KAVICA: Powerful Python Cluster Analysis and Inference Toolkit

Project description

KAVICA: Powerful Python Cluster Analysis and Inference Toolkit






What is it?
kavica is a Python package that provides semi-automated, flexible, and expressive clustering analysis designed to make working with "unlabeled" data easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world cluster analysis in Python. Additionally, it has the broader goal of becoming A powerful and flexible open source AutoML unsupervised / clustering analysis tool and pipeline. It is already well on its way towards this goal.
Main Features
Here are just a few of the things that kavica does well:
-
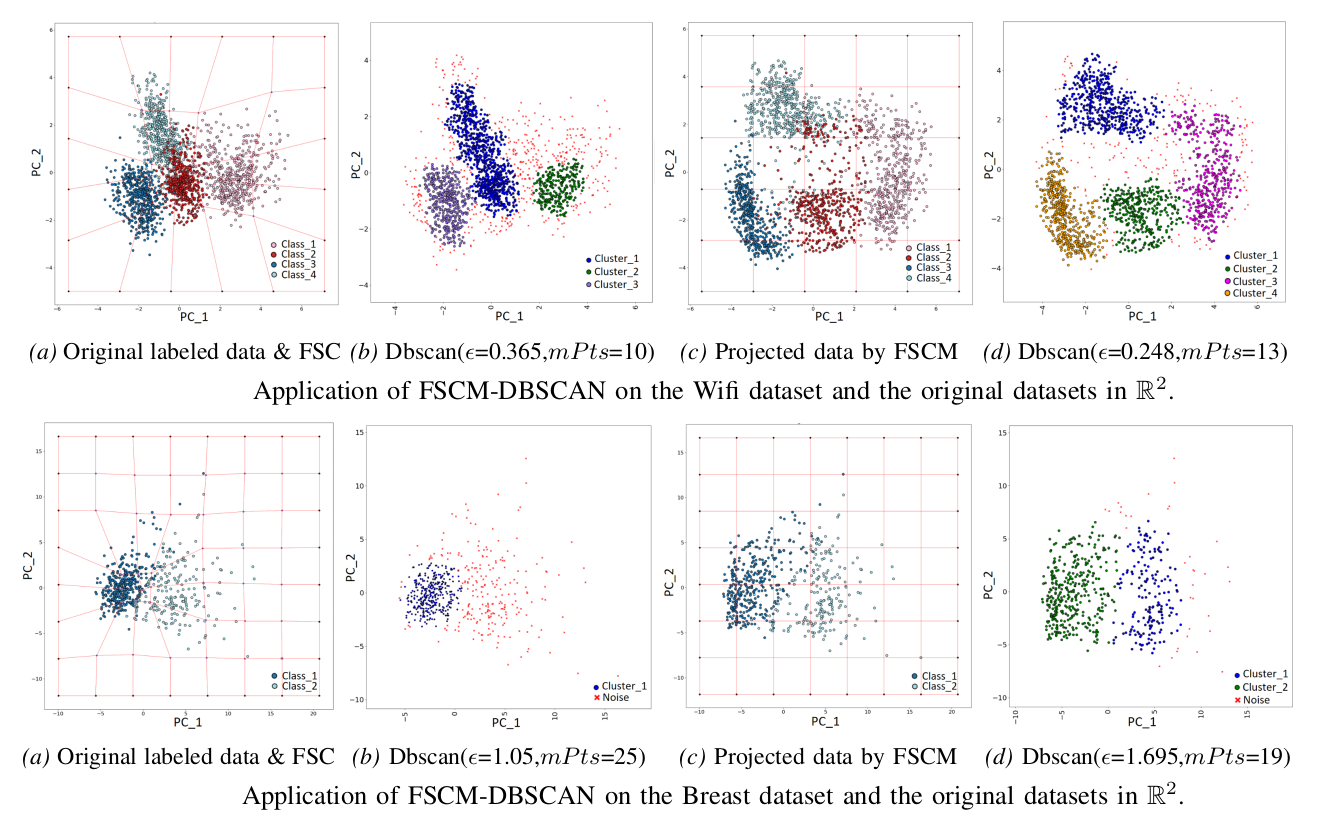
Intelligent Density Maping to model the density structuer of the data in analogy to Einstein's theory of relativity, and automated Density Homogenizing to prepare the data for the density-based clustering (e.g DBSCAN)
-
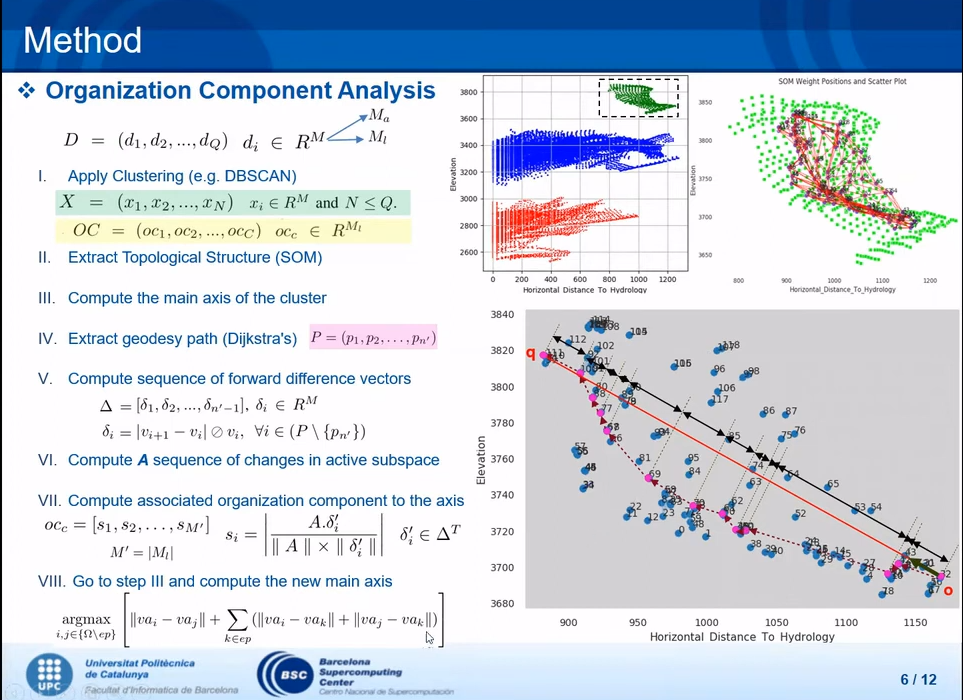
Automatic, and powerful Organization Component Analysis to interpret the clustering result by understanding the topological structuer of each cluster
-
Topological and powerful Self-Organizing Maps Inference System to use the self-learning ability of the SOM to understand the topological structuer of the data
-
Automated and Bayesian-based DBSCAN Hyper-parameter Tuner to select the optimal hyper-parameters configuration of the DBSCAN clustering algorithm
-
Efficient handling of feature selection in a potentially high-dimensional and massive datasets
-
Gravitational implementation of Kohonen Generational Self-Organizing Maps ( GSOM) useful for unsupervised learning and supper-clustering by providing an enriched graphics, plots and animations features.
-
Computational geometrical model Polygonal Cage to transfer feature vectors from a curved non-euclidean feature space to a new euclidean one.
-
Robust factor analysis to reduce a large number of variables into fewer numbers
-
Easy handling of missing data (represented as
NaN,NA, orNaT) in floating point as well as non-floating point data -
Flexible implementation of directed and undirected graph data structuer and algorithms.
-
Intuitive resampling data sets
-
Powerful, flexible parser functionality to perform parsing, manipulating, and generating operations on flat, massive and unstructured Traces datasets which are generated by MareNostrum
-
Utilities functionality: intuitive explanatory data analysis, plotting, load and generate data, and etc...
Examples:
-
-
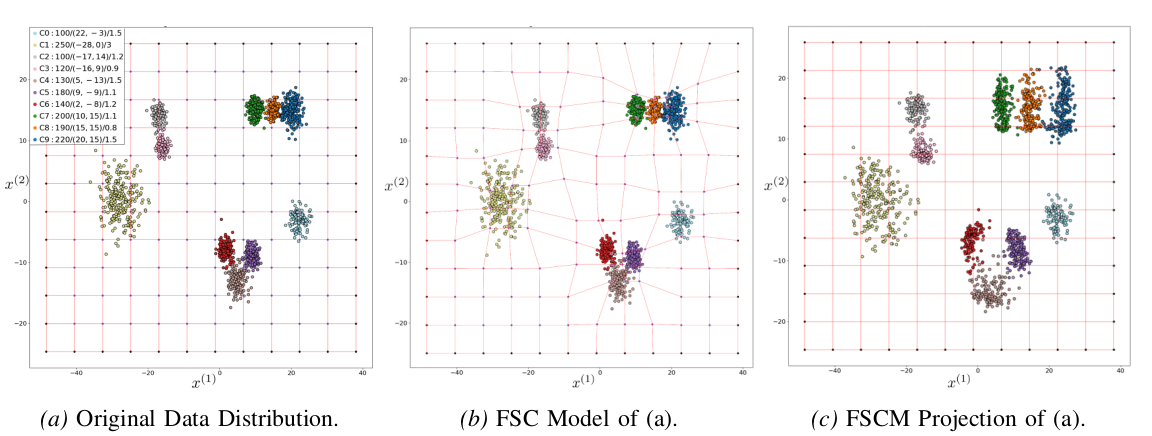
Application of Feature Space Curvature Map on a multi-density 2D dataset Synt10 containing ten clusters. (a) A scatter plot of clusters with varied densities. The legend shows the size/N(μ,σ2) per cluster, the colors represent the data original labeling and the red lines draw the initial FSF. (b) shows the FSC model that is computed with our FSCM method. Note that the red lines show the deformation of the FSF. (c) scatter plots the data (a) projected by applying our transformation through model (b). As a result, the diversity of the clusters’ density scaled appropriately to achieve a better density-based clustering performance.
-
Polygonal Cage Multilinear transformation
Feature Space Curvetuer Feature Space Fabric
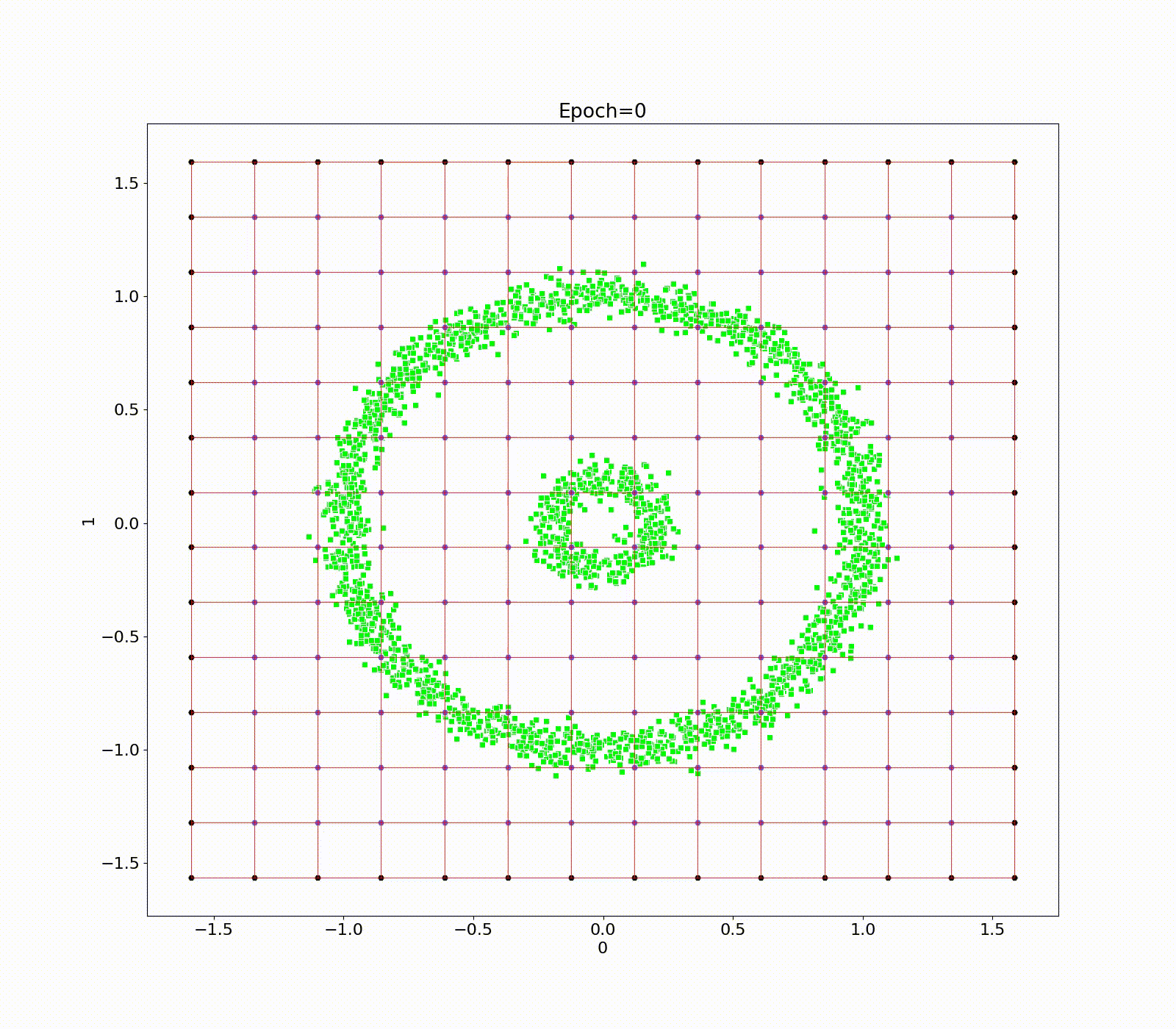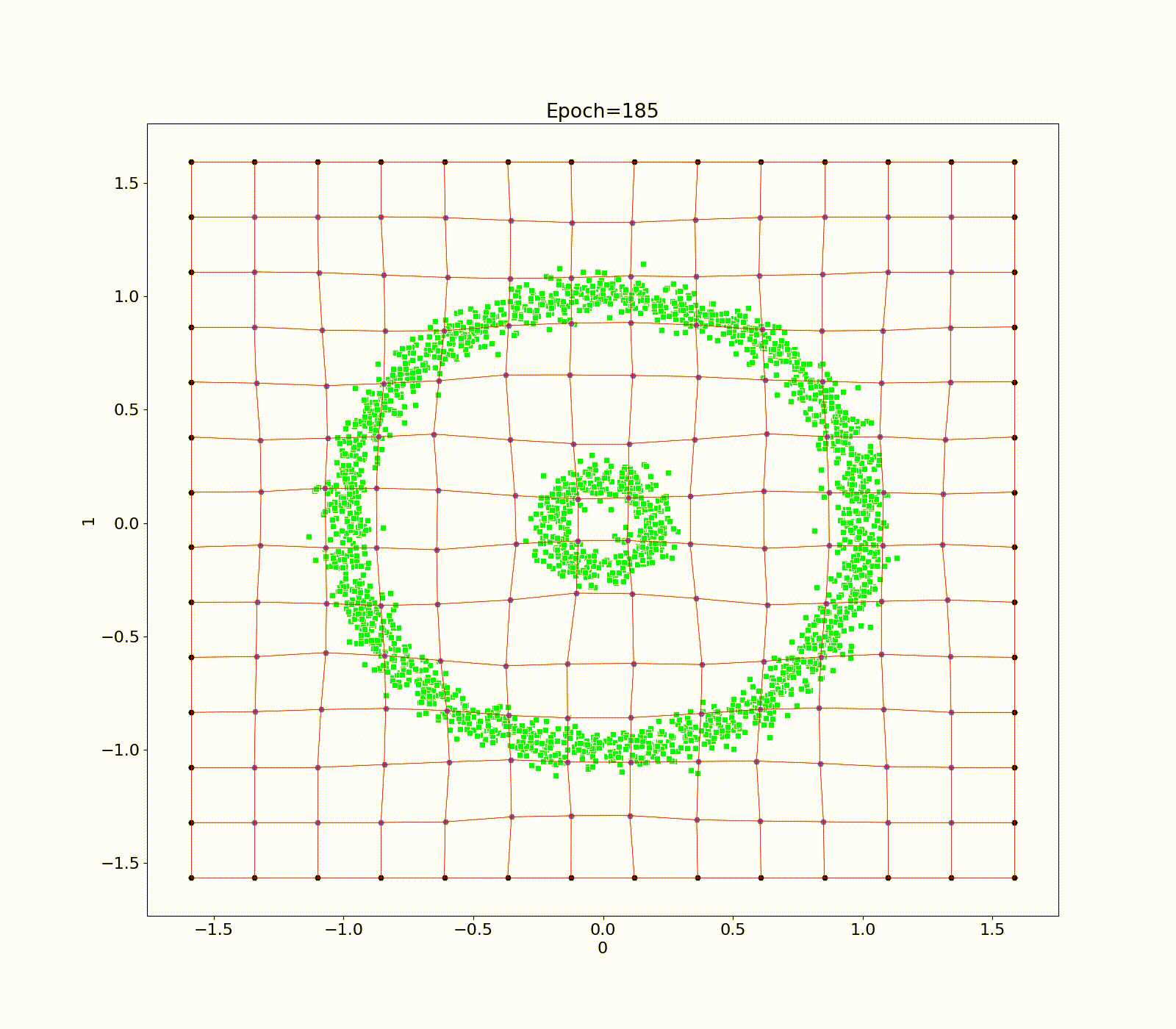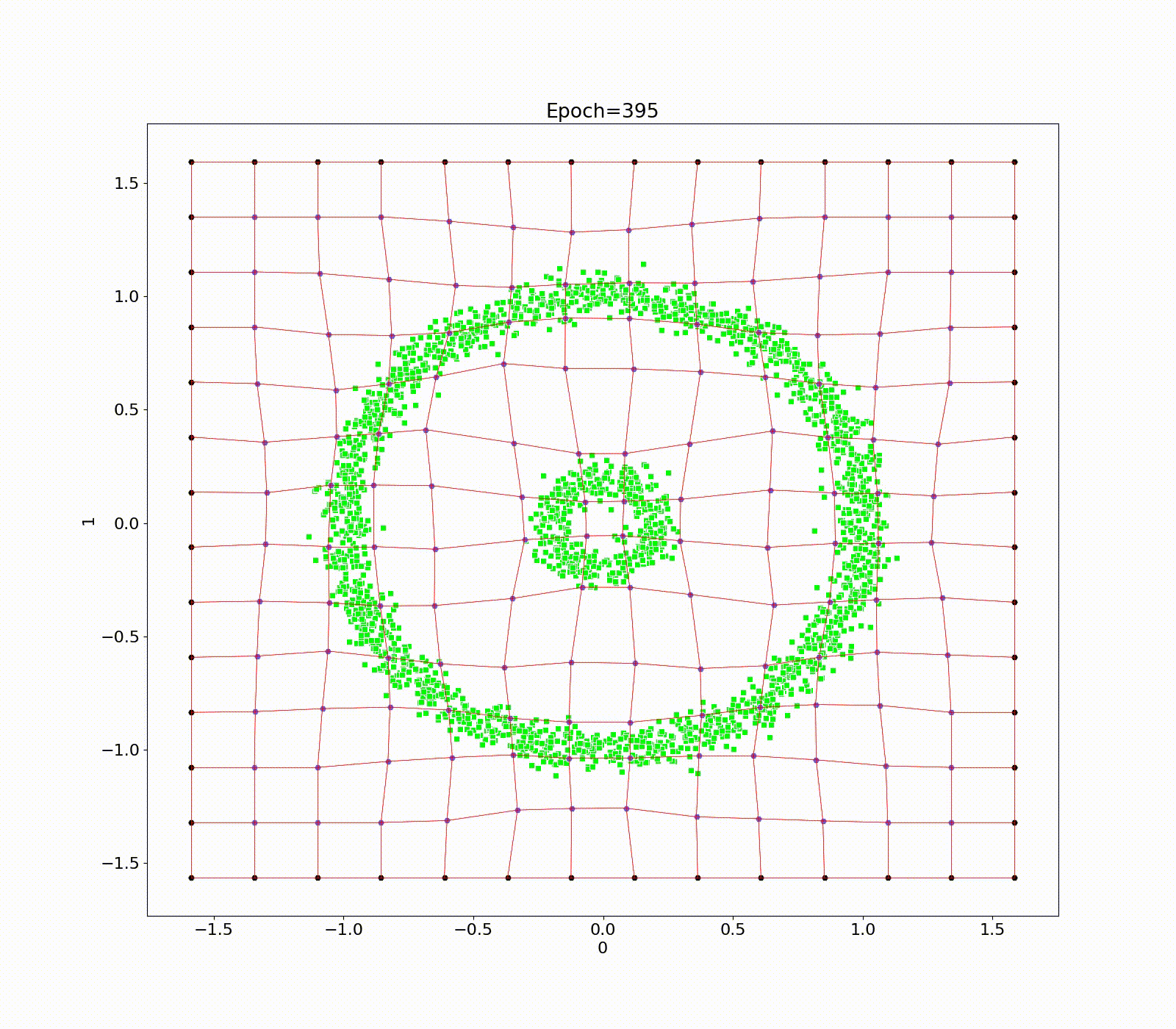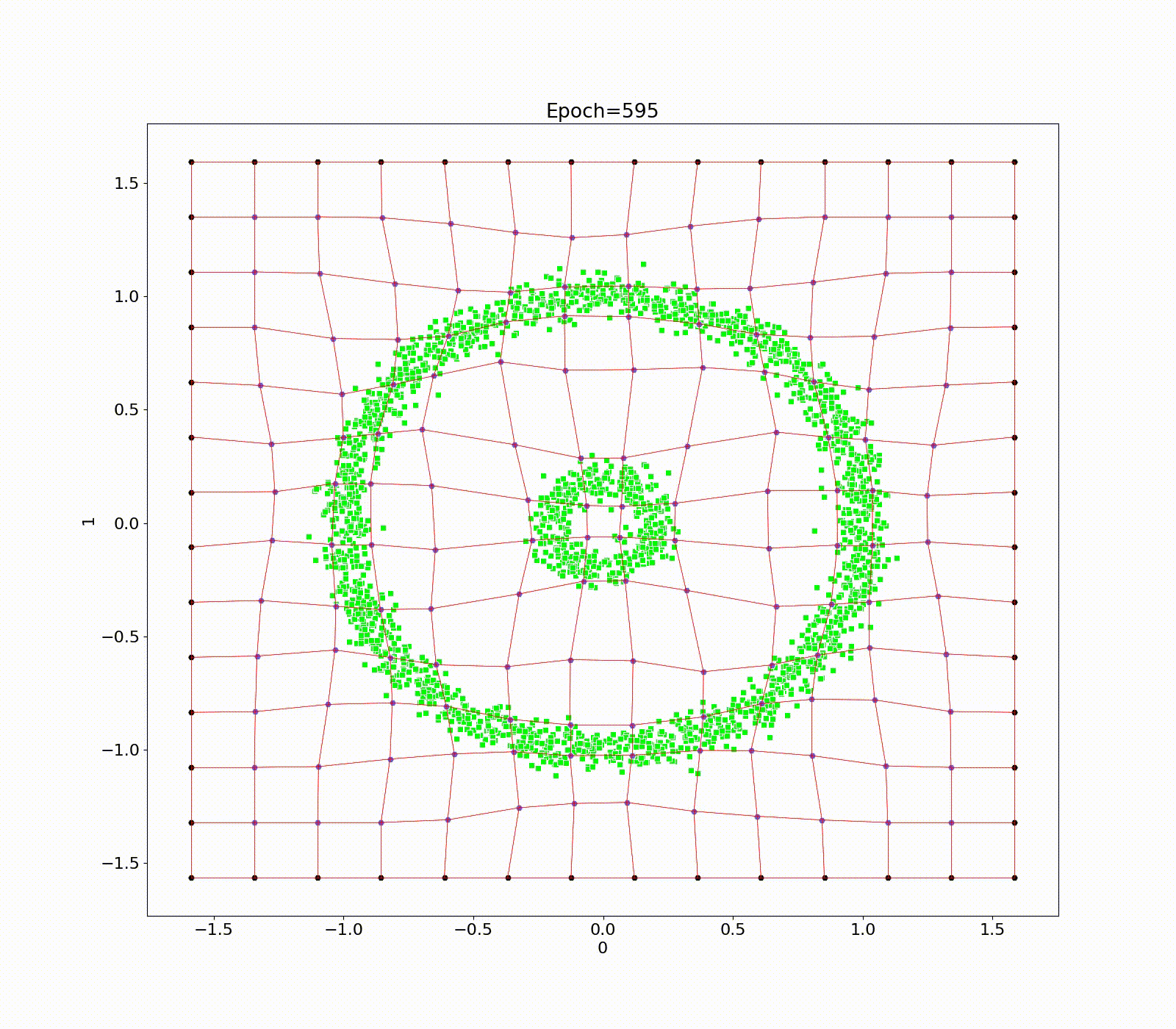
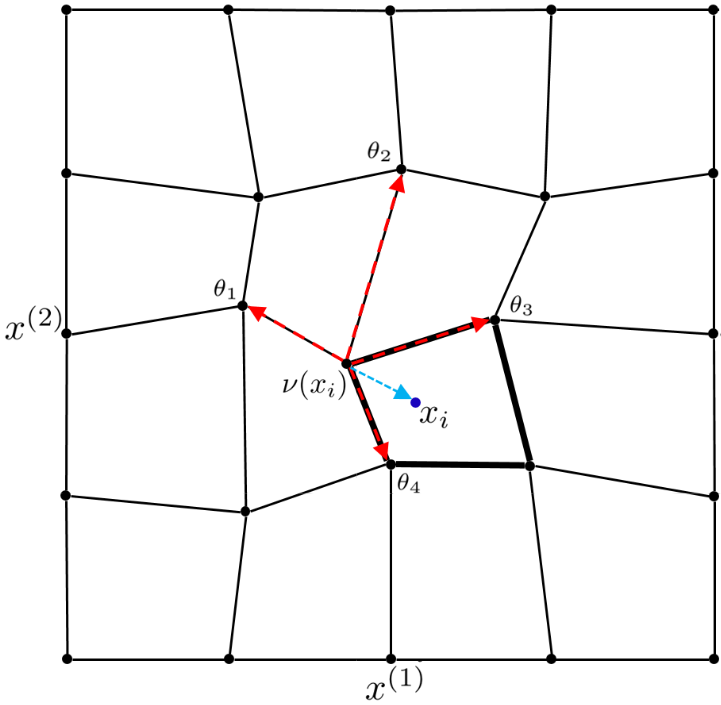
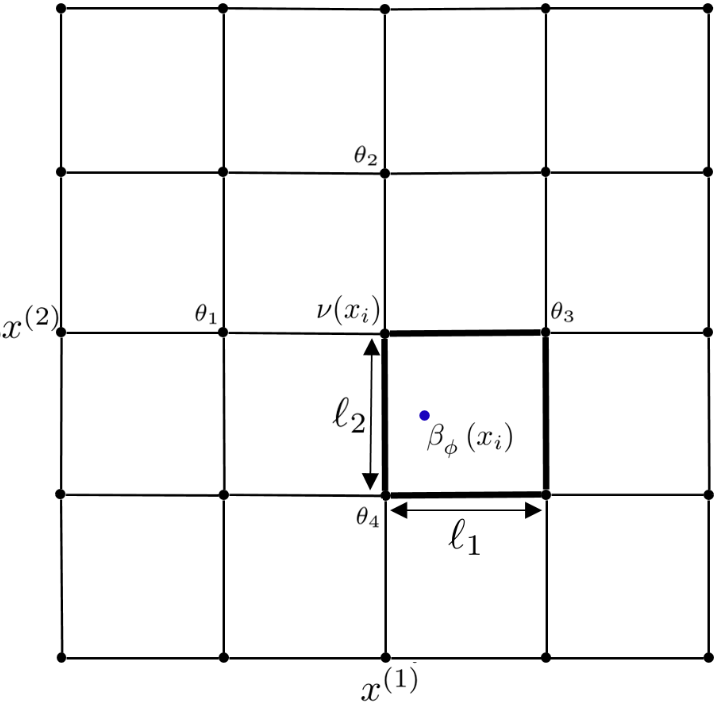
Data point transformation between a bent FSC (a) and regular FSF (b) based on the Multi-linear transformation in R2.
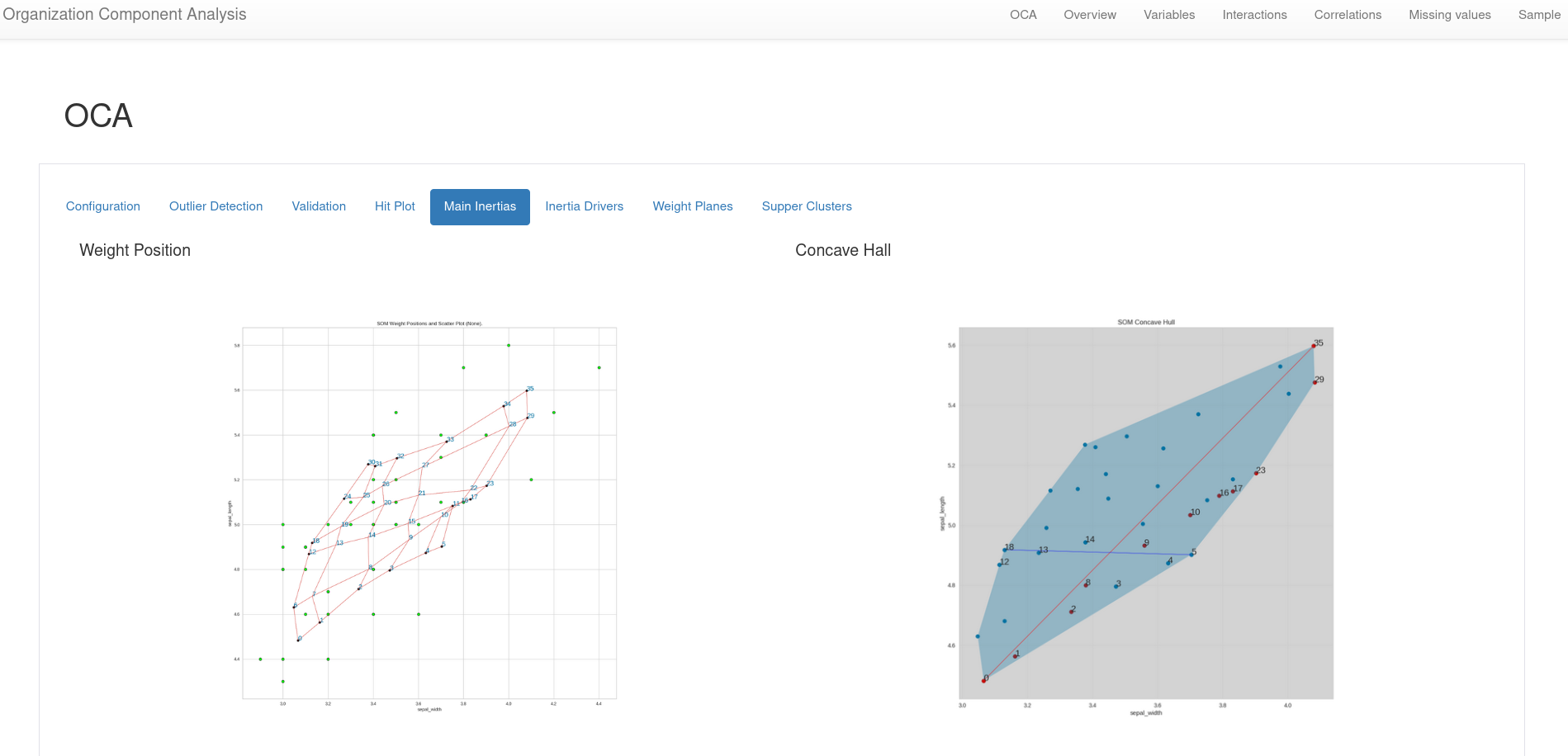
- Organization Component Analysis
Application of the OCA on the Iris dataset
Video
Where to get it
The source code is currently hosted on GitHub at: kavica
Binary installers for the latest released version are available at the Python Package Index (PyPI) and on Conda.
The recommended way to install kavica is to use:
# PyPI
pip install kavica
But it can also be installed using:
# or conda
conda config --add channels conda-forge
conda install kavica
To verify your setup, start Python from the command line and run the following:
import kavica
Dependencies
See the requirement.txt for installing the required packages:
pip install -r requirements.txt
Publications
Unsupervised Feature Selection for Noisy Data
Organization Component Analysis: The method for extracting insights from the shape of cluster
Feature Space Curvature Map: A Method To Homogenize Cluster Densities
Issue tracker
If you find a bug, please help us solve it by filing a report.
Contributing
If you want to contribute, check out the contribution guidelines.
License
The main library of kavica is released under the BSD 3 clause license.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file KAVICA-1.3.4.tar.gz.
File metadata
- Download URL: KAVICA-1.3.4.tar.gz
- Upload date:
- Size: 155.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.3 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.12 tqdm/4.64.1 importlib-metadata/4.8.3 keyring/23.4.1 rfc3986/1.5.0 colorama/0.4.5 CPython/3.6.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e94bda9414d7ca3e32a5067aa1609e5a78d68e8a561ac5b48053469ac7bd7461
|
|
| MD5 |
0d4f84ac50ba4209aa5e38a6a9b6d042
|
|
| BLAKE2b-256 |
d912fe2854a76f83bd31dab3ddb24e8e00b57a3f95c10ce718d9b15feb68cfc6
|







