Handling Cross- and Out-of-Domain Samples in Thai Word Segmentation (ACL 2020 Findings) Stacked Ensemble Framework and DeepCut as Baseline model


Project description
OSKut (Out-of-domain StacKed cut for Word Segmentation)


Handling Cross- and Out-of-Domain Samples in Thai Word Segmentation (ACL 2021 Findings)
Stacked Ensemble Framework and DeepCut as Baseline model
Read more:
- Paper: Handling Cross- and Out-of-Domain Samples in Thai Word Segmentation
- Related Work (EMNLP2020): Domain Adaptation of Thai Word Segmentation Models using Stacked Ensemble
- Blog: Domain Adaptation กับตัวตัดคำ มันดีย์จริงๆ
Citation
@inproceedings{limkonchotiwat-etal-2021-handling,
title = "Handling Cross- and Out-of-Domain Samples in {T}hai Word Segmentation",
author = "Limkonchotiwat, Peerat and
Phatthiyaphaibun, Wannaphong and
Sarwar, Raheem and
Chuangsuwanich, Ekapol and
Nutanong, Sarana",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.86",
doi = "10.18653/v1/2021.findings-acl.86",
pages = "1003--1016",
}
Install
pip install OSKut
How To use
Requirements
- python >= 3.6
- tensorflow >= 2.0
Example
- Example files are on OSKut Example notebook
- Try it on Colab
Load Engine & Engine Mode
- ws, tnhc, and BEST !!
- ws: The model trained on Wisesight-1000 and test on Wisesight-160
- ws-augment-60p: The model trained on Wisesight-1000 augmented with top-60% entropy
- tnhc: The model trained on TNHC (80:20 train&test split with random seed 42)
- BEST: The model trained on BEST-2010 Corpus (NECTEC)
- SCADS: The model trained on VISTEC-TP-TH-2021 Corpus (VISTEC)
oskut.load_model(engine='ws') # OR oskut.load_model(engine='ws-augment-60p') # OR oskut.load_model(engine='tnhc') # OR oskut.load_model(engine='best') # OR oskut.load_model(engine='scads') # OR
- tl-deepcut-XXXX
- We also provide transfer learning of deepcut on 'Wisesight' as tl-deepcut-ws, 'TNHC' as tl-deepcut-tnhc, and 'LST20' as tl-deepcut-lst20
oskut.load_model(engine='tl-deepcut-ws') # OR oskut.load_model(engine='tl-deepcut-tnhc')
- deepcut
- We also provide the original deepcut
oskut.load_model(engine='deepcut')
Segment Example
You need to read the paper to understand why we have $k$ value!
- Tokenize with default k-value
oskut.load_model(engine='ws') print(oskut.OSKut(['เบียร์ยูไม่อร่อยสัดๆๆๆๆๆฟๆ'])) print(oskut.OSKut('เบียร์ยูไม่อร่อยสัดๆๆๆๆๆฟๆ')) ['เบียร์', 'ยู', 'ไม่', 'อร่อย', 'สัด', 'ๆ', 'ๆ', 'ๆ', 'ๆ', 'ๆฟ', 'ๆ'] ['เบียร์', 'ยู', 'ไม่', 'อร่อย', 'สัด', 'ๆ', 'ๆ', 'ๆ', 'ๆ', 'ๆฟ', 'ๆ']
- Tokenize with a various k-value
oskut.load_model(engine='ws') print(oskut.OSKut('เบียร์ยูไม่อร่อยสัดๆๆๆๆๆฟๆ',k=5)) # refine only 5% of character number print(oskut.OSKut('เบียร์ยูไม่อร่อยสัดๆๆๆๆๆฟๆ',k=100)) # refine 100% of character number ['เบียร์', 'ยู', 'ไม่', 'อร่อย', 'สัด', 'ๆ', 'ๆ', 'ๆ', 'ๆ', 'ๆฟๆ'] ['เบียร์', 'ยู', 'ไม่', 'อร่อย', 'สัด', 'ๆ', 'ๆ', 'ๆ', 'ๆ', 'ๆฟ', 'ๆ']
New datasets!!
VISTEC-TP-TH-2021 (VISTEC), which consists of 49,997 text samples from Twitter (2017-2019).
VISTEC corpus contains 49,997 sentences with 3.39M words where the collection was manually annotated by linguists on four tasks, namely word segmentation, misspelling detection and correction, and named entity recognition.
For more information and download click here
Performance
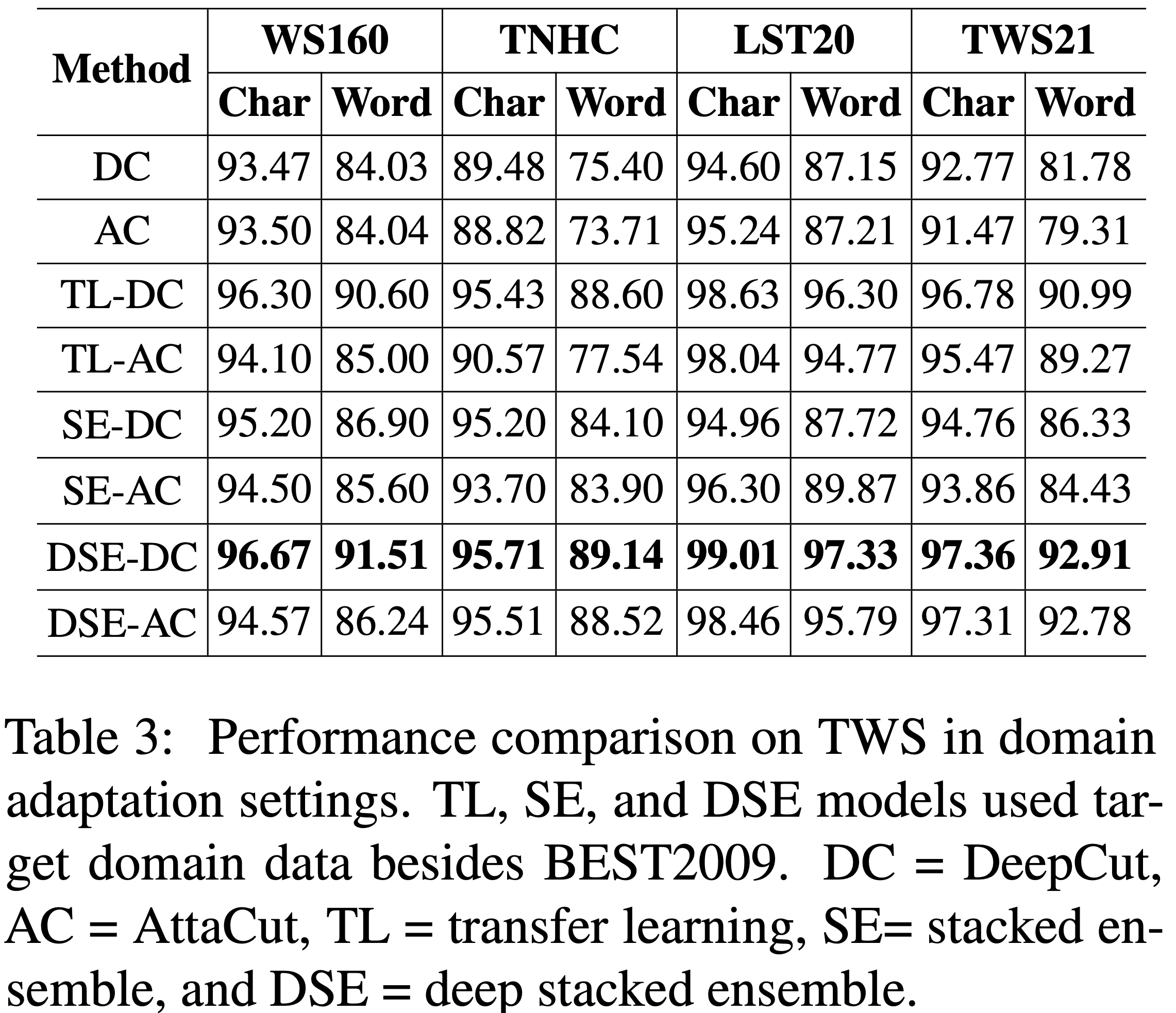
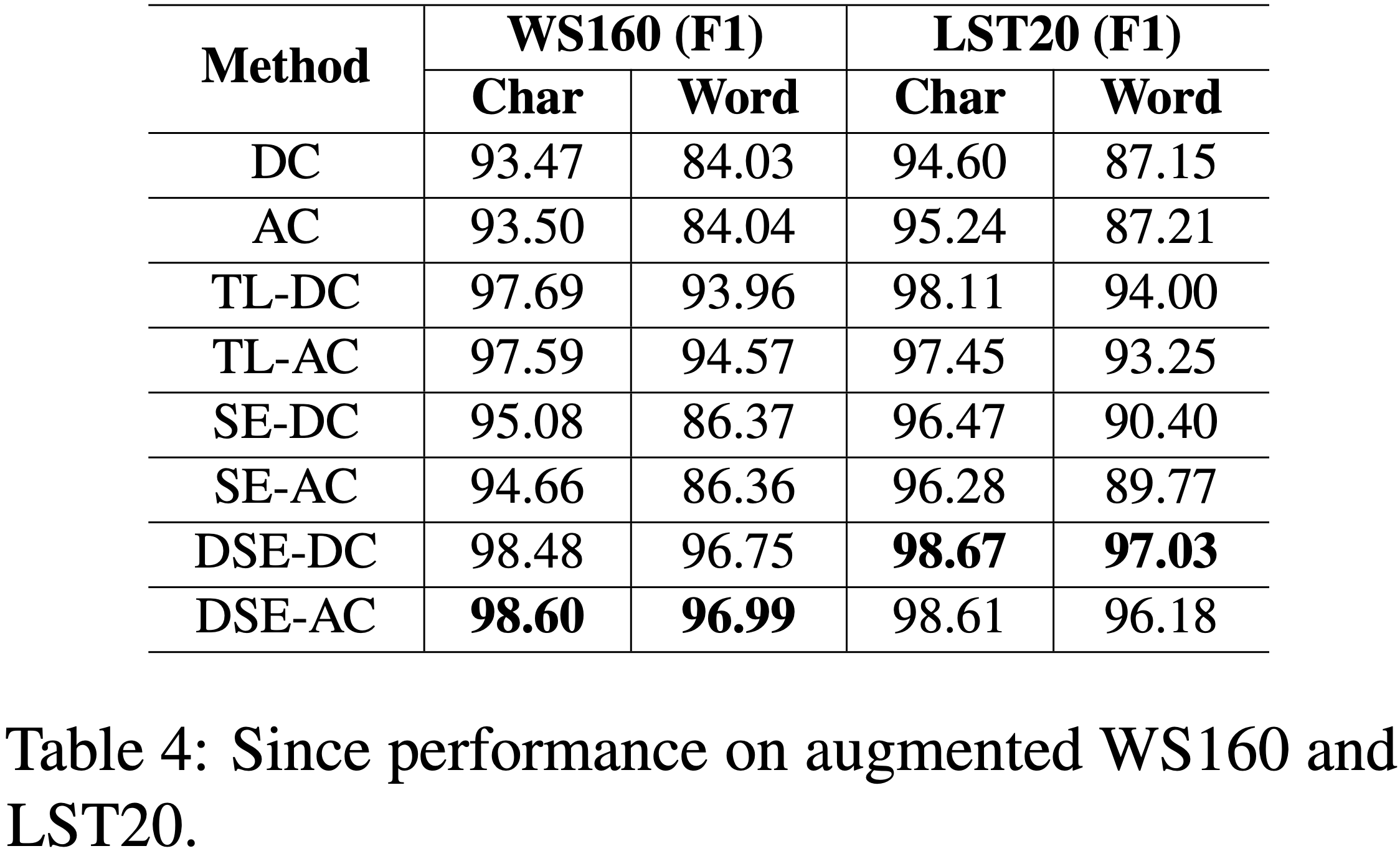
Model
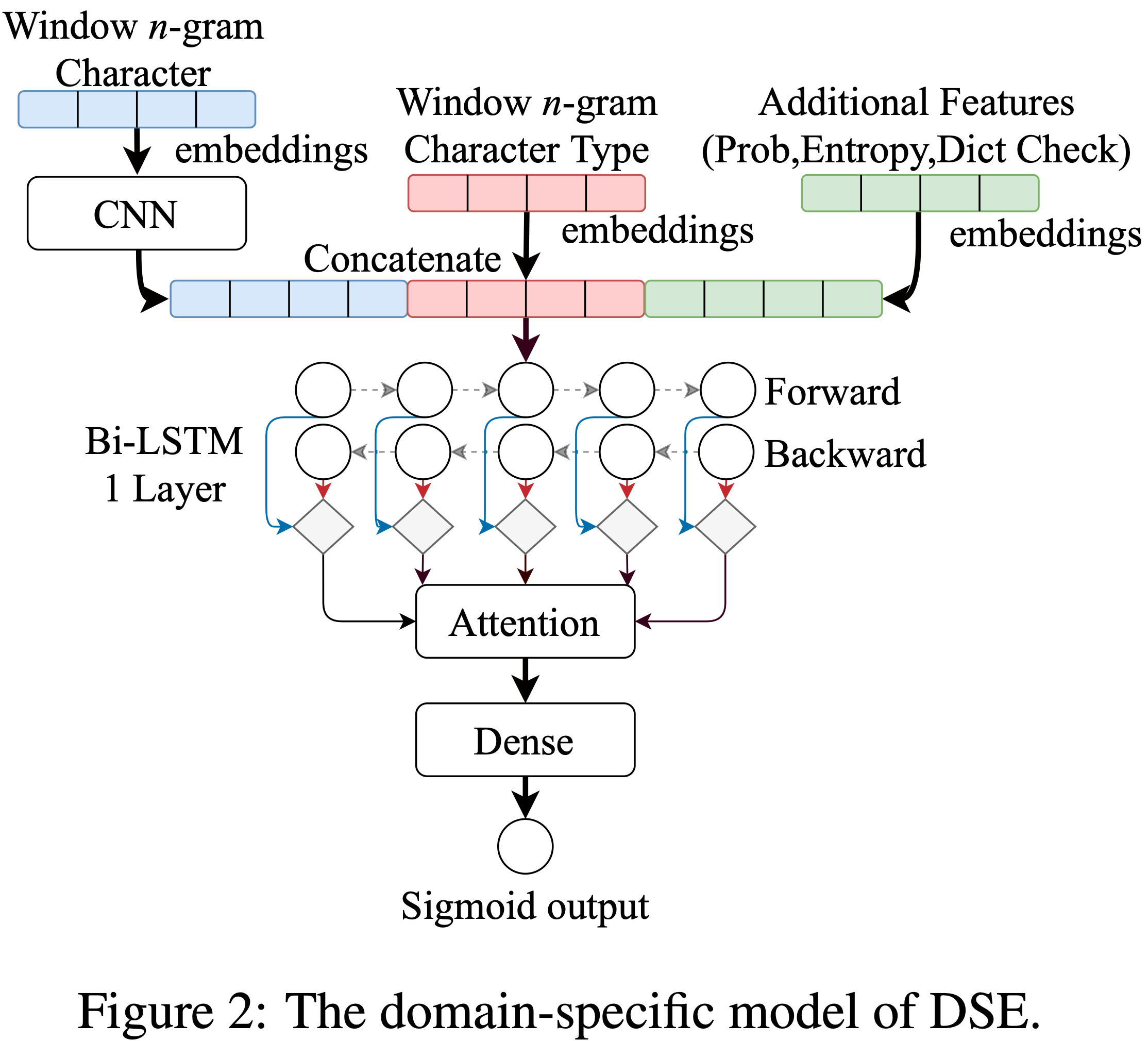
Without Data Augmentation
With Data Augmentation
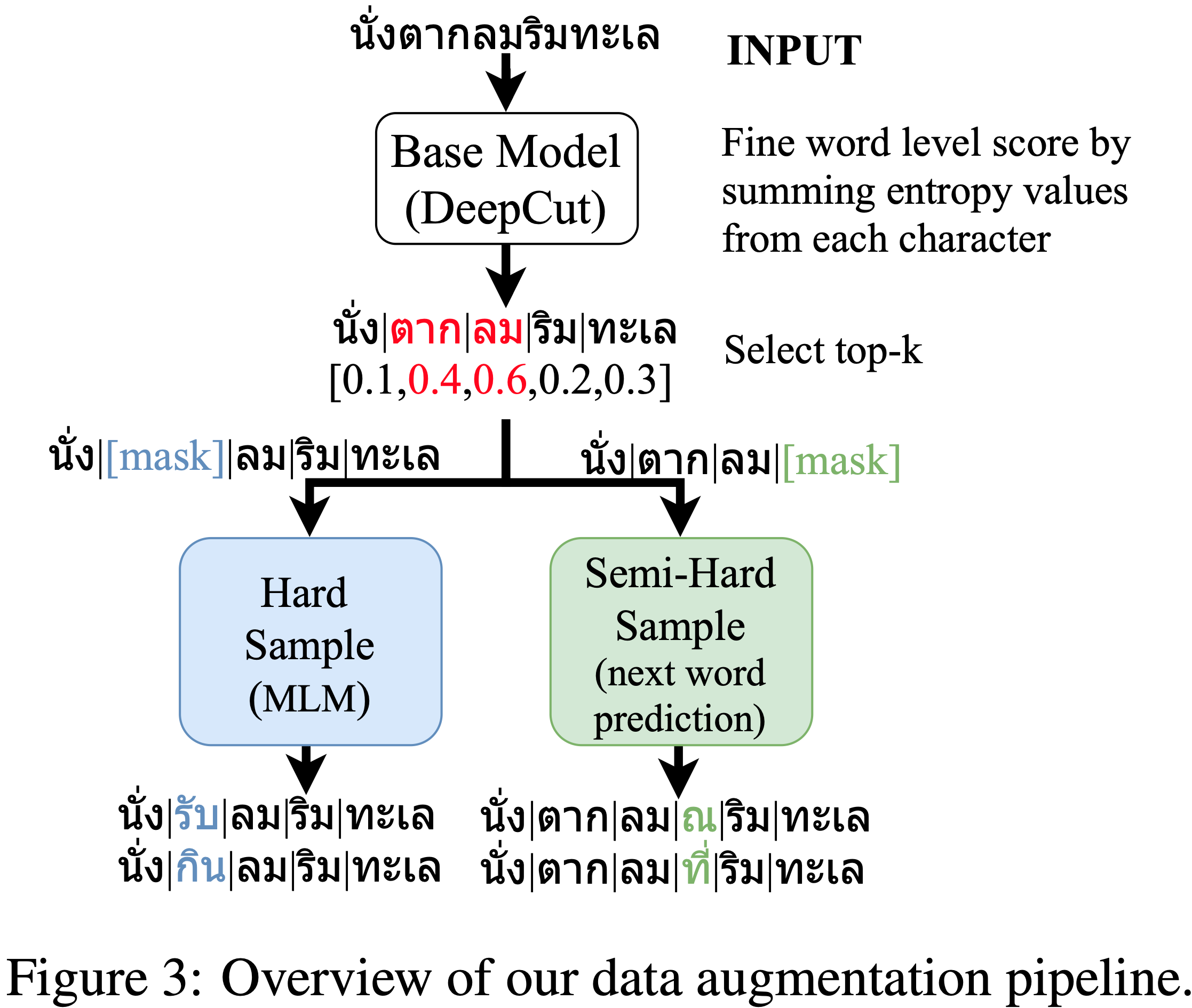
Thank you many code from
- Deepcut (Baseline Model) : We used some of code from Deepcut to perform transfer learning


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file OSKut-1.3.tar.gz.
File metadata
- Download URL: OSKut-1.3.tar.gz
- Upload date:
- Size: 17.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.6.1 pkginfo/1.5.0.1 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.49.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
28d56aeb8b663b56d46e3d7f5e527b3a4acd0a061866c8b258d41b39040e4fa5
|
|
| MD5 |
a5ee4157b885b4200b9daa7a8a0d79e2
|
|
| BLAKE2b-256 |
d5206c02a71936a1a12feb24aed025814c92bdd90c2947497fa7899e4100da88
|
File details
Details for the file OSKut-1.3-py3-none-any.whl.
File metadata
- Download URL: OSKut-1.3-py3-none-any.whl
- Upload date:
- Size: 44.2 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.6.1 pkginfo/1.5.0.1 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.49.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4d4fe9e8ece3ebc5b0cf4584064e15ee20360cb63f4903ccb9d3b02df3888966
|
|
| MD5 |
8012c3686035e76ea4b032c4d3c96050
|
|
| BLAKE2b-256 |
d6e9cf63a5d503145bf052fd3734d6735641c475ef627b9187fac7fc583cf85b
|







