Domain Adaptation of Thai Word Segmentation Models using Stacked Ensemble (EMNLP2020)


Project description
SEFR CUT (Stacked Ensemble Filter and Refine for Word Segmentation)
Domain Adaptation of Thai Word Segmentation Models using Stacked Ensemble (EMNLP 2020)
CRF as Stacked Model and DeepCut as Baseline model
Read more:
- Paper: Domain Adaptation of Thai Word Segmentation Models using Stacked Ensemble
- Blog: Domain Adaptation กับตัวตัดคำ มันดีย์จริงๆ
Install
pip install sefr_cut
How To use
Requirements
- python >= 3.6
- python-crfsuite >= 0.9.7
- pyahocorasick == 1.4.0
Example
- Example files are on SEFR Example notebook
- Try it on Colab
Load Engine & Engine Mode
- ws1000, tnhc
- ws1000: Model trained on Wisesight-1000 and test on Wisesight-160
- tnhc: Model trained on TNHC (80:20 train&test split with random seed 42)
- BEST: Trained on BEST-2010 Corpus (NECTEC)
sefr_cut.load_model(engine='ws1000') # OR sefr_cut.load_model(engine='tnhc') # OR sefr_cut.load_model(engine='best') - tl-deepcut-XXXX
- We also provide transfer learning of deepcut on 'Wisesight' as tl-deepcut-ws1000 and 'TNHC' as tl-deepcut-tnhc
sefr_cut.load_model(engine='tl-deepcut-ws1000') # OR sefr_cut.load_model(engine='tl-deepcut-tnhc') - deepcut
- We also provide the original deepcut
sefr_cut.load_model(engine='deepcut')
Segment Example
- Segment with default k
sefr_cut.load_model(engine='ws1000') print(sefr_cut.tokenize(['สวัสดีประเทศไทย','ลุงตู่สู้ๆ'])) print(sefr_cut.tokenize(['สวัสดีประเทศไทย'])) print(sefr_cut.tokenize('สวัสดีประเทศไทย')) [['สวัสดี', 'ประเทศ', 'ไทย'], ['ลุง', 'ตู่', 'สู้', 'ๆ']] [['สวัสดี', 'ประเทศ', 'ไทย']] [['สวัสดี', 'ประเทศ', 'ไทย']] - Segment with different k
sefr_cut.load_model(engine='ws1000') print(sefr_cut.tokenize(['สวัสดีประเทศไทย','ลุงตู่สู้ๆ'],k=5)) # refine only 5% of character number print(sefr_cut.tokenize(['สวัสดีประเทศไทย','ลุงตู่สู้ๆ'],k=100)) # refine 100% of character number [['สวัสดี', 'ประเทศไทย'], ['ลุงตู่', 'สู้', 'ๆ']] [['สวัสดี', 'ประเทศ', 'ไทย'], ['ลุง', 'ตู่', 'สู้', 'ๆ']]
Evaluation
- Character & Word Evaluation is provided by call fuction
evaluation()- For example
answer = 'สวัสดี|ประเทศไทย' pred = 'สวัสดี|ประเทศ|ไทย' char_score,word_score = sefr_cut.evaluation(answer,pred) print(f'Word Score: {word_score} Char Score: {char_score}') Word Score: 0.4 Char Score: 0.8 answer = ['สวัสดี|ประเทศไทย'] pred = ['สวัสดี|ประเทศ|ไทย'] char_score,word_score = sefr_cut.evaluation(answer,pred) print(f'Word Score: {word_score} Char Score: {char_score}') Word Score: 0.4 Char Score: 0.8 answer = [['สวัสดี|'],['ประเทศไทย']] pred = [['สวัสดี|'],['ประเทศ|ไทย']] char_score,word_score = sefr_cut.evaluation(answer,pred) print(f'Word Score: {word_score} Char Score: {char_score}') Word Score: 0.4 Char Score: 0.8
Performance
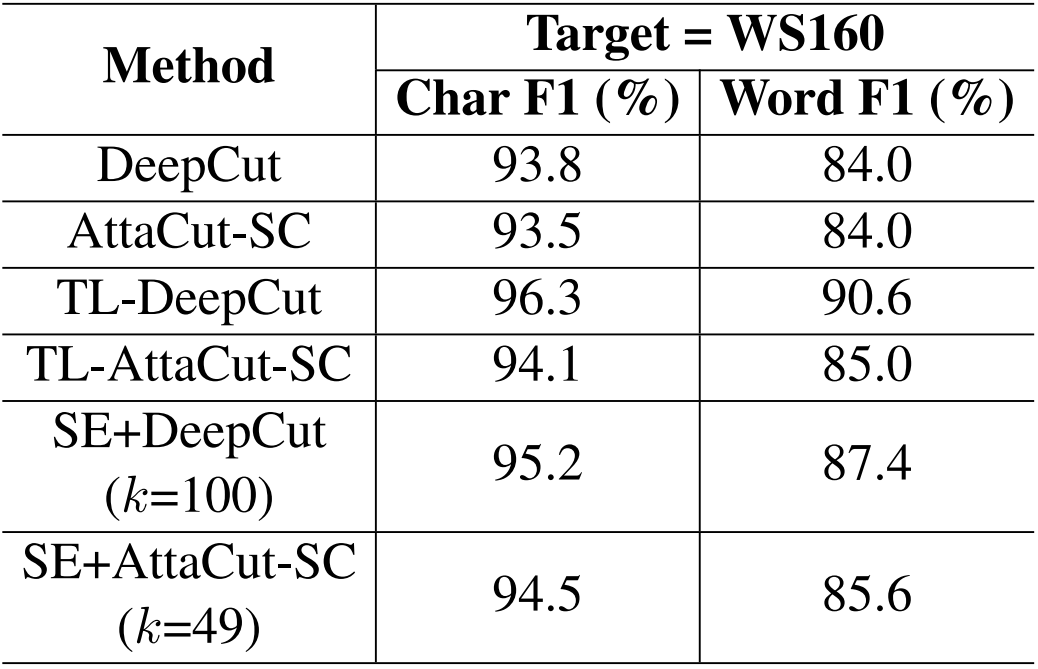
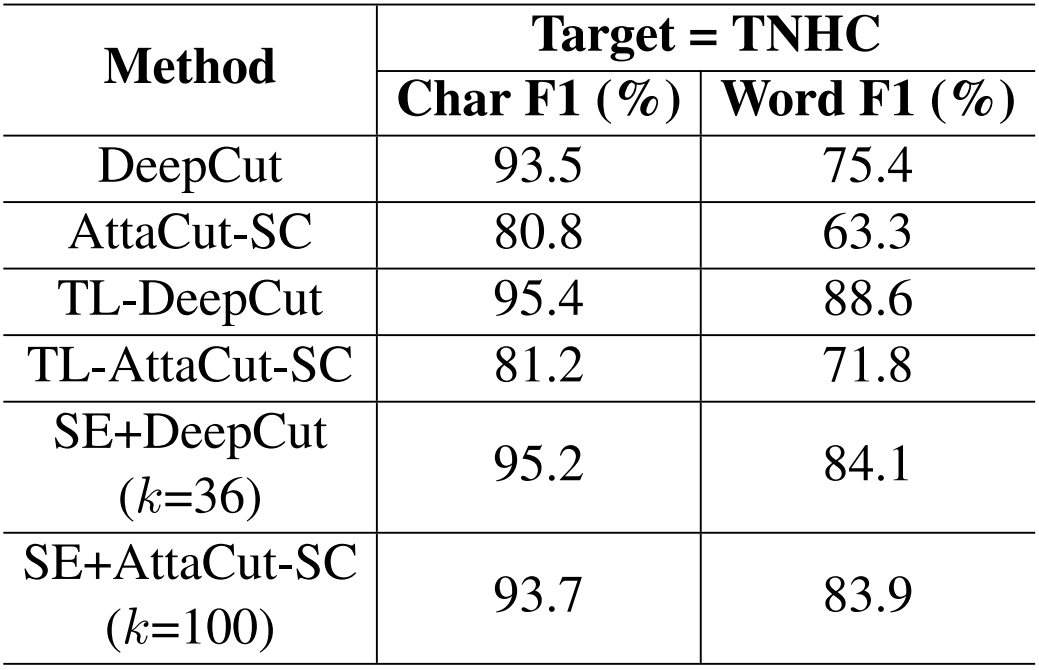
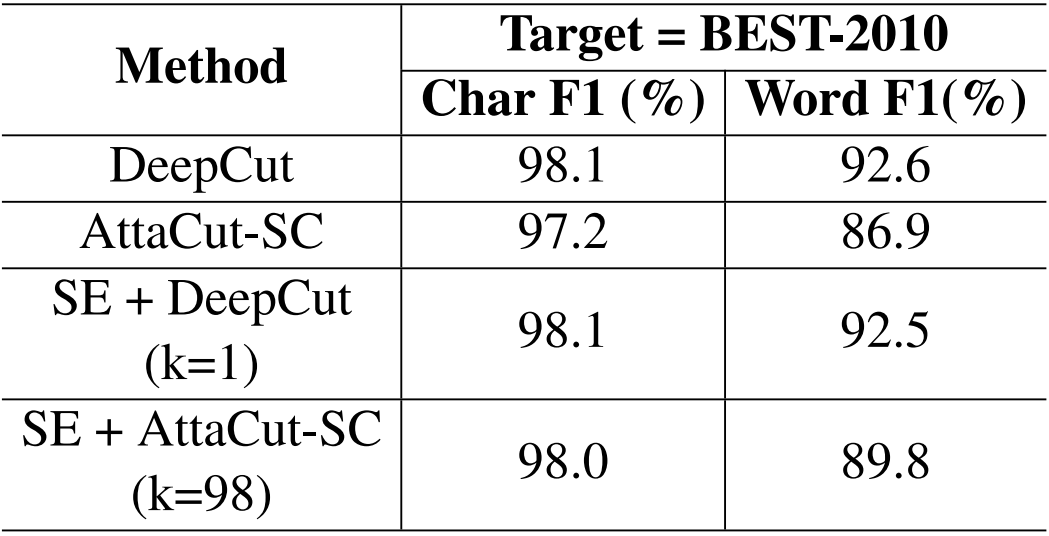
How to re-train?
- You can re-train model in folder Notebooks We provided everything for you!!
Re-train Model
- You can run the notebook file #2, the corpus inside 'Notebooks/corpus/' is Wisesight-1000, you can try with BEST, TNHC, and LST20 !
- Rename variable name
CRF_model_name - Link:HERE
Filter and Refine Example
- Set variable name
CRF_model_namesame as File#2 - If you want to know why we use filter-and-refine you can try to uncomment 3 lines in
score_()function
#answer = scoring_function(y_true,cp.deepcopy(y_pred),entropy_index_og) #f1_hypothesis.append(eval_function(y_true,answer)) #ax.plot(range(start,K_num,step),f1_hypothesis,c="r",marker='o',label='Best case')- Link:HERE
Use your own model?
- Just move your model inside 'Notebooks/model/' to 'seft_cut/model/' and call model in one line.
SEFR_CUT.load_model(engine='my_model')
Citation
- Wait our paper shown in ACL Anthology
Thank you many code from
- Deepcut (Baseline Model) : We used some of code from Deepcut to perform transfer learning
- @bact (CRF training code) : We used some from https://github.com/bact/nlp-thai in training CRF Model
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
No source distribution files available for this release.See tutorial on generating distribution archives.
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file SEFR_CUT-1.1-py3-none-any.whl.
File metadata
- Download URL: SEFR_CUT-1.1-py3-none-any.whl
- Upload date:
- Size: 8.7 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/47.1.0 requests-toolbelt/0.9.1 tqdm/4.50.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e811482d5607ab008d71f06c38b1e2a5fe1bceba8b6cf6ea8d7cf6be74864c86
|
|
| MD5 |
ee6649e5970c1d3c08c07ed607511b3d
|
|
| BLAKE2b-256 |
7b349d8e8e917baebabe350f387b84d1658ac16af19b284bda347373739a3726
|







