Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models


Project description
Docs2KG
A Human-LLM Collaborative Approach to Unified Knowledge Graph Construction from Heterogeneous Documents





Installation
We have published the package to PyPi: Docs2KG,
You can install it via:
pip install Docs2KG
python -m spacy download en_core_web_sm
Setup and Tutorial
Detailed setup and tutorial can be found in the documentation.
You have two ways to run the package:
- import the package in the code, and hook it with your own code
- run the package in the command line
Command Line
# first setup the CONFIG_FILE environment variable to local one
export CONFIG_FILE=config.yml # or any other path for the configuration file
docs2kg # this command will tell you how to use the package
# we currently support the following commands
docs2kg process-document your_input_file --agent-name phi3.5 --agent-type ollama --project-id your_project_id
docs2kg batch-process your_input_dir --agent-name phi3.5 --agent-type ollama --project-id your_project_id
docs2kg list-formats # list all the supported formats
Usage: docs2kg [OPTIONS] COMMAND [ARGS]...
Docs2KG - Document to Knowledge Graph conversion tool.
Supports multiple document formats: PDF, DOCX, HTML, and EPUB.
Options:
-c, --config PATH Path to the configuration file (default: ./config.yml)
--help Show this message and exit.
Commands:
batch-process Process all supported documents in a directory.
list-formats List all supported document formats.
neo4j Load data to Neo4j database.
process-document Process a single document file.
Usage: docs2kg process-document [OPTIONS] FILE_PATH
Process a single document file.
FILE_PATH: Path to the document file (PDF, DOCX, HTML, or EPUB)
Options:
-p, --project-id TEXT Project ID for the knowledge graph construction
-n, --agent-name TEXT Name of the agent to use for NER extraction
-t, --agent-type TEXT Type of the agent to use for NER extraction
--help Show this message and exit.
Usage: docs2kg neo4j [OPTIONS] PROJECT_ID
Load data to Neo4j database.
Options:
-m, --mode [import|export|load|docker_start|docker_stop]
Mode of operation (import or export)
-u, --neo4j-uri TEXT URI for the Neo4j database
-U, --neo4j-user TEXT Username for the Neo4j database
-P, --neo4j-password TEXT Password for the Neo4j database
-r, --reset_db Reset the database before loading data
--help
Motivation
To digest diverse unstructured documents into a unified knowledge graph, there are two main challenges:
- How to get the documents to be digitized?
- With the dual-path data processing
- For image based documents, like scanned PDF, images, etc., we can process them through the layout analysis and OCR, etc. Docling and MinerU are focusing on this part.
- For native digital documents, like ebook, docx, html, etc., we can process them through the programming parser
- It is promising that we will have a robust solution soon.
- With the dual-path data processing
- How to construct a high-quality unified knowledge graph with less effort?
For now, a lot of tools are focusing on the first challenge, however, overlook the second challenge.
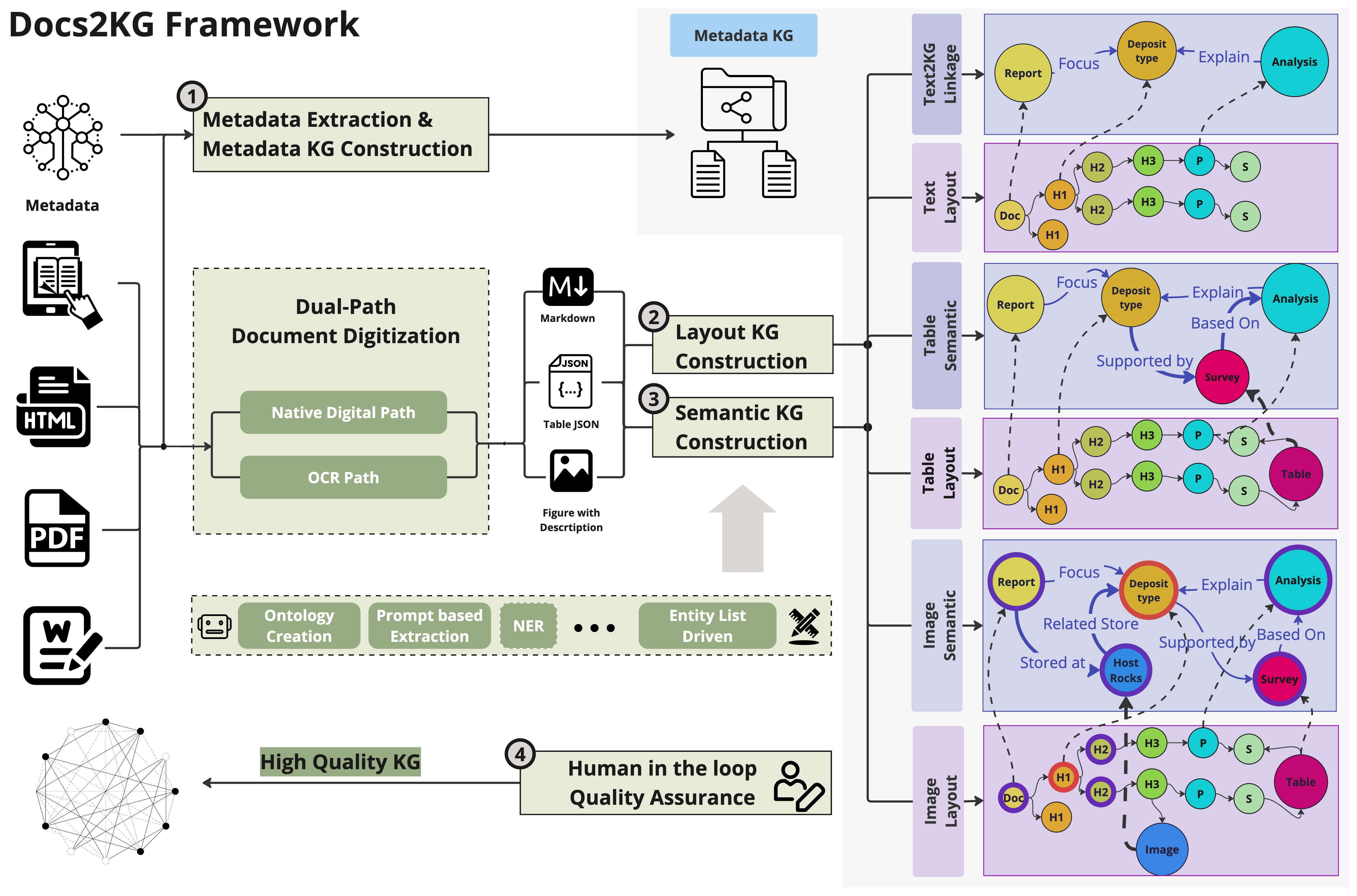
To construct a high-quality unified knowledge graph with less effort, we propose the Docs2KG.
- We adapt both bottom-up and top-down approaches to construct the unified knowledge graph and its ontology with the help of LLM.
- We organise the knowledge graph from three aspects:
- MetaKG: the knowledge about all documents, like the author, the publication date, etc.
- LayoutKG: the knowledge about the layout of the documents, like title, subtitle, section, etc.
- SemanticKG: the knowledge about the content of the documents, like entities, relations, etc.
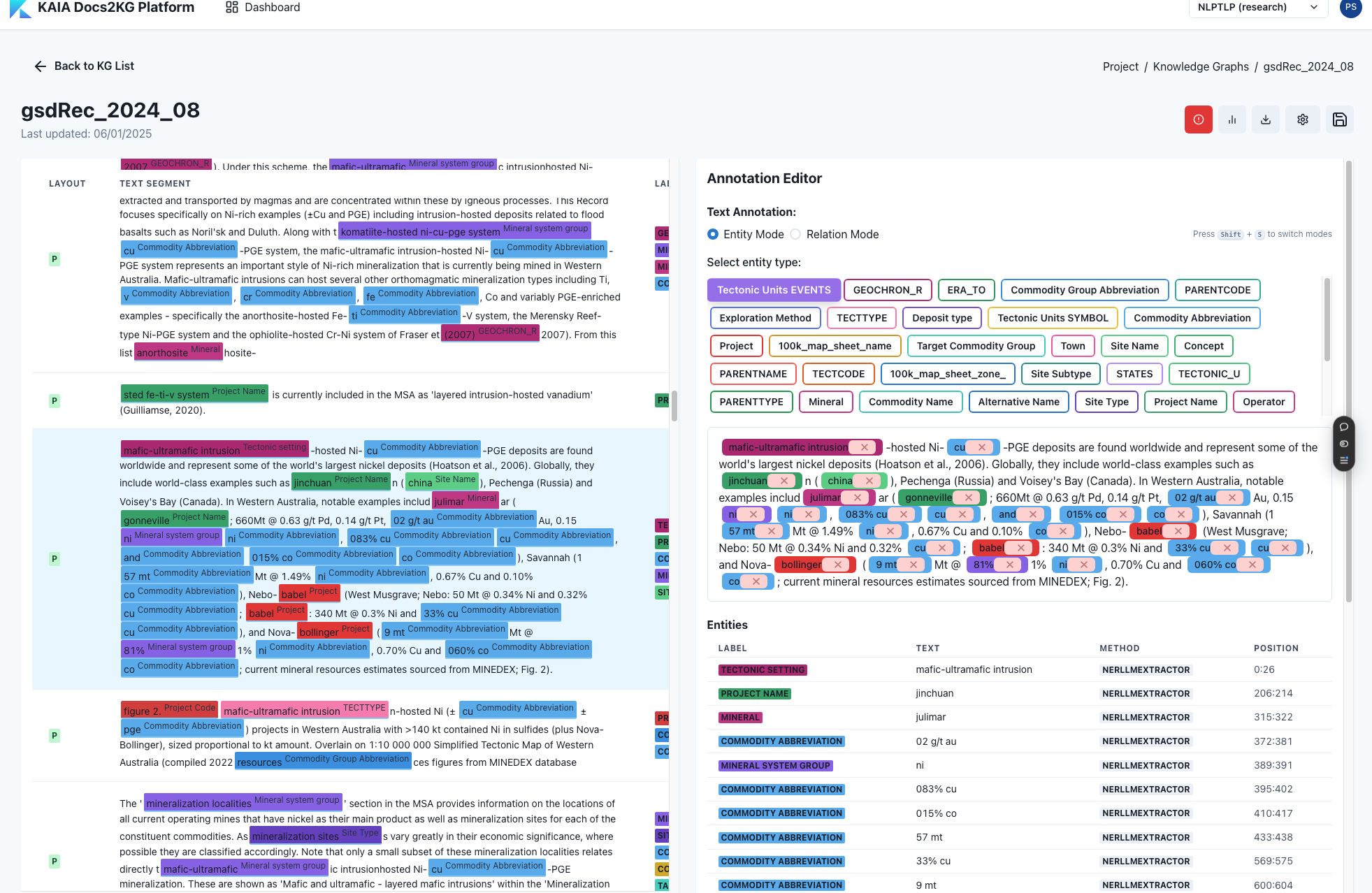
- We provide a human-LLM collaborative interface which allows human to review and enhance the generated knowledge graph.
- An updated version of ontology, entity list, relation list will in return help the KG Construction LLM agent to generate better results in the next iteration.
- The output of the knowledge graph can be used in downstream applications, like RAG, etc.
- Link for the human-LLM collaborative interface: Docs2KG
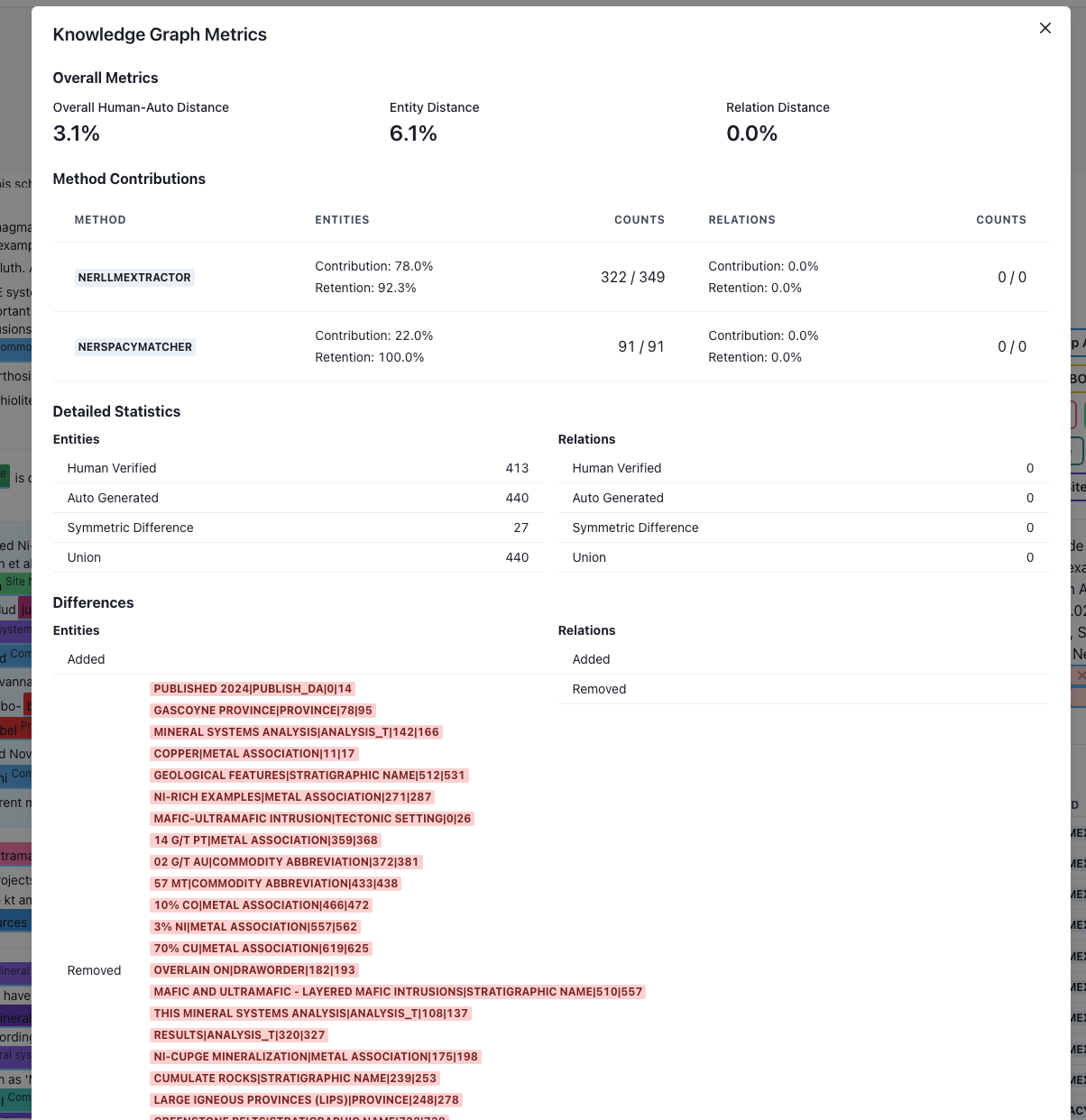
- After the annotation, metrics to evaluate the quality of automatic construction will be provided.
- How many entities are correctly extracted by each method?
- How many relations are correctly extracted by each method?
- Contribution and retention of each method in the final knowledge graph, including human annotation.
Example of the interface, you only need to register, and you can access it freely.
Development
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
pip install -r requirements.dev.txt
pip install -e .
Citation
If you find this package useful, please consider citing our work:
@misc{sun2024docs2kg,
title = {Docs2KG: Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models},
author = {Qiang Sun and Yuanyi Luo and Wenxiao Zhang and Sirui Li and Jichunyang Li and Kai Niu and Xiangrui Kong and Wei Liu},
year = {2024},
eprint = {2406.02962},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file docs2kg-0.3.5.tar.gz.
File metadata
- Download URL: docs2kg-0.3.5.tar.gz
- Upload date:
- Size: 47.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1e929aa005e76aead1f415aca4f524b3bbf5641eedee437a811958279458e296
|
|
| MD5 |
cf7a0d2cf4a01c8a0f11a5ec81d7e72e
|
|
| BLAKE2b-256 |
4483eadeb87f4685eb6960e2d7d0231f785a7ceb34fca86fe9f2399474c58f4f
|
File details
Details for the file Docs2KG-0.3.5-py3-none-any.whl.
File metadata
- Download URL: Docs2KG-0.3.5-py3-none-any.whl
- Upload date:
- Size: 58.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ced7cd89c995d89e335dbc78c9c3931ae2902f47193ace74f0ab0496bfcf6b37
|
|
| MD5 |
3c8f1155aed227ad5e0150e6ac284d7c
|
|
| BLAKE2b-256 |
b243629ae003c2d4badd559182ba21f9e25f0ede3c35c8da4739ae169b7764e3
|







