Towards Efficient Updating of Truncated Singular Value Decompostion

Project description
IncSVD: A python package for dynamic Truncated SVD


IncSVD is a python package capable of dynamically maintaining the incremental Truncated Singular Value Decomposition (Truncated SVD) of evolving matrices.
This is the code implementation of the paper "Fast Updating Truncated SVD for Representation Learning with Sparse Matrices" (ICLR'24).
Install and Setup.
It is recommended to use python 3.8 or higher and install IncSVD with the following command.
pip install IncSVD
User Guide
Initialize the IncSVD using an $m \times n$ matrix data_init given the rank (dimension) k for which the truncated SVD needs to be computed. Here is an example to initialize a $1000 \times 1000$ matrix with truncated dimension $k = 64$.
class EvolvingMatrix(data, k, sparse = True, method = "RPI")
- data: data matrix
Data matrix used to initialize truncated SVD.
The format of this initial matrix can be
np.ndarrayorscipy.sparse. - k: int Truncated dimension in the maintained SVD. It should be a positive integer not greater than the length of the sides of the original matrix.
- sparse: bool, default=True Set true implies the update process will employ the proposed acceleration methods [1]. Set false implies using the original methods (ZhaSimon's [2], Vecharynski's [3], Yamazaki's [4]).
- method: {'ZhaSimon', 'GKL', 'RPI'}, default='RPI'
Method for SVD update.
It can be chosen from
['ZhaSimon', 'GKL', 'RPI'].
import scipy.sparse
import IncSVD.EvolvingMatrix as EM
m, n, k = 1000, 1000, 64
# data_init = scipy.sparse.rand(m, n, density=0.005).tocsr()
M = EM.EvolvingMatrix(data_init, k, sparse=True, method="ZhaSimon")
[!TIP]
We recommend using
GKLorRPIwhen the rank of each update matrix (e.g. adding many rows at once) is large.
Row / Column Update
Expand the original matrix in row or column dimensions and update the corresponding SVD results.
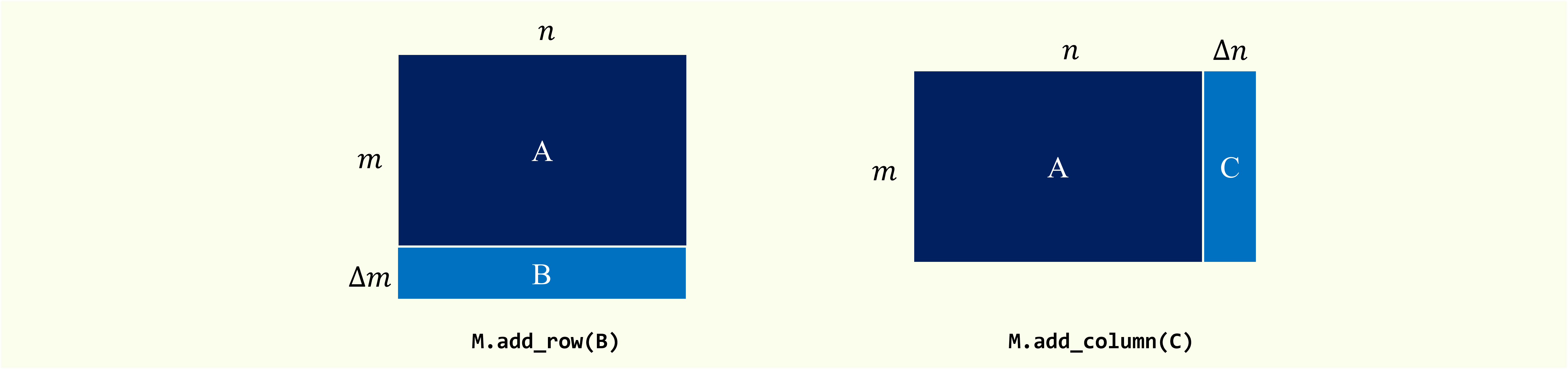
add_row(update_matrix, l=None, t=None)
- update_matrix: data matrix
Data matrix to be appended.
This matrix should have the same number of columns as the original matrix. If type
sparseis True, this matrix should be inscipy.sparse._csr.csr_matrix. - l: {int, None}
Approximate dimension for the update matrix.
When using GKL or RPI, two methods that require an approximation space, it is necessary to set
l. The update matrix of rankswill be approximated with a smaller space of ranklfor further speedup. Set toNonewhen GKL and RPI is not applied. - t: {int, None}
The number of iterations to perform in the random power iteration.
It needs to be set when using the RPI. This approximation is more accurate when
tis larger, while the computational overhead is larger. Set toNonewhen RPI is not applied.
add_column(update_matrix, l=None, t=None)
- update_matrix: data matrix
Data matrix to be appended.
This matrix should have the same number of rows as the original matrix. If type
sparseis True, this matrix should be inscipy.sparse._csc.csc_matrix. - l: {int, None}
Approximate dimension for the update matrix.
Set to
Nonewhen GKL and RPI is not applied. - t: {int, None}
The number of iterations to perform in the random power iteration.
Set to
Nonewhen RPI is not applied.
''' Add rows '''
# data_append_row = scipy.sparse.rand(m, 10, density=0.005).tocsr() * 10
M.add_row(data_append_row)
''' Add columns '''
# data_append_col = scipy.sparse.rand(n, 10, density=0.005).tocsc() * 10
M.add_column(data_append_col)
[!NOTE]
If type
sparseis True.
- [Add row] The input
data_append_rowis required to have the same number of columns as the original matrix columns and be inscipy.sparse._csr.csr_matrixtype.- [Add column] The input
data_append_colis required to have the same number of rows as the original matrix rows and be inscipy.sparse._csc.csc_matrixtype.
Low-rank Update.
Perform low-rank update $\overline{\mathbf{A}} = \mathbf{A} + \mathbf{D}_m \cdot \mathbf{E}_m^{\top}$, where $\mathbf{A}$ is the original matrix, $\mathbf{D}_m \in \mathbb{R}^{m \times s}$ and $\mathbf{E}_m \in \mathbb{R}^{n \times s}$.
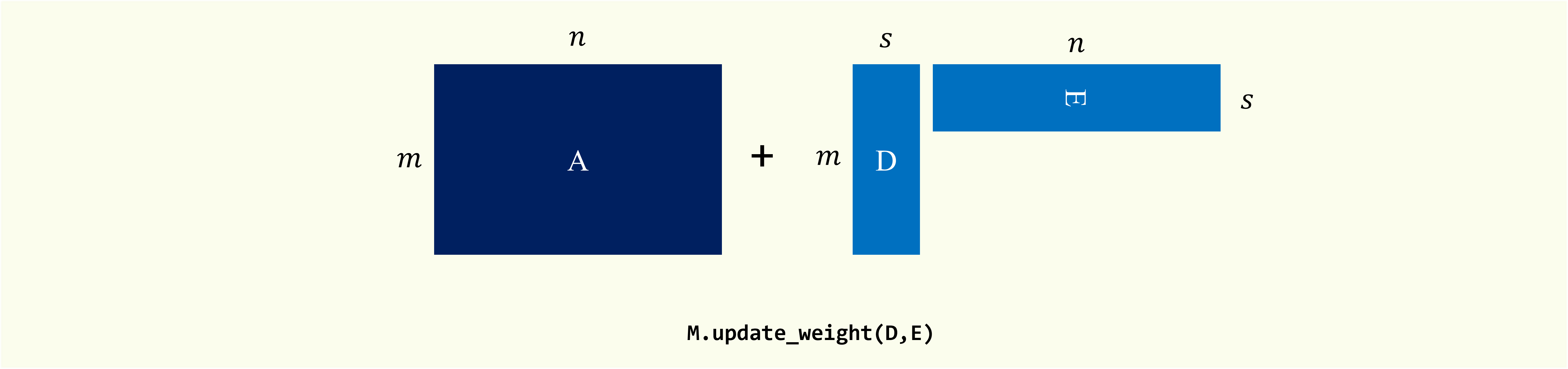
update_weight(self, update_matrix_B, update_matrix_C, l=None, t=None):
- update_matrix_B: data matrix
Data matrix to be appended.
This matrix should have the same number of columns as the original matrix. If type
sparseis True, this matrix should be inscipy.sparse._csc.csc_matrix. - update_matrix_C: data matrix
Data matrix to be appended.
This matrix should have the same number of columns as the original matrix. If type
sparseis True, this matrix should be inscipy.sparse._csc.csc_matrix. - l: {int, None}
Approximate dimension for the update matrix.
Set to
Nonewhen GKL and RPI is not applied. - t: {int, None}
The number of iterations to perform in the random power iteration.
Set to
Nonewhen RPI is not applied.
''' Low-rank update '''
# data_dm = scipy.sparse.rand(m, 10, density=0.005).tocsc() * 10
# data_em = scipy.sparse.rand(n, 10, density=0.005).tocsc() * 10
M.update_weight(data_dm, data_em)
[!NOTE]
If type
sparseis True, the inputdata_dmanddata_emis required to be inscipy.sparse._csc.csc_matrixtype.
Get the result.
Queries the current SVD result.
''' Get the result. '''
Uk, Sigmak, Vk = M.Uk, M.Sigmak, M.Vk
''' Get a row of singular vectors. '''
# i = 0
Uk0, Vk0 = M.Uki(i), M.Vki(i)
''' A low-rank approximation of data matrix can be obtained from. '''
Ak = Uk @ np.diag(Sigmak) @ Vk.T
Contact Us
If you have any questions about this code repository, feel free to raise an issue or email denghaoran@zju.edu.cn.
Citations.
If you find our work useful, please consider citing the following paper:
@inproceedings{deng2024incsvd,
title={Fast Updating Truncated {SVD} for Representation Learning with Sparse Matrices},
author={Haoran Deng and Yang Yang and Jiahe Li and Cheng Chen and Weihao Jiang and Shiliang Pu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=CX2RgsS29V}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file incsvd-0.2.7.tar.gz.
File metadata
- Download URL: incsvd-0.2.7.tar.gz
- Upload date:
- Size: 16.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a4cb01ddedee0535a944b87798e7c02989ee9fa7f95f6b539472c0f945a8b626
|
|
| MD5 |
63c86945ab1146c0f18f25b8ea7a33bf
|
|
| BLAKE2b-256 |
f23b922af636bbba4119e73eb887c4f7e4f1adcbe38bd3c4fad910f096bb4f42
|
File details
Details for the file IncSVD-0.2.7-py3-none-any.whl.
File metadata
- Download URL: IncSVD-0.2.7-py3-none-any.whl
- Upload date:
- Size: 10.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e7cc084648fec3284add4baecb149672450f315fe85507ad1b547ec795e4382c
|
|
| MD5 |
63e7fefdcbc6addf6d27a9f9131ced18
|
|
| BLAKE2b-256 |
bc5d8c39d16ebd99e7029d119fcd1980fdf642f4dd54d5a517771c982b2ee76d
|







