Discrete mixture model based ploidy inference tool

Project description
PloidPy
Introduction
PloidPy is a program written in Python designed to infer ploidy from next-generation reads aligned to a haploid reference genome. The program makes use of a stastical model representing the distribution of specific nucleotide counts and selects the most probable ploidy on the basis of a minimum AIC.
Installation
Installation of PloidPy is relatively simple and can be done easily using pip. The most recent version can be installed using the following command:
pip install git+git://github.com/floutt/PloidPy
Dependencies
In order to run PloidPy, the following dependencies are required:
Python 3.6+NumPySciPyStatsmodelsmatplotlibseabornpysam
Getting Started
Once installed, PloidPy can be run on an indexed BAM file. For this tutorial we will download some BAM files created using simulated data from the ploidyNGS repository.
wget https://github.com/diriano/ploidyNGS/raw/master/test_data/simulatedDiploidGenome/Ploidy2.bowtie2.sorted.bam
wget https://github.com/diriano/ploidyNGS/raw/master/test_data/simulatedTriploidGenome/Ploidy3.bowtie2.sorted.bam
wget https://github.com/diriano/ploidyNGS/raw/master/test_data/simulatedTetraploidGenome/Ploidy4.bowtie2.sorted.bam
After downloading these files, we have to index all of these files using samtools.
samtools index Ploidy2.bowtie2.sorted.bam
samtools index Ploidy3.bowtie2.sorted.bam
samtools index Ploidy4.bowtie2.sorted.bam
From here we can extract the minor allele count (MAC) and total read coverage from each of the BAM files using PloidPy process_bam. In the following example the Phred-like mapping threshold is set to 15
PloidPy process_bam --bam Ploidy2.bowtie2.sorted.bam --out diploid.count --quality 15
PloidPy process_bam --bam Ploidy3.bowtie2.sorted.bam --out triploid.count --quality 15
PloidPy process_bam --bam Ploidy4.bowtie2.sorted.bam --out tetraploid.count --quality 15
In addition to providing raw data to be used, the output from this also calculates the mean base call error probability (p_err) from each file. This will be important for both filtering the data and ploidy evaluation of unfiltered data. In the examples above the diploid, triploid, and tetraploid individuals have p_err values of 0.0012170473202784014, 0.001184570850292672, and 0.0011672555287687418 respectively.
After this has been done, one of two steps can be taken. Either inferring ploidy using the unfiltered data with an error component incorporated into the model or filtering the data and running the model with no error component. One can filter out the data from each individual using the following commands:
PloidPy filter --count_file diploid.count --error_prob 0.0012170473202784014 --out diploid.count.filtered
PloidPy filter --count_file triploid.count --error_prob 0.001184570850292672 --out triploid.count.filtered
PloidPy filter --count_file tetraploid.count --error_prob 0.0011672555287687418 --out tetraploid.count.filtered
With this we can evaluate the ploidy of each individual, using the PloidPy assess subcommand. When using filtered data, one should exclude the "--error_prob" argument which tells the program not to incorporate the error model into the evaluation. In this example, ploidies of 2n to 8n will be evaluated, although this can be done with any set of ploidies greater than or equal to 2n. This can be done with the following commands:
PloidPy assess --count_file diploid.count.filtered --out diploid.filtered.tsv --ploidies 2 3 4 5 6 7 8
PloidPy assess --count_file triploid.count.filtered --out triploid.filtered.tsv --ploidies 2 3 4 5 6 7 8
PloidPy assess --count_file tetraploid.count.filtered --out tetraploid.filtered.tsv --ploidies 2 3 4 5 6 7 8
The evaluation on unfiltered can similarly be done with the following commands:
PloidPy assess --count_file diploid.count --out diploid.tsv --ploidies 2 3 4 5 6 7 8 --error_prob 0.0012170473202784014
PloidPy assess --count_file triploid.count --out triploid.tsv --ploidies 2 3 4 5 6 7 8 --error_prob 0.001184570850292672
PloidPy assess --count_file tetraploid.count --out tetraploid.tsv --ploidies 2 3 4 5 6 7 8 --error_prob 0.0011672555287687418
As you can see, in both cases all of the predictions were correct! Additional information can be found in the *tsv files. Each column represents the following:
| Column | Meaning |
|---|---|
| Ploidy | Ploidy model |
| Log_Likelihood | Log likelihood of ploidy model |
| AIC | AIC value of ploidy model |
| Het_Weights | Weight parameter of each heterozygous state component |
| Uniform Weight | Weight parameter of the uniform component of the model |
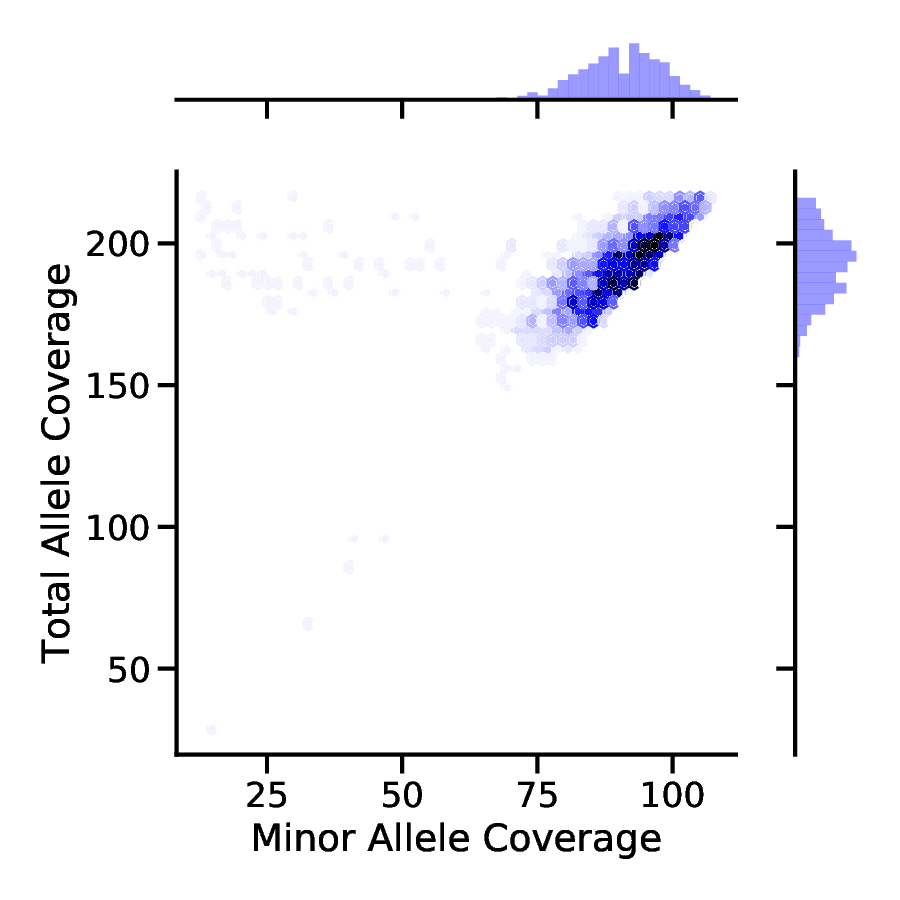
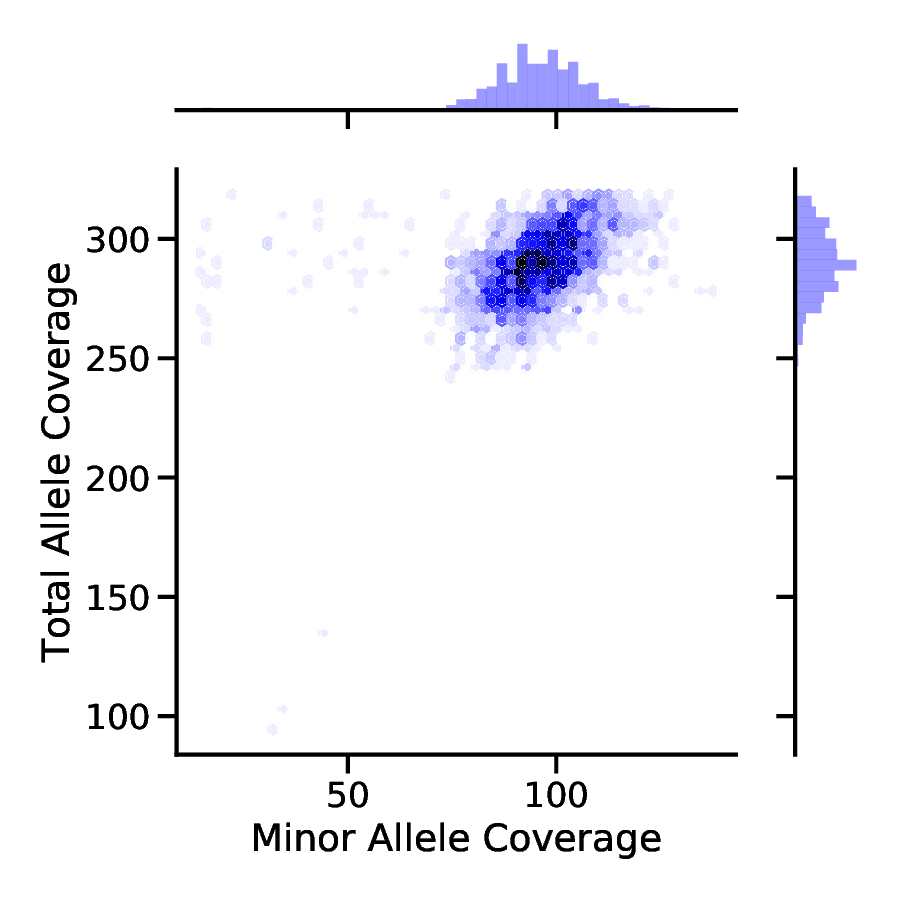
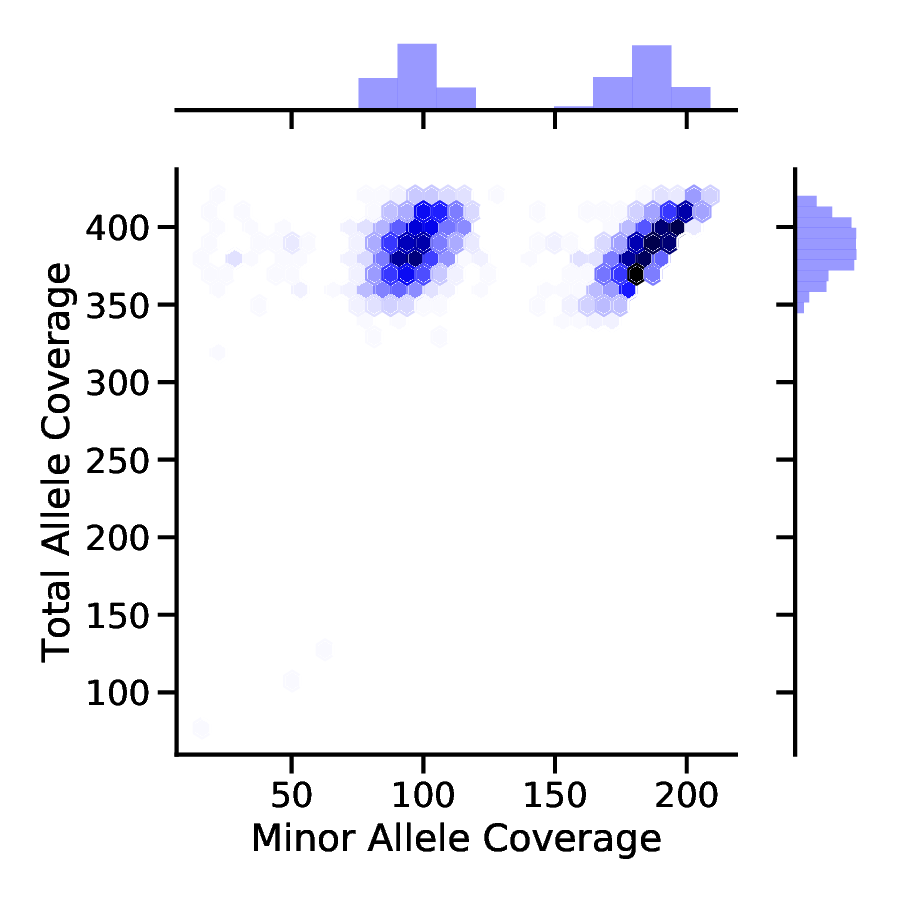
Additionally, the filtered data can be used to produce helpful figures to visualize the joint distribution of TRC and MAC values. This can be done with the following commands:
PloidPy histo --count_file diploid.count.filtered --out diploid
PloidPy histo --count_file triploid.count.filtered --out triploid
PloidPy histo --count_file tetraploid.count.filtered --out tetraploid
And here are the images!
Diploid
Triploid
Tetraploid
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file PloidPy-oaolayin-0.1.0.tar.gz.
File metadata
- Download URL: PloidPy-oaolayin-0.1.0.tar.gz
- Upload date:
- Size: 7.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/42.0.2 requests-toolbelt/0.9.1 tqdm/4.41.0 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c3a083dd92743d9c2a66defc66a3e72c8345f6cc37de551e214a5bfcdc067d42
|
|
| MD5 |
94182761666995bbf00dae2a7372035a
|
|
| BLAKE2b-256 |
0c9acf73e9ca97c7c54b210c2dafc1a634b095ab58f103c11518112bd2c6f0aa
|
File details
Details for the file PloidPy_oaolayin-0.1.0-py3-none-any.whl.
File metadata
- Download URL: PloidPy_oaolayin-0.1.0-py3-none-any.whl
- Upload date:
- Size: 10.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/42.0.2 requests-toolbelt/0.9.1 tqdm/4.41.0 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a6d90967a99e6d5e9a64bcfba7a9f799eca2a452a32c0216f76d635a9f815985
|
|
| MD5 |
1b249cc6017ee6a920cd715524c9be3e
|
|
| BLAKE2b-256 |
29a0d84a382813f8d7863a2b273d5c2361411bea1ce9b189e5cd83f6cbbfb099
|







