This high-performance package delivers blazing-fast inter-process communication through shared memory, enabling Python objects to be shared across processes with exceptional efficiency

Project description











InterProcessPyObjects package
InterProcessPyObjects is a part of the Cengal library. If you have any questions or would like to participate in discussions, feel free to join the Cengal Discord. Your support and involvement are greatly appreciated as Cengal evolves.
This high-performance package delivers blazing-fast inter-process communication through shared memory, enabling Python objects to be shared across processes with exceptional efficiency. By minimizing the need for frequent serialization-deserialization, it enhances overall speed and responsiveness. The package offers a comprehensive suite of functionalities designed to support a diverse array of Python types and facilitate asynchronous IPC, optimizing performance for demanding applications.
API State
Stable. Guaranteed to not have braking changes in the future (see bellow for details).
Any hypothetical further API-breaking changes will lead to new module creation within the package. An old version will continue its existence and continue to be importable by an explicit address (see Details bellow).
Details
The current (currently latest) version can be imported either by:
from ipc_py_objects import *
or by
from ipc_py_objects.versions.v_1 import *
If further braking changes will be made to the API - a new (v_2) version will be made. As result:
Current (v_1) version will continue to be accessible by an explicit address:
from ipc_py_objects.versions.v_1 import *
Latest (v_2) version will be accessible by either:
from ipc_py_objects import *
or by
from ipc_py_objects.versions.v_2 import *
This is a general approach across the entire Cengal library. It gives me the ability to effectively work on its huge codebase, even by myself.
By the way. I'm finishing an implementation of CengalPolyBuild - my package creation system which provides same approach to users. It is a comprehensive and hackable build system for multilingual Python packages: Cython (including automatic conversion from Python to Cython), C/C++, Objective-C, Go, and Nim, with ongoing expansions to include additional languages. Basically, it will provide easy access to all the same features I'm already using in the Cengal library package creation and management processes.
Key Features
-
Shared Memory Communication:
- Enables sharing of Python objects directly between processes using shared memory.
- Utilizes a linked list of global messages to inform connected processes about new shared objects.
-
Lock-Free Synchronization:
- Uses memory barriers for efficient communication, avoiding slow syscalls.
- Ensures each process can access and modify shared memory without contention.
-
Supported Python Types:
- Handles various Python data structures including:
- Basic types:
None,bool, 64-bitint, largeint(arbitrary precision integers),float,complex,bytes,bytearray,str. - Standard types:
Decimal,slice,datetime,timedelta,timezone,date,time - Containers:
tuple,list, classes inherited from:AbstractSet(frozenset),MutableSet(set),MappingandMutableMapping(dict). - Pickable classes instances: custom classes including
dataclass
- Basic types:
- Allows mutable containers (lists, sets, mappings) to save basic types (
None,bool, 64 bitint,float) internally, optimizing memory use and speed.
- Handles various Python data structures including:
-
NumPy and Torch Support:
- Supports numpy arrays by creating shared bytes objects coupled with independent arrays.
- Supports torch tensors by coupling them with shared numpy arrays.
-
Custom Class Support:
- Projects pickable custom classes instances (including
dataclasses) onto shared dictionaries in shared memory. - Modifies the class instance to override attribute access methods, managing data fields within the shared dictionary.
- supports classes with or without
__dict__attr - supports classes with or without
__slots__attr
- Projects pickable custom classes instances (including
-
Asyncio Compatibility:
- Provides a wrapper module for async-await functionality, integrating seamlessly with asyncio.
- Ensures asynchronous operations work smoothly with the package's lock-free approach.
Import
To use this package, simply install it via pip:
pip install InterProcessPyObjects
Then import it into your project:
from ipc_py_objects import *
Main principles
- only one process has access to the shared memory at the same time
- working cycle:
- work on your tasks
- acquire access to shared memory
- work with shared memory as fast as possible (read and/or update data structures in shared memory)
- release access to shared memory
- continue your work on other tasks
- do not forget to manually destroy your shared objects when they are not needed already
- feel free to not destroy your shared object if you need it for a whole run and/or do not care about the shared memory waste
- data will not be preserved between Creator's sessions. Shared memory will be wiped just before Creator finished its work with a shared memory instance (Consumer's session will be finished already at this point)
! Important about hashmaps
Package, currently, uses Python hash() call which is reliable across interpreter session but unreliable across different interpreter sessions because of random seeding.
In order to use same seeding across different interpreter instances (and as result, be able to use hashmaps) you can set 'PYTHONHASHSEED` env var to some fixed integer value
.bashrc
export PYTHONHASHSEED=0
Your bash script
export PYTHONHASHSEED=0
python YOURSCRIPT.py
Terminal
$ PYTHONHASHSEED=0 python YOURSCRIPT.py
An issue with the behavior of an integrated hash() call does Not affect the following data types:
None,bool,int,float,complex,str,bytes,bytearrayDecimal,slice,datetime,timedelta,timezone,date,timetuple,listsetwrapped byFastLimitedSetclass instance: for example by using.put_message(FastLimitedSet(my_set_obj))calldictwrapped byFastLimitedDictclass instance: for example by using.put_message(FastLimitedDict(my_dict_obj))call- an instances of custom classes including
dataclassby default: for example by using.put_message(my_obj)call - an instances of custom classes including
dataclasswrapped byForceStaticObjectCopyorForceStaticObjectInplaceclass instances. For example by using.put_message(ForceStaticObjectInplace(my_obj))call
It affects only the following data types:
AbstractSet(frozenset)MutableSet(set)MappingMutableMapping(dict)- an instances of custom classes including
dataclasswrapped byForceGeneralObjectCopyorForceGeneralObjectInplaceclass instances. For example by using.put_message(ForceGeneralObjectInplace(my_obj))call
Examples
- An async examples (with asyncio):
Receiver.py performance measurements
- CPU: i5-3570@3.40GHz (Ivy Bridge)
- RAM: 32 GBytes, DDR3, dual channel, 655 MHz
- OS: Ubuntu 20.04.6 LTS under WSL2. Windows 10
async with ashared_memory_context_manager.if_has_messages() as shared_memory:
# Taking a message with an object from the queue.
sso: SomeSharedObject = shared_memory.value.take_message() # 5_833 iterations/seconds
# We create local variables once in order to access them many times in the future, ensuring high performance.
# Applying a principle that is widely recommended for improving Python code.
company_metrics: List = sso.company_info.company_metrics # 12_479 iterations/seconds
some_employee: Employee = sso.company_info.some_employee # 10_568 iterations/seconds
data_dict: Dict = sso.data_dict # 16_362 iterations/seconds
numpy_ndarray: np.ndarray = data_dict['key3'] # 26_223 iterations/seconds
# Optimal work with shared data (through local variables):
async with ashared_memory_context_manager as shared_memory:
# List
k = company_metrics[CompanyMetrics.avg_salary] # 1_535_267 iterations/seconds
k = company_metrics[CompanyMetrics.employees] # 1_498_278 iterations/seconds
k = company_metrics[CompanyMetrics.in_a_good_state] # 1_154_454 iterations/seconds
k = company_metrics[CompanyMetrics.websites] # 380_258 iterations/seconds
company_metrics[CompanyMetrics.annual_income] = 2_000_000.0 # 1_380_983 iterations/seconds
company_metrics[CompanyMetrics.employees] = 20 # 1_352_799 iterations/seconds
company_metrics[CompanyMetrics.avg_salary] = 5_000.0 # 1_300_966 iterations/seconds
company_metrics[CompanyMetrics.in_a_good_state] = None # 1_224_573 iterations/seconds
company_metrics[CompanyMetrics.in_a_good_state] = False # 1_213_175 iterations/seconds
company_metrics[CompanyMetrics.avg_salary] += 1.1 # 299_415 iterations/seconds
company_metrics[CompanyMetrics.employees] += 1 # 247_476 iterations/seconds
company_metrics[CompanyMetrics.emails] = tuple() # 55_335 iterations/seconds (memory allocation performance is planned to be improved)
company_metrics[CompanyMetrics.emails] = ('sails@company.com',) # 30_314 iterations/seconds (memory allocation performance is planned to be improved)
company_metrics[CompanyMetrics.emails] = ('sails@company.com', 'support@company.com') # 20_860 iterations/seconds (memory allocation performance is planned to be improved)
company_metrics[CompanyMetrics.websites] = ['http://company.com', 'http://company.org'] # 10_465 iterations/seconds (memory allocation performance is planned to be improved)
# Method call on a shared object that changes a property through the method
some_employee.increase_years_of_employment() # 80548 iterations/seconds
# Object properties
k = sso.int_value # 850_098 iterations/seconds
k = sso.str_value # 228_966 iterations/seconds
sso.int_value = 200 # 207_480 iterations/seconds
sso.int_value += 1 # 152_263 iterations/seconds
sso.str_value = 'Hello. ' # 52_390 iterations/seconds (memory allocation performance is planned to be improved)
sso.str_value += '!' # 35_823 iterations/seconds (memory allocation performance is planned to be improved)
# Numpy.ndarray
numpy_ndarray += 10 # 403_646 iterations/seconds
numpy_ndarray -= 15 # 402_107 iterations/seconds
# Dict
k = data_dict['key1'] # 87_558 iterations/seconds
k = data_dict[('key', 2)] # 49_338 iterations/seconds
data_dict['key1'] = 200 # 86_744 iterations/seconds
data_dict['key1'] += 3 # 41_409 iterations/seconds
data_dict['key1'] *= 1 # 40_927 iterations/seconds
data_dict[('key', 2)] = 'value2' # 31_460 iterations/seconds (memory allocation performance is planned to be improved)
data_dict[('key', 2)] = data_dict[('key', 2)] + 'd' # 18_972 iterations/seconds (memory allocation performance is planned to be improved)
data_dict[('key', 2)] = 'value2' # 10_941 iterations/seconds (memory allocation performance is planned to be improved)
data_dict[('key', 2)] += 'd' # 16_568 iterations/seconds (memory allocation performance is planned to be improved)
# An example of non-optimal work with shared data (without using a local variables):
async with ashared_memory_context_manager as shared_memory:
# An example of a non-optimal method call (without using a local variable) that changes a property through the method
sso.company_info.some_employee.increase_years_of_employment() # 9_418 iterations/seconds
# An example of non-optimal work with object properties (without using local variables)
k = sso.company_info.income # 20_445 iterations/seconds
sso.company_info.income = 3_000_000.0 # 13_899 iterations/seconds
sso.company_info.income *= 1.1 # 17_272 iterations/seconds
sso.company_info.income += 500_000.0 # 18_376 iterations/seconds
# Example of non-optimal usage of numpy.ndarray without a proper local variable
data_dict['key3'] += 10 # 6_319 iterations/seconds
# Notify the sender about the completion of work on the shared object
async with ashared_memory_context_manager as shared_memory:
sso.some_processing_stage_control = True # 298_968 iterations/seconds
Reference (and explaining examples line by line)
Code for shared memory Creator side:
ashared_memory_manager: ASharedMemoryManager = ASharedMemoryManager(SharedMemory('shared_memory_identifier', create=True, size=200 * 1024**2))
# declare creation and initiation of the shared memory instance with a size of 200 MiB.
Code for shared memory Consumer side:
ashared_memory_manager: ASharedMemoryManager = ASharedMemoryManager(SharedMemory('shared_memory_identifier'))
# declares connection to shared memory instance
On shared memory Creator side:
async with ashared_memory_manager as asmm:
# creates, initiates shared memory instance and waits for the Consumer creation. Execute it once per run.
# feel free to share either `asmm` or `ashared_memory_manager` across your coroutines
On shared memory concumer side:
async with ashared_memory_manager as asmm:
# waits for the shared memory creation and initiation by the shared memory Creator. Execute it once per run.
# feel free to share either `asmm` or `ashared_memory_manager` across your coroutines
ashared_memory_context_manager: ASharedMemoryContextManager = asmm()
# creates shared memory access context manager. Create it once per coroutine. Use in the same coroutine as much as you need it.
async with ashared_memory_context_manager as shared_memory:
# acquire access to shared memory as soon as possible
async with ashared_memory_context_manager.if_has_messages() as shared_memory:
# acquire access to shared memory if message queue is not empty
shared_memory # is an instance of ValueHolder class from the Cengal library
shared_memory.value # is an instance of `SharedMemory` instance
shared_memory.existence # bool. Will be set to True at the beginning of an each context (`with`) block. Set it to `False`
# if you want to release CPU for a small time portion before shared memory will be acquired next time.
# if at least one coroutine will not set it to `False` - next acquire attempt will be made immediately which will
# lower latency and increase performance but at the same time will consume more CPU time.
# Default behavior (`True`) is better for CPU intensive algorithms,
# while `False` on all process coroutines (which have their own memory access context managers) will be better
# for example for desktop or mobile applications
SharedMemory fields and methods you might frequently use in an async approach (in coroutines)
SharedMemory.size # an actual size of the shared memory
SharedMemory.name # an identifier of the shared memory
SharedMemory.create # `True` on Creator side. `False` on Consumer side
obj_mapped = shared_memory.value.put_message(obj)
# Puts object to the shared memory and create an appropriate message
# Returns mapped version of the object if applicable (returns the same object otherwise).
# Next types will return same object: None, bool, int, float, str, bytes, bytearray, tuple.
obj_mapped, shared_obj_offset = shared_memory.value.put_message_2(obj)
# Puts object to the shared memory and create an appropriate message
# Returns:
# * Mapped version of the object if applicable (returns the same object otherwise).
# Next types will return same object: None, bool, int, float, str, bytes, bytearray, tuple.
# * An offset to the shared object data structure which holds an appropriate shared object content
has_messages: bool = shared_memory.value.has_messages()
# main way for checking an internal message queue for an emptiness
obj_mapped = shared_memory.value.take_message()
# Takes (and removes) the latest message from an internal message queue.
# Creates and returns mapped object from an appropriate shared object data structure.
# Does not deletes an appropriate shared object data structure.
# Returns mapped version of the object if applicable (returns new copy of an object otherwise).
# Next types will return new copy of an object: None, bool, int, float, str, bytes, bytearray, tuple.
# Will raise NoMessagesInQueueError exception if an internal message queue is empty
obj_mapped, shared_obj_offset = shared_memory.value.take_message_2()
# Takes (and removes) the latest message from an internal message queue.
# Creates and returns mapped object from an appropriate shared object data structure.
# Does not deletes an appropriate shared object data structure.
# Returns:
# * Mapped version of the object if applicable (returns new copy of an object otherwise).
# Next types will return new copy of an object: None, bool, int, float, str, bytes, bytearray, tuple.
# * An offset to the shared object data structure which holds an appropriate shared object content
# Will raise NoMessagesInQueueError exception if an internal message queue is empty
shared_memory.value.destroy_obj(shared_obj_offset)
# Destroys the shared object data structure which holds an appropriate shared object content.
# Use it in order to free memory used by your shared object.
shared_memory.value.destroy_object(shared_obj_offset)
# An alias to the `shared_memory.value.destroy_obj()` call
shared_obj_buffer: memoryview = shared_memory.value.get_obj_buffer(shared_obj_offset)
# returns `memoryview` to the data section of your shared object.
# Feel free to use this memory for your own needs while an appropriate shared object is still not destroyed.
# Next types provides buffer to their shared data: bytes, bytearray, str, numpy.ndarray (buffer of an appropriate shared bytes object mapped by this ndarray), torch.Tensor (buffer of an appropriate shared bytes object mapped by this Tensor)
Useful exceptions
class SharedMemoryError:
# Base exception all other exceptions are inherited from it
class FreeMemoryChunkNotFoundError(SharedMemoryError):
"""Indicates that an unpartitioned chunk of free memory of requested size not being found.
Regarding this error, it’s important to adjust the size parameter in the SharedMemory configuration. Trying to estimate memory consumption down to the byte is not practical because it fails to account for the memory overhead required by each entity stored (such as entity type metadata, pointers to child entities, etc.).
When setting the size parameter for SharedMemory, consider using broader units like tens (for embedded systems), hundreds, or thousands of megabytes, rather than precise byte counts. This approach is similar to how you would not precisely calculate the amount of memory needed for a web server hosted externally; you make an educated guess, like assuming that 256 MB might be insufficient but 768 MB could be adequate, and then adjust based on practical testing.
Also, be aware of memory fragmentation, which affects all memory allocation systems, including the OS itself. For example, if you have a SharedMemory pool sized to store exactly ten 64-bit integers, accounting for additional bytes for system information, your total might be around 200 bytes. Initially, after storing the integers, your memory might appear as ["int", "int", ..., "int"]. If you delete every second integer, the largest contiguous free memory chunk could be just 10 bytes, despite having 50 bytes free in total. This fragmentation means you cannot store a larger data structure like a 20-byte string which needs contiguous space.
To resolve this, simply increase the size parameter value of SharedMemory. This is akin to how you would manage memory allocation for server hosting or thread stack sizes in software development.
"""
NoMessagesInQueueError
# Next calls can raise it if an internal message queue is empty: take_message(), take_message_2(), read_message(), read_message_2()
Performance tips
Data structures
Data structures
It is recommended to use IntEnum+list based data structures instead of dictionaries or even instead custom class instancess (including dataclass) if you want best performance.
For example instead operating with dict:
Example
Message sender
company_metrics: Dict[str, Any] = {
'websites': ['http://company.com', 'http://company.org'],
'avg_salary': 3_000.0,
'employees': 10,
'in_a_good_state': True,
}
company_metrics_mapped: List = shared_memory.value.put_message(company_metrics)
Message receiver
company_metrics: Dict[str, Any] = shared_memory.value.take_message()
k = company_metrics['employees'] # 87_558 iterations/seconds
company_metrics['employees'] = 200 # 86_744 iterations/seconds
company_metrics['employees'] += 3 # 41_409 iterations/seconds
or even instead operating with dataclass (classes by default operate faster then dict):
Example
Message sender
@dataclass
class CompanyMetrics:
income: float
employees: int
avg_salary: float
annual_income: float
in_a_good_state: bool
emails: Tuple
websites = List[str]
company_metrics: CompanyMetrics = CompanyMetrics(
income=1.4,
employees: 12,
avg_salary: 35.0,
annual_income: 30_000.0,
in_a_good_state: False,
emails: ('sails@company.com', 'support@company.com'),
websites = ['http://company.com', 'http://company.org'],
)
company_metrics_mapped: CompanyMetrics = shared_memory.value.put_message(company_metrics)
Message receiver
company_metrics: CompanyMetrics = shared_memory.value.take_message()
k = company_metrics.employees # 850_098 iterations/seconds
company_metrics.employees = 200 # 207_480 iterations/seconds
company_metrics.employees += 1 # 152_263 iterations/seconds
it would be more beneficial to operate with a list and appropriate IntEnum indexes:
Example
Message sender:
class CompanyMetrics(IntEnum):
income = 0
employees = 1
avg_salary = 2
annual_income = 3
in_a_good_state = 4
emails = 5
websites = 6
company_metrics: List = intenum_dict_to_list({ # lists with IntEnum indexes are blazing-fast alternative to dictionaries
CompanyMetrics.websites: ['http://company.com', 'http://company.org'],
CompanyMetrics.avg_salary: 3_000.0,
CompanyMetrics.employees: 10,
CompanyMetrics.in_a_good_state: True,
}) # Unmentioned fields will be filled with Null values
company_metrics_mapped: List = shared_memory.value.put_message(company_metrics)
Message receiver:
company_metrics: List = shared_memory.value.take_message()
k = company_metrics[CompanyMetrics.avg_salary] # 1_535_267 iterations/seconds
company_metrics[CompanyMetrics.avg_salary] = 5_000.0 # 1_300_966 iterations/seconds
company_metrics[CompanyMetrics.avg_salary] += 1.1 # 299_415 iterations/seconds
Sets
Sets
You might use FastLimitedSet wrapper for your set in order to get much faster shared sets.
Just wrap your dictionary with FastLimitedSet:
my_obj: List = [
True,
2,
FastLimitedSet({
'Hello ',
'World',
3,
})
]
my_obj_mapped = shared_memory.value.put_message(my_obj)
Drawbacks of this approach: only initial set of items will be shared. Changes made to the mapped objects (an added or deleted items) will not be shared and will not be visible by other process.
Dictionaries
Dictionaries
You might use FastLimitedDict wrapper for your dict in order to get much faster shared dictionary.
Just wrap your dictionary with FastLimitedDict:
my_obj: List = [
True,
2,
FastLimitedDict({
1: 'Hello ',
'2': 'World',
3: np.array([1, 2, 3], dtype=np.int32),
})
]
my_obj_mapped = shared_memory.value.put_message(my_obj)
Drawbacks of this approach: only initial set of key-values pairs will be shared. Added, updated or deleted key-value pairs will not be shared and such changes will not be visible by other process.
Custom classes (including `dataclass`)
Custom classes (including dataclass)
By default, shared custom class instances (including dataclass instances) have static set of attributes (similar to instances of classes with __slots__). That means that all new (dynamically added to the mapped object, attributes will not became shared). This behavior increases performance.
For example
For example
@dataclass
class SomeSharedObject:
some_processing_stage_control: bool
int_value: int
str_value: str
data_dict: Dict[Hashable, Any]
company_info: CompanyInfo
my_obj: List = [
True,
2,
SomeSharedObject(
some_processing_stage_control=False,
int_value=18,
str_value='Hello, ',
data_dict=None,
company_info=None,
),
]
my_obj_mapped: List = shared_memory.value.put_message(my_obj)
my_obj_mapped[2].some_new_attribute = 'Hi!' # this attribute will Not became shared and as result will not became accessible by other process
If you need to share class instance with ability to add new shared attributes to it's mapped instance, you can wrap your object with either ForceGeneralObjectCopy or ForceGeneralObjectInplace
For example
For example
@dataclass
class SomeSharedObject:
some_processing_stage_control: bool
int_value: int
str_value: str
data_dict: Dict[Hashable, Any]
company_info: CompanyInfo
my_obj: List = [
True,
2,
ForceGeneralObjectInplace(SomeSharedObject(
some_processing_stage_control=False,
int_value=18,
str_value='Hello, ',
data_dict=None,
company_info=None,
)),
]
my_obj_mapped: List = shared_memory.value.put_message(my_obj)
my_obj_mapped[2].some_new_attribute = 'Hi!' # this attribute Will became shared and as result Will be seen by process
Difference between ForceGeneralObjectCopy and ForceGeneralObjectInplace:
ForceGeneralObjectInplace.my_obj_mapped = shared_memory.value.put_message(ForceGeneralObjectInplace(my_obj))call will change class of an originalmy_objobject. AndTrue == (my_obj is my_obj_mapped)ForceGeneralObjectCopy.my_obj_mapped = shared_memory.value.put_message(ForceGeneralObjectCopy(my_obj))call will Not change an originalmy_objobject.my_obj_mappedobject will be constructed from the scratch
Also you can tune a default behavior by wrapping your object with either ForceStaticObjectCopy or ForceStaticObjectInplace.
Difference between ForceStaticObjectCopy and ForceGeneralObjectInplace:
ForceGeneralObjectInplace.my_obj_mapped = shared_memory.value.put_message(ForceGeneralObjectInplace(my_obj))call will change class of an originalmy_objobject. AndTrue == (my_obj is my_obj_mapped)ForceStaticObjectCopy.my_obj_mapped = shared_memory.value.put_message(ForceStaticObjectCopy(my_obj))call will Not change an originalmy_objobject.my_obj_mappedobject will be constructed from the scratch
How to choose shared memory size
How to choose shared memory size
When setting the size parameter for SharedMemory, consider using broader units like tens (for embedded systems), hundreds, or thousands of megabytes, rather than precise byte counts. This approach is similar to how you would not precisely calculate the amount of memory needed for a web server hosted externally; you make an educated guess, like assuming that 256 MB might be insufficient but 768 MB could be adequate, and then adjust based on practical testing.
Also, be aware of memory fragmentation, which affects all memory allocation systems, including the OS itself. For example, if you have a SharedMemory pool sized to store exactly ten 64-bit integers, accounting for additional bytes for system information, your total might be around 200 bytes. Initially, after storing the integers, your memory might appear as ["int", "int", ..., "int"]. If you delete every second integer, the largest contiguous free memory chunk could be just 10 bytes, despite having 50 bytes free in total. This fragmentation means you cannot store a larger data structure like a 20-byte string which needs contiguous space.
To resolve this, simply increase the size parameter value of SharedMemory. This is akin to how you would manage memory allocation for server hosting or thread stack sizes in software development.
Benchmarks
System
- CPU: i5-3570@3.40GHz (Ivy Bridge)
- RAM: 32 GBytes, DDR3, dual channel, 655 MHz
- OS: Ubuntu 20.04.6 LTS under WSL2. Windows 10
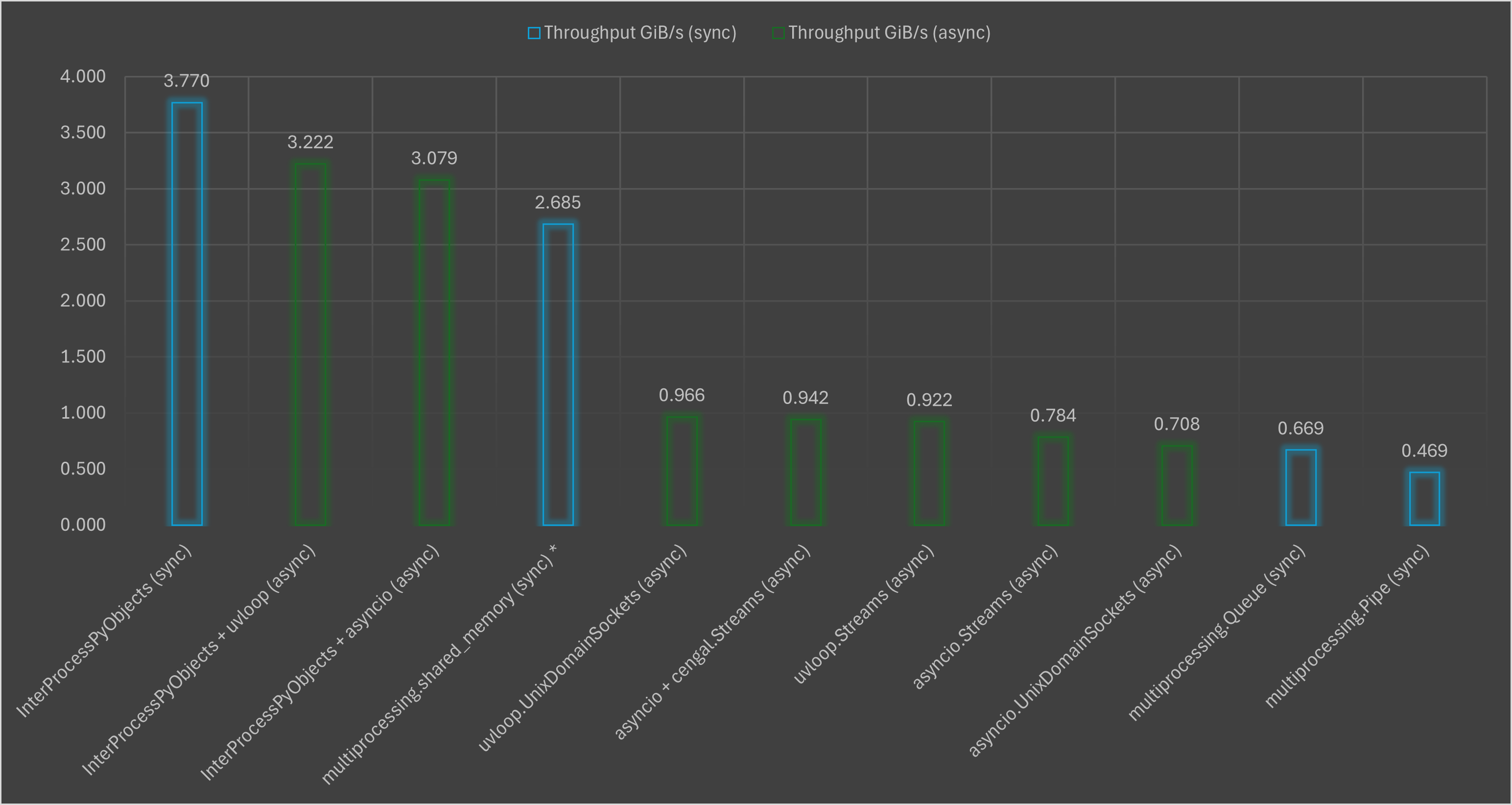
Throughput GiB/s
Benchmarks results
Refference results (sysbench)
sysbench memory --memory-oper=write run
5499.28 MiB/sec
Results
* multiprocessing.shared_memory.py - simple implementation. This is a simple implementation because it uses a similar approach to the one used in uvloop.*, asyncio.*, multiprocessing.Queue, and multiprocessing.Pipe benchmarking scripts. Similar implementations are expected to be used by the majority of projects.
Benchmarks results table
| Approach | sync/async | Throughput GiB/s |
|---|---|---|
| InterProcessPyObjects (sync) | sync | 3.770 |
| InterProcessPyObjects + uvloop | async | 3.222 |
| InterProcessPyObjects + asyncio | async | 3.079 |
| multiprocessing.shared_memory | sync | 2.685 |
| uvloop.UnixDomainSockets | async | 0.966 |
| asyncio + cengal.Streams | async | 0.942 |
| uvloop.Streams | async | 0.922 |
| asyncio.Streams | async | 0.784 |
| asyncio.UnixDomainSockets | async | 0.708 |
| multiprocessing.Queue | sync | 0.669 |
| multiprocessing.Pipe | sync | 0.469 |
Benchmark scripts
- InterProcessPyObjects - Sync:
- InterProcessPyObjects - Async (uvloop):
- InterProcessPyObjects - Async (asyncio):
- multiprocessing.shared_memory.py
- uvloop.UnixDomainSockets.py
- asyncio_with_cengal.Streams.py
- uvloop.Streams.py
- asyncio.Streams.py
- asyncio.UnixDomainSockets.py
- multiprocessing.Queue.py
- multiprocessing.Pipe.py
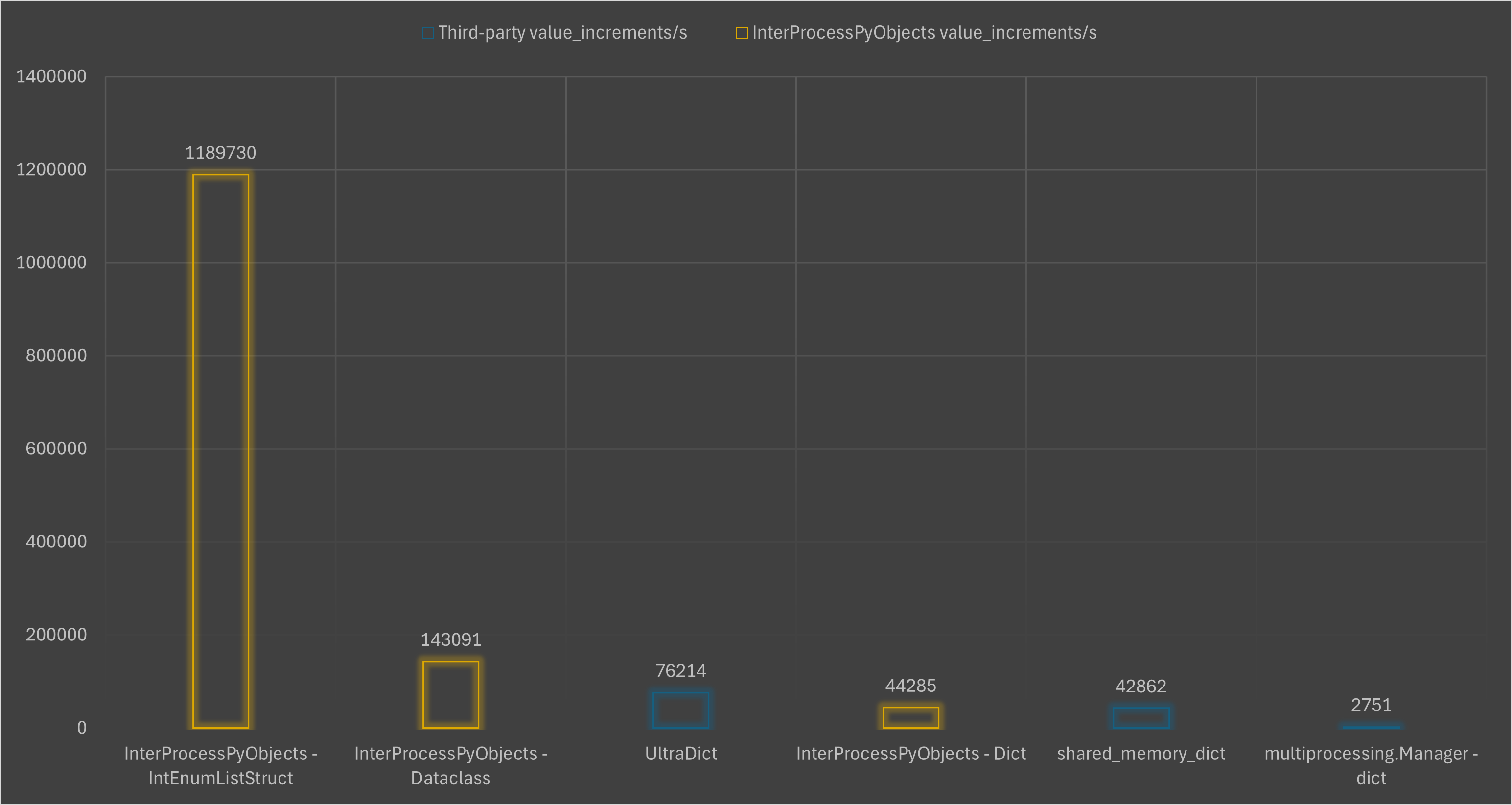
Shared Dict Performance
Benchmarks results
Competitors:
1. multiprocessing.Manager - dict
Pros:
- Part of the standard library
Cons:
- Slowest solution
- Values are read-only unless they are an explicit instances of
multiprocessing.Managersupported types (types inherited frommultiprocessing.BaseProxylikemultiprocessing.DictProxyormultiprocessing.ListProxy)
Benchmark scripts:
2. UltraDict
Pros:
- Relatively fast writes
- Fast repetitive reads of an unchanged values
- Has built in inter-process synchronization mechanism
Cons:
- Relies on pickle on an each change
- Non-dictionary values are read-only from the multiprocessing perspective
Benchmark scripts:
3. shared_memory_dict
Pros:
- At least faster than 'multiprocessing.Manager - dict' solution
Cons:
- Second slowest solution
- Relies on pickle on an each change
- Values (even lists or dicts) are read-only from the multiprocessing perspective
- Can not be initialized from the other
dictnor even from the otherSharedMemoryDictinstance: you need to manually put an each key-value pair into it using loop - Has known issues with inter-process synchronization. Is is better for developer to use their own external inter-process synchronization mechanisms (from
multiprocessing.Managerfor example)
Benchmark scripts:
4. InterProcessPyObjects - IntEnumListStruct
Pros:
- Fastest solution: 15.6 times faster than
UltraDict - Good for structures: when all fields are already known
- Support any InterProcessPyObjects' supported data types as values
- Values of mutable types are naturally mutable: developer do not need to prepare and change their data explicitly
Cons:
- Can use only IntEnum (int) keys
- Fixed size of a size of a provided IntEnum
Benchmark scripts:
Message sender example:
class CompanyMetrics(IntEnum):
income = 0
employees = 1
avg_salary = 2
annual_income = 3
in_a_good_state = 4
emails = 5
websites = 6
company_metrics: List = intenum_dict_to_list({ # lists with IntEnum indexes are blazing-fast alternative to dictionaries
CompanyMetrics.websites: ['http://company.com', 'http://company.org'],
CompanyMetrics.avg_salary: 3_000.0,
CompanyMetrics.employees: 10,
CompanyMetrics.in_a_good_state: True,
}) # Unmentioned fields will be filled with Null values
company_metrics_mapped: List = shared_memory.value.put_message(company_metrics)
Message receiver example:
company_metrics: List = shared_memory.value.take_message()
k = company_metrics[CompanyMetrics.avg_salary]
company_metrics[CompanyMetrics.avg_salary] = 5_000.0
company_metrics[CompanyMetrics.avg_salary] += 1.1
5. InterProcessPyObjects - Dataclass
Pros:
- Fast. Second fastest solution: around 2 times faster than
UltraDict - Good for structures and object: when all fields are already known
- Works with objects naturally - without an explicit preparation or changes from the developer's side
- Support any InterProcessPyObjects' supported data types as values
- Supports
dataclassas well as other objects - Supports object's methods
- Fields of mutable types are naturally mutable: developer do not need to prepare and change their data explicitly
- Does not relies on frequent data pickle: uses pickle only for an initial object construction but not for the fields updates
Cons:
- Set of fields is fixed by the set of fields of an original object
Benchmark scripts:
6. InterProcessPyObjects - Dict
Pros:
- Slightly faster than
SharedMemoryDict - Works with objects naturally - without an explicit preparation or changes from the developer's side
- Support any InterProcessPyObjects' supported data types as values
- Support any InterProcessPyObjects' supported Hashable data types as keys
- Values of mutable types are naturally mutable: developer do not need to prepare and change their data explicitly
- Does not relies on pickle
- Speed optimizations are architectures and planned for an implementation
Cons:
- Speed optimization implementation are in progress - not released yet
Benchmark scripts:
Results
Benchmarks results table
| Approach | increments/s |
|---|---|
| InterProcessPyObjects - IntEnumListStruct | 1189730 |
| InterProcessPyObjects - Dataclass | 143091 |
| UltraDict | 76214 |
| InterProcessPyObjects - Dict | 44285 |
| SharedMemoryDict | 42862 |
| multiprocessing.Manager - dict | 2751 |
Todo
- Connect more than two processes
- Use third-party fast hashing implementations instead of or in addition to built in
hash()call - Continuous performance improvements
Conclusion
This Python package provides a robust solution for inter-process communication, supporting a variety of Python data structures, types, and third-party libraries. Its lock-free synchronization and asyncio compatibility make it an ideal choice for high-performance, concurrent execution.
Based on Cengal
This is a stand-alone package for a specific Cengal module. Package is designed to offer users the ability to install specific Cengal functionality without the burden of the library's full set of dependencies.
The core of this approach lies in our 'cengal-light' package, which houses both Python and compiled Cengal modules. The 'cengal' package itself serves as a lightweight shell, devoid of its own modules, but dependent on 'cengal-light[full]' for a complete Cengal library installation with all required dependencies.
An equivalent import:
from cengal.hardware.memory.shared_memory import *
from cengal.parallel_execution.asyncio.ashared_memory_manager import *
Cengal library can be installed by:
pip install cengal
https://github.com/FI-Mihej/Cengal
https://pypi.org/project/cengal/
Projects using Cengal
- CengalPolyBuild - A Comprehensive and Hackable Build System for Multilingual Python Packages: Cython (including automatic conversion from Python to Cython), C/C++, Objective-C, Go, and Nim, with ongoing expansions to include additional languages. (Planned to be released soon)
- cengal_app_dir_path_finder - A Python module offering a unified API for easy retrieval of OS-specific application directories, enhancing data management across Windows, Linux, and macOS
- cengal_cpu_info - Extended, cached CPU info with consistent output format.
- cengal_memory_barriers - Fast cross-platform memory barriers for Python.
- flet_async - wrapper which makes Flet async and brings booth Cengal.coroutines and asyncio to Flet (Flutter based UI)
- justpy_containers - wrapper around JustPy in order to bring more security and more production-needed features to JustPy (VueJS based UI)
- Bensbach - decompiler from Unreal Engine 3 bytecode to a Lisp-like script and compiler back to Unreal Engine 3 bytecode. Made for a game modding purposes
- Realistic-Damage-Model-mod-for-Long-War - Mod for both the original XCOM:EW and the mod Long War. Was made with a Bensbach, which was made with Cengal
- SmartCATaloguer.com - TagDB based catalog of images (tags), music albums (genre tags) and apps (categories)
License
Copyright © 2012-2024 ButenkoMS. All rights reserved.
Licensed under the Apache License, Version 2.0.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file interprocesspyobjects-1.0.7.tar.gz.
File metadata
- Download URL: interprocesspyobjects-1.0.7.tar.gz
- Upload date:
- Size: 30.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
725c5ce10a48e1aada2daf3fc8db7f9f9fbb45c92e14769fd8635111ff054c96
|
|
| MD5 |
81ba886be137f680add3e5c7eca9ee54
|
|
| BLAKE2b-256 |
eba51add6cb55b93747690900951361997f8db3f6410d2b57d94fc81dfd05a1a
|
File details
Details for the file interprocesspyobjects-1.0.7-py3-none-any.whl.
File metadata
- Download URL: interprocesspyobjects-1.0.7-py3-none-any.whl
- Upload date:
- Size: 21.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
38b58c86daa7c9dc8e1b1c4dadad6b7058088cc2102a8b5e786b6cbfbf32724c
|
|
| MD5 |
336de93447bb71f4cbae31772eee198b
|
|
| BLAKE2b-256 |
a3bba090803c9a74bb78fafa1f39b339adb1310f4b4338dfc3e4e73b6b4a8563
|







