampling_dict['sampling_type'] accepts a string as one of {'default', 'bulk_seeds', 'sampling_seed', 'transform_seed'}
-
privacy_encode: a boolean marker {True, False, 'private'} defaults to False. For cases where sets are returned as pandas dataframe, a user may desire privacy preserving encodings in which column headers of received data are anonymized. This parameter when activated as True shuffles the order of columns and replaces headers and suffixes with integers. ID sets are not anonymized. Label sets are only anonymized in the 'private' scenario. Note that conversion information is available in returned postprocess_dict under privacy reports (in other words, privacy can be circumvented if user has access to an unencrypted postprocess_dict). When activated the postprocess_dict returned columntype_report captures the privacy encodings and the column_map is erased. Note that when activated consistent convention is applied in postmunge and inversion is supported. When privacy_encode is activated postmunge(.) printstatus is only available as False or 'silent'. The 'private' option also activates shuffling of rows in train and test data for both automunge(.) and postmunge(.) and resets the dataframe indexes (although retains the Automunge_index column returned in the ID set). Thus prepared data in the 'private' option can be kept row-wise anonymous by not sharing the returned ID set. We recommend considering use of the encrypt_key parameter in conjunction with privacy_encode. Please note that when privacy_encode is activated postmunge options for featureeval and driftreport are not available to avoid data leakage channel. It may be beneficial in privacy sensitive applications to inject noise via DP transforms and apply distribution conversions to numeric features e.g. via DPqt or DPbx. Further detail on privacy encoding provided in the essay Private Encodings with Automunge.
-
encrypt_key: as one of {False, 16, 24, 32, bytes} (where bytes means a bytes type object with length of 16, 24, or 32) defaults to False, other scenarios all result in an encryption of the returned postprocess_dict. 16, 24, and 32 refer to the block size, where block size of 16 aligns with 128 bit encryption, 32 aligns with 256 bit. When encrypt_key is passed as an integer, a returned encrypt_key is derived and returned in the closing printouts. This returned printout should be copied and saved for use with the postmunge(.) encrypt_key parameter. In other words, without this encryption key, user will not be able to prepare additional data in postmunge(.) with the returned postprocess_dict. When encrypt_key is passed as a bytes object (of length 16, 24, or 32), it is treated as a user specified encryption key and not returned in printouts. When data is encrypted, the postprocess_dict returned from automunge(.) is still a dictionary that can be downloaded and uploaded with pickle, and based on which scenario was selected by the privacy_encode parameter (for scenarios other than 'private'), the returned postprocess_dict will contain some public entries that are not encrypted, such as ['columntype_report', 'label_columntype_report', 'privacy_encode', 'automungeversion', 'labelsencoding_dict', 'FS_sorted', 'column_map', 'sampling_report_dict'] - where FS_sorted and column_map are ommitted when privacy_encode is not False and all public entries are omitted when privacy_encode = 'private'. The encryption key, as either returned in printouts or based on user specification, can then be passed to the postmunge(.) encrypt_key parameter to prepare additional data. The only postmunge operation available without the encryption key is for label inverison (unless privacy_encode is 'private'). Thus privacy_encode may be fully private, and a user with access to the returned postprocess_dict will not be able to invert training data without the encryption key. Please note that the AES encryption is applied with the pycrypto python library which requires installation in order to run (we found there were installations available via conda install).
-
printstatus: user can pass True/False/'summary'/'silent' indicating whether the function will print status of processing during operation. Defaults to 'summary' to return a summary of returned sets and any feature importance or drift reports. True returns all printouts. When False only error message printouts generated. When 'summary' only reports and summary are printed. When 'silent' no printouts are generated. Note that all of these scenarios are also available by the logger parameter regardless of printstatus setting.
-
logger: user can initialize a dictionary externally, e.g. logger={}, and pass it to this parameter, e.g. logger=logger. automunge(.) will then log every printout scenario and validation result as they are being accessed in this external dictionary, which can then either be inspected for troubleshooting in cases of a halt scenario or archived. The report scenarios are loosely aligned with python logging module and also related to the tiers of printstatus.
logger = {}
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train,
logger=logger,
printstatus='silent')
#and then, e.g.
print(logger['debug_report'])
print(logger['info_report'])
print(logger['warning_report'])
#or validation results available in logger['validations']
Ok well we'll demonstrate further below how to build custom transformation functions, for now you should have sufficient tools to build sets of transformation categories using the family tree primitives and etc.
...
postmunge(.)
The postmunge(.) function is intended to consistently prepare subsequently available and consistently formatted train or test data with just a single function call. It requires passing the postprocess_dict object returned from the original application of automunge and that the passed test data have consistent column header labeling as the original train set (or for Numpy arrays consistent order of columns). Processing data with postmunge(.) is considerably more efficient than automunge(.) since it does not require the overhead of the evaluation methods, the derivation of transformation normalization parameters, and/or the training of models for ML infill.
#for postmunge(.) function to prepare subsequently available data
#using the postprocess_dict object returned from original automunge(.) application
#Remember to initialize automunge
from Automunge import *
am = AutoMunge()
#Then we can run postmunge function as:
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test,
testID_column = False,
pandasoutput = 'dataframe', printstatus = 'summary', inplace = False,
dupl_rows = False, TrainLabelFreqLevel = False,
featureeval = False, traindata = False, noise_augment = 0,
driftreport = False, inversion = False,
returnedsets = True, shuffletrain = False,
entropy_seeds = False, random_generator = False, sampling_dict = False,
randomseed = False, encrypt_key = False, logger = {})
Or to run postmunge(.) with default parameters we simply need the postprocess_dict object returned from the corresponding automunge(.) call and a consistently formatted additional data set.
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test)
postmunge(.) returned sets:
Here now are descriptions for the returned sets from postmunge, which will be followed by descriptions of the parameters which can be passed to the function. Default is that returned sets are pandas dataframes, with single column sets returned as pandas series.
For dataframes, data types of returned columns are based on the transformation applied, for example columns with boolean integers are cast as int8, ordinal encoded columns are given a conditional type based on the size of encoding space as either uint8, uint16, or uint32. Continuous sets are cast as float16, float32, or float64 based on the automunge(.) floatprecision parameter. And direct passthrough columns via excl transform retain the received data type.
-
test: the set of features, consistently encoded and normalized as the training data, that can be used to generate predictions from a model trained with the train set from automunge.
-
test_ID: the set of ID values corresponding to the test set. Also included in this set is a derived column titled 'Automunge_index', this column serves as an index identifier for order of rows as they were received in passed data, such as may be beneficial when data is shuffled. For more information please refer to writeup for the testID_column parameter. If the received df_test had a non-ranged integer index, it is extracted and returned in this set.
-
test_labels: a set of numerically encoded labels corresponding to the test set if a label column was passed. Note that the function assumes the label column is originally included in the train set. Note that if the labels set is a single column a returned dataframe is flattened to a pandas Series or a returned Numpy array is also flattened (e.g. [[1,2,3]] converted to [1,2,3] ).
-
postreports_dict: a dictionary containing entries for following:
- postreports_dict['featureimportance']: results of optional feature importance evaluation based on parameter featureeval. (See automunge(.) notes above for feature importance printout methods.)
- postreports_dict['finalcolumns_test']: list of columns returned from postmunge
- postreports_dict['driftreport']: results of optional drift report evaluation tracking properties of postmunge data in comparison to the original data from automunge call associated with the postprocess_dict presumably used to train a model. Results aggregated by entries for the original (pre-transform) list of columns, and include the normalization parameters from the automunge call saved in postprocess_dict as well as the corresponding parameters from the new data consistently derived in postmunge
- postreports_dict['sourcecolumn_drift']: results of optional drift report evaluation tracking properties of postmunge data derived from source columns in comparison to the original data from automunge(.) call associated with the postprocess_dict presumably used to train a model.
- postreports_dict['pm_miscparameters_results']: reporting results of validation tests performed on parameters and passed data
#the results of a postmunge driftreport assessment are returned in the postreports_dict
#object returned from a postmunge call, as follows:
postreports_dict = \
{'featureimportance':{(not shown here for brevity)},
'finalcolumns_test':[(derivedcolumns)],
'driftreport': {(sourcecolumn) : {'origreturnedcolumns_list':[(derivedcolumns)],
'newreturnedcolumns_list':[(derivedcolumns)],
'drift_category':(category),
'orignotinnew': {(derivedcolumn):{'orignormparam':{(stats)}},
'newnotinorig': {(derivedcolumn):{'newnormparam':{(stats)}},
'newreturnedcolumn':{(derivedcolumn):{'orignormparam':{(stats)},
'newnormparam':{(stats)}}}},
'rowcount_basis': {'automunge_train_rowcount':#, 'postmunge_test_rowcount':#},
'sourcecolumn_drift': {'orig_driftstats': {(sourcecolumn) : (stats)},
'new_driftstats' : {(sourcecolumn) : (stats)}}}
#the driftreport stats for derived columns are based on the normalization_dict entries from the
#corresponding processing function associated with that column's derivation
#here is an example of source column drift assessment statistics for a positive numeric root category:
postreports_dict['sourcecolumn_drift']['new_driftstats'] = \
{(sourcecolumn) : {'max' : (stat),
'quantile_99' : (stat),
'quantile_90' : (stat),
'quantile_66' : (stat),
'median' : (stat),
'quantile_33' : (stat),
'quantile_10' : (stat),
'quantile_01' : (stat),
'min' : (stat),
'mean' : (stat),
'std' : (stat),
'MAD' : (stat),
'skew' : (stat),
'shapiro_W' : (stat),
'shapiro_p' : (stat),
'nonpositive_ratio' : (stat),
'nan_ratio' : (stat)}}
...
postmunge(.) passed parameters
#for postmunge(.) function on subsequently available test data
#using the postprocess_dict object returned from original automunge(.) application
#Remember to initialize automunge
from Automunge import *
am = AutoMunge()
#Then we can run postmunge function as:
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test,
testID_column = False,
pandasoutput = 'dataframe', printstatus = 'summary', inplace = False,
dupl_rows = False, TrainLabelFreqLevel = False,
featureeval = False, traindata = False, noise_augment = 0,
driftreport = False, inversion = False,
returnedsets = True, shuffletrain = False,
entropy_seeds = False, random_generator = False, sampling_dict = False,
randomseed = False, encrypt_key = False, logger = {})
-
postprocess_dict: this is the dictionary returned from the initial application of automunge(.) which included normalization parameters to facilitate consistent processing of additional train or test data to the original processing of the train set. This requires a user to remember to download the dictionary at the original application of automunge, otherwise if this dictionary is not available a user can feed this subsequent test data to the automunge along with the original train data exactly as was used in the original automunge(.) call.
-
df_test: a pandas dataframe or numpy array containing a structured dataset intended for use to generate predictions from a machine learning model trained from the automunge returned sets. The set must be consistently formatted as the train set with consistent order of columns and if labels are included consistent labels. If desired the set may include an ID column. The tool supports the inclusion of non-index-range column as index or multicolumn index (requires named index columns). Such index types are added to the returned "ID" sets which are consistently shuffled and partitioned as the train and test sets. If numpy array passed any ID columns from train set should be included. Note that if a label column is included consistent with label column from automunge(.) call it will be automatically applied as label and similarly for ID columns. If desired can also be passed as a dataframe with only the label columns and features ommitted.
-
testID_column: defaults to False, user can pass a column header or list of column headers for columns that are to be segregated from the df_test set for return in the test_ID set (consistently shuffled and partitioned when applicable). For example this may be desired for an index column or any other column that the user wishes to exclude from the ML infill basis. Defaults to False, which can be used for cases where the df_test set does not contain any ID columns, or may also be passed as the default of False when the df_test ID columns match those passed to automunge(.) in the trainID_column parameter, in which case they are automatically given comparable treatment. Thus, the primary intended use of the postmunge(.) testID_column parameter is for cases where a df_test has ID columns different from those passed with df_train in automunge(.). Note that an integer column index or list of integer column indexes may also be passed such as if the source dataset was a numpy array. (In general though when passing data as numpy arrays we recommend matching ID columns to df_train.) In cases of unnamed non-range integer indexes, they are automatically extracted and returned in the ID sets as 'Orig_index'. If a user would like to include a column both in the features for encoding and the ID sets for original form retention, they can pass testID_column as a list of two lists, e.g. [list1, list2], where the first list may include ID columns to be struck from the features and the second list may include ID columns to be retained in the features. (We recommend only using testID_column specification for cases where df_test includes columns that weren't present in the original df_train, otehrwise it is automatic.)
-
pandasoutput: selects format of returned sets. Defaults to 'dataframe' for returned pandas dataframe for all sets. Dataframes index is not always preserved, non-integer indexes are extracted to the ID sets, and automunge(.) generates an application specific range integer index in ID sets corresponding to the order of rows as they were passed to function). If set to True, features and ID sets are comparable, and single column label sets are converted to Pandas Series instead of dataframe. If set to False returns numpy arrays instead of dataframes. Note that the dataframes will have column specific data types, or returned numpy arrays will have a single data type.
-
printstatus: user can pass True/False/'summary'/'silent' indicating whether the function will print status of processing during operation. Defaults to 'summary' to return a summary of returned sets and any feature importance or drift reports. True returns all printouts. When False only error message printouts generated. When 'summary' only reports and summary are printed. When 'silent' no printouts are generated.
-
inplace: defaults to False, when True the df_test passed to postmunge(.) is overwritten with the returned test set. This reduces memory overhead. For example, to take advantage with reduced memory overhead you could call postmunge(.) as:
df_test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test, inplace = True)
-
dupl_rows: can be passed as (True/False) which indicates if duplicate rows will be consolidated to single instance in returned sets. (In other words, if same row included more than once, it will only be returned once.) Defaults to False for not activated. True applies consolidation to test set. Note this is applied prior to TrainLabelFreqLevel if elected. As implemented this does not take into account duplicate rows in test data which have different labels, only one version of features/label pair is returned. Please note dupl_rows option not recommended in cases where automunge(.) applied the ppd_append option and will return a printout and validation result as dupl_rows_ppd_append_postmunge_valresult.
-
TrainLabelFreqLevel: a boolean identifier (True/False) which indicates if the TrainLabelFreqLevel method will be applied to oversample test data associated with underrepresented labels. The method adds multiples to test data rows for those labels with lower frequency resulting in an (approximately) levelized frequency. This defaults to False. Note that this feature may be applied to numerical label sets if the assigncat processing applied to the set in automunge(.) had included aggregated bins, such as for example 'exc3' for pass-through numeric with standard deviation bins, or 'exc4' for pass-through numeric with powers of ten bins. Note this method requires the inclusion of a designated label column. Further detail on oversampling provided in the essay Oversampling with Automunge.
-
featureeval: a boolean identifier (True/False) to activate a feature importance evaluation, comparable to one performed in automunge but based on the test set passed to postmunge. Defaults to False. The results are returned in the postreports_dict object returned from postmunge as postreports_dict['featureimportance']. The results will also be printed out if printstatus is activated. Note that sorted feature importance results are returned in postreports_dict['FS_sorted'], including columns sorted by metric and metric2. Relies on ML_cmnd parameters from original automunge(.) call.
-
driftreport: defaults to False, accepts one of {False, True, 'efficient', 'report_effic', 'report_full'}. Activates a drift report evaluation, in which drift statistics are collected for comparison between features in the train data that was passed to automunge(.) verses test data passed to postmunge(.). May include drift statistics associated with the raw data found in the input features, and may also include drift statistics associated with the returned data derived features as collected during derivations and recorded in the normalization parameters of a transformation. The results are returned in the postreports_dict object returned from postmunge as postreports_dict['driftreport'] and postreports_dict['sourcecolumn_drift']. Additional drift statistics for columns returned from a PCA or Binary dimensionality reduction are available in conjunction with the driftreport = True scenario, which are returned in postreports_dict['dimensionality_reduction_driftstats']. The results will also be printed out if printstatus is activated. Defaults to False, and:
- False means no postmunge drift assessment is performed
- True means an assessment is performed for both the source column and derived column stats
- 'efficient' means that a postmunge drift assessment is only performed on the source columns (less information but better latency / computational efficiency)
- 'report_effic' means that the efficient assessment is performed (only source column stats) and returned with no processing of data
- 'report_full' means that the full assessment is performed for both the source column and derived column and returned with no processing of data Note that for transforms returning multi column sets, the drift stats will only be reported for first column in the categorylist. Note that driftreport is not available in conjunction with privacy encoding. Further detail on drift reports are provided in the essay Drift Reporting with Automunge.
-
inversion: defaults to False, may be passed as one of {False, 'test', 'labels', 'denselabels', a list, or a set}, where ‘test’ or ‘labels’ activate an inversion operation to recover, by a set of transformations mirroring the inversion of those applied in automunge(.), the form of test data or labels data to consistency with the source columns as were originally passed to automunge(.). As further clarification, passing inversion='test' should be in conjunction with passing df_test = test (where test is a dataframe of train or test data returned from an automunge or postmunge call), and passing inversion='labels' should be in conjunction with passing df_test = test_labels (where test_labels is a dataframe of labels or test_labels returned from an automunge or postmunge call). When inversion is passed as a list, accepts list of source column or returned column headers for inversion targets. When inversion is passed as a set, accepts a set with single entry of a returned column header serving as a custom target for the inversion path. (inversion list or set specification not supported when the automunge(.) privacy_encode option was activated.) 'denselabels' is for label set inversion in which labels were prepared in multiple formats, such as to recover the original form on each basis for comparison (currently supported for single labels_column case). The inversion operation is supported by the optional process_dict entry 'info_retention' and required for inversion process_dict entry 'inverseprocess' (or 'custom_inversion'). Note that columns are only recovered for those sets in which a path of inversion was available by these processdict entries. Note that the path of inversion is prioritized to those returned sets with information retention and availability of inverseprocess functions. Note that both feature importance and Binary dimensionality reduction is supported, support is not expected for PCA. Note that recovery of label sets with label smoothing is supported. Note that during an inversion operation the postmunge function only considers the parameters postprocess_dict, df_test, inversion, pandasoutput, and/or printstatus. Note that in an inversion operation the postmunge(.) function returns three sets: a recovered set, a list of recovered columns, and a dictionary logging results of the path selection process and validation results. Please note that the general convention in library is that entries not successfully recovered from inversion may be recorded corresponding to the imputation value from the forward pass, NaN, or some other transformation function specific convention. Further details on inversion is provided in the essay Announcing Automunge Inversion.
Here is an example of a postmunge call with inversion.
df_invert, recovered_list, inversion_info_dict = \
am.postmunge(postprocess_dict, test_labels, inversion='labels',
pandasoutput=True, printstatus='summary', encrypt_key = False)
Here is an example of a process_dict entry with the optional inversion entries included, such as may be defined by user for custom functions and passed to automunge(.) in the processdict parameter:
process_dict.update({'mnmx' : {'dualprocess' : self.process_mnmx,
'singleprocess' : None,
'postprocess' : self.postprocess_mnmx,
'inverseprocess' : self.inverseprocess_mnmx,
'info_retention' : True,
'NArowtype' : 'numeric',
'MLinfilltype' : 'numeric',
'labelctgy' : 'mnmx'}})
-
traindata: boolean {True, False, 'train_no_noise', 'test_no_noise'}, defaults to False. Only inspected when a transformation is called that treats train data different than test data (currently only relevant to DP family of transforms for noise injection to train sets or label smoothing transforms in smth family). When passed as True treats df_test as a train set for purposes of these specific transforms, otherwise default of False treats df_test as a test set (which turns off noise injection for DP transforms). As you would expect, 'train_no_noise' and 'test_no_noise' designates data passed to postmunge(.) as train or test data but turns off noise injections.
-
noise_augment: accepts type int or float(int) >=0. Defaults to 0. Used to specify a count of additional duplicates of test data prepared and concatenated with the original test set. Intended for use in conjunction with noise injection, such that the increased size of training corpus can be a form of data augmentation. Takes into account the traindata parameter passed to postmunge(.) for distinguishing whether to treat the duplicates as train or test data for purposes of noise injections. Note that injected noise will be uniquely randomly sampled with each duplicate. When noise_augment is received as a dtype of int, one of the duplicates will be prepared without noise. When noise_augment is received as a dtype of float(int), all of the duplicates will be prepared with noise. When shuffletrain is activated the duplicates are collectively shuffled, and can distinguish between duplicates by the original df_test.shape in comparison to the ID set's Automunge_index. Please be aware that with large dataframes a large duplicate count may run into memory constraints, in which case additional duplicates can be prepared in additional postmunge(.) calls. Note that the entropy seed budget only accounts for preparing one set of data, for the noise_augment option with entropy seeding we recommend passing a custom extra_seed_generator with a sampling_type specification, which will result in internal samplings of additional entropy seeds for each additional noise_augment duplicate (or for the bulk_seeds case with external sampling can increase entropy_seed budget proportional to the number of additional duplicates with noise).
-
returnedsets: Can be passed as one of {True, False, 'test_ID', 'test_labels', 'test_ID_labels'}. Designates the composition of the sets returned from a postmunge(.) call. Defaults to True for the full composition of five returned sets. With other options postmunge(.) only returns a single set, where for False that set consists of the test set, or for the other options returns the test set concatenated with the ID, labels, or both. For example:
#in default of returnedsets=True, postmunge(.) returns five sets, such as this call:
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test, returnedsets = True)
#for other returnedset options, postmunge(.) returns just a single set, the test set:
test = \
am.postmunge(postprocess_dict, df_test, returnedsets = False)
#Note that if you want to access the column labels for an appended ID or labels set,
#They can be accessed in the postprocess_dict under entries for
postprocess_dict['finalcolumns_labels']
postprocess_dict['finalcolumns_trainID']
-
shuffletrain: can be passed as one of {True, False} which indicates if the rows in the returned sets will be (consistently) shuffled. This value defaults to False.
-
entropy_seeds: defaults to False, accepts integer or list / flattened array of integers which may serve as supplemental sources of entropy for noise injections with DP transforms, we suggest integers in range {0:(2 ** 31 - 1)} to align with int32 dtype. entropy_seeds are specific to an automunge(.) or postmunge(.) call, in other words they are not returned in the populated postprocess_dict. Please note that for determinatino of how many entropy seeds are needed for various sampling_dict['sampling_type'] scenarios, can inspect postprocess_dict['sampling_report_dict'], where if insufficient seeds are available for these scenarios additional seeds will be derived with the extra_seed_generator. Note that the sampling_report_dict will report requirements separately for train and test data and in the bulk_seeds case will have a row count basis. (If not passing test data to automunge(.) the test budget can be omitted.) Note that the entropy seed budget only accounts for preparing one set of data, for the noise_augment option we recommend passing a custom extra_seed_generator with a sampling_type specification, which will result in internal samplings of additional entropy seeds for each additional noise_augment duplicate (or for the bulk_seeds case with external sampling can increased entropy_seed budget proportional to the number of additional duplicates with noise).
-
random_generator: defaults to False, accepts numpy.random.Generator formatted random samplers which are applied for noise injections with DP transforms. Note that random_generator may optionally be applied in conjunction with entropy_seeds. When not specified applies numpy.random.PCG64. Examples of alternate generators could be a generator initialized with the QRAND library to sample from a quantum circuit. Or if the alternate library does not have numpy.random support, their output can be channeled as entropy_seeds for a similar benefit. random_generator is specific to an automunge(.) or postmunge(.) call, in other words it is not returned in the populated postprocess_dict. Please note that numpy formatted generators of both forms e.g. np.random.PCG64 or np.random.PCG64() may be passed, in the latter case any entropy seeding to this generator will be turned off automatically.
-
sampling_dict: defaults to False, accepts a dictionary including possible keys of {sampling_type, seeding_type, sampling_report_dict, stochastic_count_safety_factor, extra_seed_generator, sampling_generator}. sampling_dict is specific to an automunge(.) or postmunge(.) call, in other words they are not returned in the populated postprocess_dict.
- sampling_dict['sampling_type'] accepts a string as one of {'default', 'bulk_seeds', 'sampling_seed', 'transform_seed'}
- default: every sampling receives a common set of entropy_seeds per user specification which are shuffled and passed to each call
- bulk_seeds: every sampling receives a unique supplemental seed for every sampled entry for sampling from sampling_generator (expended seed counts dependent on train/test/both configuration and numbers of rows). This scenario also defaults to sampling_dict['seeding_type'] = 'primary_seeds'
- sampling_seed: every sampling operation receives one supplemental seed for sampling from sampling_generator (expended seed counts dependent on train/test/both configuration)
- transform_seed: every noise transform receives one supplemental seed for sampling from sampling_generator (expended seed counts are the same independant of train/test/both configuration)
- sampling_dict['seeding_type'] defaults to 'supplemental_seeds' or 'primary_seeds' as described below, where 'supplemental_seeds' means that entropy seeds are integrated into np.random.SeedSequence with entropy seeding from the operating system. Also accepts 'primary_seeds', in which user passed entropy seeds are the only source of seeding. Please note that 'primary_seeds' is used as the default for the bulk_seeds sampling_type and 'supplemental_seeds' is used as the default for other sampling_type options.
- sampling_dict['sampling_report_dict'] defaults as False, accepts a prior populated postprocess_dict['sampling_report_dict'] from an automunge(.), call if this is not received it will be generated internally. sampling_report_dict is a resource for determining how many entropy_seeds are needed for various sampling_type scnearios.
- sampling_dict['stochastic_count_safety_factor']: defaults to 0.15, accepts float 0-1, is associated with the bulk_seeds sampling_type case and is used as a multiplier for number of seeds populated for sampling operations with a stochastic number of entries
- sampling_dict['sampling_generator']: used to specify which generator will be used for sampling operations other than generation of additional entropy_seeds. defaults to 'custom' (meaning the passed random_generator or when unspecified the default PCG64), and accepts one of {'custom', 'PCG64', 'MersenneTwister'}
- sampling_dict['extra_seed_generator']: used to specify which generator will be used to sample additional entropy_seeds when more are needed to meet requirements of sampling_report_dict, defaults to 'custom' (meaning the passed random_generator or when unspecified the default PCG64), and accepts one of {'custom', 'PCG64', 'MersenneTwister', 'off', 'sampling_generator'}, where sampling_generator matches specification for sampling_generator, and 'off' turns off sampling of additional entropy seeds.
- sampling_dict['sampling_type'] accepts a string as one of {'default', 'bulk_seeds', 'sampling_seed', 'transform_seed'}
-
randomseed: defaults as False, also accepts integers within 0:2**31-1. When not specified, randomseed is based on a uniform randomly sampled integer within that range using an entropy_seeds when available. This value is used as the postmunge(.) seed of randomness for operations that don't require matched random seeding to automunge(.).
-
encrypt_key: when the postprocess_dict was encrypted by way of the corresponding automunge(.) encrypt_key parameter, a key is either derived and returned in the closing automunge(.) printouts, or a key is based on user specification. To prepare additional data in postmunge(.) with the encrypted postprocess_dict requires passing that key to the postmunge(.) encrypt_key parameter. Defaults to False for when encryption was not performed, other accepts a bytes type object with expected length of 16, 24, or 32. Please note that the AES encryption is applied with the pycrypto python library which requires installation in order to run (we found there were installations available via conda install).
-
logger: user can initialize a dictionary externally (e.g. logger={}) and then pass it to this parameter (e.g. logger=logger). postmunge(.) will then log every printout scenario and validation result as they are being accessed in this external dictionary, which can then either be inspected for troubleshooting in cases of a halt scenario or archived. The report scenarios are loosely aligned with python logging module and also related to the tiers of printstatus.
logger = {}
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict,
df_test,
logger=logger,
printstatus='silent')
#and then, e.g.
print(logger['debug_report'])
print(logger['info_report'])
print(logger['warning_report'])
#or validation results available in logger['validations']
Default Transformations
When root categories of transformations are not assigned for a given column in assigncat, automunge performs an evaluation of data properties to infer appropriate means of feature engineering and numerical encoding. The default categories of transformations are as follows:
- nmbr: for numeric data, columns are treated with z-score normalization. If binstransform parameter was activated this will be supplemented by a collection of bins indicating number of standard deviations from the mean. Note that default infill performed prior to ML infill is imputation with negative zero. The exception is for numeric data received in a column with pandas 'categoric' data type, which are instead binarized consistent to categoric sets (as 1010 or bnry). Note that numerical sets with 2 unique values in train set default to bnry. Note that features with majority str(int/float) entries are also treated as numeric.
- 1010: for categorical data excluding special cases described following, columns are subject to binarization encoding via '1010' (e.g. for majority str or bytes type entries). If the number of unique entries in the column exceeds the parameter 'numbercategoryheuristic' (which defaults to 255), the encoding will instead be by hashing. Note that for default infill missing data has a distinct representation in the encoding space. Note that features with majority str(int/float) entries are treated as numeric.
- bnry: for categorical data of <=2 unique values excluding infill (e.g. NaN), the column is encoded to 0/1. Note that numerical sets with 2 unique values in train set also default to bnry.
- hsh2: for categorical data, if the number of unique entries in the column exceeds the parameter 'numbercategoryheuristic' (which defaults to 255), the encoding will instead be by 'hsh2' which is an ordinal (integer) encoding based on hashing. hsh2 is excluded from ML infill.
- hash: for all unique entry categoric sets (based on sets with >75% unique entries), the encoding will be by hash which extracts distinct words within entries returned in a set of columns with an integer hashing. hash is excluded from ML infill. Note that for edge cases with large string entries resulting in too high dimensionality, the max_column_count parameter can be passed to default_assignparam in assignparam to put a cap on returned column count.
- dat6: for time-series data, a set of derivations are performed returning 'year', 'mdsn', 'mdcs', 'hmss', 'hmsc', 'bshr', 'wkdy', 'hldy' (these are defined in next section)
- null: for columns without any valid values in training set (e.g. all NaN) column is deleted
For label sets, we use a distinct set of root categories under automation. These are in some cases comparable to those listed above for training data, but differ in that the label sets will not include a returned 'NArw' (infill marker) even when parameter NArw_marker passed as True.
- lbnb: for numerical data, a label set is treated with an 'nmbr' z-score normalization.
- lbor: for categoric data of >2 unique values, a label set is treated with an ordinal encoding similar to 'ord3' ordinal encoding (frequency sorted order of encodings). lbor differs from ord3 in that missing data does not receive a distinct encoding and is instead grouped into the 0 activation (consistent with the ord3 parameter setting null_activation=False).
- lbbn: for categoric data of <3 unique values, a label set is treated with an 'bnry' binary encoding (single column binary), also applied to numeric sets with 2 unique values
Other label categories are available for assignment in assigncat, described below in the library of transforms section for label set encodings.
Note that if a user wishes to avoid the automated assignment of default transformations, such as to leave those columns not specifically assigned to transformation categories in assigncat as unchanged, the powertransform parameter may be passed as values 'excl' or 'exc2', where for 'excl' columns not explicitly assigned to a root category in assigncat will be left untouched, or for 'exc2' columns not explicitly assigned to a root category in assigncat will be forced to numeric and subject to default modeinfill. (These two excl arguments may be useful if a user wants to experiment with specific transforms on a subset of the columns without incurring processing time of an entire set.) This option may interfere with ML infill if data is not all numerically encoded.
If the data is already numerically encoded with NaN entries for missing data, ML infill can be applied without further preprocessing transformations by passing powertransform = 'infill'.
Note that for columns designated for label sets as a special case categorical data will default to 'ordl' (ordinal encoding) instead of '1010'. Also, numerical data will default to 'excl2' (pass-through) instead of 'nmbr'.
-
powertransform: if the powertransform parameter is activated, a statistical evaluation will be performed on numerical sets to distinguish between columns to be subject to bxcx, nmbr, or mnmx. Please note that we intend to further refine the specifics of this process in future implementations. Additionally, powertransform may be passed as values 'excl' or 'exc2', where for 'excl' columns not explicitly assigned to a root category in assigncat will be left untouched, or for 'exc2' columns not explicitly assigned to a root category in assigncat will be forced to numeric and subject to default modeinfill. (These two excl arguments may be useful if a user wants to experiment with specific transforms on a subset of the columns without incurring processing time of an entire set for instance.) To default to noise injection to numeric and (non-hashed) categoric, can apply 'DP1' or 'DP2', (or 'DT1','DT2', 'DB1', 'DB2').
-
floatprecision: parameter indicates the precision of floats in returned sets (16/32/64) such as for memory considerations.
In all cases, if the parameter NArw_marker is activated returned sets will be supplemented with a NArw column indicating rows that were subject to infill. Each transformation category has a default infill approach detailed below.
Note that default transformations can be overwritten within an automunge(.) call by way of passing custom transformdict family tree definitions which overwrite the family tree of the default root categories listed above. For instance, if a user wishes to process numerical columns with a default mean scaling ('mean') instead of z-score normalization ('nmbr'), the user may copy the transform_dict entries from the code-base for 'mean' root category and assign as a definition of the 'nmbr' root category, and then pass that defined transformdict in the automunge call. (Note that we don't need to overwrite the processdict for nmbr if we don't intend to overwrite its use as an entry in other root category family trees. Also it is good practice to retain any downstream entries such as in case the default for nmbr is used as an entry in some other root category's family tree.) Here's a demonstration.
#create a transformdict that overwrites the root category definition of nmbr with mean:
#(assumes that we want to include NArw indicating presence of infill)
transformdict = {'nmbr' : {'parents' : [],
'siblings': [],
'auntsuncles' : ['mean'],
'cousins' : ['NArw'],
'children' : [],
'niecesnephews' : [],
'coworkers' : [],
'friends' : []}}
#And then we can simply pass this transformdict to an automunge(.) call.
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train,
transformdict = transformdict)
Note if any of default transformation automation categories (nmbr/1010/ord3/text/bnry/dat6/null) are overwritten in this fashion, a user can still assign original default categories to distinct columns in assigncat by using corresponding alternates of (nmbd/101d/ordd/texd/bnrd/datd/nuld).
...
Library of Transformations
Library of Transformations Subheadings:
- Intro
- Label Set Encodings
- Numeric Set Normalizations
- Numeric Set Transformations
- Numeric Set Bins and Grainings
- Sequential Numerical Set Transformations
- Categorical Set Encodings
- Date-Time Data Normalizations
- Date-Time Data Bins
- Differential Privacy Noise Injections
- Misc. Functions
- Parsed Categoric Encodings
- More Efficient Parsed Categoric Encodings
- Multi-tier Parsed-Categoric-Encodings
- List of Root Categories
- List of Suffix Appenders
- Other Reserved Strings
- Root Category Family Tree Definitions
Intro
Automunge has a built in library of transformations that can be passed for specific columns with assigncat. (A column if left unassigned will defer to the automated default methods to evaluate properties of the data to infer appropriate methods of numerical encoding.) For example, a user can pass a min-max scaling method to a list of specific columns with headers 'column1', 'column2' with:
assigncat = {'mnmx':['column1', 'column2']}
When a user assigns a column to a specific category, that category is treated as the root category for the tree of transformations. Each key has an associated transformation function (where the root category transformation function is only applied if the root key is also found in the tree of family primitives). The tree of family primitives, as introduced earlier, applies first the keys found in upstream primitives i.e. parents/siblings/auntsuncles/cousins. If a transform is applied for a primitive that includes downstream offspring, such as parents/ siblings, then the family tree for that key with offspring is inspected to determine downstream offspring categories, for example if we have a parents key of 'mnmx', then any children/niecesnephews/coworkers/friends in the 'mnmx' family tree will be applied as parents/siblings/auntsuncles/cousins, respectively. Note that the designation for supplements/replaces refers purely to the question of whether the column to which the transform is being applied is kept in place or removed.
Now we'll start here by listing again the family tree primitives for those root categories built into the automunge library. After that we'll give a quick narrative for each of the associated transformation functions. First here again are the family tree primitives.
'parents' :
upstream / first generation / replaces column / with offspring
'siblings':
upstream / first generation / supplements column / with offspring
'auntsuncles' :
upstream / first generation / replaces column / no offspring
'cousins' :
upstream / first generation / supplements column / no offspring
'children' :
downstream parents / offspring generations / replaces column / with offspring
'niecesnephews' :
downstream siblings / offspring generations / supplements column / with offspring
'coworkers' :
downstream auntsuncles / offspring generations / replaces column / no offspring
'friends' :
downstream cousins / offspring generations / supplements column / no offspring
Here is a quick description of the transformation functions associated with each key which can either be assigned to a family tree primitive (or used as a root key). We're continuing to build out this library of transformations. In some cases different transformation categories may be associated with the same set of transformation functions, but may be distinguished by different family tree aggregations of transformation category sets.
Note the design philosophy is that any transform can be applied to any type of data and if the data is not suited (such as applying a numeric transform to a categorical set) the transform will just return all zeros. Note the default infill refers to the infill applied under 'standardinfill'. Note the default NArowtype refers to the categories of data that won't be subject to infill.
Label Set Encodings
Label set encodings are unique in that they don't include an aggregated NArw missing data markers based on NArw_marker parameter. Missing data in label sets are subject to row deletions. Note that inversion of label set encodings is support by the postmunge(.) inversion parameter.
- lbnm: for numeric label sets, entries are given a pass-through transform via 'exc2' (the numeric default under automation)
- lbnb: for numeric label sets, entries are given a z-score normalization via 'nmbr'
- lbor: for categoric label sets, entries are given an ordinal encoding via 'ordl' (the categoric default under automation)
- lb10: for categoric label sets, entries are given a binary encoding via '1010'
- lbos: for categoric label sets, entries are given an ordinal encoding via 'ordl' followed by a conversion to string by 'strg' (some ML libraries prefer string encoded labels to recognize the classification application)
- lbte: for categoric label sets, entries are given a one-hot encoding (this has some interpretability benefits over ordinal)
- lbbn: for categoric label sets with 2 unique values, entries are given a binarization via 'bnry'
- lbsm: for categoric encoding with smoothed labels (i.e. "label smoothing"), further described in smth transform below (accepts activation parameter for activation threshold)
- lbfs: for categoric encoding with fitted smoothed labels (i.e. fitted label smoothing), further described in fsmh transform below (accepts activation parameter for activation threshold)
- lbda: for date-time label sets, entries are encoded comparable to 'dat6' described further below
Numeric Set Normalizations
Please note that a survey of numeric transforms was provided in the paper Numeric Encoding Options with Automunge.
- nmbr/nbr2/nbr3/nmdx/nmd2/nmd3: z-score normalization
(x - mean) / (standard deviation)- useful for: normalizing numeric sets of unknown distribution
- default infill: negzeroinfill
- default NArowtype: numeric
- suffix appender: '_nmbr' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'cap' and 'floor', default to False for no floor or cap, True means floor/cap based on training set min/max, otherwise passed values serve as floor/cap to scaling, noting that if cap
- 'stdev_cap', defaults to False, when cap and floor aren't specified, can pass an integer or float to serve a cap/floor based on this number of standard deviations from the mean
- 'multiplier' and 'offset' to apply multiplier and offset to post-transform values, default to 1,0, note that multiplier is applied prior to offset
- 'abs_zero', defaults to True, deactivate to turn off conversion of negative zeros to positive zeros applied prior to infill (this is included to supplement negzeroinfill)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean / std / max / min / median / MAD
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- nbr4: z-score normalization similar to nmbr but with defaultinfill of zeroinfill instead of negzeroinfill and with abs_zero parameter deactivated
- mean/mea2/mea3: mean normalization (like z-score in the numerator and min-max in the denominator)
(x - mean) / (max - min) My intuition says z-score has some benefits but really up to the user which they prefer.- useful for: similar to z-score except data remains in fixed range
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_mean' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'cap' and 'floor', default to False for no floor or cap, True means floor/cap based on training set min/max, otherwise passed values serve as floor/cap to scaling, noting that if cap
- 'stdev_cap', defaults to False, when cap and floor aren't specified, can pass an integer or float to serve a cap/floor based on this number of standard deviations from the mean
- 'multiplier' and 'offset' to apply multiplier and offset to post-transform values, default to 1,0, note that multiplier is applied prior to offset
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: minimum / maximum / mean / std / median / MAD
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- mnmx/mnm2/mnm5/mmdx/mmd2/mmd3: vanilla min-max scaling
(x - min) / (max - min)- useful for: normalizing numeric sets where all non-negative output is preferred
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_mnmx' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'cap' and 'floor', default to False for no floor or cap, True means floor/cap based on training set min/max, otherwise passed values serve as floor/cap to scaling, noting that if cap
- 'stdev_cap', defaults to False, when cap and floor aren't specified, can pass an integer or float to serve a cap/floor based on this number of standard deviations from the mean
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: minimum / maximum / maxminusmin / mean / std / cap / floor / median / MAD
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- mnm3/mnm4: min-max scaling with outliers capped at 0.01 and 0.99 quantiles
- useful for: normalizing numeric sets where all non-negative output is preferred, and outliers capped
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_mnm3' in base configuration or based on the family tree category
- assignparam parameters accepted:
- qmax or qmin to change the quantiles from 0.99/0.01
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: quantilemin / quantilemax / mean / std / median / MAD
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- mnm6: min-max scaling with test floor set capped at min of train set (ensures
test set returned values >= 0, such as might be useful for kernel PCA for instance)
- useful for: normalizing numeric sets where all non-negative output is preferred, guarantees nonnegative in postmunge
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_mnm6' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: minimum / maximum / mean / std / median / MAD
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- retn: related to min/max scaling but retains +/- of values, based on conditions
if max>=0 and min<=0, x=x/(max-min), elif max>=0 and min>=0 x=(x-min)/(max-min),
elif max<=0 and min<=0 x=(x-max)/(max-min)
- useful for: normalization with sign retention for interpretability
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_retn' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'cap' and 'floor', default to False for no floor or cap, True means floor/cap based on training set min/max, otherwise passed values serve as floor/cap to scaling, noting that if cap
- 'stdev_cap', defaults to False, when cap and floor aren't specified, can pass an integer or float to serve a cap/floor based on this number of standard deviations from the mean
- 'multiplier' and 'offset' to apply multiplier and offset to post-transform values, default to 1,0, note that multiplier is applied prior to offset
- 'divisor' to select between default of 'minmax' or 'mad, 'std', where minmax means scaling by divisor of max-min std based on scaling by divisor of standard deviation and mad by median absolute deviation
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: minimum / maximum / mean / std / median / MAD
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- rtbn: retain normalization supplemented by ordinal encoded standard deviation bins
- rtb2: retain normalization supplemented by one-hot encoded standard deviation bins
- MADn/MAD2: mean absolute deviation normalization, subtract set mean
(x - mean) / (mean absolute deviation)- useful for: normalizing sets with fat-tailed distribution
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_MADn' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean / MAD / maximum / minimum / median
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- MAD3: mean absolute deviation normalization, subtract set maximum
(x - maximum) / (mean absolute deviation)- useful for: normalizing sets with fat-tailed distribution
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_MAD3' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean / MAD / datamax / maximum / minimum / median
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- mxab: max absolute scaling normalization (just including this one for completeness, retn is a much better option to ensure consistent scaling between sets)
(x) / max absolute- useful for: normalizing sets by dividing by max, commonly used in some circles
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_mxab' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: minimum / maximum / maxabs / mean / std
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- lgnm: normalization intended for lognormal distributed numerical sets,
achieved by performing a logn transform upstream of a nmbr normalization.
- useful for: normalizing sets within proximity of lognormal distribution
- default infill: mean
- default NArowtype: positivenumeric
- suffix appender: '_lgnm_nmbr'
- assignparam parameters accepted: can pass params to nmbr consistent with nmbr documentation above
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: consistent with both logn and nmbr
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
Numeric Set Transformations
- bxcx/bxc2/bxc3/bxc4/bxc5: performs Box-Cox power law transformation. Applies infill to
values <= 0. Note we currently have a test for overflow in returned results and if found
set to 0. Please note that this method makes use of scipy.stats.boxcox. Please refer to
family trees below for full set of transformation categories associated with these roots.
- useful for: translates power law distributions to closer approximate gaussian
- default infill: mean (i.e. mean of values > 0)
- default NArowtype: positivenumeric
- suffix appender: '_bxcx' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: trnsfrm_mean / bxcx_lmbda / bxcxerrorcorrect / mean
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: no
- qttf/qtt2: performs quantile transformation to transform distribution properties of feature set.
Please note this method makes use of sklearn.preprocessing.QuantileTransformer from Scikit-Learn.
qttf converts to a normal output distribution, qtt2 converts to a uniform output distribution. When received data is all non-numeric returns as 0.
- useful for: translates distributions to closer approximate gaussian (may be applied as alternative to bxcx)
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_qttf' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'output_distribution': defualts to 'normal' for qttf, or 'uniform' for qtt2
- 'random_state': based on automunge(.) randomseed
- other parameters and their type requirements consistent with scikit documentation (n_quantiles, ignore_implicit_zeros, subsample)
- note that copy parameter not supported, fit parameters not supported
- driftreport postmunge metrics: input_max / input_min / input_stdev / input_mean
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- log0/log1: performs logarithmic transform (base 10). Applies infill to values <= 0.
- useful for: sets with mixed range of large and small values
- default infill: meanlog
- default NArowtype: positivenumeric
- suffix appender: '_log0' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: meanlog
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- logn: performs natural logarithmic transform (base e). Applies infill to values <= 0.
- useful for: sets with mixed range of large and small values
- default infill: meanlog
- default NArowtype: positivenumeric
- suffix appender: '_logn' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: meanlog
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- sqrt: performs square root transform. Applies infill to values < 0.
- useful for: common mathematic transform
- default infill: mean
- default NArowtype: nonnegativenumeric
- suffix appender: '_sqrt' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: meansqrt
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- addd: performs addition of an integer or float to a set
- useful for: common mathematic transform
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_addd' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'add' for value added (default to 1)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean, add
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- sbtr: performs subtraction of an integer or float to a set
- useful for: common mathematic transform
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_sbtr' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'subtract' for value subtracted (default to 1)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean, subtract
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- mltp: performs multiplication of an integer or float to a set
- useful for: common mathematic transform
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_mltp' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'multiply' for value multiplied (default to 2)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean, multiply
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- divd: performs division of an integer or float to a set
- useful for: common mathematic transform
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_divd' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'divide' for value subtracted (default to 2)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean, divide
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- rais: performs raising to a power of an integer or float to a set
- useful for: common mathematic transform
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_rais' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'raiser' for value raised (default to 2)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean, raiser
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- absl: performs absolute value transform to a set
- useful for: common mathematic transform
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_absl' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mean
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with partial recovery
- trigometric functions sint/cost/tant/arsn/arcs/artn: performs trigometric transformations.
Transforms are built on top of numpy np.sin/np.cos/np.tan/np.arcsin/np.arccos/np.arctan respectively.
- useful for: common mathematic transform
- default infill: adjinfill
- default NArowtype: numeric
- suffix appender: based on the family tree category
- assignparam parameters accepted:
- 'operation': defaults to operation associated with the function, accepts {'sin', 'cos', 'tan', 'arsn', 'arcs', 'artn'}
- driftreport postmunge metrics: maximum, minimum
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with partial recovery
Q Notation family of transforms return a multicolumn binary encoded set with registers for sign, integers, and fractionals. Transforms accept parameters integer_bits / fractional_bits / sign_bit for register sizes, care should be taken for adequate registers to avoid overflow (overflow entries have values replaced with max or min capacity based on register sizes). Default register sizes were selected to accommodate z-score normalized data with +/-6 standard deviations from mean and approximately 4 significant figures in decimals. For example, with default parameters an input column 'floats' will return columns: ['floats_qbt1_sign', 'floats_qbt1_2^2', 'floats_qbt1_2^1', 'floats_qbt1_2^0', 'floats_qbt1_2^-1', 'floats_qbt1_2^-2', 'floats_qbt1_2^-3', 'floats_qbt1_2^-4', 'floats_qbt1_2^-5', 'floats_qbt1_2^-6', 'floats_qbt1_2^-7', 'floats_qbt1_2^-8', 'floats_qbt1_2^-9', 'floats_qbt1_2^-10', 'floats_qbt1_2^-11', 'floats_qbt1_2^-12']. Further details on the Q notation family of transforms provided in the essay A New Kind of Data.
- qbt1: binary encoded signed floats with registers for sign, integers, and fractionals, default overflow at +/- 8.000
- useful for: feeding normalized floats to quantum circuits
- default infill: negative zero
- default NArowtype: numeric
- suffix appender: '_qbt1_2^#' where # integer associated with register and also '_qbt1_sign'
- assignparam parameters accepted:
- suffix: defaults to 'qbt1'
- sign_bit: boolean defaults to True to include sign register
- integer_bits: defaults to 3 for number of bits in register
- fractional_bits: defaults to 12 for number of bits in register
- angle_bits: boolean, defaults to False, when activated records activations as angles 0/pi instead of 0/1
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: maximum, minimum, mean, stdev
- returned datatype: int8
- inversion available: yes with full recovery
- qbt2: binary encoded signed integers with registers for sign and integers, default overflow at +/-32,767
- useful for: feeding floats to quantum circuits
- default infill: zero
- default NArowtype: negative zero
- suffix appender: '_qbt2_2^#' where # integer associated with register and also '_qbt2_sign'
- assignparam parameters accepted:
- suffix: defaults to 'qbt2'
- sign_bit: boolean defaults to True to include sign register
- integer_bits: defaults to 15 for number of bits in register
- fractional_bits: defaults to 0 for number of bits in register
- angle_bits: boolean, defaults to False, when activated records activations as angles 0/pi instead of 0/1
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: maximum, minimum, mean, stdev
- returned datatype: int8
- inversion available: yes with full recovery
- qbt3: binary encoded unsigned floats with registers for integers and fractionals, default overflow at 8.000 and <0
- useful for: feeding unsigned normalized floats to quantum circuits
- default infill: zero
- default NArowtype: numeric
- suffix appender: '_qbt3_2^#' where # integer associated with register
- assignparam parameters accepted:
- suffix: defaults to 'qbt3'
- sign_bit: boolean defaults to False, activate to include sign register
- integer_bits: defaults to 3 for number of bits in register
- fractional_bits: defaults to 13 for number of bits in register
- angle_bits: boolean, defaults to False, when activated records activations as angles 0/pi instead of 0/1
- driftreport postmunge metrics: maximum, minimum, mean, stdev
- returned datatype: int8
- inversion available: yes with full recovery
- qbt4: binary encoded unsigned integers with registers for integers, default overflow at 65,535 and <0
- useful for: feeding unsigned floats to quantum circuits
- default infill: zero
- default NArowtype: numeric
- suffix appender: '_qbt4_2^#' where # integer associated with register
- assignparam parameters accepted:
- suffix: defaults to 'qbt4'
- sign_bit: boolean defaults to False, activate to include sign register
- integer_bits: defaults to 16 for number of bits in register
- fractional_bits: defaults to 0 for number of bits in register
- angle_bits: boolean, defaults to False, when activated records activations as angles 0/pi instead of 0/1
- driftreport postmunge metrics: maximum, minimum, mean, stdev
- returned datatype: int8
- inversion available: yes with full recovery
Other Q Notation root categories:
- nmqb has upstream z score to qbt1 and z score not retained
- nmq2 has upstream z score to qbt1 and z score is retained
- mmqb has upstream min max to qbt3 and min max not retained
- mmq2 has upstream min max to qbt3 and min max is retained
- lgnr logarithmic number representation, registers 1 for sign, 1 for log sign, 4 log integer registers, 3 log fractional registers
Numeric Set Bins and Grainings
- pwrs: bins groupings by powers of 10 (for values >0)
- useful for: feature engineering for linear models, also for oversampling bins with TrainFreqLevelizer parameter
- default infill: no activation (defaultinfill not supported)
- default NArowtype: positivenumeric
- suffix appender: '_pwrs_10^#' where # is integer indicating target powers of 10 for column
- assignparam parameters accepted:
- 'negvalues', boolean defaults to False, True bins values <0 (recommend using pwr2 instead of this parameter since won't update NArowtype)
- 'suffix': to change suffix appender (leading underscore added internally)
- 'zeroset': boolean defaults to False, when True the number zero receives a distinct activation instead of grouping with missing data (recommend also updating NArowtype, such as to nonnegativenumeric)
- 'cap': defaults to False for no cap, can pass as integer or float and > values replaced with this figure
- 'floor': defaults to False for no floor, can pass as integer or float and < values replaced with this figure
- driftreport postmunge metrics: powerlabelsdict / meanlog / maxlog / activation_ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- pwr2: bins groupings by powers of 10 (comparable to pwrs with negvalues parameter activated for values >0 & <0)
- useful for: feature engineering for linear models, also for oversampling bins with TrainFreqLevelizer parameter
- default infill: no activation (defaultinfill not supported)
- default NArowtype: nonzeronumeric
- suffix appender: '_pwr2_10^#' or '_pwr2_-10^#' where # is integer indicating target powers of 10 for column
- assignparam parameters accepted:
- 'negvalues', boolean defaults to True, True bins values <0 (recommend using pwrs instead of this parameter since won't update NArowtype)
- 'zeroset': boolean defaults to False, when True the number zero receives a distinct activation instead of grouping with missing data (recommend also updating NArowtype, such as to numeric)
- 'suffix': to change suffix appender (leading underscore added internally)
- 'cap': defaults to False for no cap, can pass as integer or float and > values replaced with this figure
- 'floor': defaults to False for no floor, can pass as integer or float and < values replaced with this figure
- driftreport postmunge metrics: powerlabelsdict / labels_train / missing_cols / activation_ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- pwor: for numerical sets, outputs an ordinal encoding indicating where a
value fell with respect to powers of 10
- useful for: ordinal version of pwrs
- default infill: zero (defaultinfill not supported)
- default NArowtype: positivenumeric
- suffix appender: '_pwor' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'negvalues', boolean defaults to False, True bins values <0 (recommend using por2 instead of this parameter since won't update NArowtype)
- 'zeroset': boolean defaults to False, when True the number zero receives a distinct activation instead of grouping with missing data (recommend also updating NArowtype, such as to nonnegativenumeric)
- 'suffix': to change suffix appender (leading underscore added internally)
- 'cap': defaults to False for no cap, can pass as integer or float and > values replaced with this figure
- 'floor': defaults to False for no floor, can pass as integer or float and < values replaced with this figure
- driftreport postmunge metrics: meanlog / maxlog / ordl_activations_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with partial recovery
- por2: for numerical sets, outputs an ordinal encoding indicating where a
value fell with respect to powers of 10 (comparable to pwor with negvalues parameter activated)
- useful for: ordinal version of pwr2
- default infill: zero (a distinct encoding) (defaultinfill not supported)
- default NArowtype: nonzeronumeric
- suffix appender: '_por2' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'negvalues', boolean defaults to True, True bins values <0 (recommend using pwor instead of this parameter since won't update NArowtype)
- 'zeroset': boolean defaults to False, when True the number zero receives a distinct activation instead of grouping with missing data (recommend also updating NArowtype, such as to numeric)
- 'suffix': to change suffix appender (leading underscore added internally)
- 'cap': defaults to False for no cap, can pass as integer or float and > values replaced with this figure
- 'floor': defaults to False for no floor, can pass as integer or float and < values replaced with this figure
- driftreport postmunge metrics: train_replace_dict / test_replace_dict / ordl_activations_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with partial recovery
- pwbn: comparable to pwor but followed by a binary encoding, such as may be useful for data with
high variability
- useful for: ordinal version of pwrs
- default infill: zero (a distinct encoding)
- default NArowtype: nonzeronumeric
- suffix appender: 'pwbn_1010#' (where # is integer for binary encoding activation number)
- assignparam parameters accepted:
- accepts parameters comparable to pwor
- driftreport postmunge metrics: train_replace_dict / test_replace_dict / ordl_activations_dict
- returned datatype: int8
- inversion available: yes with partial recovery
- por3: comparable to por2 but followed by a binary encoding, such as may be useful for data with
high variability
- useful for: ordinal version of pwr2
- default infill: zero (a distinct encoding)
- default NArowtype: nonzeronumeric
- suffix appender: 'por3_1010#' (where # is integer for binary encoding activation number)
- assignparam parameters accepted:
- accepts parameters comparable to pwor
- driftreport postmunge metrics: train_replace_dict / test_replace_dict / ordl_activations_dict
- returned datatype: int8
- inversion available: yes with partial recovery
- bins: for numerical sets, outputs a set of columns (defaults to 6) indicating where a
value fell with respect to number of standard deviations from the mean of the
set (i.e. integer suffix represent # from mean as <-2:0, -2-1:1, -10:2, 01:3, 12:4, >2:5)
Note this can be activated to supplement numeric sets with binstransform automunge parameter.
- useful for: feature engineering for linear models, also for oversampling bins with TrainFreqLevelizer parameter
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_bins_#' where # is integer identifier of bin
- assignparam parameters accepted:
- bincount integer for number of bins, defaults to 6
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / binsstd / activation_ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- bsor: for numerical sets, outputs an ordinal encoding indicating where a
value fell with respect to number of standard deviations from the mean of the
set (i.e. integer encoding represent # from mean as <-2:0, -2-1:1, -10:2, 01:3, 12:4, >2:5)
- useful for: ordinal version of bins
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_bsor' in base configuration or based on the family tree category
- assignparam parameters accepted:
- bincount as integer for # of bins (defaults to 6)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: ordinal_dict / ordl_activations_dict / binsmean / binsstd
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with partial recovery
- bnwd/bnwK/bnwM: for numerical set graining to fixed width bins for one-hot encoded bins
(columns without activations in train set excluded in train and test data).
bins default to width of 1/1000/1000000 e.g. for bnwd/bnwK/bnwM
- useful for: bins for sets with known recurring demarcations
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_bnwd_#1_#2' where #1 is the width and #2 is the bin identifier (# from min) and 'bnwd' as bnwK or bnwM based on variant
- assignparam parameters accepted:
- 'width' to set bin width
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / bn_min / bn_max / bn_delta / bn_count / bins_id / bins_cuts / bn_width_bnwd (or bnwK/bnwM) / textcolumns / activation_ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- bnwo/bnKo/bnMo: for numerical set graining to fixed width bins for ordinal encoded bins
(integers without train set activations still included in test set).
bins default to width of 1/1000/1000000 e.g. for bnwd/bnwK/bnwM
- useful for: ordinal version of preceding
- default infill: mean
- default NArowtype: numeric
- suffix appender: '_bnwo' (or '_bnKo', '_bnMo')
- assignparam parameters accepted:
- 'width' to set bin width
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / bn_min / bn_max / bn_delta / bn_count / bins_id / bins_cuts / bn_width / ordl_activations_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with partial recovery
- bnep/bne7/bne9: for numerical set graining to equal population bins for one-hot encoded bins.
bin count defaults to 5/7/9 e.g. for bnep/bne7/bne9
- useful for: bins for sets with unknown demarcations
- default infill: no activation (defaultinfill not supported)
- default NArowtype: numeric
- suffix appender: '_bnep_#1' where #1 is the bin identifier (# from min) (or bne7/bne9 instead of bnep)
- assignparam parameters accepted:
- 'bincount' to set number of bins
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / bn_min / bn_max / bn_delta / bn_count / bins_id / bins_cuts / bincount_bnep (or bne7/bne9) / textcolumns / activation_ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- bneo/bn7o/bn9o: for numerical set graining to equal population bins for ordinal encoded bins.
bin count defaults to 5/7/9 e.g. for bneo/bn7o/bn9o
- useful for: ordinal version of preceding
- default infill: adjacent cell
- default NArowtype: numeric
- suffix appender: '_bneo' (or bn7o/bn9o)
- assignparam parameters accepted:
- 'bincount' to set number of bins
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / bn_min / bn_max / bn_delta / bn_count / bins_id / bins_cuts / bincount / ordl_activations_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with partial recovery
- bkt1: for numerical set graining to user specified encoded bins. First and last bins unconstrained.
- useful for: bins for sets with known irregular demarcations
- default infill: no activation (defaultinfill not supported)
- default NArowtype: numeric
- suffix appender: '_bkt1_#1' where #1 is the bin identifier (# from min)
- assignparam parameters accepted:
- 'buckets', a list of numbers, to set bucket boundaries (leave out +/-'inf') defaults to [0,1,2] (arbitrary plug values), can also pass buckets values as percent of range by framing as a set instead of list e.g. {0,0.25,0.50,1}
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / buckets_bkt1 / bins_cuts / bins_id / textcolumns / activation_ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- bkt2: for numerical set graining to user specified encoded bins. First and last bins bounded.
- useful for: bins for sets with known irregular demarcations, similar to preceding but first and last bins bounded
- default infill: no activation (defaultinfill not supported)
- default NArowtype: numeric
- suffix appender: '_bkt2_#1' where #1 is the bin identifier (# from min)
- assignparam parameters accepted:
- 'buckets', a list of numbers, to set bucket boundaries defaults to [0,1,2] (arbitrary plug values), can also pass buckets values as percent of range by framing as a set instead of list e.g. {0,0.25,0.50,1}
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / buckets_bkt2 / bins_cuts / bins_id / textcolumns / activation_ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- bkt3: for numerical set graining to user specified ordinal encoded bins. First and last bins unconstrained.
- useful for: ordinal version of bkt1
- default infill: unique activation
- default NArowtype: numeric
- suffix appender: '_bkt3' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'buckets', a list of numbers, to set bucket boundaries (leave out +/-'inf') defaults to [0,1,2] (arbitrary plug values), can also pass buckets values as percent of range by framing as a set instead of list e.g. {0,0.25,0.50,1}
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / buckets / bins_cuts / bins_id / ordl_activations_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with partial recovery
- bkt4: for numerical set graining to user specified ordinal encoded bins. First and last bins bounded.
- useful for: ordinal version of bkt2
- default infill: unique activation
- default NArowtype: numeric
- suffix appender: '_bkt4' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'buckets', a list of numbers, to set bucket boundaries defaults to [0,1,2] (arbitrary plug values), can also pass buckets values as percent of range by framing as a set instead of list e.g. {0,0.25,0.50,1}
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / buckets / bins_cuts / bins_id / ordl_activations_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with partial recovery
- note that bins each have variants for one-hot vs ordinal vs binary encodings one-hot : bkt1, bkt2, bins, bnwd, bnwK, bnwM, bnep, bne7, bne9, pwrs, pwr2 ordinal : bkt3, bkt4, bsor, bnwo, bnKo, bnMo, bneo, bn7o, bn9o, pwor, por2 binary : bkb3, bkb4, bsbn, bnwb, bnKb, bnMb, bneb, bn7b, bn9b, pwbn, por3
- tlbn: returns equal population bins in separate columns with activations replaced by min-max scaled
values within that segment's range (between 0-1) and other values subject to an infill of -1
(intended for use to evaluate feature importance of different segments of a numerical set's distribution
with metric2 results from a feature importance evaluation). Further detail on the tlbn transform provided
in the essay Automunge Influence.
- useful for: evaluating relative feature importance between different segments of a numeric set distribution
- default infill: no activation (this is the recommended infill for this transform)
- default NArowtype: numeric
- suffix appender: '_tlbn_#' where # is the bin identifier, and max# is right tail / min# is left tail
- assignparam parameters accepted:
- 'bincount' to set number of bins (defaults to 9)
- 'buckets', defaults to False, can pass as a list of bucket boundaries for custom distribution segments which will take precedence over bincount (leave out -/+inf which will be added for first and last bins internally)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: binsmean / bn_min / bn_max / bn_delta / bn_count / bins_id / bins_cuts / bincount_tlbn / textcolumns / activation_ratios
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
Sequential Numerical Set Transformations
Please note that sequential transforms assume the forward progression of time towards direction of bottom of dataframe. Please note that only stdrdinfill (adjinfill) are supported for shft transforms.
- dxdt/d2dt/d3dt/d4dt/d5dt/d6dt: rate of change (row value minus value in preceding row), high orders
return lower orders (e.g. d2dt returns original set, dxdt, and d2dt), all returned sets include 'retn'
normalization which scales data with min/max while retaining +/- sign
- useful for: time series data, also bounding sequential sets
- default infill: adjacent cells
- default NArowtype: numeric
- suffix appender: '_dxdt' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'periods' sets number of time steps offset to evaluate, defaults to 1
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: positiveratio / negativeratio / zeroratio / minimum / maximum / mean / std
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: no
- dxd2/d2d2/d3d2/d4d2/d5d2/d6d2: denoised rate of change (average of last two or more rows minus average
of preceding two or more rows), high orders return lower orders (e.g. d2d2 returns original set, dxd2,
and d2d2), all returned sets include 'retn' normalization
- useful for: time series data, also bounding sequential sets
- default infill: adjacent cells
- default NArowtype: numeric
- suffix appender: '_dxd2' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'periods' sets number of time steps offset to evaluate, defaults to 2
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: positiveratio / negativeratio / zeroratio / minimum / maximum / mean / std
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: no
- nmdx/nmd2/nmd3/nmd4/nmd5/nmd6: comparable to dxdt but includes upstream of sequential transforms a nmrc numeric string parsing top extract numbers from string sets
- mmdx/mmd2/mmd3/mmd4/mmd5/mmd6: comparable to dxdt but uses z-score normalizations via 'nbr2' instead of 'retn'
- dddt/ddd2/ddd3/ddd4/ddd5/ddd6: comparable to dxdt but no normalizations applied
- dedt/ded2/ded3/ded4/ded5/ded6: comparable to dxd2 but no normalizations applied
- inversion available: no
- shft/shf2/shf3: shifted data forward by a period number of time steps defaulting to 1/2/3. Note that NArw aggregation
not supported for shift transforms, infill only available as adjacent cell
- useful for: time series data, carrying prior time steps forward
- default infill: adjacent cells (defaultinfill not supported)
- default NArowtype: numeric
- suffix appender: '_shft' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'periods' sets number of time steps offset to evaluate, defaults to 1/2/3
- 'suffix' sets the suffix appender of returned column as may be useful to distinguish if applying this multiple times
- driftreport postmunge metrics: positiveratio / negativeratio / zeroratio / minimum / maximum / mean / std
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
Categorical Set Encodings
- bnry: converts sets with two values to boolean identifiers. Defaults to assigning
1 to most common value and 0 to second most common, unless 1 or 0 is already included
in most common of the set then defaults to maintaining those designations. If applied
to set with >2 entries applies infill to those entries beyond two most common.
- useful for: binarizing sets with two unique values (differs from 1010 in that distinct encoding isn't registered for missing data to return single column)
- default infill: most common value
- default NArowtype: justNaN
- suffix appender: '_bnry' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'str_convert': boolean defaults as False for distinct encodings between numbers and string equivalents e.g. 2 != '2', or when passed as True e.g. 2 == '2'. Also can be passed as 'conditional_on_bytes' which resets to True when bytes entries are present in train set otherwise resets to False.
- 'suffix': to change suffix appender (leading underscore added internally)
- 'invert': reverses the 0/1 convention (results in most common value having 0 activation which is default for lbbn label processing to resolve a remote edge case for labels)
- driftreport postmunge metrics: missing / 1 / 0 / extravalues / oneratio / zeroratio
- returned datatype: int8
- inversion available: yes with full recovery
- bnr2: (Same as bnry except for default infill.)
- useful for: similar to bnry preceding but with different default infill
- default infill: least common value
- default NArowtype: justNaN
- suffix appender: '_bnr2' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'str_convert': boolean defaults as False for distinct encodings between numbers and string equivalents e.g. 2 != '2', or when passed as True e.g. 2 == '2'. Also can be passed as 'conditional_on_bytes' which resets to True when bytes entries are present in train set otherwise resets to False.
- 'suffix': to change suffix appender (leading underscore added internally)
- 'invert': reverses the 0/1 convention (results in most common value having 0 activation which is default for lbbn label processing to resolve a remote edge case for labels)
- driftreport postmunge metrics: missing / 1 / 0 / extravalues / oneratio / zeroratio
- returned datatype: int8
- inversion available: yes with full recovery
- text/txt2: converts categorical sets to one-hot encoded set of boolean identifiers
(consistently encodings numbers and numerical string equivalents due to column labeling convention, e.g. 12 == '12').
Note that text and onht are implemented with the same functions by updates to the suffix_convention parameter.
- useful for: one hot encoding, returns distinct column activation per unique entry
- default infill: no activation in row
- default NArowtype: justNaN
- suffix appender:
- '_text_(entry)' where entry is the categoric entry target of column activations (one of the unique values found in received column)
- assignparam parameters accepted:
- 'suffix_convention', accepts one of {'text', 'onht'} for suffix convention, defaults to 'text'. Note that 'str_convert' and 'null_activation' parameters only accepted in 'onht' configuration.
- 'str_convert', applied as True in text suffix_convention for common encodings between numbers and string equivalents e.g. 2 == '2'. (text does not support other str_convert scenarios due to column header conventions)
- 'null_activation': applied as False in text suffix_convention for no activations for missing data
- 'all_activations': defaults to False, can pass as a list of all entries that will be targets for activations (which may have fewer or more entries than the set of unique values found in the train set, including entries not found in the train set)
- 'add_activations': defaults to False, user can pass as a list of entries that will be added as targets for activations (resulting in extra returned columns if those entries aren't present in the train set)
- 'less_activations': defaults to False, user can pass as a list of entries that won't be treated as targets for activation (these entries will instead receive no activation)
- 'consolidated_activations': defaults to False, user can pass a list of entries (or a list of lists of entries) that will have their activations consolidated to a single common activation
- 'ordered_overide': default to True, accepts boolean indicating if columns received as pandas ordered categoric will use that basis for order of the returned columns. Note this is deactivated when activation parameters are specified (all/add/less/consolidated).
- 'frequency_sort': boolean defaults to True, when activated the order of returned columns is sorted by frequency of entries as found in the train set, when deactivated sorting is alphabetic
- onht: converts categorical sets to one-hot encoded set of boolean identifiers
(like text but different convention for returned column headers and distinct encodings for numbers and numerical string equivalents). Note that text and onht are implemented with the same functions by updates to the suffix_convention parameter. To apply onht to a "messy" feature with multiple columns in input headers can apply assigncat set bracket specification to root category 'cns2'.
- useful for: similar to text transform preceding but with numbered column header convention
- default infill: no activation in row
- default NArowtype: justNaN
- suffix appender: '_onht_#' where # integer corresponds to the target entry of a column
- assignparam parameters accepted:
- 'suffix_convention', accepts one of {'text', 'onht'} for suffix convention, defaults to 'text' (onht process_dict specification overwrites this to 'onht'). Note that 'str_convert' and 'null_activation' parameters only accepted in 'onht' configuration.
- 'str_convert', boolean defaults as True for common encodings between numbers and string equivalents e.g. 2 != '2', when passed as True e.g. 2 == '2' (the False scenario does not support bytes type entries). Also can be passed as 'conditional_on_bytes' which resets to True when bytes entries are present in train set otherwise resets to False.
- 'null_activation': defaults to False, when True missing data is returned with distinct activation in final column in set. (Also accepts as 'Binary' which is for internal use.)
- 'all_activations': defaults to False, can pass as a list of all entries that will be targets for activations (which may have fewer or more entries than the set of unique values found in the train set, including entries not found in the train set)
- 'add_activations': defaults to False, user can pass as a list of entries that will be added as targets for activations (resulting in extra returned columns if those entries aren't present in the train set)
- 'less_activations': defaults to False, user can pass as a list of entries that won't be treated as targets for activation (these entries will instead receive no activation)
- 'consolidated_activations': defaults to False, user can pass a list of entries (or a list of lists of entries) that will have their activations consolidated to a single common activation
- 'ordered_overide': default to True, accepts boolean indicating if columns received as pandas ordered categoric will use that basis for order of the returned columns. Note this is deactivated when activation parameters are specified (all/add/less/consolidated).
- 'frequency_sort': boolean defaults to True, when activated the order of returned columns is sorted by frequency of entries as found in the train set, when deactivated sorting is alphabetic
- driftreport postmunge metrics: textlabelsdict_text / + '_ratio' (column specific) text_categorylist is key between columns and target entries
- returned datatype: int8
- inversion available: yes with full recovery
- ordl/ord2/ord5: converts categoric sets to ordinal integer encoded set, encodings sorted alphabetically
- useful for: categoric sets with high cardinality where one-hot or binarization may result in high dimensionality. Also default for categoric labels.
- default infill: naninfill, with returned distinct activation of integer 0
- default NArowtype: justNaN
- suffix appender: '_ordl' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'str_convert', boolean defaults as True for common encodings between numbers and string equivalents e.g. 2 == '2'. Also can be passed as 'conditional_on_bytes' which resets to True when bytes entries are present in train set otherwise resets to False.
- 'null_activation': defaults to True for a distinct missing data encoding, when False missing data is grouped with another entry in the 0 integer encoding. (Also accepts as 'Binary' which is for internal use.)
- 'all_activations': defaults to False, can pass as a list of all entries that will be targets for activations (which may have fewer or more entries than the set of unique values found in the train set, including entries not found in the train set)
- 'add_activations': defaults to False, user can pass as a list of entries that will be added as targets for activations (resulting in extra returned columns if those entries aren't present in the train set)
- 'less_activations': defaults to False, user can pass as a list of entries that won't be treated as targets for activation (these entries will instead receive no activation)
- 'consolidated_activations': defaults to False, user can pass a list of entries (or a list of lists of entries) that will have their activations consolidated to a single common activation
- 'ordered_overide': default to True, accepts boolean indicating if columns received as pandas ordered categoric will use that basis for order of the returned columns. Note this is deactivated when activation parameters are specified (all/add/less/consolidated).
- 'frequency_sort': boolean defaults to True but set as False for ordl, when activated the order of integer activations is sorted by frequency of entries as found in the train set, when deactivated sorting is alphabetic. The 0 activation is reserved for missing data.
- driftreport postmunge metrics: ordinal_dict / ordinal_overlap_replace / ordinal_activations_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with full recovery
- ord3: converts categoric sets to ordinal integer encoded set, sorted first by frequency of category
occurrence, second basis for common count entries is alphabetical. To apply ord3 to a "messy" feature with multiple columns in input headers can apply assigncat set bracket specification to root category 'cns3'.
- useful for: similar to ordl preceding but activations are sorted by entry frequency instead of alphabetical
- default infill: unique activation
- default NArowtype: justNaN
- suffix appender: '_ord3' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'ordered_overide', boolean defaults True, when True inspects for Pandas ordered categorical and if found integer encoding order defers to that basis
- 'str_convert', boolean defaults as True for common encodings between numbers and string equivalents e.g. 2 == '2' (the False scenario does not support bytes type entries). Also can be passed as 'conditional_on_bytes' which resets to True when bytes entries are present in train set otherwise resets to False.
- 'null_activation': defaults to True for a distinct missing data encoding, when False missing data is grouped with another entry in the 0 integer encoding. (Also accepts as 'Binary' which is for internal use.)
- 'all_activations': defaults to False, can pass as a list of all entries that will be targets for activations (which may have fewer or more entries than the set of unique values found in the train set, including entries not found in the train set)
- 'add_activations': defaults to False, user can pass as a list of entries that will be added as targets for activations (resulting in extra returned columns if those entries aren't present in the train set)
- 'less_activations': defaults to False, user can pass as a list of entries that won't be treated as targets for activation (these entries will instead receive no activation)
- 'consolidated_activations': defaults to False, user can pass a list of entries (or a list of lists of entries) that will have their activations consolidated to a single common activation
- 'ordered_overide': default to True, accepts boolean indicating if columns received as pandas ordered categoric will use that basis for order of the returned columns. Note this is deactivated when activation parameters are specified (all/add/less/consolidated).
- 'frequency_sort': boolean defaults to True, when activated the order of integer activations is sorted by frequency of entries as found in the train set, when deactivated sorting is alphabetic. The 0 activation is reserved for missing data.
- driftreport postmunge metrics: ordinal_dict / ordinal_overlap_replace / ordinal_activations_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with full recovery
- ord4: derived by an ord3 transform followed by a mnmx transform. Useful as a scaled metric (numeric in range 0-1) which ranks any redundant entries by frequency of occurrence.
- lbos: an ord3 encoding followed by downstream conversion to string dtype. This may be useful for label sets passed to downstream libraries to ensure they treat labels as target for classification instead of regression.
- 1010: converts categorical sets of >2 unique values to binary encoding (more memory
efficient than one-hot encoding). To apply 1010 to a "messy" feature with multiple columns in input headers can apply assigncat set bracket specification to root category 'cnsl'.
- useful for: our default categoric encoding for sets with number of entries below numbercategoryheustic (defaulting to 255)
- default infill: naninfill, with returned distinct activation set of all 0's
- default NArowtype: justNaN
- suffix appender: '_1010_#' where # is integer indicating order of 1010 columns
- assignparam parameters accepted:
- 'str_convert', boolean defaults as True for common encodings between numbers and string equivalents e.g. 2 == '2'. Also can be passed as 'conditional_on_bytes' which resets to True when bytes entries are present in train set otherwise resets to False.
- 'null_activation': defaults to True for a distinct missing data encoding, when False missing data is grouped with another entry in the all 0 encoding. (Also accepts as 'Binary' which is for internal use.)
- 'all_activations': defaults to False, can pass as a list of all entries that will be targets for activations (which may have fewer or more entries than the set of unique values found in the train set, including entries not found in the train set), note NaN missing data representation will be added
- 'add_activations': defaults to False, user can pass as a list of entries that will be added as targets for activations (resulting in extra returned columns if those entries aren't present in the train set)
- 'less_activations': defaults to False, user can pass as a list of entries that won't be treated as targets for activation (these entries will instead receive no activation)
- 'consolidated_activations': defaults to False, user can pass a list of entries (or a list of lists of entries) that will have their activations consolidated to a single common activation. For consolidation with NaN missing data representation user should instead apply an assignnan conversion.
- 'max_zero': defaults to False, when activated the encodings are conducted to maximize 0 encoding representation for unique entries as sorted by frequency (e.g. most frequent entries have most zeros in their encoding.) This was implemented since 0 is the low energy state for quantum circuits. The root category '10mz' applies 1010 with this parameter defaulting to activated.
- driftreport postmunge metrics: _1010_binary_encoding_dict / _1010_overlap_replace / _1010_binary_column_count / _1010_activations_dict (for example if 1010 encoded to three columns based on number of categories <8, it would return three columns with suffix appenders 1010_1, 1010_2, 1010_3)
- returned datatype: int8
- inversion available: yes with full recovery
- maxb / matx / ma10: categoric encodings that allow user to cap the number activations in the set.
maxb (ordinal), matx (one hot), and ma10 (binary).
- useful for: categoric sets where some outlier entries may not occur with enough frequency for training purposes
- default infill: plug value unique activation
- default NArowtype: justNaN
- suffix appender: '_maxb' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'maxbincount': set a maximum number of activations (integer) default False
- 'minentrycount': set a minimum number of entries in train set to register an activation (integer) default False
- 'minentryratio': set a minimum ratio of entries in train set to register an activation (float between 0-1)
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: new_maxactivation / consolidation_count
- returned datatype: matx and ma10 as int8, maxb as conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with full recovery
- ucct: converts categorical sets to a normalized float of unique class count,
for example, a 10 row train set with two instances of 'circle' would replace 'circle' with 0.2
and comparable to test set independent of test set row count
- useful for: supplementing categoric sets with a proxy for activation frequency
- default infill: ratio of infill in train set
- default NArowtype: justNaN
- suffix appender: '_ucct' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: ordinal_dict / ordinal_overlap_replace / ordinal_activations_dict
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: no
- lngt/lngm/lnlg: returns string length of categoric entries (lngm followed by mnmx, lnlg by logn)
- useful for: supplementing categoric sets with a proxy for information content (based on string length)
- default infill: plug value of 3 (based on len(str(np.nan)) )
- default NArowtype: justNaN
- suffix appender: '_lngt' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: maximum, minimum, mean, std
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: no
- aggt: consolidate categoric entries based on user passed aggregate parameter
- useful for: performing upstream of categoric encoding when some entries are redundant
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_aggt' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'aggregate' as a list or as a list of lists of aggregation sets
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: aggregate
- returned datatype: str (other categoric encodings can be returned downstream to return numeric)
- inversion available: yes with partial recovery
- smth: applies a one-hot encoding followed by a label smoothing operation to reduce activation value and increase null value. The smoothing is applied to train data but not validation or test data. Smoothing can be applied to test data in postmunge(.) by activating the traindata parameter.
- useful for: label smoothing, speculate there may be benefit for categoric encodings with noisy entries of some error rate
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_smt0_(entry)_smth_#' where # is integer in base configuration or based on the family tree category
- assignparam parameters accepted:
- note that parameters for the upstream onehot encoding can be passed in assignparam to the smt0 category (consistent to text transform), and smoothing parameters can be passed to the smth category
- 'activation' defaults to 0.9, a float between 0.5-1 to designate activation value
- 'LSfit' defaults to False, when True applies fitted label smoothing (consistent with fsmh)
- 'testsmooth' defaults to False, when True applies smoothing to test data in both automunge and postmunge
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: comparable to onht
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- fsmh: comparable to smth but applies by default a fitted label smoothing, in which null values are fit to ratio of activations corresponding to current activation. The smoothing is applied to train data but not validation or test data. Smoothing can be applied to test data in postmunge(.) by activating the traindata parameter. (Note that parameters for the upstream onehot encoding can be passed in assignparam to the fsm0 category (consistent to text transform), and smoothing parameters can be passed to the fsmh category
- hash: applies "the hashing trick" to convert high cardinality categoric sets to set of columns with integer word encodings
e.g. for an entry "Three word quote" may return three columns with integers corresponding to each of three words
where integer is determined by hashing, and also based on passed parameter vocab_size.
Note that hash strips out special characters. Uhsh is available if upstream uppercase conversion desired. Note that there is a possibility
of encoding overlap between entries with this transform. Also note that hash is excluded from ML infill
vocab_size calculated based on number of unique words found in train set times a multiplier (defaulting to 2), where if that
is greater than cap then reverts to cap. The hashing transforms are intended as an alternative to other categoric
encodings which doesn't require a conversion dictionary assembly for consistent processing of subsequent data, as
may benefit sets with high cardinality (i.e. high number of unique entries). The tradeoff is that inversion
is not supported as there is possibility of redundant encodings for different unique entries. Further detail on hashing
provided in the essay Hashed Categoric Encodings with Automunge.
- useful for: categoric sets with very high cardinality, default for categoric sets with (nearly) all unique entries
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_hash_#' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'heuristic_multiplier', float defaults to 2
- 'heuristic_cap', integer defaults to 1024
- 'vocab_size', integer defaults to False, when assigned overrides heuristic
- 'space', defaults to ' ', this is used to extract words by space separator
- 'excluded_characters', defaults to [',', '.', '?', '!', '(', ')'], these characters are stripped prior to encoding
- 'salt', arbitrary string, defaults to empty string '', appended to entries to perturb encoding basis for privacy
- 'hash_alg', defaults to 'hash' for use of native python hash function for speed, 'md5' uses hashlib md5 function instead
- 'max_column_count', defaults to False, can pass as integer to cap the number of returned columns, in which case when words are extracted the final column's encodings will be based on all remaining word and space characters inclusive
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: col_count (number of columns), vocab_size
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: no
- hsh2: similar to hash but does not partition entries by space separator, so only returns one column. Note this version doesn't scrub special characters prior to encoding.
- useful for: categoric sets with very high cardinality, default for categoric sets with number of entries exceeding numbercategoryheuristic (defaulting to 255)
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_hsh2' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'heuristic_multiplier', float defaults to 2
- 'heuristic_cap', integer defaults to 1024
- 'vocab_size', integer defaults to False, when assigned overrides heuristic
- 'excluded_characters', a list of strings, defaults to [] (an empty set), these characters are stripped prior to encoding
- 'salt', arbitrary string, defaults to empty string '', appended to entries to perturb encoding basis for privacy
- 'hash_alg', defaults to 'hash' for use of native python hash function for speed, 'md5' uses hashlib md5 function instead
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: col_count (number of columns), vocab_size
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: no
- hs10: similar to hsh2 but returns activations in a set of columns with binary encodings, similar to 1010
- useful for: binary version of hsh2
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_hs10_#' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'heuristic_multiplier', float defaults to 2
- 'heuristic_cap', integer defaults to 1024
- 'vocab_size', integer defaults to False, when assigned overrides heuristic
- 'excluded_characters', a list of strings, defaults to [] (an empty set), these characters are stripped prior to encoding
- 'salt', arbitrary string, defaults to empty string '', appended to entries to perturb encoding basis for privacy
- 'hash_alg', defaults to 'hash' for use of native python hash function for speed, 'md5' uses hashlib md5 function instead
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: col_count (number of columns), vocab_size
- returned datatype: int8
- inversion available: no
- UPCS: convert string entries to all uppercase characters
- useful for: performing upstream of categoric encodings when case configuration is irrelevant
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_UPCS' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'activate', boolean defaults to True, False makes this a passthrough without conversion
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: activate
- returned datatype: str (other categoric encodings can be returned downstream to return numeric)
- inversion available: yes with partial recovery
- new processing functions Unht / Utxt / Utx2 / Utx3 / Uord / Uor2 / Uor3 / Uor6 / U101 / Ucct / Uhsh / Uhs2 / Uh10
- comparable to functions onht / text / txt2 / txt3 / ordl / ord2 / ord3 / ors6 / 1010 / ucct / hash / hsh2 / hs10
- but upstream conversion of all strings to uppercase characters prior to encoding
- (e.g. 'USA' and 'usa' would be consistently encoded)
- default infill: in uppercase conversion NaN's are assigned distinct encoding 'NAN'
- and may be assigned other infill methods in assigninfill
- default NArowtype: 'justNaN'
- suffix appender: '_UPCS' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: comparable to functions text / txt2 / txt3 / ordl / ord2 / ord3 / ors6 / 1010 / ucct
- returned datatype: comparable to functions onht / text / txt2 / txt3 / ordl / ord2 / ord3 / ors6 / 1010 / ucct / hash / hsh2 / hs10
- inversion available: yes
- ntgr/ntg2/ntg3: sets of transformations intended for application to integer sets of unknown interpretation
(such as may be continuous variables, discrete relational variables, or categoric). The ntgr family encodes
in multiple forms appropriate for each of these different types, such as to allow the ML training to identify
which is most useful. Reference the family trees below for composition details (can do a control-F search for ntgr etc).
- useful for: encoding integer sets of unknown interpretation
- default NArowtype: 'integer'
- ntgr set includes: ord4, retn, 1010, ordl
- ntg2 set includes: ord4, retn, 1010, ordl, pwr2
- ntg3 set includes: ord4, retn, ordl, por2
Date-Time Data Normalizations
Date time processing transforms are implementations of two master functions: time and tmcs, which accept various parameters associated with suffix, time scale, and sin/cos periodicity, etc. They segment time stamps by time scale returned in separate columns. If a particular time scale is not present in training data it is omitted.
- date/dat2: for datetime formatted data, segregates data by time scale to multiple
columns (year/month/day/hour/minute/second) and then performs z-score normalization
- useful for: datetime entries of mixed time scales where periodicity is not relevant
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: includes appenders for (_year, _mnth, _days, _hour, _mint, _scnd)
- assignparam parameters accepted:
- timezone: defaults to False as passthrough, otherwise can pass time zone abbreviation (useful to consolidate different time zones such as for bus hr bins) for list of pandas accepted abbreviations see pytz.all_timezones
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: meanyear / stdyear / meanmonth / stdmonth / meanday / stdday / meanhour / stdhour / meanmint / stdmint / meanscnd / stdscnd
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: pending
- year/mnth/days/hour/mint/scnd: segregated by time scale and z-score normalization
- useful for: datetime entries of single time scale where periodicity is not relevant
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: includes appenders for (_year, _mnth, _days, _hour, _mint, _scnd)
- driftreport postmunge metrics: timemean / timemax / timemin / timestd
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: pending
- mnsn/mncs/dysn/dycs/hrsn/hrcs/misn/mics/scsn/sccs: segregated by time scale and
dual columns with sin and cos transformations for time scale period (e.g. 12 months, 24 hrs, 7 days, etc)
- useful for: datetime entries of single time scale where periodicity is relevant
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: includes appenders for (mnsn/mncs/dysn/dycs/hrsn/hrcs/misn/mics/scsn/sccs)
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: timemean / timemax / timemin / timestd
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: pending
- mdsn/mdcs: similar sin/cos treatment, but for combined month/day, note that periodicity is based on
number of days in specific months, including account for leap year, with 12 month periodicity
- useful for: datetime entries of single time scale combining months and days where periodicity is relevant
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: includes appenders for (mdsn/mdcs)
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: timemean / timemax / timemin / timestd
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: pending
- dhms/dhmc: similar sin/cos treatment, but for combined day/hour/min, with 7 day periodicity
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: includes appenders for (dhms/dhmc)
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: timemean / timemax / timemin / timestd
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: pending
- hmss/hmsc: similar sin/cos treatment, but for combined hour/minute/second, with 24 hour periodicity
- useful for: datetime entries of single time scale combining time scales where periodicity is relevant
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: includes appenders for (hmss/hmsc)
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: timemean / timemax / timemin / timestd
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: pending
- mssn/mscs: similar sin/cos treatment, but for combined minute/second, with 1 hour periodicity
- useful for: datetime entries of single time scale combining time scales below minute threshold where periodicity is relevant
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: includes appenders for (hmss/hmsc)
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: timemean / timemax / timemin / timestd
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: pending
- dat6: default transformation set for time series data, returns:
'year', 'mdsn', 'mdcs', 'hmss', 'hmsc', 'bshr', 'wkdy', 'hldy'
- useful for: datetime entries of multiple time scales where periodicity is relevant, default date-time encoding, includes bins for holidays, business hours, and weekdays
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: includes appenders for ('year', 'mdsn', 'mdcs', 'hmss', 'hmsc', 'bshr', 'wkdy', 'hldy')
- assignparam parameters accepted:
- timezone: defaults to False as passthrough, otherwise can pass time zone abbreviation (useful to consolidate different time zones such as for bus hr bins) for list of pandas accepted abbreviations see pytz.all_timezones
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: meanyear / stdyear / mean_mdsn / mean_mdcs / mean_hmss / mean_hmsc
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: pending
Date-Time Data Bins
- wkdy: boolean identifier indicating whether a datetime object is a weekday
- useful for: supplementing datetime encodings with weekday bins
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: '_wkdy' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: activationratio
- returned datatype: int8
- inversion available: pending
- wkds/wkdo: encoded weekdays 0-6, 'wkds' for one-hot via 'text', 'wkdo' for ordinal via 'ord3'
- useful for: ordinal version of preceding wkdy
- default infill: 7 (e.g. eight days a week)
- default NArowtype: datetime
- suffix appender: '_wkds' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: mon_ratio / tue_ratio / wed_ratio / thr_ratio / fri_ratio / sat_ratio / sun_ratio / infill_ratio
- returned datatype: wkds as int8, wkdo as uint8
- inversion available: pending
- mnts/mnto: encoded months 1-12, 'mnts' for one-hot via 'text', 'mnto' for ordinal via 'ord3'
- useful for: supplementing datetime encodings with month bins
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: '_mnts' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: infill_ratio / jan_ratio / feb_ratio / mar_ratio / apr_ratio / may_ratio / jun_ratio / jul_ratio / aug_ratio / sep_ratio / oct_ratio / nov_ratio / dec_ratio
- returned datatype: mnts as int8, mnto as uint8
- inversion available: pending
- bshr: boolean identifier indicating whether a datetime object falls within business
hours (9-5, time zone unaware)
- useful for: supplementing datetime encodings with business hour bins
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: '_bshr' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'start' and 'end', which default to 9 and 17
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: activationratio
- returned datatype: int8
- inversion available: pending
- hldy: boolean identifier indicating whether a datetime object is a US Federal
holiday
- useful for: supplementing datetime encodings with holiday bins
- default infill: adjinfill
- default NArowtype: datetime
- suffix appender: '_hldy' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'holiday_list', should be passed as a list of strings of dates of additional holidays to be recognized e.g. ['2020/03/30']
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: activationratio
- returned datatype: int8
- inversion available: pending
Differential Privacy Noise Injections
The DP family of transformations are for purposes of stochastic noise injection to train and/or test features. Noise is sampled by default with support of numpy.random (which as of version 1.17.0 defaults to the PCG pseudo random number generator). Supplemental entropy seedings or alternate random samplers can be applied with the automunge(.)/postmunge(.) parameters entropy_seeds and random_generator. The transforms default to injecting noise to training data and not test data, although trainnoise/testnoise parameters can be activated for any combination of the two. For cases where test data injections are not defaulted with the testnoise parameter, test data can be treated as train data for purposes of noise with the postmunge(.) traindata parameter. Please refer to the essay Noise Injections with Automunge for further detail.
Each of the DP root categories (e.g. DPnb, DPmm, DP**, etc) defaults to injecting noise to train data and not to test data (i.e. trainnoise=True, testnoise=False), however each have otherwise equivalent variations as DT root categories (e.g. DTnb, DTmm, DT**, etc) which default to injecting to test data and not to train data (i.e. trainnoise=False, testnoise=True), or as DB root categories (e.g. DBnb, DBmm, DB**, etc) which default to injecting to both train and test data (i.e. trainnoise=True, testnoise=True). In each case these defaults can be updated by parameter assigment.
Note that when passing parameters to a few of these functions (specifically the hashing variants), the transformation category associated with the transformation function may be different than the root category, as noted below DPh1/DPh2/DPhs. Note that DP transforms can be applied in conjunction with the automunge(.) or postmunge(.) noise_augment parameter to automatically prepare additional concatenated duplicates as a form of data augmentation.
For distribution sampled numeric or weighted sampling categoric categories, the DP transforms have an option to scale different segments of a feature's noise profile to correspond to different attribute segments of an adjacent protected categoric feature, which is expected to benefit loss discrepency for the attributes of that protected feature.
- DPnb: applies a z-score normalization followed by a noise injection to train data sampled
from a Gaussian which defaults to 0 mu and 0.06 sigma, but only to a subset of the data based
on flip_prob parameter.
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream nmbr (as DPn3) cleans data
- default NArowtype: numeric
- suffix appender: '_DPn3_DPnb'
- assignparam parameters accepted:
- 'noisedistribution' as {'normal', 'laplace', 'uniform'}, defaults to normal, used to select between gaussian (normal), laplace, and uniform distributed noise, also accepts one of {'abs_normal', 'abs_laplace', 'abs_uniform', 'negabs_normal', 'negabs_laplace', 'negabs_uniform'}, where the prefix 'abs' refers to injecting only positive noise by taking absolute value of sampled noise, and the prefix negabs refers to injecting only negative noise by taking the negative absolute value of sampled noise
- 'flip_prob' for percent of entries receiving noise injection, defaults to 0.03
- 'mu' for noise mean, defaults to 0
- 'sigma' for noise scale, defaults to 0.06 - note that for uniform sampling high is (sigma-mu) and low is (mu-sigma)
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- parameters should be passed to 'DPnb' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- 'rescale_sigmas': defaults as False, True rescales sigma specifications based on standard deviation of feature in training set (this option intended for use in conjunction with DPne which injects numeric noise without applying a preceding normalization)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_noisedistribution, test_flip_prob, test_mu, test_sigma}, which otherwise default to test_noisedistribution, test_mu, and test_flip_prob matching the train data parameters and test_sigma=0.03
- please note that each of the noise distribution parameters {sigma, flip_prob, test_sigma, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {mu, sigma, flip_prob, test_mu, test_sigma, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: mu, sigma for DPnm, upstream z score via nmbr for others
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- DPmm: applies a min-max scaling followed by a noise injection to train data sampled
from a Gaussian which defaults to 0 mu and 0.03 sigma. Note that noise is scaled to ensure output
remains in range 0-1 (by scaling neg noise when scaled input <0.5 and scaling pos noise when scaled input >0.5)
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream mnmx (as DPm2) cleans data
- default NArowtype: numeric
- suffix appender: '_DPm2_DPmm'
- assignparam parameters accepted:
- 'noisedistribution' as {'normal', 'laplace', 'uniform'}, defaults to normal, used to select between gaussian (normal), laplace, and uniform distributed noise, also accepts one of {'abs_normal', 'abs_laplace', 'abs_uniform', 'negabs_normal', 'negabs_laplace', 'negabs_uniform'}, where the prefix 'abs' refers to injecting only positive noise by taking absolute value of sampled noise, and the prefix negabs refers to injecting only negative noise by taking the negative absolute value of sampled noise. *Note that we recommend deactivating parameter noise_scaling_bias_offset in conjunction with abs or negabs scenarios, otherwise the sampled mean will be shifted resulting in noise with zero mean.
- 'flip_prob' for percent of entries receiving noise injection, defaults to 0.03
- 'mu' for noise mean, defaults to 0
- 'sigma' for noise scale, defaults to 0.03 - note that for uniform sampling high is (sigma-mu) and low is (mu-sigma)
- 'noise_scaling_bias_offset', boolean defaulting to True, activates an evaluation of scaled noise to offset the sampled noise mean to closer approximate a resulting zero mean for the scaled noise (helps to mitigate potential for bias from noise scaling in cases of imbalanced feature distribution).
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- parameters should be passed to 'DPmm' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_noisedistribution, test_flip_prob, test_mu, test_sigma}, which otherwise default to test_noisedistribution, test_mu, and test_flip_prob matching the train data parameters and test_sigma=0.02
- please note that each of the noise distribution parameters {sigma, flip_prob, test_sigma, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {mu, sigma, flip_prob, test_mu, test_sigma, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: mu, sigma for DPnm, upstream minmax via mnmx for others
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- DPrt: applies a retn normalization with a noise injection to train data sampled
from a Gaussian which defaults to 0 mu and 0.03 sigma. Note that noise is scaled to ensure output
remains in range 0-1 (by scaling neg noise when scaled and centered input <0.5 and scaling pos noise when scaled and centered input >0.5)
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: comparable to retn with mean (calculated before noise injection)
- suffix appender: '_DPrt' in base configuration or based on the family tree category
- assignparam parameters accepted:
- parameters comparable to retn divisor / offset / multiplier / cap / floor / stdev_cap defaulting to 'minmax'/0/1/False/False/False, also
- 'noisedistribution' as {'normal', 'laplace', 'uniform'}, defaults to normal, used to select between gaussian (normal), laplace, and uniform distributed noise, also accepts one of {'abs_normal', 'abs_laplace', 'abs_uniform', 'negabs_normal', 'negabs_laplace', 'negabs_uniform'}, where the prefix 'abs' refers to injecting only positive noise by taking absolute value of sampled noise, and the prefix negabs refers to injecting only negative noise by taking the negative absolute value of sampled noise. *Note that we recommend deactivating parameter noise_scaling_bias_offset in conjunction with abs or negabs scenarios, otherwise the sampled mean will be shifted resulting in noise with zero mean.
- 'mu' for noise mean, defaults to 0,
- 'sigma' for noise scale, defaults to 0.03 - note that for uniform sampling high is (sigma-mu) and low is (mu-sigma)
- 'flip_prob' for percent of entries receiving noise injection, defaults to 0.03
- 'noise_scaling_bias_offset', boolean defaulting to True, activates an evaluation of scaled noise to offset the sampled noise mean to closer approximate a resulting zero mean for the scaled noise (helps to mitigate potential for bias from noise scaling in cases of imbalanced feature distribution)
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- Parameters should be passed to 'DPrt' transformation category from family tree.
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_noisedistribution, test_flip_prob, test_mu, test_sigma}, which otherwise default to test_noisedistribution, test_mu, and test_flip_prob matching the train data parameters and test_sigma=0.02
- please note that each of the noise distribution parameters {sigma, flip_prob, test_sigma, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {mu, sigma, flip_prob, test_mu, test_sigma, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: mu, sigma, flip_prob for DPrt, also metrics comparable to retn
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- DLmm/DLnb/DLrt: comparable to DPmm/DPnb/DPrt but defaults to laplace distributed noise instead of gaussian (normal) with same parameters accepted (where mu is center of noise, sigma is scale, and flip-prob is ratio) and with same default parameter values
- DPqt/DPbx: numeric noise injections with distribution conversions by the qttf/bxcx transforms
- DPbn: applies a two value binary encoding (bnry) followed by a noise injection to train data which
flips the activation per parameter flip_prob which defaults to 0.03
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream bnry (as DPb2) cleans data
- default NArowtype: justNaN
- suffix appender: '_DPb2_DPbn'
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'weighted' boolean defaults to True for weighted noise sampling from set of unique entries in train data. When False noise sampling is by a uniform draw from set of unique entries as found in train data (which is a little more computationally efficient).
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPbn' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: flip_prob for DPbn, upstream binary via bnry for others
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- DPod: applies an ordinal encoding (ord3) followed by a noise injection to train data which
flips the activations per parameter flip_prob which defaults to 0.03 to a weighted random draw from the
set of activations (including the current activation so actual flip percent is < flip_prob based
on number of activations)
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream ord3 (as DPo4) cleans data
- default NArowtype: justNaN
- suffix appender: '_DPo4_DPod'
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'weighted' boolean defaults to True for weighted noise sampling from set of unique entries in train data. When False noise sampling is by a uniform draw from set of unique entries as found in train data (which is a little more computationally efficient).
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPod' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- 'passthrough': defaults to False, when True the data type conversion is turned off to allow DPod to be applie for pass-through categoric
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: flip_prob for DPod, upstream ordinal via ord3 for others
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes
- DPoh: applies a one hot encoding followed by a noise injection to train data which
flips the activations per parameter flip_prob which defaults to 0.03 to a weighted random draw from the
set of activations (including the current activation so actual flip percent is < flip_prob based
on number of activations). Note that assignparam for noise injection
can be passed directly to DPoh.
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream ord3 (as DPo5) cleans data
- default NArowtype: justNaN
- suffix appender: 'DPo5_#_DPoh' where # is integer for each categoric entry
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'weighted' boolean defaults to True for weighted noise sampling from set of unique entries in train data. When False noise sampling is by a uniform draw from set of unique entries as found in train data (which is a little more computationally efficient).
- 'swap_noise' boolean defaults False, instead of a random flip to alternate activation, randomly samples from feature rows. Has a similar effect as weighted sampling, however when injecting to test data requires multiple samples for comparable effect
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPo2' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: comparable to onht
- returned datatype: int8
- inversion available: yes
- DP10: applies a binarization followed by a noise injection to train data which
flips the activations per parameter flip_prob which defaults to 0.03 to a weighted random draw from the
set of activations (including the current activation so actual flip percent is < flip_prob based
on number of activations). Note that assignparam for noise injection
can be passed directly to DP10.
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream ord3 (as DPo6) cleans data
- default NArowtype: justNaN
- suffix appender: 'DPo6_#_DP10' where # is integer for each column which collectively encode categoric entries
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'weighted' boolean defaults to True for weighted noise sampling from set of unique entries in train data. When False noise sampling is by a uniform draw from set of unique entries as found in train data (which is a little more computationally efficient).
- 'swap_noise' boolean defaults False, instead of a random flip to alternate activation, randomly samples from feature rows. Has a similar effect as weighted sampling, however when injecting to test data requires multiple samples for comparable effect
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPo3' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: comparable to 1010
- returned datatype: int8
- inversion available: yes
- DPh1: applies a multi column hash binarization via hs10 followed by a multi column categoric noise injection via DPmc, which
flips the activation sets per parameter flip_prob which defaults to 0.03 to a weighted random draw from the
set of activation sets (including the current activation set so actual flip percent is < flip_prob based
on number of activations). Note that assignparam for noise injection
can be passed to the intermediate category DPo3 which applies the DPod transform. Defaults to weighted sampling.
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream hs10 cleans data
- default NArowtype: justNaN
- suffix appender: '\DPh1_#_DPmc' where # is integer for each column which collectively encode categoric entries
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'swap_noise' boolean defaults False, instead of a random flip to alternate activation, randomly samples from feature rows. Has a similar effect as weighted sampling, however when injecting to test data requires multiple samples for comparable effect
- 'weighted' boolean defaults to True for weighted noise sampling from set of unique entries in train data. When False noise sampling is by a uniform draw from set of unique entries as found in train data (which is a little more computationally efficient).
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPmc' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: hs10 metrics
- returned datatype: int8
- inversion available: yes
- DPhs: applies a multi column hash binarization via hash followed by a multi column categoric noise injection via mlhs, which flips the activations in each column individually per parameter flip_prob which defaults to 0.03 to a weighted random draw from the set of activations (including the current activation so actual flip percent is < flip_prob based on number of activations). assign_param for mlhs requires passing parameters to DPod through the mlti assignparam norm_params as noted below, and any noise distribution parameters should be redundantly passed to the mlhs call for purposes of setting entropy seeds. For example:
assignparam = {'mlhs' :
{'targetinputcolumn' :
{'testnoise' : True,
'norm_params' : {'testnoise' : True}}}}
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream hs10 cleans data
- default NArowtype: justNaN
- suffix appender: '\DPhs_#_mlhs_DPod' where # is integer for each column which collectively encode categoric entries
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'weighted' boolean defaults to True for weighted noise sampling from set of unique entries in train data. When False noise sampling is by a uniform draw from set of unique entries as found in train data (which is a little more computationally efficient).
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- DPod noise injection assignparam parameters can be passed to the mlhs parameter 'norm_params' embedded in a dictionary (e.g. assignparam = {'mlhs' : {inputcolumn : {'norm_params' : {'flip_prob' : 0.05}}}} ) Defaults to weighted sampling. (The norm_params approach is associated with use of the mlti transform which is what mlhs applies)
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: hash metrics
- returned datatype: conditional integer based on hashing vocab size
- inversion available: yes
- DPh2: applies a single column hash binarization via hsh2 followed by a single column categoric noise injection via DPod function (as DPo7), which
flips the activations per parameter flip_prob which defaults to 0.03 to a weighted random draw from the
set of activations (including the current activation so actual flip percent is < flip_prob based
on number of activations).
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream hs10 cleans data
- default NArowtype: justNaN
- suffix appender: '\DPh2_DPo7'
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'weighted' boolean defaults to True for weighted noise sampling from set of unique entries in train data. When False noise sampling is by a uniform draw from set of unique entries as found in train data (which is a little more computationally efficient).
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPo7' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- 'protected_feature' defaults to False, accepts input column header string specifiation, scales different segments of this transform's target feature's noise profile to correspond to different attribute segments of specified adjacent protected categoric feature, which the hypothesis is that this may benefit loss discrepency for the attributes of that protected feature
- driftreport postmunge metrics: hash metrics
- returned datatype: conditional integer based on hashing vocab size
- inversion available: yes
- DPns: applies a z-score normalization via nmbr followed by a swap_noise injection by DPmc, which for noise targets randomly samples between other rows in the feature. Swap noise is an alternate convention than the distribution sampling applied in DPnb.
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream transform cleans data
- default NArowtype: justNaN
- suffix appender: '\DPn4_DPns'
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'swap_noise' boolean defaults True, randomly samples from rows (we don't recommend the False scenario when applied downstream of continuous features which is intended for injection to categoric features)
- 'weighted' - not supported in conjunction with swap_noise = True
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPmc' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- driftreport postmunge metrics: nmbr metrics
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- DP1s: applies a 1010 binarization followed by a swap_noise injection by DPmc, which for noise targets randomly samples between other rows in the feature. Swap noise is an alternate convention than the weighted sampling applied in DP10.
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: the DP function does not apply a default infill assume upstream transform cleans data
- default NArowtype: justNaN
- suffix appender: 'DPo8_#_DP1s' where # is integer for each column which collectively encode categoric entries
- assignparam parameters accepted:
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'swap_noise' boolean defaults True, randomly samples from rows (the False scenario results in an encoding comparable to DP10)
- 'weighted' - not supported in conjunction with swap_noise = True
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPmc' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob, test_weighted}, which otherwise default to test_weighted matching the train data and test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- driftreport postmunge metrics: 1010 metrics
- returned datatype: int8
- inversion available: yes
- DPsk: applies a masking of sampled entries with a mask_value defaulting to the integer 0. As configured in default process_dict specification treats data as full pass-through without NArow aggregation or infill, similar to DPne and DPse noted below. Can also be used to add discrete noise to continuous features by the additive parameter.
- useful for: noise injection for data augmentation, model perturbation for ensembles, differential privacy
- default infill: does notapply infill
- default NArowtype: exclude
- suffix appender: '_DPsk'
- assignparam parameters accepted:
- 'mask_value' the value injected to masked entries, defaults to integer 0
- 'additive' boolean defaults as False, for adding discrete noise to continuous numeric features, results in mask value being added to selected entries instead of replaced
- 'flip_prob' for percent of activation flips (defaults to 0.03),
- 'trainnoise' defaults to True, when False noise is not injected to training data in automunge or postmunge
- 'testnoise' defaults to False, when True noise is injected to test data in both automunge and postmunge by default
- noise injection parameters should be passed to 'DPsk' transformation category from family tree
- 'suffix': to change suffix appender (leading underscore added internally)
- when activating testnoise, test data specific noise distribution parameters can be passed to {test_flip_prob}, which otherwise default to test_flip_prob = 0.01
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as list of candidate values for a unique sampling applied in automunge and postmunge.
- please note that each of the noise distribution parameters {flip_prob, test_flip_prob} can be passed as scipy.stats distribution for a uniquely sampled value with each application (this was implemented to support some experiments associated with noise_augment).
- 'retain_basis' accepts boolean defaulting to False, the use is associated with parameters passed as lists or distributions, when True the sampled basis from automunge(.) is carried through to postmunge(.) instead of a unique sampling for each
- the DP transforms also accept parameters random_generator and sampling_resource_dict which are derived internally based on automunge or postmunge parameters
- driftreport postmunge metrics: mask_value, other noise parameters
- returned datatype: consistent with input
- inversion available: yes
- DPse: for full pass-through other than swap noise injection (i.e. may be applied to numeric or categoric features with string entries). Comparable parameters supported to DPmc (swap_noise defaults to True). Only other edits are suffix appender on the returned column header. Excluded from ML infill and NArw aggregation. DPse may be suitable for incorporating noise injections to categoric test features into a prior prepared pipeline. A similar pass-through transform for numeric features with distribution sampled injections is available as DPne as noted above. Note that this can be applied to multi-column input sets by assigncat specification that replaces a single input header string with a {set} of input header strings.
- DPpc: for full pass-through other than weighted categoric injection (may be applie to categoric features with both numeric and string entries). Comparable parameter support to DPod (passthrough defaults to True). Excluded from ML infill and NArw aggregation. DPpc is an alternate to DPse for passthrough noise to categoric sets that fits the noise weightings to the train data as opposed to mathcing the train or test profile. Also has benefit fo protected_feature support.
- DPmp: similar to DPpc but can be applied to multi-column sets, such as e.g. to inject noise into one hot encoded categoric features. Can be applied to multi-column input sets by assigncat specification that replaces a single input header string with a {set} of input header strings.
- DPne: for full pass-through other than numeric noise injection (i.e. no normalization applied). Comparable parameters supported to DPnb, samples gaussian by default also has laplace support. Note that for DPne the rescale_sigmas option defaults to True such that specified sigma parameters are rescaled by multiplication with the training set standard deviation, thus allowing common default sigma options independant of feature scale. For user specified sigma parameters they will also be rescaled unless rescale_sigmas has been deactivated. Only other edits to returned feature other than noise injection are conversion to float dtype / non numeric to NaN and suffix appender on the returned column header. Excluded from ML infill and NArw aggregation. DPne may be suitable for incorporating noise injections to numeric test features into a prior prepared pipeline. Includes protected_feature support.
Please note that DPse (passthrough swap noise e.g. for categoric), DPne (passthrough gaussian or laplace noise for numeric), DPsk (passthrough mask noise for numeric or categoric), and excl (passthrough without noise) can be used in tandem to pass a dataframe to automunge(.) for noise injection without other edits or infill, such as could be used to incorporate noise into an existing tabular pipeline. When limited to these three root categories the returned dataframe will match the same order of columns with only edits other than noise as updated column headers and DPne will overide any data types other than float. (To retain same order of rows can deactivate shuffletrain parameter.)
Misc. Functions
- excl: passes source column un-altered, no transforms, data type conversion, or infill. The feature is excluded from ML infill basis of all other features. If a passthrough column is desired to be included in ML infill basis for surrounding features, it should instead be passed to one of the other passthrough transforms, such as exc2 for continuous numeric, exc5 for ordinal encoded integers, or exc8 for continuous integers. Data returned from excl may be non-numeric. excl has a special suffix convention in the library in that the column is returned without a suffix appender (to signify full pass-through), if suffix retention is desired it is available by the automunge(.) excl_suffix parameter.
Note that for assignnan designation of infill conversions, excl is excluded from 'global' assignments
(although may still be assigned explicitly under assignnan columns or categories entries). excl also retains original form of entries that for other transforms are converted to missing data markers, such as None or inf.
- useful for: full passthrough sets
- default infill: none
- default NArowtype: exclude
- suffix appender: None or '_excl' (dependent on automunge(.) excl_suffix parameter)
- assignparam parameters accepted: none
- driftreport postmunge metrics: none
- returned datatype: retains data type of received data
- inversion available: yes
- exc2/exc3/exc4/exc6: passes source column unaltered other than force to numeric, adjinfill applied
(exc3 and exc4 have downstream standard deviation or power of 10 bins aggregated such as may be beneficial
when applying TrainLabelFreqLevel to a numeric label set). For use without NArw aggregation use exc6/
- useful for: numeric pass-through sets, feature included in surrounding ML infill models
- default infill: adjinfill
- default NArowtype: numeric
- suffix appender: '_exc2' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: none
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes
- exc5/exc8: passes source column unaltered other than force to numeric, adjinfill applied for non-integers. exc5 is for ordinal encoded integers, exc8 is for continuous integers. For use without NArw aggregation use exc7/exc9
- useful for: passthrough integer sets, feature included in surrounding ML infill models
- default infill: adjinfill
- default NArowtype: integer
- suffix appender: '_exc5' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- 'integertype': sets the convention for returned datatype exc5 defaults to 'singlct', exc8 defaults to 'integer'
- driftreport postmunge metrics: none
- returned datatype: exc5 is conditional uint based on size of encoding space, exc8 is int32
- inversion available: yes
- eval: performs data property evaluation consistent with default automation to designated column
- useful for: applying automated evaluation to distinct columns for cases where default automated evaluation turned off by powertransform='excl'
- default infill: based on evaluation
- default NArowtype: based on evaluation
- suffix appender: based on evaluation
- assignparam parameters accepted: none
- driftreport postmunge metrics: none
- returned datatype: based on transformation applied
- inversion available: contingent on result
- ptfm: performs distribution property evaluation consistent with the automunge powertransform
parameter activated to designated column
- useful for: applying automated powertransform evaluation to distinct columns
- default infill: based on evaluation
- default NArowtype: based on evaluation
- suffix appender: based on evaluation
- assignparam parameters accepted: none
- driftreport postmunge metrics: none
- returned datatype: based on transformation applied
- inversion available: contingent on result
- copy: create new copy of column, may be used when applying the same transform to same column more
than once with different parameters as an alternate to defining a distinct category processdict entry for each redundant application.
This also may be useful when defining a family tree where the shortest path isn't the desired inversion path, in which case
can add some intermediate copy operations to shortest path until inversion selects the desired path
(as inversion operates on heuristic of selecting shortest transformation path with full information retention,
unless full information retention isn't available then the shortest path without full information retention).
Does not prepare column for ML on its own (e.g. returned data will carry forward non-numeric entries and will not conduct infill).
- default infill: exclude
- default NArowtype: exclude
- suffix appender: '_copy' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: none
- returned datatype: consistent with input
- inversion available: yes
- shfl: shuffles the values of a column based on passed randomseed (Note that returned data may not
be numeric and predictive methods like ML infill and feature selection may not work for that scenario
unless an additional transform is applied downstream.)
- useful for: shuffle useful to negate feature from influencing inference
- default infill: naninfill
- default NArowtype: justNAN
- suffix appender: '_shfl' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: none
- returned datatype: consistent with input
- inversion available: no
- mlti: mlti is a category that may take as input a set of one or more columns returned from an upstream transform, for example this could be a multi-column set returned from a concurrent_nmbr containing multiple columns of continuous numeric entries (or otherwise take a single column input when applied to an upstream primitive). mlti applies a normalization to each of the columns on an independent basis. The normalization defaults to z-score via nmbr or alternate transforms may be designated by assignparam. (Currently mlti is not defined as a root category, but is available for use as a tree category.) mlti is defined in process_dict based on concurrent_nmbr MLinfilltype. mlti may be used to apply an arbitrary transformation category to each column from a set of columns returned from a transform (such as for a concurrent MLinfilltype). The MLinfilltype basis for mlti is concurrent_nmbr, meaning it assumes returned columns are continuous numeric. For concurrent_ordl MLinfilltype can either overwrite processdict or make use of mlto. Returned concurrent_act support is available by overwriting the processdict entry.
- useful for: normalizing a set of numeric features returned from an upstream transform
- default infill: consistent with the type of normalization selected
- default NArowtype: justNaN
- suffix appender: '_mlti_' + suffix associated with the normalization
- assignparam parameters accepted:
- 'norm_category': defaults to 'nmbr', used to specify type of normalization applied to each column. Used to access transformation functions from process_dict.
- 'norm_params': defaults to empty dictionary {}, used to pass parameters to the normalization transform, e.g. as {parameter : value}. Note that parameters can also be passed to the norm_category through the assignparam automunge(.) parameter, with any specifications (such as to global_assignparam or default_assignparam) taking precedence over specifications through norm_params.
- 'dtype': accepts one of {'float', 'conditionalinteger', 'mlhs'}, defaults to float. conditionalinteger is for use with mlto. 'mlhs' is for use with mlhs.
- driftreport postmunge metrics: records drift report metrics included with the normalization transform
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: based on normalization transform inversion (if norm_category does not support inversion a passthrough inversion is applied)
- mlto: comparable to mlti but intended for use with returning multiple ordinal encoded columns. mlto is defined in process_dict based on concurrent_ordl MLinfilltype.
- useful for: ordinal encoding a set of categoric features returned from an upstream transform
- default infill: consistent with the type of ordinal encoding selected
- default NArowtype: justNaN
- suffix appender: '_mlto_' + suffix associated with the normalization
- assignparam parameters accepted:
- 'norm_category': defaults to 'ord3', used to specify type of ordinal encoding applied to each column. Used to access transformation functions from process_dict.
- 'norm_params': defaults to empty dictionary {}, used to pass parameters to the normalization transform, e.g. as {parameter : value}
- 'dtype': accepts one of {'float', 'conditionalinteger', 'mlhs'}, defaults to conditionalinteger.
- driftreport postmunge metrics: records drift report metrics included with the normalization transform
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: based on normalization transform inversion (if norm_category does not support inversion a passthrough inversion is applied)
- bnst/bnso: intended for use downstream of multicolumn boolean integer sets, such as those returned from MLinfilltype multirt, 1010, concurrent_act. bnst serves to aggregate the multicolumn representation into a single column encoding. bnst returns a string representation, bnso performs a downstream ordinal encoding. Intended for sets with boolean integer entries.
- useful for: some downstream libraries prefer label sets in single column representations. This allows user to convert a multicolumn to single column for this or some other purpose.
- default infill: zeroinfill (assumes infill performed upstream.)
- default NArowtype: justNaN
- suffix appender: '_bnst'
- assignparam parameters accepted:
- suffix: defaults to tree category, accepts string
- upstreaminteger: defaults to True for boolean integer input, when False can receive other single character entries, although inversion not supported for the False scenario
- driftreport postmunge metrics: none
- returned datatype: bnst returns string, bnso conditional integer per downstream ordinal encoding
- inversion available: supported for upstreaminteger True scenario, False performs a passthrough inversion without recovery
- GPS1: for converting sets of GPS coordinates to normalized latitude and longitude, relies on comma separated inputs, with latitude/longitude reported as DDMM.... or DDDMM.... and direction as one of 'N'/'S' or 'E'/'W'. Note that with GPS data, depending on the application, there may be benefit to setting the automunge(.) floatprecision parameter to 64 instead of the default 32. If you want to apply ML infill or some other assigninfill on the returned sets, we recommend ensuring missing data is received as NaN, otherwise missing entries will receive adjinfill.
- useful for: converting GPS coordinates to normalized latitude and normalized longitude
- default infill: adjinfill
- default NArowtype: justNaN
- suffix appender: _GPS1_latt_mlti_nmbr and _GPS1_long_mlti_nmbr
- assignparam parameters accepted:
- 'GPS_convention': accept one of {'default', 'nonunique'}, under default all rows are individually parsed. nonunique is used in GPS3 and GPS4.
- 'comma_addresses': accepts as list of 4 integers, defaulting to [2,3,4,5], which corresponds to default where latitude located after comma 2, latitude direction after comma 3, longitude after comma 4, longitude direction after comma 5
- 'comma_count': an integer, defaulting to 14, used in inversion to pad out commas on the recovered data format
- driftreport postmunge metrics: metrics included with the downstream normalization transforms
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with partial recovery e.g. for default configuration recovers data in the form ",,DDMM.MMMMMMM,C,DDMM.MMMMMMM,C,,,,,,,,," (where C is the direction)
- GPS2: comparable to GPS1 but without the downstream normalization, so returns floats in units of arc minutes. (If you want missing data returned as NaN instead of adjinfill, can set process_dict entry NArowtype to 'exclude'.)
- GPS3: comparable to GPS1, including downstream normalization, but only unique entries are parsed instead of all rows. Parses unique entries in both the train and test set. This may benefit latency in cases of redundant entries.
- GPS4: comparable to GPS1, including downstream normalization, but only unique entries are parsed instead of all rows. Parses unique entries in the train set and relies on assumption that the set of unique entries in test set will be the same or a subset of the train set, which may benefit latency for this scenario.
- GPS5: comparable to GPS3 but performs a downstream ordinal encoding instead of normalization, as may be desired when treating a fixed range of GPS coordinates as a categoric feature, latitude and longitude encoded separately.
- GPS6: comparable to GPS3 but performs both a downstream ordinal encoding and a downstream normalization, such as to treat latitude and longitude both as categoric and continuous numeric features. This is probably a better default than GPS3 or GPS5 for fixed range of entries.
- NArw: produces a column of boolean integer identifiers for rows in the source
column with missing or improperly formatted values. Note that when NArw
is assigned in a family tree it bases NArowtype on the root category,
when NArw is passed as the root category it bases NArowtype on default.
- useful for: supplementing any transform with marker for missing entries. On by default by NArw_marker parameter
- default infill: not applicable
- default NArowtype: justNaN
- suffix appender: '_NArw' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: pct_NArw
- returned datatype: int8
- inversion available: no
- NAr2: produces a column of boolean identifiers for rows in the source
column with missing or improperly formatted values.
- useful for: similar to NArw but different default NArwtype for when used as a root category
- default infill: not applicable
- default NArowtype: numeric
- suffix appender: '_NAr2' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: pct_NArw
- returned datatype: int8
- inversion available: no
- NAr3: produces a column of boolean identifiers for rows in the source
column with missing or improperly formatted values.
- useful for: similar to NArw but different default NArwtype for when used as a root category
- default infill: not applicable
- default NArowtype: positivenumeric
- suffix appender: '_NAr3' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: pct_NArw
- returned datatype: int8
- inversion available: no
- NAr4: produces a column of boolean identifiers for rows in the source
column with missing or improperly formatted values.
- useful for: similar to NArw but different default NArwtype for when used as a root category
- default infill: not applicable
- default NArowtype: nonnegativenumeric
- suffix appender: '_NAr4' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: pct_NArw
- returned datatype: int8
- inversion available: no
- NAr5: produces a column of boolean identifiers for rows in the source
column with missing or improperly formatted values.
- useful for: similar to NArw but different default NArwtype for when used as a root category
- default infill: not applicable
- default NArowtype: integer
- suffix appender: '_NAr5' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: pct_NArw
- returned datatype: int8
- inversion available: no
- null: deletes source column
- default infill: none
- default NArowtype: exclude
- no suffix appender, column deleted
- assignparam parameters accepted: none
- driftreport postmunge metrics: none
- returned datatype: N/A
- inversion available: no
Parsed Categoric Encodings
Please note I recommend caution on using splt/spl2/spl5/spl6 transforms on categorical sets that may include scientific units for instance, as prefixes will not be noted for overlaps, e.g. this wouldn't distinguish between kilometer and meter for instance. Note that overlap lengths below 5 characters are ignored unless that value is overridden by passing 'minsplit' parameter through assignparam. Further detail on parsed categoric encodings provided in the essay Parsed Categoric Encodings with Automunge.
- splt: searches categorical sets for overlaps between string character subsets and returns new boolean column
for identified overlap categories. Note this treats numeric values as strings e.g. 1.3 = '1.3'.
Note that priority is given to overlaps of higher length, and by default overlap go down to 5 character length.
- useful for: extracting grammatical structure shared between entries
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_splt_####' where #### is target identified string overlap
- assignparam parameters accepted:
- 'minsplit': indicating lowest character length for recognized overlaps
- 'space_and_punctuation': True/False, defaults to True, when passed as False character overlaps are not recorded which include space or punctuation based on characters in excluded_characters parameter
- 'excluded_characters': a list of strings which are excluded from overlap
identification when space_and_punctuation set as False, defaults to
[' ', ',', '.', '?', '!', '(', ')'] - 'concurrent_activations': defaults as False, True makes comparable to sp15, although recommend using sp15 instead for correct MLinfilltype
- 'suffix': returned column suffix appender, defaults to 'splt'
- 'int_headers': True/False, defaults as False, when True returned column headers are encoded with integers, such as for privacy preserving of data contents
- 'test_same_as_train': defaults False, True makes this comparable to spl8
- driftreport postmunge metrics: overlap_dict / splt_newcolumns_splt / minsplit
- returned datatype: int8
- inversion available: yes with partial recovery
- sp15: similar to splt, but allows concurrent activations for multiple detected overlaps (spelled sp-fifteen)
Note that this version runs risk of high dimensionality of returned data in comparison to splt.
- useful for: extracting grammatical structure shared between entries with increased information retention vs splt
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_sp15_####' where #### is target identified string overlap
- assignparam parameters accepted:
- comparable to splt, with concurrent_activations as True
- driftreport postmunge metrics: overlap_dict / splt_newcolumns_sp15 / minsplit
- returned datatype: int8
- inversion available: yes with partial recovery
- sp19: comparable to sp15, but with returned columns aggregated by a binary encoding to reduce dimensionality
- useful for: extracting grammatical structure shared between entries with decreased dimensionality vs sp15
- default infill: distinct encoding
- default NArowtype: justNaN
- suffix appender: '_sp19_#' where # is integer associated with the encoding
- assignparam parameters accepted: comparable to sp15
- driftreport postmunge metrics: comparable to sp15 with addition of _1010_activations_dict for activation ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- sbst: similar to sp15, but only detects string overlaps shared between full unique entries and subsets of longer character length entries
- useful for: extracting cases of overlap between full entries and subsets of other entries
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_sbst_####' where #### is target identified string overlap
- assignparam parameters accepted:
- 'int_headers': True/False, defaults as False, when True returned column headers are encoded with integers, such as for privacy preserving of data contents
- 'minsplit': indicating lowest character length for recognized overlaps, defaults to 1
- 'concurrent_activations': True/False, defaults to True, when True entries may have activations for multiple simultaneous overlaps
- 'test_same_as_train': defaults False, True makes this comparable to sbs2
- 'suffix': returned column suffix appender, defaults to 'sbst'
- driftreport postmunge metrics: overlap_dict / splt_newcolumns_sbst / minsplit
- returned datatype: int8
- inversion available: yes with partial recovery
- sbs3: comparable to sbst, but with returned columns aggregated by a binary encoding to reduce dimensionality
- useful for: binary version of sbst for reduced dimensionality
- default infill: distinct encoding
- default NArowtype: justNaN
- suffix appender: '_sbs3_#' where # is integer associated with the encoding
- assignparam parameters accepted: comparable to sbst
- driftreport postmunge metrics: comparable to sbst with addition of _1010_activations_dict for activation ratios
- returned datatype: int8
- inversion available: yes with partial recovery
- spl2/ors2/ors6/txt3: similar to splt, but instead of creating new column identifier it replaces categorical
entries with the abbreviated string overlap
- useful for: similar to splt but returns single column, used in aggregations like or19
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_spl2' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'minsplit': indicating lowest character length for recognized overlaps
- 'space_and_punctuation': True/False, defaults to True, when passed as False character overlaps are not recorded which include space or punctuation based on characters in excluded_characters parameter
- 'excluded_characters': a list of strings which are excluded from overlap
identification when space_and_punctuation set as False, defaults to
[' ', ',', '.', '?', '!', '(', ')'] - 'test_same_as_train': defaults False, True makes this comparable to spl9
- 'suffix': returned column suffix appender, defaults to 'spl2'
- 'consolidate_nonoverlaps': defaults to False, True makes this comparable to spl5
- driftreport postmunge metrics: overlap_dict / spl2_newcolumns / spl2_overlap_dict / spl2_test_overlap_dict / minsplit
- returned datatype: str (other categoric encodings can be returned downstream to return numeric)
- inversion available: yes with partial recovery
- spl5/ors5: similar to spl2, but those entries without identified string overlap are set to 0,
(used in ors5 in conjunction with ord3)
- useful for: final tier of spl2 aggregations such as in or19
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_spl5' in base configuration or based on the family tree category
- assignparam parameters accepted:
- comparable to spl2, consolidate_nonoverlaps as True
- driftreport postmunge metrics: overlap_dict / spl2_newcolumns / spl2_overlap_dict / spl2_test_overlap_dict / spl5_zero_dict / minsplit
- returned datatype: str (other categoric encodings can be returned downstream to return numeric)
- inversion available: yes with partial recovery
- spl6: similar to spl5, but with a splt performed downstream for identification of overlaps
within the overlaps
- useful for: just a variation on parsing aggregations
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_spl6' in base configuration or based on the family tree category
- assignparam parameters accepted:
- comparable to spl2
- driftreport postmunge metrics: overlap_dict / spl2_newcolumns / spl2_overlap_dict / spl2_test_overlap_dict / spl5_zero_dict / minsplit
- returned datatype: int8
- inversion available: yes with partial recovery
- spl7: similar to spl5, but recognizes string character overlaps down to minimum 2 instead of 5
- useful for: just a variation on parsing aggregations
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_spl7' in base configuration or based on the family tree category
- assignparam parameters accepted:
- comparable to spl5, minsplit defaults to 2
- driftreport postmunge metrics: overlap_dict / srch_newcolumns_srch / search
- returned datatype: int8
- inversion available: yes with partial recovery
- srch: searches categorical sets for overlaps with user passed search string and returns new boolean column
for identified overlap entries.
- useful for: identifying specific entry character subsets by search
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_srch_####' where #### is target identified search string
- assignparam parameters accepted:
- 'search': a list of strings, defaults as empty set (note search parameter list can included embedded lists of terms for aggregated activations of terms in the sub-list)
- 'case': bool to indicate case sensitivity of search, defaults True
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: overlap_dict / splt_newcolumns_splt / minsplit
- returned datatype: int8
- inversion available: yes with partial recovery
- src2: comparable to srch but expected to be more efficient when target set has narrow range of entries
- useful for: similar to srch slight variation on implementation
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_src2_####' where #### is target identified search string
- assignparam parameters accepted:
- 'search': a list of strings, defaults as empty set (note search parameter list can included embedded lists of terms for aggregated activations of terms in the sub-list)
- 'case': bool to indicate case sensitivity of search, defaults True
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: overlap_dict / splt_newcolumns_splt / minsplit
- returned datatype: int8
- inversion available: yes with partial recovery
- src3: comparable to src2 with additional support for test set entries not found in train set
- src4: searches categorical sets for overlaps with user passed search string and returns ordinal column
for identified overlap entries. (Note for multiple activations encoding priority given to end of list entries).
- useful for: ordinal version of srch
- default infill: none
- default NArowtype: justNaN
- suffix appender: '_src4' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'search': a list of strings, defaults as empty set (note search parameter list can included embedded lists of terms for aggregated activations of terms in the sub-list)
- 'case': bool to indicate case sensitivity of search, defaults True
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: overlap_dict / splt_newcolumns_splt / minsplit
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: yes with partial recovery
- nmrc/nmr2/nmr3: parses strings and returns any number groupings, prioritized by longest length
- useful for: extracting numeric character subsets of entries
- default infill: mean
- default NArowtype: parsenumeric
- suffix appender: '_nmrc' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: overlap_dict / mean / maximum / minimum
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- nmcm/nmc2/nmc3: similar to nmrc, but recognizes numbers with commas, returns numbers stripped of commas
- useful for: extracting numeric character subsets of entries, recognizes commas
- default infill: mean
- default NArowtype: parsenumeric
- suffix appender: '_nmcm' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: overlap_dict / mean / maximum / minimum
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- nmEU/nmE2/nmE3: similar to nmcm, but recognizes numbers with period or space thousands delimiter and comma decimal
- useful for: extracting numeric character subsets of entries, recognizes EU format
- default infill: mean
- default NArowtype: parsenumeric
- suffix appender: '_nmEU' in base configuration or based on the family tree category
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: overlap_dict / mean / maximum / minimum
- returned datatype: based on automunge(.) floatprecision parameter (defaults to float32)
- inversion available: yes with full recovery
- strn: parses strings and returns any non-number groupings, prioritized by longest length, followed by ord3 ordinal encoding
- useful for: extracting nonnumeric character subsets of entries
- default infill: naninfill
- default NArowtype: justNaN
- suffix appender: '_strn_ord3'
- assignparam parameters accepted:
- 'suffix': to change suffix appender (leading underscore added internally)
- driftreport postmunge metrics: overlap_dict
- returned datatype: conditional based on size of encoding space (uint8 / uint16 / uint32)
- inversion available: pending
More Efficient Parsed Categoric Encodings
- new processing functions nmr4/nmr5/nmr6/nmc4/nmc5/nmc6/nmE4/nmE5/nmE6/spl8/spl9/sp10 (spelled sp"ten")/sp16/src2/sbs2/sp20/sbs4:
- comparable to functions nmrc/nmr2/nmr3/nmcm/nmc2/nmc3/nmEU/nmE2/nmE3/splt/spl2/spl5/sp15/srch/sbst/sp19/sbs3
- but make use of new assumption that set of unique values in test set is same or a subset of those values from the train set, which allows for a more efficient application (no more string parsing of test sets)
- default infill: comparable
- default NArowtype: comparable
- suffix appender: same format, updated per the new category
- assignparam parameters accepted: comparable
- driftreport postmunge metrics: comparable
- returned datatype: comparable
- inversion available: yes
- new processing functions nmr7/nmr8/nmr9/nmc7/nmc8/nmc9/nmE7/nmE8/nmE9:
- comparable to functions nmrc/nmr2/nmr3/nmcm/nmc2/nmc3/nmEU/nmE2/nmE3
- but implements string parsing only for unique test set entries not found in train set
- for more efficient test set processing in automunge and postmunge
- (less efficient than nmr4/nmc4 etc but captures outlier points as may not be unusual in continuous distributions)
- default infill: comparable
- default NArowtype: comparable
- suffix appender: same format, updated per the new category
- assignparam parameters accepted: comparable
- driftreport postmunge metrics: overlap_dict / mean / maximum / minimum / unique_list / maxlength
- returned datatype: comparable
- inversion available: no
Multi-tier Parsed Categoric Encodings
The following are a few variations of parsed categoric encoding aggregations. We recommend the or19 variant and have written about in paper Parsed Categoric Encodings with Automunge.
- new processing root categories or11 / or12 / or13 / or14 / or15 / or16 / or17 / or18 / or19 / or20
- or11 / or13 intended for categorical sets that may include multiple tiers of overlaps and include base binary encoding via 1010 supplemented by tiers of string parsing for overlaps using spl2 and spl5, or11 has two tiers of overlap string parsing, or13 has three, each parsing returned with an ordinal encoding sorted by frequency (ord3)
- or12 / or14 are comparable to or11 / or13 but include an additional supplemental transform of string parsing for numerical entries with nmrc followed by a z-score normalization of returned numbers via nmbr
- or15 / or16 / or17 / or18 comparable to or11 / or12 / or13 / or14 but incorporate an UPCS transform upstream and make use of spl9/sp10 instead of spl2/spl5 for assumption that set of unique values in test set is same or subset of train set for more efficient postmunge
- or19 / or20 comparable to or16 / or18 but replace the 'nmrc' string parsing for numeric entries with nmc8 which allows comma characters in numbers and makes use of consistent assumption to spl9/sp10 that set of unique values in test set is same or subset of train for efficient postmunge
- or21 / or22 comparable to or19 / or20 but use spl2/spl5 instead of spl9/sp10, which allows string parsing to handle test set entries not found in the train set
- or23 similar to or19 but instead of spl2/spl5 chain applies a sp19 for binary encoded string parsing with concurrent activations
- assignparam parameters accepted: 'minsplit': indicating lowest character length for recognized overlaps (note that parameter has to be assigned to specific categories such as spl2/spl5 etc), also other parameters associated with constituent functions
- driftreport postmunge metrics: comparable to constituent functions
- inversion available: yes with full recovery
List of Root Categories
Here are those root categories presented again in a concise sorted list, intended as reference so user can avoid unintentional duplication.
- '1010',
- '101d',
- '10mz',
- 'DB10',
- 'DB1s',
- 'DBb2',
- 'DBbn',
- 'DBbx',
- 'DBh1',
- 'DBh2',
- 'DBhs',
- 'DBm2',
- 'DBmc',
- 'DBmm',
- 'DBmp',
- 'DBn2',
- 'DBn3',
- 'DBn4',
- 'DBnb',
- 'DBne',
- 'DBnm',
- 'DBns',
- 'DBo4',
- 'DBo5',
- 'DBo6',
- 'DBo7',
- 'DBo8',
- 'DBod',
- 'DBoh',
- 'DBqt',
- 'DBrt',
- 'DBse',
- 'DBsk',
- 'DLmm',
- 'DLnb',
- 'DLrt',
- 'DP10',
- 'DP1s',
- 'DPb2',
- 'DPbn',
- 'DPbx',
- 'DPh1',
- 'DPh2',
- 'DPhs',
- 'DPm2',
- 'DPmc',
- 'DPmm',
- 'DPmp',
- 'DPn2',
- 'DPn3',
- 'DPn4',
- 'DPnb',
- 'DPne',
- 'DPnm',
- 'DPns',
- 'DPo4',
- 'DPo5',
- 'DPo6',
- 'DPo7',
- 'DPo8',
- 'DPod',
- 'DPoh',
- 'DPpc',
- 'DPqt',
- 'DPrt',
- 'DPse',
- 'DPsk',
- 'DT10',
- 'DT1s',
- 'DTb2',
- 'DTbn',
- 'DTbx',
- 'DTh1',
- 'DTh2',
- 'DThs',
- 'DTm2',
- 'DTmc',
- 'DTmm',
- 'DTmp',
- 'DTn2',
- 'DTn3',
- 'DTn4',
- 'DTnb',
- 'DTne',
- 'DTnm',
- 'DTns',
- 'DTo4',
- 'DTo5',
- 'DTo6',
- 'DTo7',
- 'DTo8',
- 'DTod',
- 'DToh',
- 'DTqt',
- 'DTrt',
- 'DTse',
- 'DTsk',
- 'GPS1',
- 'GPS2',
- 'GPS3',
- 'GPS4',
- 'GPS5',
- 'GPS6',
- 'MAD2',
- 'MAD3',
- 'MADn',
- 'NAr2',
- 'NAr3',
- 'NAr4',
- 'NAr5',
- 'NArw',
- 'U101',
- 'Ucct',
- 'Uh10',
- 'Uhs2',
- 'Uhsh',
- 'UPCS',
- 'Unht',
- 'Uor2',
- 'Uor3',
- 'Uor6',
- 'Uord',
- 'Utx2',
- 'Utx3',
- 'Utxt',
- 'absl',
- 'addd',
- 'aggt',
- 'arcs',
- 'arsn',
- 'artn',
- 'bins',
- 'bkb3',
- 'bkb4',
- 'bkt1',
- 'bkt2',
- 'bkt3',
- 'bkt4',
- 'bn7b',
- 'bn7o',
- 'bn9b',
- 'bn9o',
- 'bnKo',
- 'bnMo',
- 'bne7',
- 'bne9',
- 'bneb',
- 'bneo',
- 'bnep',
- 'bnKb',
- 'bnMb',
- 'bnr2',
- 'bnrd',
- 'bnry',
- 'bnso',
- 'bnst',
- 'bnwb',
- 'bnwK',
- 'bnwM',
- 'bnwd',
- 'bnwo',
- 'bsbn',
- 'bshr',
- 'bsor',
- 'bxc2',
- 'bxc3',
- 'bxc4',
- 'bxc5',
- 'bxc6',
- 'bxc7',
- 'bxcx',
- 'cnsl',
- 'cns2',
- 'cns3',
- 'copy',
- 'cost',
- 'd2d2',
- 'd2dt',
- 'd3d2',
- 'd3dt',
- 'd4d2',
- 'd4dt',
- 'd5d2',
- 'd5dt',
- 'd6d2',
- 'd6dt',
- 'dat2',
- 'dat3',
- 'dat4',
- 'dat5',
- 'dat6',
- 'datd',
- 'date',
- 'day2',
- 'day3',
- 'day4',
- 'day5',
- 'days',
- 'ddd2',
- 'ddd3',
- 'ddd4',
- 'ddd5',
- 'ddd6',
- 'dddt',
- 'ded2',
- 'ded3',
- 'ded4',
- 'ded5',
- 'ded6',
- 'dedt',
- 'dhmc',
- 'dhms',
- 'divd',
- 'dxd2',
- 'dxdt',
- 'dycs',
- 'dysn',
- 'exc2',
- 'exc3',
- 'exc4',
- 'exc5',
- 'exc6',
- 'exc7',
- 'exc8',
- 'exc9',
- 'excl',
- 'fsmh',
- 'hash',
- 'hldy',
- 'hmsc',
- 'hmss',
- 'hour',
- 'hrcs',
- 'hrs2',
- 'hrs3',
- 'hrs4',
- 'hrsn',
- 'hs10',
- 'hsh2',
- 'lb10',
- 'lbbn',
- 'lbda',
- 'lbfs',
- 'lbnm',
- 'lbo5',
- 'lbor',
- 'lbos',
- 'lbsm',
- 'lbte',
- 'lgn2',
- 'lgnm',
- 'lgnr',
- 'lngt',
- 'lngm',
- 'lnlg',
- 'log0',
- 'log1',
- 'logn',
- 'ma10',
- 'matx',
- 'maxb',
- 'mdcs',
- 'mdsn',
- 'mea2',
- 'mea3',
- 'mean',
- 'mics',
- 'min2',
- 'min3',
- 'min4',
- 'mint',
- 'misn',
- 'mlhs',
- 'mltG',
- 'mlti',
- 'mlto',
- 'mltp',
- 'mmd2',
- 'mmd3',
- 'mmd4',
- 'mmd5',
- 'mmd6',
- 'mmdx',
- 'mmor',
- 'mmq2',
- 'mmqb',
- 'mncs',
- 'mnm2',
- 'mnm3',
- 'mnm4',
- 'mnm5',
- 'mnm6',
- 'mnm7',
- 'mnmx',
- 'mnsn',
- 'mnt2',
- 'mnt3',
- 'mnt4',
- 'mnt5',
- 'mnt6',
- 'mnth',
- 'mnto',
- 'mnts',
- 'mscs',
- 'mssn',
- 'mxab',
- 'nbr2',
- 'nbr3',
- 'nbr4',
- 'nmbd',
- 'nmbr',
- 'nmc2',
- 'nmc3',
- 'nmc4',
- 'nmc5',
- 'nmc6',
- 'nmc7',
- 'nmc8',
- 'nmc9',
- 'nmcm',
- 'nmd2',
- 'nmd3',
- 'nmd4',
- 'nmd5',
- 'nmd6',
- 'nmdx',
- 'nmE2',
- 'nmE3',
- 'nmE4',
- 'nmE5',
- 'nmE6',
- 'nmE7',
- 'nmE8',
- 'nmE9',
- 'nmEU',
- 'nmq2',
- 'nmqb',
- 'nmr2',
- 'nmr3',
- 'nmr4',
- 'nmr5',
- 'nmr6',
- 'nmr7',
- 'nmr8',
- 'nmr9',
- 'nmrc',
- 'ntg2',
- 'ntg3',
- 'ntgr',
- 'nuld',
- 'null',
- 'om10',
- 'onht',
- 'or10',
- 'or11',
- 'or12',
- 'or13',
- 'or14',
- 'or15',
- 'or16',
- 'or17',
- 'or18',
- 'or19',
- 'or20',
- 'or21',
- 'or22',
- 'or23',
- 'or3b',
- 'or3c',
- 'or3d',
- 'ord2',
- 'ord3',
- 'ord4',
- 'ord5',
- 'ordd',
- 'ordl',
- 'ors2',
- 'ors5',
- 'ors6',
- 'ors7',
- 'por2',
- 'por3',
- 'pwbn',
- 'pwor',
- 'pwr2',
- 'pwrs',
- 'qbt1',
- 'qbt2',
- 'qbt3',
- 'qbt4',
- 'qbt5',
- 'qtt1',
- 'qttf',
- 'qtt2',
- 'rais',
- 'retn',
- 'rtb2',
- 'rtbn',
- 'sbs2',
- 'sbs3',
- 'sbs4',
- 'sbst',
- 'sbtr',
- 'sccs',
- 'scn2',
- 'scnd',
- 'scsn',
- 'sgn1',
- 'sgn2',
- 'sgn3',
- 'sgn4',
- 'shf2',
- 'shf3',
- 'shf4',
- 'shf5',
- 'shf6',
- 'shf7',
- 'shf8',
- 'shfl',
- 'shft',
- 'sint',
- 'smth',
- 'sp10',
- 'sp11',
- 'sp12',
- 'sp13',
- 'sp14',
- 'sp15',
- 'sp16',
- 'sp17',
- 'sp18',
- 'sp19',
- 'sp20',
- 'spl2',
- 'spl5',
- 'spl6',
- 'spl7',
- 'spl8',
- 'spl9',
- 'splt',
- 'sqrt',
- 'src2',
- 'src3',
- 'src4',
- 'srch',
- 'strn',
- 'strg',
- 'tant',
- 'texd',
- 'text',
- 'tlbn',
- 'tmzn',
- 'txt2',
- 'txt3',
- 'ucct',
- 'wkdo',
- 'wkds',
- 'wkdy',
- 'yea2',
- 'year'
List of Suffix Appenders
The convention is that each transform returns a derived column or set of columns which are distinguished from the source column by suffix appenders to the header strings. Note that in cases of root categories whose family trees include multiple generations, there may be multiple inclusions of different suffix appenders in a single returned column. A list of included suffix appenders would be too long to include here since every transformation category serves as a distinct suffix appender. Note that the transformation functions test for suffix overlap error from creating new column with headers already present in dataframe and return results in final printouts and postprocess_dict['miscparameters_results']['suffixoverlap_results']. (Or for comparable validation results for PCA, Binary, and excl transforms see 'PCA_suffixoverlap_results', 'Binary_suffixoverlap_results', 'excl_suffixoverlap_results'.)
Other Reserved Strings
Note that as Automunge applies transformations, new column headers are derived with addition of suffix appenders with leading underscore. There is an edge case where a new column header may be derived matching one already found in the set, which would be a channel for error. All new header configurations are validated for this overlap channel and if found, reported in final printouts and aggregated in the validation result postprocess_dict['miscparameters_results']['suffixoverlap_aggregated_result']. To eliminate risk of column header overlap edge cases, one can pass column headers in df_train that omit the underscore character '_' or otherwise inspect this validation result upon automunge(.) completion.
- 'Binary__1010_#' / 'Binary__ord3': The columns returned from Binary transform have headers per one of these conventions. Note that if this header is already present in the data, it will instead populate as 'Binary_############1010#' / 'Binary_############_ord3' which includes the 12 digit random integer associated with the application number and this adjustment will be reported with validation results.
- 'PCA__#': The columns returned from PCA dimensionality reduction have headers per this convention. Note that if this header is already present in the data, it will instead populate as 'PCA_############_#' which includes the 12 digit random integer associated with the application number and this adjustment will be reported with validation results.
- 'Automunge_index': a reserved column header for index columns returned in ID sets. When automunge(.) is run the returned ID sets are populated with an index matching order of rows from original returned set, note that if this header is already present in the ID sets it will instead populate as 'Automunge_index_' + a 12 digit random integer associated with the application number and will be reported with validation results.
Note that results of various validation checks such as for column header overlaps and other potential bugs are returned from automunge(.) in closing printouts and in the postprocess_dict as postprocess_dict['miscparameters_results'], and returned from postmunge(.) in the postreports_dict as postreports_dict['pm_miscparameters_results']. (If the function fails to compile check the printouts.) It is not a requirement, but we also recommend omitting underscore characters in strings used for transformation category identifiers for interpretation purposes.
Root Category Family Tree Definitions
The family tree definitions reference documentation are now recorded in a separate file in the github repo titled "FamilyTrees.md".
Custom Transformation Functions
Ok another item on the agenda, we're going to demonstrate methods to create custom transformation functions, such that a user may customize the feature engineering while building on all of the extremely useful built in features of automunge such as infill methods including ML infill, feature importance, dimensionality reduction, preparation for class imbalance oversampling, and perhaps most importantly the simplest possible way for consistent processing of additional data with just a single function call. The transformation functions will need to be channeled through pandas and incorporate a handful of simple data structures, which we'll demonstrate below.
To give a simple example, we'll demonstrate defining a custom transformation for z-score normalization, with an added parameter of a user configurable multiplier to demonstrate how we can access parameters passed through assignparam. We'll associate the transform with a new category we'll call 'newt' which we'll define with entries passed in the transformdict and processdict data structures.
Let's create a really simple family tree for the new root category 'newt' which simply creates a column identifying any rows subject to infill (NArw), performs the z-score normalization we'll define below, and separately aggregates a collection of standard deviation bins with the 'bins' transform.
transformdict = {'newt' : {'parents' : [],
'siblings' : [],
'auntsuncles' : ['newt', 'bins'],
'cousins' : ['NArw'],
'children' : [],
'niecesnephews' : [],
'coworkers' : [],
'friends' : []}}
Note that since this newt requires passing normalization parameters derived from the train set to process the test set, we'll need to create two separate transformation functions, the first a "custom_train" function that processes the train set and records normalization parameters, and the second a "custom_test" that only processes the test set on its own using the parameters derived during custom_train. (Note that if we don't need properties from the train set to process the test set we would only need to define a custom_train.)
So what's being demonstrated here is that we're populating a processdict entry which will pass the custom transformation functions that we'll define below to associate them with the category for use when that category is entered in one of the family tree primitives associated with a root category. Note that the entries for custom_test and custom_inversion are both optional, and info_retention is associated with the inversion.
processdict = {'newt' : {'custom_train' : custom_train_template,
'custom_test' : custom_test_template,
'custom_inversion' : custom_inversion_template,
'info_retention' : True,
'NArowtype' : 'numeric',
'MLinfilltype' : 'numeric'}}
Note that for the processdict entry key, shown here as 'newt', the convention in library is that this key serves as the default suffix appender for columns returned from the transform unless otherwise specified in assignparam.
Note that for transforms in the custom_train convention, an initial infill is automatically applied as adjacent cell infill to serve as precursor to ML infill. A user may also specify by a 'defaultinfill' processdict entry other conventions for this initial infill associated with the transformation category, as one of {'adjinfill', 'meaninfill', 'medianinfill', 'modeinfill', 'interpinfill', 'lcinfill', 'zeroinfill', 'oneinfill', 'naninfill', 'negzeroinfill'}. naninfill may be suitable when a custom infill is applied as part of the custom transform. If naninfill retention is desired for the returned data, either it may be assigned in assigninfill, or the 'NArowtype' processdict entry can be cast as 'exclude', noting that the latter may interfere with ML infill unless the feature is excluded from ML infill bases through ML_cmnd['full_exclude'].
Note that for transforms in the custom_train convention, after the transformation function is applied, a data type casting is performed based on the MLinfilltype unless deactivated with a dtype_convert processdict entry.
Now we have to define the custom processing functions which we are passing through the processdict to automunge.
Here we'll define a "custom_train" function intended to process a train set and derive any properties need to process test data, which will be returned in a dictionary we'll refer to as the normalization_dict. Note that the normalization_dict can also be used to store any drift statistics we want to collect for a postmunge driftreport. The test data can then be prepared with the custom_test we'll demonstrate next (unless custom_test is omitted in the processdict in which case test data will be prepared with the same custom_train function).
Now we'll define the function. (Note that if defining for the internal library an additional self parameter required as first argument.) Note that pandas is available as pd and numpy as np.
def custom_train_template(df, column, normalization_dict):
"""
#Template for a custom_train transformation function to be applied to a train feature set.
#Where if a custom_test entry is not defined then custom_train will be applied to any
#corresponding test feature sets as well (as may be ok when processing the feature in df_test
#doesn't require accessing any train data properties from the normalization_dict).
#Receives a df as a pandas dataframe
#Where df will generally be from df_train (or may also be from df_test when custom_test not specified)
#column is the target column of transform
#which will already have the suffix appender incorporated when this is applied
#normalization_dict is a dictionary pre-populated with any parameters passed in assignparam
#(and also parameters designated in any defaultparams for the associated processdict entry)
#returns the resulting transformed dataframe as df
#returns normalization_dict, which is a dictionary for storing properties derived from train data
#that may then be accessed to consistently transform test data
#note that any desired drift statistics can also be stored in normalization_dict
#e.g. normalization_dict.update({'property' : property})
#(automunge(.) may externally consider normalization_dict keys of 'inplace' or 'newcolumns_list')
#note that prior to this function call
#a datatype casting based on the NArowtype processdict entry may have been performed
#as well as a default infill of adjinfill
#unless infill type otherwise specified in a defaultinfill processdict entry
#note that this default infill is a precursor to ML infill
#note that if this same custom_train is to be applied to both train and test data
#(when custom_test not defined) then the quantity, headers, and order of returned columns
#will need to be consistent independent of data properties
#Note that the assumptions for data type of received data
#Should align with the NArowtype specified in processdict
#Note that the data types and quantity of returned columns
#Will need to align with the MLinfilltype specified in processdict
#note that following this function call a dtype conversion will take place based on MLinfilltype
#unless deactivated with a dtype_convert processdict entry
"""
#As an example, here is the application of z-score normalization
#derived based on the training set mean and standard deviation
#which can accept any kind of numeric data
#so corresponding NArowtype processdict entry can be 'numeric'
#and returns a single column of continuous numeric data
#so corresponding MLinfilltype processdict entry will need to be 'numeric'
#where we'll include the option for a parameter 'multiplier'
#which is an arbitrary example to demonstrate accessing parameters
#basically we check if that parameter had been passed in assignparam or defaultparams
if 'multiplier' in normalization_dict:
multiplier = normalization_dict['multiplier']
#or otherwise assign and save a default value
else:
multiplier = 1
normalization_dict.update({'multiplier' : multiplier})
#Now we measure any properties of the train data used for the transformation
mean = df[column].mean()
stdev = df[column].std()
#It's good practice to ensure numbers used in derivation haven't been derived as nan
#or would result in dividing by zero
if mean != mean:
mean = 0
if stdev != stdev or stdev == 0:
stdev = 1
#In general if that same basis will be needed to process test data we'll store in normalization_dict
normalization_dict.update({'mean' : mean,
'stdev': stdev})
#Optionally we can measure additional drift stats for a postmunge driftreport
#we will also save those in the normalization_dict
minimum = df[column].min()
maximum = df[column].max()
normalization_dict.update({'minimum' : minimum,
'maximum' : maximum})
#Now we can apply the transformation
#The generic formula for z-score normalization is (x - mean) / stdev
#here we incorporate an additional variable as the multiplier parameter (defaults to 1)
df[column] = (df[column] - mean) * multiplier / stdev
#A few clarifications on column management for reference:
#Note that it is ok to return multiple columns
#we recommend naming additional columns as a function of the received column header
#e.g. newcolumn = column + '_' + str(int)
#returned column headers should be strings
#when columns are conditionally created as a function of data properties
#will need to save headers for reference in custom_test
# e.g. normalization_dict.update('newcolumns_list' : [newcolumn]}
#Note that it is ok to delete the received column from dataframe as part of transform if desired
#If any other temporary columns were created as part of transform that aren't returned
#their column headers should be logged as a normalization_dict entry under 'tempcolumns'
# e.g. normalization_dict.update('tempcolumns' : [tempcolumn]}
#we recommend naming non-returned temporary columns with integer headers since other headers will be strings
return df, normalization_dict
And then since this is a method that passes values between the train and test sets, we'll need to define a corresponding "custom_test" function intended for use on test data.
def custom_test_template(df, column, normalization_dict):
"""
#This transform will be applied to a test data feature set
#on a basis of a corresponding custom_train entry
#Such as test data passed to either automunge(.) or postmunge(.)
#Using properties from the train set basis stored in the normalization_dict
#Note that when a custom_test entry is not defined,
#The custom_train entry will instead be applied to both train and test data
#Receives df as a pandas dataframe of test data
#and a string column header (column)
#which will correspond to the column (with suffix appender already included)
#that was passed to custom_train
#Also receives a normalization_dict dictionary
#Which will be the dictionary populated in and returned from custom_train
#note that prior to this function call
#a datatype casting based on the NArowtype processdict entry may have been performed
#as well as a default infill of adjinfill
#unless infill type otherwise specified in a defaultinfill processdict entry
#where convention is that the quantity, headers, and order of returned columns
#will need to match those returned from the corresponding custom_train
"""
#As an example, here is the corresponding z-score normalization
#derived based on the training set mean and standard deviation
#which was populated in a normalization_dict in the custom_train example given above
#Basically the workflow is we access any values needed from the normalization_dict
#apply the transform
#and return the transformed dataframe
#access the train set properties from normalization_dict
mean = normalization_dict['mean']
stdev = normalization_dict['stdev']
multiplier = normalization_dict['multiplier']
#then apply the transformation and return the dataframe
df[column] = (df[column] - mean) * multiplier / stdev
return df
And finally here is an example of the convention for inverseprocess functions, such as may be passed to a processdict entry to support an inversion operation on a custom transformation function (associated with postmunge(.) inversion parameter).
def custom_inversion_template(df, returnedcolumn_list, inputcolumn, normalization_dict):
"""
#User also has the option to define a custom inversion function
#Corresponding to custom_train and custom_test
#Where the function receives a dataframe df
#Containing a post-transform configuration of one or more columns whose headers are
#recorded in returnedcolumn_list
#And this function is for purposes of creating a new column with header inputcolumn
#Which inverts that transformation originally applied to produce those
#columns in returnedcolumn_list
#Here normalization_dict is the same as populated and returned from a corresponding custom_train
#as applied to the train set
#Returns the transformed dataframe df with the addition of a new column as df[inputcolumn]
#Note that the returned dataframe should retain the columns in returnedcolumn_list
#Whose retention will be managed elsewhere
"""
#As an example, here we'll be inverting the z-score normalization
#derived based on the training set mean and standard deviation
#which corresponds to the examples given above
#Basically the workflow is we access any values needed from the normalization_dict
#Initialize the new column inputcolumn
#And use values in the set from returnedcolumn_list to recover values for inputcolumn
#First let's access the values we'll need from the normalization_dict
mean = normalization_dict['mean']
stdev = normalization_dict['stdev']
multiplier = normalization_dict['multiplier']
#Now initialize the inputcolumn
df[inputcolumn] = 0
#So for the example of z-score normalization, we know returnedcolumn_list will only have one entry
#In some other cases transforms may have returned multiple columns
returnedcolumn = returnedcolumn_list[0]
#now we perform the inversion
df[inputcolumn] = (df[returnedcolumn] * stdev / multiplier) + mean
return df
Please note that if you included externally initialized functions in an automunge(.) call, like for custom_train transformation functions, they will need to be reinitialized by user prior to uploading an externally saved postprocess_dict with pickle in a new notebook. (This was a design decision for security considerations.) Please note that if you assign a multicolumn input feature set to a single root category with tree categories in custom_train convention by assigncat {set} bracket specification e.g. assigncat = {'newt':[{'column1', 'column2'}]} then your custom_train transform will recieve those headers as a list through normalization_dict['messy_data_headers'].
Further details on custom transformations provided in the essay Custom Transformations with Automunge.
Custom ML Infill Functions
Ok final item on the agenda, we're going to demonstrate methods to create custom ML infill functions for model training and inference, such that a user may integrate their own machine learning algorithms into the platform. We have tried to balance our options for alternate learning libraries from the default random forest, but recognize that sophisticate hyperparameter tuning is not our forte, so want to leave the option open for users to integrate their own implementations, such as may be for example built on top of XGBoost or other learning libraries.
We'll demonstrate here templates for defining training and inference functions for classification and regression. These functions can be initialized externally and applied for ML infill and feature importance. Please note that if you included externally initialized functions in an automunge(.) call, like for customML inference functions (but not customML training functions), they will need to be reinitialized by user prior to uploading an externally saved postprocess_dict with pickle in a new notebook. These demonstrations are shown with scikit Random Forest models for simplicity. Further details on Custom ML is provided in the essay Custom ML Infill with Automunge.
def customML_train_classifier(labels, features, columntype_report, commands, randomseed):
"""
#Template for integrating user defined ML classificaiton training into ML infill
#labels for classification are received as a single column pandas series with header of integer 1
#and entries of str(int) type (i.e. string representations of non-negative integers like '0', '1')
#if user prefers numeric labels, they can apply labels = labels.astype(int)
#features is received as a numerically encoded pandas dataframe
#with categoric entries as boolean integer or ordinal integer
#and may include binarized features
#headers are strings matching the returned convention with suffix appenders
#columntype_report is a dictionary reporting properties of the columns found in features
#a list of categoric features is available as columntype_report['all_categoric']
#a list of of numeric features is available as columntype_report['all_numeric']
#and columntype_report also contains more granular information such as feature set groupings and types
#consistent with the form returned in postprocess_dict['columntype_report']
#commands is received per user specification passed to automunge(.)
#in ML_cmnd['MLinfill_cmnd']['customML_Classifier']
#such as could be a dictionary populated as {'parameter' : value}
#and then could be passed to model training as **commands
#this is the same dictionary received for the corresponding predict function
#so if user intends to pass different commands to both operations they could structure as e.g.
#{'train' : {'parameter1' : value1}, 'predict' : {'parameter2' : value2}}
#and then pass to model training as **commands['train']
#randomseed is received as a randomly sampled integer
#the returned model is saved in postprocess_dict
#and accessed to impute missing data in automunge and again in postmunge
#as channeled through the corresponding customML_predict_classifier
#if model training not successful user can return model as False
#if the function returns a ValueError model will automatically populate as False
"""
model = RandomForestClassifier(**commands)
#labels are received as str(int), for this demonstration will convert to integer
labels = labels.astype(int)
model.fit(features, labels)
return model
def customML_train_regressor(labels, features, columntype_report, commands, randomseed):
"""
#Template for integrating user defined ML regression training into ML infill
#labels for regression are received as a single column pandas series with header of integer 0
#and entries of float type
#commands is received per user specification passed to automunge(.)
#in ML_cmnd['MLinfill_cmnd']['customML_Regressor']
#features, columntype_report, randomseed
#are comparable in form to those documented for the classification template
#the returned model is saved in postprocess_dict
#and accessed to impute missing data in automunge and again in postmunge
#as channeled through the corresponding customML_predict_regressor
#if model training not successful user can return model as False
#Note that if user only wishes to define a single function
#they can use the labels header convention (0/1) to distinguish between
#whether data is served for classification or regression
"""
model = RandomForestRegressor(**commands)
model.fit(features, labels)
return model
def customML_predict_classifier(features, model, commands):
"""
#Template for integrating user defined ML classification inference into ML infill
#features is comparable in form to those features received in the corresponding training operation
#model is the model returned from the corresponding training operation
#commands is the same as received in the corresponding training operation
#infill should be returned as single column numpy array, pandas dataframe, or series (column header is ignored)
#returned infill entry types should either be str(int) or int
"""
infill = model.predict(features)
return infill
def customML_predict_regressor(features, model, commands):
"""
#Template for integrating user defined ML regression inference into ML infill
#features is comparable in form to those features received in the corresponding training operation
#model is the model returned from the corresponding training operation
#commands is the same as received in the corresponding training operation
#infill should be returned as single column numpy array, pandas dataframe, or series (column header is ignored)
#returned infill entry types should be floats or integers
"""
infill = model.predict(features)
return infill
Having defined our custom functions, we can then pass them to an automunge(.) call through the ML_cmnd parameter. We can activate their use by setting ML_cmnd['autoML_type'] = 'customML'. We can pass parameters to our functions through ML_cmnd['autoML_type']['MLinfill_cmnd']. And we can pass our defined functions through ML_cmnd['autoML_type']['customML'].
ML_cmnd = {'autoML_type' : 'customML',
'MLinfill_cmnd' : {'customML_Classifier':{'parameter1' : value1},
'customML_Regressor' :{'parameter2' : value2}},
'customML' : {'customML_Classifier_train' : customML_train_classifier,
'customML_Classifier_predict': customML_predict_classifier,
'customML_Regressor_train' : customML_train_regressor,
'customML_Regressor_predict' : customML_predict_regressor}}
Please note that for customML autoML_type, feature importance in postmunge is performed with the default random forest. (This was a design decision that benefits privacy of custom model training when sharing postprocess_dict with third party, this way only customML inference needs to be re-initialized when uploading postprocess_dict in a separate notebook.)
Note that the library has an internal suite of inference functions for different ML libraries that can optionally be used in place of a user defined customML inference function. These can be activated by passing a string to entries for 'customML_Classifier_predict' or 'customML_Regressor_predict' as one of {'tensorflow', 'xgboost', 'catboost', 'flaml', 'randomforest'}. Use of the internally defined inference functions allows a user to upload a postprocess_dict in a separate notebook without needing to first reinitialize the customML inference functions. For example, to apply a default inference function for the XGBoost library could apply:
ML_cmnd = {'autoML_type' : 'customML',
'MLinfill_cmnd' : {'customML_Classifier':{'parameter1' : value1},
'customML_Regressor' :{'parameter2' : value2}},
'customML' : {'customML_Classifier_train' : customML_train_classifier,
'customML_Classifier_predict': 'xgboost',
'customML_Regressor_train' : customML_train_regressor,
'customML_Regressor_predict' : 'xgboost'}}
And thus ML infill can run with any tabular learning library or algorithm. BYOML.
Final Model Training
- Please note that Automunge with 8.13 introduced what is currently an experimental implementation for final model training and inference. For example, they are well suited for training a final model in conjunction with our optuna_XG1 hyperparameter tuner using the same ML_cmnd API to select tuning options. Note that this option can apply a different model architecture or tuning options than those used for ML infill.
- automodel(.) accepts a training set and postprocess_dict as returned from automunge(.) to automatically train a model which is saved in the postprocess_dict
- autoinference(.) accepts a test set prepared in automunge(.) or postmunge(.) and a postprocess_dict which has been populated by automodel and returns the results of inference.
- Note that when a model from automodel(.) is populated in a postprocess_dict, then when additional test data is prepared with that postprocess_dict in postmunge(.), if the test set does not include label features, then autoinference will automatically be called within postmunge(.) with the results of inference returned in the returned labels set we call test_labels.
Here is an example of an automodel pipeline using gradient boosting with optuna tuning to train the final model and then running inference in postmunge:
#prepare data for ML
train, train_ID, labels, \
val, val_ID, val_labels, \
test, test_ID, test_labels, \
postprocess_dict = \
am.automunge(df_train,
labels_column = labels_column)
#Set final model XGBoost tuning parameters for Optuna Bayesian tuning
ML_cmnd = {'autoML_type' : 'xgboost',
# 'xgboost_gpu_id' : 0,
'hyperparam_tuner' : 'optuna_XG1',
'optuna_n_iter' : 1000,
'optuna_timeout' : 3600,
'optuna_kfolds' : 5,
'optuna_fasttune' : True,
'optuna_early_stop': 150,
'optuna_max_depth_tuning_stepsize' : 1,
}
#train final model with automodel which will be saved in postprocess_dict
postprocess_dict = \
am.automodel(train, labels, postprocess_dict,
ML_cmnd = ML_cmnd, encrypt_key = False,
printstatus = True, randomseed = False)
#optional: download postprocess_dict with pickle
#can either run inference to raw data in postmunge
#or directly to encoded data with autoinference
#here we demonstrate running inference on validation data with autoinference
#followed by running inference on raw test data with postmunge
#run inference on encoded data with autoinference, here shown on validation data
val_predictions = \
am.autoinference(val, postprocess_dict, encrypt_key = False,
printstatus = True, randomseed = False)
#run inference on raw test data with postmunge
#note predictions will be returned as test_labels
test, test_ID, test_labels, \
postreports_dict = \
am.postmunge(postprocess_dict, df_test)
#optionally can invert the encoded predictions back to original form of labels
df_invert, recovered_list, inversion_info_dict = \
am.postmunge(postprocess_dict, test_labels, inversion='labels')
We consider the final model functions automodel(.) and autoinference(.) in Beta.
Conclusion
And there you have it; you now have all you need to prepare data for machine learning with the Automunge platform. Feedback is welcome.
...
As a citation, please note that the Automunge package makes use of the Pandas, Scikit-learn, SciPy stats, and NumPy libraries. In addition to the default of Scikit-learn's Random Forest predictive models, Automunge also has options for ML infill using the CatBoost, FLAML, or XGboost libraries, and includes a hyperparameter tuning option by the Optuna library.
Wes McKinney. Data Structures for Statistical Computing in Python, Proceedings of the 9th Python in Science Conference, 51-56 (2010) publisher link
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, Édouard Duchesnay. Scikit-learn: Machine Learning in Python, Journal of Machine Learning Research, 12, 2825-2830 (2011) publisher link
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, St ́efan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, CJ Carey, Ilhan Polat, Yu Feng, Eric W. Moore, Jake Vand erPlas, Denis Laxalde, Josef Perktold, Robert Cim- rman, Ian Henriksen, E. A. Quintero, Charles R Harris, Anne M. Archibald, Antˆonio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1. 0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261– 272, 2020. doi: https://doi.org/10.1038/s41592-019-0686-2.
S. van der Walt, S. Colbert, and G. Varoquaux. The numpy array: A structure for efficient numerical computation. Computing in Science & Engineering, 13:22–30, 2011.
Anna Veronika Dorogush, Vasily Ershov, Andrey Gulin. CatBoost: gradient boosting with categorical features support arXiv:1810.11363
Chi Wang, Qingyun Wu, Markus Weimer, Erkang Zhu. FLAML: A Fast and Lightweight AutoML Library arXiv:1911.04706
Tianqi Chen, Carlos Guestrin. XGBoost: A Scalable Tree Boosting System arXiv:1603.02754
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, Masanori Koyama. Optuna: A Next-generation Hyperparameter Optimization Framework. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2019). arXiv:1907.10902
...
Please note that this list of citations is not exhaustive, we have had several additional influences that are cited in the papers of the Automunge Medium Publication.
...
As a quick clarification on the various permutations of the term “Automunge” used in codebase:
Automunge - The name of the library which prepares data for machine learning. Note that Automunge Inc. is doing business as Automunge. Note that imports are conducted by “pip install Automunge”. Note that Automunge is also the name of a folder in the GitHub repository. "Automunge" is a registered trademark.
AutoMunge - name of a defined class in the Automunge library. Note that jupyter notebook initializations are recommended as
from Automunge import *
am = AutoMunge()
Note that AutoMunge is also used as the title of a GitHub repository published by the Automunge account where we have been sharing code.
Automunger - name of a file published in GitHub repository (as Automunger.py) which is saved in the folder titled Automunge
automunge(.) - name of a function defined in the AutoMunge class in the Automunge library which is the central interface for initial preparations of data.
postmunge(.) - name of a function defined in the AutoMunge class in the Automunge library which is the central interface for subsequent preparations of additional data on the same basis.
...
Please note that the pickle library has a security vulnerability when loading an object of unknown origin. We do not use pickle in our codebase but suggested use above for downloading a returned postprocess_dict because of its ability to serialize and download arbitrary python objects. If you intend to distribute a pickled postprocess_dict publicly, the python docs suggest signing the data with hmac to ensure that it has not been tampered with.
...
Please note that Automunge imports make use of the Pandas, Scikit-Learn, Numpy, and Scipy Stats libraries which are released under a 3-Clause BSD license. We include options that may import the Catboost or XGBoost libraries which are released under the Apache License 2.0, as well as options for the FLAML and Optuna libraries which are released under a MIT License.
...
Have fun munging!!
...
You can read more about the tool through the blog posts documenting the development online at the Automunge Medium Publication or for more writing there is a related collection of essays titled From the Diaries of John Henry.
The Automunge website is helpfully located at automunge.com.
If you are looking for something to cite, our paper Tabular Engineering with Automunge was accepted to the 2021 NeurIPS Data-Centric AI workshop.
...
This file is part of Automunge which is released under the BSD-3-Clause license. See file LICENSE or go to https://github.com/Automunge/AutoMunge for full license details.
contact available via automunge.com
Copyright (C) 2018, 2019, 2020, 2021, 2022, 2023 - All Rights Reserved
U.S. Patent No. 11861462
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file automunge-9.0.tar.gz.
File metadata
- Download URL: automunge-9.0.tar.gz
- Upload date:
- Size: 607.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a15bc273b502fe22fab9b9323fa257f75e07496d547ac610b83166c39566b6b2
|
|
| MD5 |
b948ae2325b256c8cba1ef93c60479d3
|
|
| BLAKE2b-256 |
d2d4db5f3e1ca262721c37706f5b291a620754429d94dc4b69f291d832769ecc
|
File details
Details for the file automunge-9.0-py3-none-any.whl.
File metadata
- Download URL: automunge-9.0-py3-none-any.whl
- Upload date:
- Size: 445.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
11ead7a3767fd1b47f524a3a64c6f7ca2dceba7ce1cc2b58350132457a808252
|
|
| MD5 |
49b370a3730425d978f62f6e52b486fe
|
|
| BLAKE2b-256 |
da412317bc533032420701c4df72a8826452c765896d717c64422cbc5eb9b7b7
|







