Using neural networks to extract sufficient statistics from data by maximising the Fisher information


Project description






The IMNN is a statistical method for transformation and compression of data from complex, high-dimensional distributions down to the number of physical parameters in the model which generates that data. It is asymptotically lossless in terms of information about the physical parameters. The method uses neural networks as a backbone for the transformation although any parameterised transformation with enough flexibility to map the data could be used.
Using simulations generated from the model the Fisher information (for a Gaussian distribution with parameter independent covariance) is calculated from the output of the transformation and its log determinant is maximised under the condition that the covariance of the outputted transformed simulations are approximately constant and approach the identity matrix.
Since the Fisher information only needs to be evaluated at a single fiducial parameter value it is exceptionally cheap to fit in comparison to other types of neural networks at the expense that the information is extracted from the data optimally about that fiducial parameter value and that the gradients of the simulations are needed (although this can be done numerically).
The ideal situation for performing inference is to fit an IMNN at a fiducial choice of parameters, evaluate the quasi-maximum-likelihood estimate of the parameters for the target data of choice and retrain a new IMNN at this estimate (still very cheap). This can be repeated iteratively until the IMNN is being trained at the maximum likelihood values of the parameters which will be most sensitive to the features in the data at that point and allow for the most precise constraints.
Note that the parameter estimates from the IMNN are not intended to be indicative of unbiased parameter estimates if the fiducial parameter choice is far from the maximum likelihood parameter values from some target. Instead they are meant to be used in a likelihood-free (simulation-based) inference scenario.
Using the IMNN
Implemented in JAX, the IMNN module provides a way to setup the fitting algorithm and fit an IMNN and then use it to make parameter estimates. There are several scenarios for the types of inputs that can be used.
SimulatorIMNN
Using a simulator (written in JAX or at least XLA compilable) for the generation of data provides the best results since generation of data is done on-the-fly. Since the focus of the IMNN is to maximise the information about the parameters from the data from the model, having a limited dataset means that spurious accidental correlations will almost certainly be learned about, overestimating the amount of information that can be extracted. For this reason, if using a limited sized training set like with GradientIMNN or NumericalGradientIMNN, then it is important to use a validation set and use early stopping based on the information extracted from this validation set. All these problems are side-stepped if simulations are generated on the fly since the same data is never seen multiple times. Of course, if the simulator is expensive then this may not be feasible.
The simulator needs to be of the form
def simulator(rng, parameters):
""" Simulate a realisation of the data
Parameters
----------
rng : int(2,)
A jax stateless random number generator
parameters : float(n_params,)
parameter values at which to generate the simulations at
Returns
-------
float(input_shape):
a simulation generated at parameter values `parameters`
"""
# Do stuff
return simulationGradientIMNN
If simulations are expensive but a set of simulations with their gradients can be precalculated then it is possible to use these instead to train the IMNN. In this case the simulations are passed through the network and the Jacobian of the network outputs are calculated with respect to their inputs which using the chain rule can be combined with the gradient of the simulation with respect to the model parameters to get the Jacobian of the network outputs with respect to the physical model parameters, used for calculating the Fisher information. Although possible to not use a validation set when fitting it is highly recommended to use early stopping with a validation set to avoid overestimation of the amount of information extracted.
The simulations and their gradients should be of the form
import jax
from imnn.utils import value_and_jacrev
rng = jax.random.PRNGKey(0)
fiducial_parameters = # fiducial parameter values as a float(n_params,)
n_s = # number of simulations used to estimate covariance of network outputs
rng, *keys = jax.random.split(rng, num=n_s + 1)
fiducial, derivative = jax.vmap(
lambda key: value_and_jacrev(
simulator,
argnums=1)(key, fiducial_parameters))(
np.array(keys))
fiducial.shape
>>> (n_s, input_shape)
derivative.shape
>>> (n_s, input_shape, n_params)Note that n_s derivatives are necessarily needed since only the mean of the derivatives is calculated which is more stable than the covariance. Therefore only n_d < n_s are required, although most stable optimisation is achieved using n_d = n_s.
NumericalGradientIMNN
If the gradient of the simulations with respect to the physical model parameters is not possible then numerical derivatives can be done. In this case simulations are made at the fiducial parameter value and then varied slightly with respect to each parameter independently with each of these simulations made at the same seed. Theses varied simulations are passed through the network and the outputs are used to make a numerical estimate via finite differences. There is quite a lot of fitting optimisation sensitivity to the choice of the finite difference size. Note that, again, it is VERY highly recommended to use a validation set for early stopping to prevent overestimation of the amount of information that can be extracted and the extraction of information from spurious features only existing in the limited dataset.
The simulations and their numerical derivatives should be made something like:
import jax
import jax.numpy as np
rng = jax.random.PRNGKey(0)
fiducial_parameters = # fiducial parameter values as a float(n_params,)
parameter_differences = # differences between varied parameter values for
# finite differences as a float(n_params,)
n_s = # number of simulations used to estimate covariance of network outputs
n_d = # number of simulations used to estimate the numerical derivative of
# the mean of the network outputs
rng, *keys = jax.random.split(rng, num=n_s + 1)
fiducial = jax.vmap(
lambda key: simulator(key, fiducial_parameters))(
np.array(keys))
varied_below = (fiducial_parameters - np.diag(parameter_differences) / 2)
varied_above = (fiducial_parameters + np.diag(parameter_differences) / 2)
below_fiducial = jax.vmap(
lambda key: jax.vmap(
lambda param: simulator(key, param))(varied_below))(
np.array(keys)[:n_d])
above_fiducial = jax.vmap(
lambda key: jax.vmap(
lambda param: simulator(key, param))(varied_above))(
np.array(keys)[:n_d])
derivative = np.stack([below_fiducial, above_fiducial], 1)
fiducial.shape
>>> (n_s, input_shape)
derivative.shape
>>> (n_s, 2, n_params, input_shape)Matching seeds across pairs of varied parameters is fairly important for efficient training - stateless simulating like above makes this much easier.
Aggregation
If simulations or networks are very large then it can be difficult to fit an IMNN since the Fisher information requires the covariance to be well approximated to be able to maximise it. This means that all of the simulations must be passed through the network before doing a backpropagation step. To help with this, aggregation of computation and accumulated gradients are implemented. In this framework a list of XLA devices is passed to the IMNN class and data is passed to each device (via TensorFlow dataset iteration) to calculate the network outputs (and their derivatives using any of the SimulatorIMNN, GradientIMNN or NumericalGradientIMNN). These outputs are relatively small in size and so the gradient of the loss function (covariance regularised log determinant of the Fisher information) can be calculated easily. All of the data is then passed through the network again (a small number [n_per_device] at a time) and the Jacobian of the network outputs with respect to the neural network parameters is calculated. The chain rule is then used to combine these with the gradient of the loss function with respect to the network outputs to get the gradient of the loss function with respect to the network parameters. These gradients are summed together n_per_device at a time until a single gradient pytree for each parameter in the network is obtained which is then passed to the optimiser to implement the backpropagation. This requires two passes of the data through the network per iteration which is expensive, but is currently the only way to implement this for large data inputs which do not fit into memory. If the whole computation does fit in memory then there will be orders of magnitudes speed up compared to aggregation. However, aggregation can be done over as many XLA devices are available which should help things a bit. It is recommended to process as many simulations as possible at once by setting n_per_device to as large a value as can be handled. All central operations are computed on a host device which should be easily accessible (in terms of I/O) from all the other devices.
import jax
host = jax.devices("cpu")[0]
devices = jax.devices("gpu")
n_per_device = # number as high as makes sense for the size of dataTensorFlow Datasets
If memory is really tight and data needs to be loaded from disk then it is possible to use TensorFlow Datasets to do this, but the datasets must be EXTREMELY specifically made. There are examples in the examples directly, but shortly there are two different variants, the DatasetGradientIMNN and the DatasetNumericalGradientIMNN. For the DatasetNumericalGradientIMNN the datasets must be of the form
import tensorflow as tf
fiducial = [
tf.data.TFRecordDataset(
sorted(glob.glob("fiducial_*.tfrecords")),
num_parallel_reads=1
).map(writer.parser
).skip(i * n_s // n_devices
).take(n_s // n_devices
).batch(n_per_device
).repeat(
).as_numpy_iterator()
for i in range(n_devices)]
derivative = [
tf.data.TFRecordDataset(
sorted(glob.glob("derivative_*.tfrecords")),
num_parallel_reads=1
).map(writer.parser
).skip(i * 2 * n_params * n_d // n_devices
).take(2 * n_params * n_d // n_devices
).batch(n_per_device
).repeat(
).as_numpy_iterator()
for i in range(n_devices)]Here the tfrecords contains the simulations which are parsed by the writer.parser (there is a demonstration in imnn.TFRecords). The simulations are split into n_devices different datasets each which contain n_s // n_devices simulations which are passed to the network n_per_device at a time and repeated and not shuffled. For derivative, because there are multiple simulations at each seed for the finite differences then 2 * n_params * n_d // n_devices need to be available to each device before passing n_per_device to the network on each device.
For the DatasetGradientIMNN the loops are made quicker by separating the derivative and simulation calculation from the simulation only calculations (the difference between n_s and n_d). In this case the datasets must be constructed like:
fiducial = [
tf.data.TFRecordDataset(
sorted(glob.glob("fiducial_*.tfrecords")),
num_parallel_reads=1
).map(writer.parser
).skip(i * n_s // n_devices
).take(n_s // n_devices)
for i in range(n_devices)]
main = [
tf.data.Dataset.zip((
fiducial[i],
tf.data.TFRecordDataset(
sorted(glob.glob("derivative_*.tfrecords")),
num_parallel_reads=1).map(
lambda example: writer.derivative_parser(
example, n_params=n_params)))
).take(n_d // n_devices
).batch(n_per_device
).repeat(
).as_numpy_iterator()
for i in range(n_devices)]
remaining = [
fiducial[i].skip(n_d // n_devices
).take((n_s - n_d) // n_devices
).batch(n_per_device
).repeat(
).as_numpy_iterator()
for i in range(n_devices)]Note that using datasets can be pretty tricky, aggregated versions of GradientIMNN and NumericalGradientIMNN does all the hard work as long as the data can be fit in memory.
Neural models
The IMNN is designed with stax-like models and jax optimisers which are very flexible and designed to be quickly developed. Note that these modules don’t need to be used exactly, but they should look like them. Models should contain
def initialiser(rng, input_shape):
""" Initialise the parameters of the model
Parameters
----------
rng : int(2,)
A jax stateless random number generator
input_shape : tuple
The shape of the input to the network
Returns
-------
tuple:
The shape of the output of the network
pytree (list or tuple):
The values of the initialised parameters of the network
"""
# Do stuff
return output_shape, initialised_parameters
def apply_model(parameters, inputs):
""" Passes inputs through the network
Parameters
----------
parameters : pytree (list or tuple)
The values of the parameters of the network
inputs : float(input_shape)
The data to put through the network
Returns
-------
float(output_shape):
The output of the network
"""
# Do neural networky stuff
return output
model = (initialiser, apply_model)The optimiser also doesn’t specifically need to be a jax.experimental.optimizer, but it must contain
def initialiser(initial_parameters):
""" Initialise the state of the optimiser
Parameters
----------
parameters : pytree (list or tuple)
The initial values of the parameters of the network
Returns
-------
pytree (list or tuple) or object:
The initial state of the optimiser containing everything needed to
update the state, i.e. current state, the running mean of the
weights for momentum-like optimisers, any decay rates, etc.
"""
# Do stuff
return state
def updater(it, gradient, state):
""" Updates state based on current iteration and calculated gradient
Parameters
----------
it : int
A counter for the number of iterations
gradient : pytree (list or tuple)
The gradients of the parameters to update
state : pytree (list or tuple) or object
The state of the optimiser containing everything needed to update
the state, i.e. current state, the running mean of the weights for
momentum-like optimisers, any decay rates, etc.
Returns
-------
pytree (list or tuple) or object:
The updated state of the optimiser containing everything needed to
update the state, i.e. current state, the running mean of the
weights for momentum-like optimisers, any decay rates, etc.
"""
# Do updating stuff
return updated_state
def get_parameters(state):
""" Returns the values of the parameters at the current state
Parameters
----------
state : pytree (list or tuple) or object
The current state of the optimiser containing everything needed to
update the state, i.e. current state, the running mean of the
weights for momentum-like optimisers, any decay rates, etc.
Returns
-------
pytree (list or tuple):
The current values of the parameters of the network
"""
# Get parameters
return current_parameters
optimiser = (initialiser, updater, get_parameters)IMNN
Because there are many different cases where we might want to use different types of IMNN subclasses. i.e. with a simulator, aggregated over GPUs, using numerical derivatives, etc. then there is a handy single function will try and return the intended subclass. This is
import imnn
IMNN = imnn.IMNN(
n_s, # number of simulations for covariance
n_d, # number of simulations for derivative mean
n_params, # number of parameters in physical model
n_summaries, # number of outputs from the network
input_shape, # the shape a single input simulation
θ_fid, # the fiducial parameter values for the sims
model, # the stax-like model
optimiser, # the jax optimizers-like optimiser
key_or_state, # either a random number generator or a state
simulator=None, # SimulatorIMNN simulations on-the-fly
fiducial=None, # GradientIMNN or NumericalGradientIMNN sims
derivative=None, # GradientIMNN or NumericalGradientIMNN ders
main=None, # DatasetGradientIMNN sims and derivatives
remaining=None, # DatasetGradientIMNN simulations
δθ=None, # NumericalGradientIMNN finite differences
validation_fiducial=None, # GradientIMNN or NumericalGradientIMNN sims
validation_derivative=None, # GradientIMNN or NumericalGradientIMNN ders
validation_main=None, # DatasetGradientIMNN sims and derivatives
validation_remaining=None, # DatasetGradientIMNN simulations
host=None, # Aggregated.. host computational device
devices=None, # Aggregated.. devices for running network
n_per_device=None, # Aggregated.. amount of data to pass at once
cache=None, # Aggregated.. whether to cache simulations
prefetch=None,) # Aggregated.. whether to prefetch simsSo for example to initialise an AggregatedSimulatorIMNN and train it we can do
rng, key = jax.random.split(rng)
IMNN = imnn.IMNN(n_s, n_d, n_params, n_summaries, input_shape,
fiducial_parameters, model, optimiser, key,
simulator=simulator, host=host, devices=devices,
n_per_device=n_per_device)
rng, key = jax.random.split(rng)
IMNN.fit(λ=10., ϵ=0.1, rng=key)
IMNN.plot(expected_detF=50.)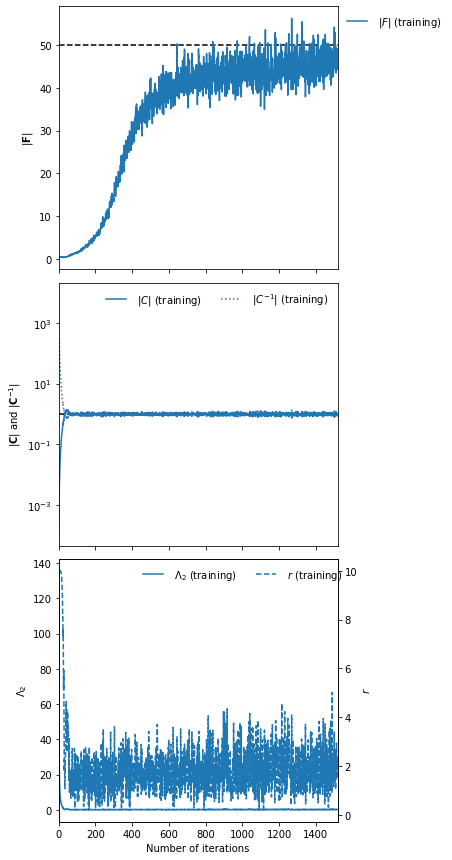
Or for a`` NumericalGradientIMNN``
rng, key = jax.random.split(rng)
IMNN = imnn.IMNN(n_s, n_d, n_params, n_summaries, input_shape,
fiducial_parameters, model, optimiser, key,
fiducial=fiducial, derivative=derivative,
δθ=parameter_differences,
validation_fiducial=validation_fiducial,
validation_derivative=validation_derivative)
IMNN.fit(λ=10., ϵ=0.1)
IMNN.plot(expected_detF=50.)λ and ϵ control the strength of regularisation and should help with speed of convergence but not really impact the final results.
Doing likelihood-free inference
With a trained IMNN it is possible to get an estimate of some data using
estimate = IMNN.get_estimate(target_data)Along with the Fisher information from the network, we can use this to make a Gaussian approximation of the posterior under the assumption that the fiducial parameter values used to calculate the Fisher information coincide with the parameter estimate. This posterior can be calculated using the imnn.lfi module. For all of the available functions in the lfi module a TensorFlow Probability-like distribution is used for the prior, e.g. for a uniform distribution for two parameters between 0 and 10 each we could write
import tensorflow_probability
tfp = tensorflow_probability.substrates.jax
prior = tfp.distributions.Blockwise(
[tfp.distributions.Uniform(low=low, high=high)
for low, high in zip([0., 0.], [10., 10.])])
prior.low = np.array([0., 0.])
prior.high = np.array([10., 10.])We set the values of prior.low and prior.high since they are used to define the plotting ranges. Note that prior.event_shape should be equal to n_params, i.e. the number of parameters in the physical model.
GaussianApproximation
The GaussianApproximation simply evaluates a multivariate Gaussian with mean at estimate and covariance given by np.linalg.inv(IMNN.F) on a grid defined by the prior ranges.
GA = imnn.lfi.GaussianApproximation(
parameter_estimates=estimate,
invF=np.linalg.inv(IMNN.F),
prior=prior,
gridsize=100)And corner plots of the Gaussian approximation can be made using
GA.marginal_plot(
ax=None, # Axes object to plot (constructs new if None)
ranges=None, # Ranges for each parameter (None=preset)
marginals=None, # Marginal distributions to plot (None=preset)
known=None, # Plots known parameter values if not None
label=None, # Adds legend element if not None
axis_labels=None, # Adds labels to the axes if not None
levels=None, # Plot specified approx significance contours
linestyle="solid", # Linestyle for the contours
colours=None, # Colour for the contours
target=None, # If multiple target data, which index to plot
format=False, # Whether to set up the plot decoration
ncol=2, # Number of columns in the legend
bbox_to_anchor=(1.0, 1.0)) # Where to place the legendNote that this approximation shouldn’t be necessarily a good estimate of the true posterior, for that actual LFI methods should be used.
ApproximateBayesianComputation
To generate simulations and accept or reject these simulations based on a distance based criterion from some target data we can use
ABC = imnn.lfi.ApproximateBayesianComputation(
target_data=target_data,
prior=prior,
simulator=simulator,
compressor=IMNN.get_estimate,
gridsize=100,
F=IMNN.F,
distance_measure=None)This takes in the target data and compresses it using the provided compressor (like IMNN.get_estimate). The Fisher information matrix can be provided to rescale the parameter directions to make meaningful distance measurements as long as summaries are parameter estimates. If a different distance measure is better for the specific problem this can be passed as a function. Note that if simulations have already been done for the ABC and only the plotting and the acceptance and rejection is needed then simulator can be set to None. The ABC can actually be run by calling the module
parameters, summaries, distances = ABC(
ϵ=None, # The size of the epsilon ball to accept summaries
rng=None, # Random number generator for params and simulation
n_samples=None, # The number of samples to run (at one time)
parameters=None, # Values of parameters with premade compressed sims
summaries=None, # Premade compressed sims to avoid running new sims
min_accepted=None, # Num of required sims in epsilon ball (iterative)
max_iterations=10, # Max num of iterations to try and get min_accepted
smoothing=None, # Amount of smoothing on the histogrammed marginals
replace=False) # Whether to remove all previous run summariesIf not run and no premade simulations have been made then n_samples and rng must be passed. Note that if ϵ is too large then the accepted samples should not be considered to be drawn from the posterior but rather some partially marginalised part of the joint distribution of summaries and parameters, and hence it can be very misleading - ϵ should be a small as possible! Like with the GaussianApproximation there is a ABC.marginal_plot(...) but the parameter samples can also be plotted as a scatter plot on the corner plot
ABC.scatter_plot(
ax=None, # Axes object to plot (constructs new if None)
ranges=None, # Ranges for each parameter (None=preset)
points=None, # Parameter values to scatter (None=preset)
label=None, # Adds legend element if not None
axis_labels=None, # Adds labels to the axes if not None
colours=None, # Colour for the scatter points (and hists)
hist=True, # Whether to plot 1D histograms of points
s=5, # Marker size for points
alpha=1., # Amount of transparency for the points
figsize=(10, 10), # Size of the figure if not premade
linestyle="solid", # Linestyle for the histograms
target=None, # If multiple target data, which index to plot
ncol=2, # Number of columns in the legend
bbox_to_anchor=(0., 1.)) # Where to place the legendAnd the summaries can also be plotted on a corner plot with exactly the same parameters as scatter_plot (apart from gridsize being added) but if points is left None then ABC.summaries.accepted is used instead and the ranges calculated from these values. If points is supplied but ranges is None then the ranges are calculated from the minimum and maximum values of the points are used as the edges.
ABC.scatter_summaries(
ax=None,
ranges=None,
points=None,
label=None,
axis_labels=None,
colours=None,
hist=True,
s=5,
alpha=1.,
figsize=(10, 10),
linestyle="solid",
gridsize=100,
target=None,
format=False,
ncol=2,
bbox_to_anchor=(0.0, 1.0))PopulationMonteCarlo
To more efficiently accept samples than using a simple ABC where samples are drawn from the prior, the PopulationMonteCarlo provides a JAX accelerated iterative acceptance and rejection scheme where each iteration the population of samples with summaries closest to the summary of the desired target defines a new proposal distribution to force a fixed population to converge towards the posterior without setting an explicit size for the epsilon ball of normal ABC. The PMC is stopped using a criterion on the number of accepted proposals compared to the number of total draws from the proposal. When this gets very small it suggests the distribution is stationary and that the proposal has been reached. It works similarly to ApproximateBayesianComputation.
PMC = imnn.lfi.PopulationMonteCarlo(
target_data=target_data,
prior=prior,
simulator=simulator,
compressor=IMNN.get_estimate,
gridsize=100,
F=IMNN.F,
distance_measure=None)And it can be run using
parameters, summaries, distances = PMC(
rng, # Random number generator for params and sims
n_points, # Number of points from the final distribution
percentile=None, # Percentage of points making the population
acceptance_ratio=0.1, # Fraction of accepted draws vs total draws
max_iteration=10, # Maximum number of iterations of the PMC
max_acceptance=1, # Maximum number of tries to get an accepted
max_samples=int(1e5), # Maximum number of attempts to get parameter
n_initial_points=None, # Number of points in the initial ABC step
n_parallel_simulations=None, # Number of simulations to do in parallel
proposed=None, # Prerun parameter values for the initial ABC
summaries=None, # Premade compressed simulations for ABC
distances=None, # Precalculated distances for the initial ABC
smoothing=None, # Amount of smoothing on histogrammed marginal
replace=False) # Whether to remove all previous run summariesThe same plotting functions as ApproximateBayesianComputation are also available in the PMC
Note
There seems to be a bug in PopulationMonteCarlo and the parallel sampler is turned off
Installation
The IMNN can be install by cloning the repository and installing via python or by pip installing, i.e.
git clone https://bitbucket.org/tomcharnock/imnn.git
cd imnn
python setup.py installor
pip install IMNNNotes on installation
The IMNN was quite an early adopter of JAX and as such it uses some experimental features. It is known to be working with jax>=0.2.10,<=0.2.12 and should be fine with newer versions for a while. One of the main limitations is with the use of TensorFlow Probability in the LFI module which also depends on JAX but is also dealing with the development nature of this language. The TensorFlow Datasets also requires TensorFlow>=2.1.0, but this requirement is not explicitly set so that python3.9 users can install a newer compatible version of TensorFlow without failing.
During the development of this code I implemented the value_and_jac* functions in JAX, which saves a huge amount of time for the IMNN, but these had not yet been pulled into the JAX api and as such there is a copy of these functions in imnn.utils.jac but they depend on jax.api and other functions which may change with jax development. If this becomes a problem then it will be necessary to install jax and jaxlib first, i.e. via
pip install jax==0.2.11 jaxlib==0.1.64or whichever CUDA enabled version suits you.
The previous version of the IMNN is still available (and works well) built on a TensorFlow backend. If you want to use keras models, etc. it will probably be easier to use that. It is not as complete as this module, but is likely to be a bit more stable due to not depending on JAXs development as heavily. This can be installed via either
git clone https://bitbucket.org/tomcharnock/imnn-tf.git
cd imnn-tf
python setup.py installor
pip install imnn-tfNote that that code isn’t as well documented, but there are plenty of examples still.
References
If you use this code please cite
@article{charnock2018,
author={Charnock, Tom and Lavaux, Guilhem and Wandelt, Benjamin D.},
title={Automatic physical inference with information maximizing neural networks},
volume={97},
ISSN={2470-0029},
url={http://dx.doi.org/10.1103/PhysRevD.97.083004},
DOI={10.1103/physrevd.97.083004},
number={8},
journal={Physical Review D},
publisher={American Physical Society (APS)},
year={2018},
month={Apr}
}and maybe also
@software{imnn2021,
author = {Tom Charnock},
title = {{IMNN}: Information maximising neural networks},
url = {http://bitbucket.org/tomcharnock/imnn},
version = {0.3.2},
year = {2021},
}Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file IMNN-0.3.2.tar.gz.
File metadata
- Download URL: IMNN-0.3.2.tar.gz
- Upload date:
- Size: 2.1 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
11d4485f6785c9c107179b4e346169d8dde4265e0fedb96ba5928fc4d6ea82f6
|
|
| MD5 |
0abf8259a86fc8d0b3d9dcfe2cc9f407
|
|
| BLAKE2b-256 |
c72fec68a74f305b700245f3c6b6fb08870937a017b778fe8fa79bf2e895596f
|
File details
Details for the file IMNN-0.3.2-py3-none-any.whl.
File metadata
- Download URL: IMNN-0.3.2-py3-none-any.whl
- Upload date:
- Size: 127.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a35865c98264b6470b33df7861d18de1a3dc2ebf1ba23e0426c8918615b518f7
|
|
| MD5 |
80c4e5a6a09e334361725cd58db22971
|
|
| BLAKE2b-256 |
f386e8c914d994aa50591281fddaab96a1d89bde0627e7c0799b371b410abeb1
|







