A multiprocessing web crawling and web scraping framework.

Project description
MultiprocessingSpider
Description
MultiprocessingSpider is a simple and easy to use web crawling and web scraping framework.
Architecture
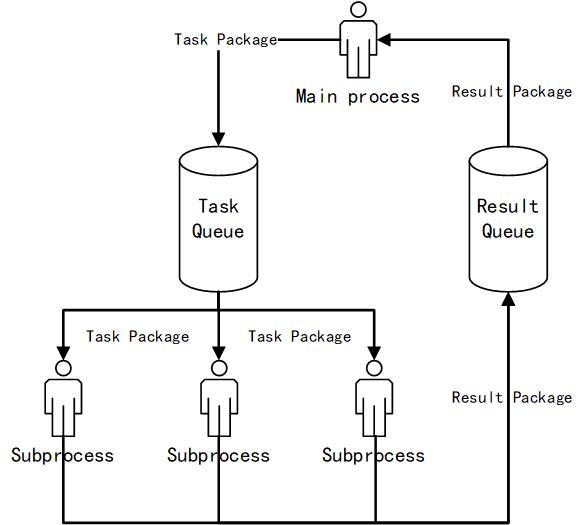
Dependencies
- requests
Installation
pip install MultiprocessingSpider
Basic Usage
MultiprocessingSpider
from MultiprocessingSpider.spiders import MultiprocessingSpider
from MultiprocessingSpider.packages import TaskPackage, ResultPackage
class MyResultPackage(ResultPackage):
def __init__(self, prop1, prop2, sleep=True):
super().__init__(sleep)
self.prop1 = prop1
self.prop2 = prop2
class MySpider(MultiprocessingSpider):
start_urls = ['https://www.a.com/page1']
proxies = [
{"http": "http://111.111.111.111:80"},
{"http": "http://123.123.123.123:8080"}
]
def router(self, url):
return self.parse
def parse(self, response):
# Parsing task or new page from "response"
...
# Yield a task package
yield TaskPackage('https://www.a.com/task1')
...
# Yield a url or a url list
yield 'https://www.a.com/page2'
...
yield ['https://www.a.com/page3', 'https://www.a.com/page4']
@classmethod
def subprocess_handler(cls, package, sleep_time, timeout, retry):
url = package.url
# Request "url" and parse data
...
# Return result package
return MyResultPackage('value1', 'value2')
@staticmethod
def process_result_package(package):
# Processing result package
if 'value1' == package.prop1:
return package
else:
return None
if __name__ == '__main__':
s = MySpider()
# Start the spider
s.start()
# Block current process
s.join()
# Export results to csv file
s.to_csv('result.csv')
# Export results to json file
s.to_json('result.json')
FileSpider
from MultiprocessingSpider.spiders import FileSpider
from MultiprocessingSpider.packages import FilePackage
class MySpider(FileSpider):
start_urls = ['https://www.a.com/page1']
stream = True
buffer_size = 1024
overwrite = False
def router(self, url):
return self.parse
def parse(self, response):
# Parsing task or new page from "response"
...
# Yield a file package
yield FilePackage('https://www.a.com/file.png', 'file.png')
...
# Yield a new url or a url list
yield 'https://www.a.com/page2'
...
yield ['https://www.a.com/page3', 'https://www.a.com/page4']
if __name__ == '__main__':
s = MySpider()
# Add a url
s.add_url('https://www.a.com/page5')
# Start the spider
s.start()
# Block current process
s.join()
FileDownloader
from MultiprocessingSpider.spiders import FileDownloader
if __name__ == '__main__':
d = FileDownloader()
# Start the downloader
d.start()
# Add a file
d.add_file('https://www.a.com/file.png', 'file.png')
# Block current process
d.join()
More examples → GitHub
License
GPLv3.0
This is a free library, anyone is welcome to modify : )
Release Note
v1.1.2
Refactor
- Remove property "name" from "FileDownloader".
- Complete class "UserAgentGenerator" in "MultiprocessingSpider.Utils".
- Continue to optimize the setter method of each property. An exception will be raised if the value is invalid. "sleep_time" now can be set to 0.
- Change the sleep strategy of subprocess, subprocess will sleep after receiving the task package to prevent multiple requests from being sent at the same time.
v1.1.1
Bug Fixes
- Fix "start_urls" invalidation.
v1.1.0
Features
- Add overwrite option for "FileSpider".
- Add routing system. After overriding "router" method, you can yield a single url or a url list in your parse method.
Bug Fixes
- Fix retry message display error.
Refactor
- Optimize setter method. Now you can do this: spider.sleep_time = ' 5'.
- Will not resend request when "status_code" is not between 200 and 300.
a) MultiprocessingSpider
- Rename property "handled_url_table" to "handled_urls".
- Remove method "parse", add "example_parse_method".
- "User-Agent" in "web_headers" is now generated randomly.
- Change url_table parsing order, current rule: "FIFP" (first in first parse).
b) FileDownloader
- Remove "add_files" method.
v1.0.0
- The first version.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file MultiprocessingSpider-1.1.2.tar.gz.
File metadata
- Download URL: MultiprocessingSpider-1.1.2.tar.gz
- Upload date:
- Size: 26.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.2.0 requests-toolbelt/0.9.1 tqdm/4.41.0 CPython/3.8.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ff9ad77b59c567ca5cbd81be17b398f2bc153c9a80f2494970f03f5b9105e79e
|
|
| MD5 |
85b162f5d5285e0acf5479494558e7bb
|
|
| BLAKE2b-256 |
7014d0828b44a5ced215a93b4015558da303c608da5558a3a8a7cb39adc50f9c
|
File details
Details for the file MultiprocessingSpider-1.1.2-py3-none-any.whl.
File metadata
- Download URL: MultiprocessingSpider-1.1.2-py3-none-any.whl
- Upload date:
- Size: 27.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.2.0 requests-toolbelt/0.9.1 tqdm/4.41.0 CPython/3.8.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d644da61239beb03e337251770399a4d0f1a0941a0457b523b2fb54d25093c38
|
|
| MD5 |
0b1cf3d10c7709a62691092e19a10d3b
|
|
| BLAKE2b-256 |
93c4cf3ddf874d0fcf7df369cc7dfb0ec7708fbc1740fc5504b0992478fbcfb9
|







