A tool for printing data in a columnar format.

Project description
Columnar
A library for creating columnar output strings using data as input.
Installation
pip install columnar
Examples
from columnar import columnar
from click import style
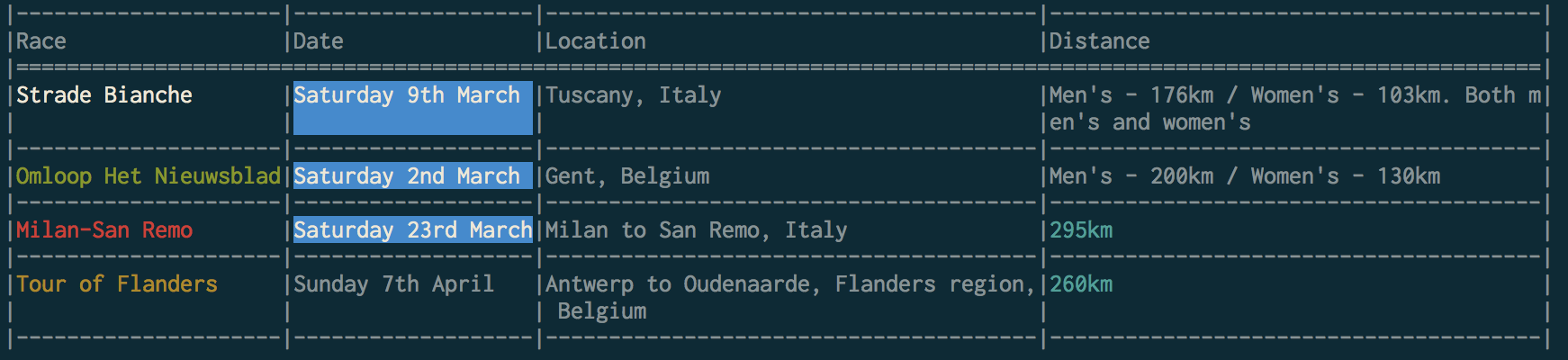
data = [
['Strade Bianche', 'Saturday 9th March', 'Tuscany, Italy', "Men's - 176km / Women's - 103km. Both men's and women's "],
['Omloop Het Nieuwsblad', 'Saturday 2nd March', 'Gent, Belgium', "Men's - 200km / Women's - 130km"],
['Milan-San Remo', 'Saturday 23rd March', 'Milan to San Remo, Italy', '295km'],
['Tour of Flanders', 'Sunday 7th April', 'Antwerp to Oudenaarde, Flanders region, Belgium', '260km']
]
patterns = [
('Saturday.+', lambda text: style(text, fg='white', bg='blue')),
('\d+km', lambda text: style(text, fg='cyan')),
('Omloop Het Nieuwsblad', lambda text: style(text, fg='green')),
('Strade Bianche', lambda text: style(text, fg='white')),
('Milan-San Remo', lambda text: style(text, fg='red')),
('Tour of Flanders', lambda text: style(text, fg='yellow')),
]
table = columnar(data, headers=['Race', 'Date', 'Location', 'Distance'], patterns=patterns)
print(table)
Or for that fresh Docker look:
from columnar import columnar
headers = ['name', 'id', 'host', 'notes']
data = [
['busybox', 'c3c37d5d-38d2-409f-8d02-600fd9d51239', 'linuxnode-1-292735', 'Test server.'],
['alpine-python', '6bb77855-0fda-45a9-b553-e19e1a795f1e', 'linuxnode-2-249253', 'The one that runs python.'],
['redis', 'afb648ba-ac97-4fb2-8953-9a5b5f39663e', 'linuxnode-3-3416918', 'For queues and stuff.'],
['app-server', 'b866cd0f-bf80-40c7-84e3-c40891ec68f9', 'linuxnode-4-295918', 'A popular destination.'],
['nginx', '76fea0f0-aa53-4911-b7e4-fae28c2e469b', 'linuxnode-5-292735', 'Traffic Cop'],
]
table = columnar(data, headers, no_borders=True)
print(table)

Note that when using the
no_bordersargument the headers will be capitalized by default. This can be disabled by passingpreformatted_headers=True.
Columnar also supports emojis and characters that take up two display columns (assuming your display knows what to do with them):
from columnar import columnar
headers = ["User", "Message", "Zip"]
data = [
['Yiying Lu', 'Fried Dumplings!!!! Yum! 😍😍😍', 47130],
['Jennifer Lee', 'Facebook banned the 🍑, can you believe it?', 97153],
['Premier12', '本日のヒーロー🦸周東選手✨ #周東佑京 #侍ジャパン #プレミア12 #AUSP12 #Premier12', 549726]
]
table = columnar(data, headers)
print(table)

Patterns
Columnar supports patterns, which are two-item tuples each containing a regular expression and a function. The regular expression is applied to each item in data using re.match() and if there is a match the corresponding function is applied to the text of that element. Only the first matching pattern is applied, meaning patterns can be prioritized by their order in the input array. This can be used to perform colorization, casing, or other custom tasks that will affect the display of the text in the table.
Color Support
As noted above, color may be applied to text by adding it to the text through a pattern. However, text may also be pre-colored by applying ANSI color codes to the text before it is passed to columnar as made easy by libraries like click and colorama. Note however, that any color that is applied will be applied to the contents of the whole cell. For example, if the text for a cell is
f"unmodified text {click.style('modified text', fg='blue')} more unmodified text"
the entire cell's text will be turned blue.
Selecting Columns
If your table has a large number of columns, or you wish to highlight a subset of the columns use the select keyword argument. It takes a list of strings which are compiled to regular expressions using re.compile(arg, re.I) and used to select columns using pattern.search(column_name). For example, given the following columns
['Name', 'BirthDate', 'Zip Code', 'City Code', 'County Code']
using select=['name', '.*code'] will select all columns except the BirthDate column.
Dropping Columns
It is often the case that one or more columns of the data will not be useful. For example, columns where all the values are "Null" or "-". To filter out these columns use the drop keyword argument. This argument takes a list of values and drops any column whose contents are a subset of those values. For example, given four columns
a NA 1 -
b NA 2 Null
- NA 3 -
d NA 4 None
using drop=['-', 'Null', 'NA', 'None'] will drop the second and fourth columns, even though the first column contains a dash also.
Column Sizing Algorithm
There are an infinite number of ways to determine column sizing and text wrapping given a dataset. This package allows the user to specify a minimum column width, a maximum column width, and a "wrap max" which partially define wrapping and column sizing. The rest of the logic that goes into determining how to fit data into a table when the data is wider than the terminal employs a pretty simple heuristic. First determine how wide each column wants to be without wrapping. If all the columns are too wide to fit on the screen, shrink as many columns as are needed in order for the table to fit, starting with the widest column and progressing through the columns from largest to smallest. If the size of the columns falls below the minimum column width then raise an exception, specifically a columnar.exceptions.TableOverflowError. This should only happen if there are so many columns that terminal_width / num_columns is less than the minimum column width.
Text Wrapping
The contents of a column are wrapped as needed to fit in the column with no effort made to split on spaces. However, new-line characters are preserved and tab characters are replaced with four spaces. The maximum number of times the contents of a column are wrapped before being truncated is given by wrap_max. Another way to think about wrap_max is that wrap_max + 1 is the maximum number of rows a single cell can occupy. Any content past the wrap_max + 1th row is truncated.
API
columnar() Arguments
data
An iterable of iterables, typically a list of lists of strings where each string will occupy its own cell in the table. However, list elements need not be strings. No matter what is passed, each element in the list is converted to a string using str().
headers=None
A list of strings, one for each column in data, which will be displayed as the table headers. If left as None this will produce a table that does not have a header row.
patterns=[]
As explained above, patterns accepts a list of two-item tuples which can be used to transform the input data in order to perform tasks like text coloring, capitalization, or other formatting.
drop=[]
As explained above, drop takes a list of strings and if any column contains only elements in that list the column and its corresponding header will be excluded from the table. Can be used to exclude columns where all the values are "Null", or "-", etc. If an empty list is passed (default) then no columns are dropped.
select=[]
Accepts a list of string that are compiled to regular expressions using the case insensitive, re.I, flag. Any column that matches any of these regular expressions is kept while all other columns are dropped. If select is specified drop is ignored, meaning that it is possible to display columns that may have been dropped by drop by specifying them in select. Passing an empty list (default) causes all columns not dropped by drop to be displayed.
no_borders=False
Accepts a boolean value that specifies whether or not to display the borders between rows and columns. Passing True will hide all the borders and convert the headers to all caps for a more minimalistic look.
head=0
Similar to the unix bash command, displays only head number of rows of data. For example
columnar(data, headers, head=4)
will display the first four rows of data. Passing 0 (default) will display all the data.
justify='l'
Specifies how each column should be justified. Justification options are either l, c, or r for left, center, and right justification respectively.
This argument accepts either a single value, or a list with len(list) == num_columns. If a single value is specified the justification for all columns will be set to that value. Otherwise, if a list is supplied, values will be applied to each column individually. For exmaple
columnar(data, headers=['one', 'two', 'three'], justify='c')
will center all three columns, while
columnar(data, headers=['one', 'two', 'three'], justify=['r', 'c', 'l'])
will right-justify column 'one', center column 'two', and left-justify column 'three'.
wrap_max=5
Sets the maximum number of times a line will wrap inside its cell. Another way to think of this is that wrap_max + 1 is the maximum number of lines that a cell can occupy. New-line characters in the input are preserved, meaning that they count against the value of wrap_max.
max_column_width=None
Sets the maximum width for a column, causing the contents to wrap if they contain more characters than max_column_width. Setting this value to None (default) will only cause text to be wrapped if the whole table is too wide to fit on the screen causing the column-sizing algorithm to kick in.
min_column_width=5
Sets the minimum width of a column, adding whitespace to either the left side, right side, or both sides depending on the value of justify. Note that if min_column_width is too high the table may not fit on the screen and a columnar.exceptions.TableOverflowError will be thrown.
row_sep='-'
Specifies the character, or string, used to draw borders between the rows.
column_sep='|'
Specifies the character, or string, used to draw borders between the columns.
terminal_width=None
Specifies the width of the output display. If left as None the width will default to shutil.get_terminal_size().columns. However, for cases where the default does not give a desirable result the display width can be specified here.
preformatted_headers=False
Controls header formatting when no_borders==True. The default, False, will cause the headers to be automatically capitalized. True will use the headers as provided without any modification.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file Columnar-1.4.1.tar.gz.
File metadata
- Download URL: Columnar-1.4.1.tar.gz
- Upload date:
- Size: 11.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.0 importlib_metadata/3.7.3 packaging/20.9 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.9.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c3cb57273333b2ff9cfaafc86f09307419330c97faa88dcfe23df05e6fbb9c72
|
|
| MD5 |
beb09f7ad2005554a6ab71b23702dbbe
|
|
| BLAKE2b-256 |
5e0da0b2fd781050d29c9df64ac6df30b5f18b775724b79779f56fc5a8298fe9
|
File details
Details for the file Columnar-1.4.1-py3-none-any.whl.
File metadata
- Download URL: Columnar-1.4.1-py3-none-any.whl
- Upload date:
- Size: 11.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.0 importlib_metadata/3.7.3 packaging/20.9 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.9.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8efb692a7e6ca07dcc8f4ea889960421331a5dffa8e5af81f0a67ad8ea1fc798
|
|
| MD5 |
65d71d7188470339c59b3234c6a05acb
|
|
| BLAKE2b-256 |
0600a17a5657bf090b9dffdb310ac273c553a38f9252f60224da9fe62d9b60e9
|







