AgileRL is a deep reinforcement learning library focused on improving RL development through RLOps.




Project description

Reinforcement learning streamlined.
Easier and faster reinforcement learning with RLOps. Visit our website. View documentation.
Join the Discord Server for questions, help and collaboration.









🚀 Train super-fast for free on Arena, the RLOps platform from AgileRL 🚀
AgileRL is a Deep Reinforcement Learning library focused on improving development by introducing RLOps - MLOps for reinforcement learning.
This library is initially focused on reducing the time taken for training models and hyperparameter optimization (HPO) by pioneering evolutionary HPO techniques for reinforcement learning.
Evolutionary HPO has been shown to drastically reduce overall training times by automatically converging on optimal hyperparameters, without requiring numerous training runs.
We are constantly adding more algorithms and features. AgileRL already includes state-of-the-art evolvable LLM fine-tuning, on-policy, off-policy, offline, multi-agent and contextual multi-armed bandit reinforcement learning algorithms with distributed training.
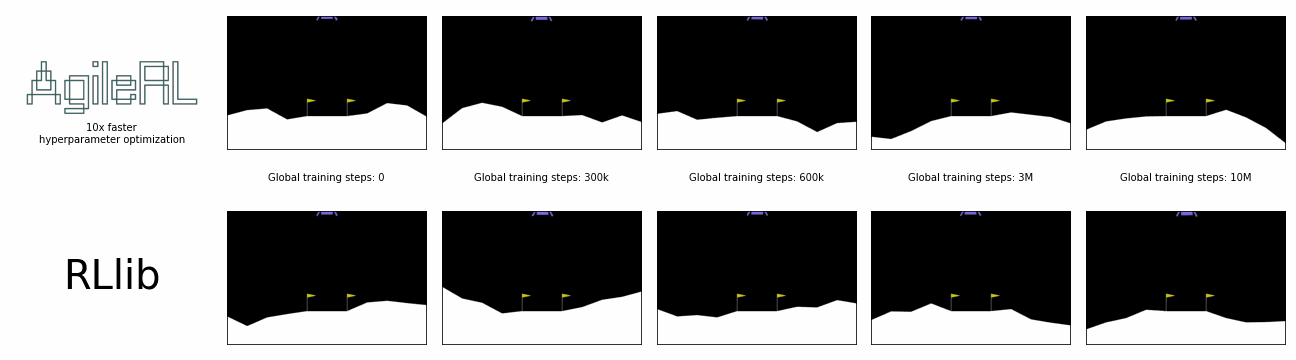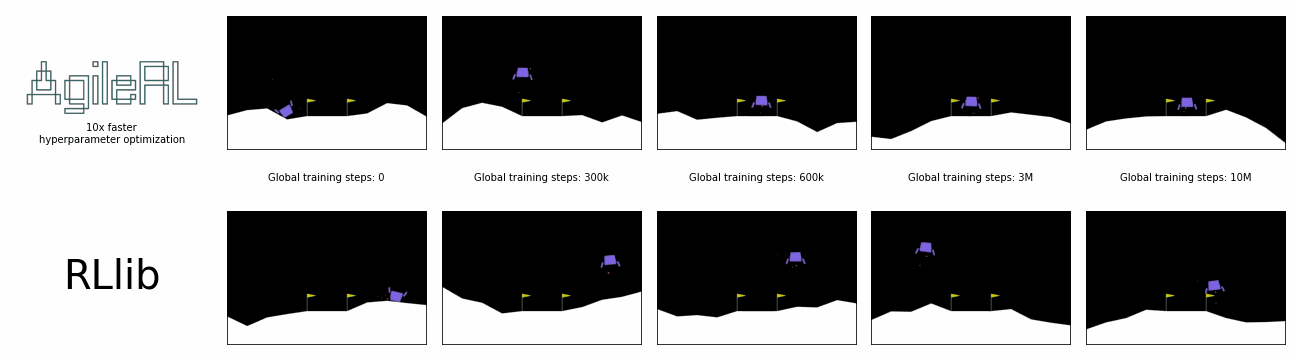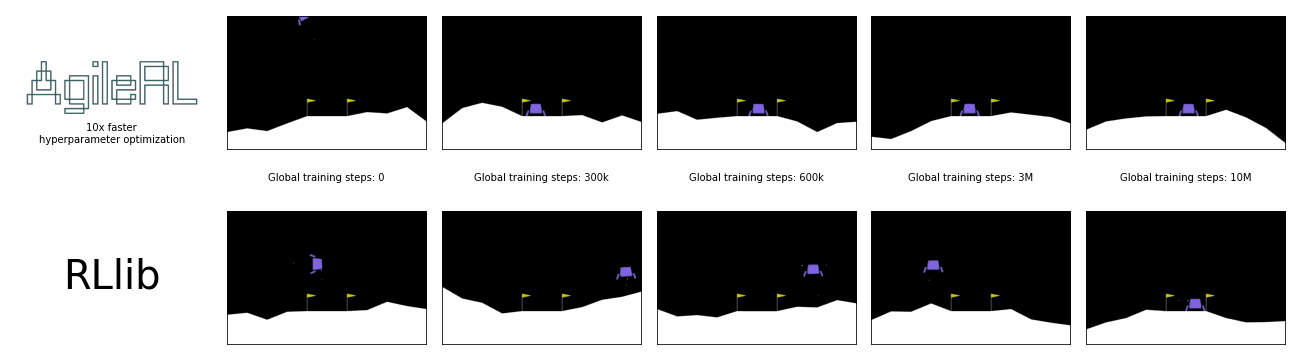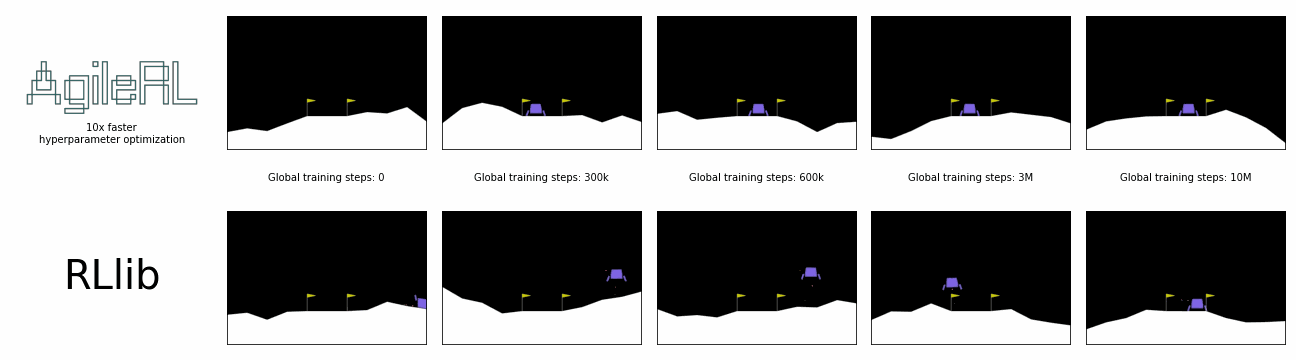
AgileRL offers 10x faster hyperparameter optimization than SOTA.
Table of Contents
Benchmarks
LLM Fine-tuning
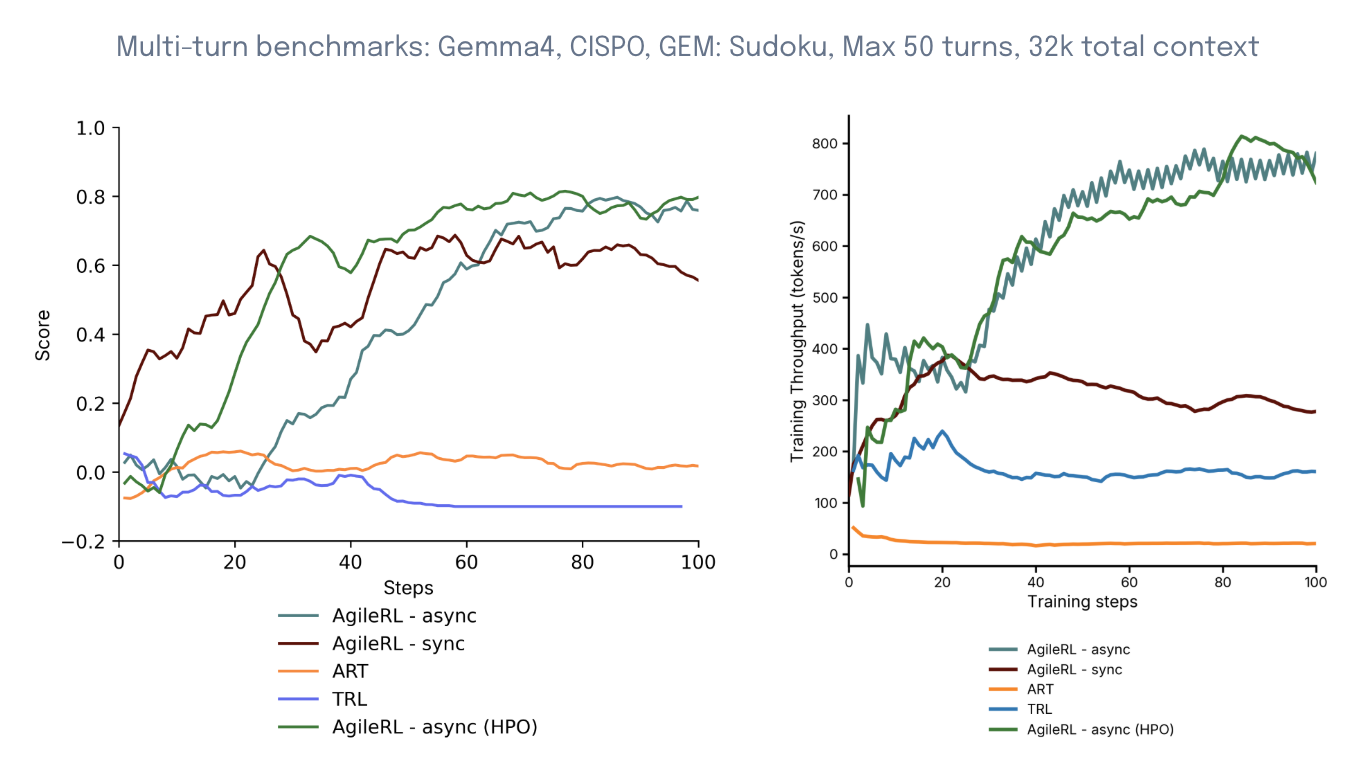
AgileRL's multi-turn LLM training enables state-of-the-art performance on long-horizon tasks with small models. In the following example, AgileRL's CISPO was benchmarked against ART and TRL on the GEM Sudoku Hard task. This is a difficult multi-turn problem, which requires a context length of 32k tokens and up to 50 turns per rollout. The sync AgileRL run is a single agent using the AgileRL framework. The async and HPO runs were performed on Arena, AgileRL's RLOps platform. All runs used the same starting hyperparameters. AgileRL runs were run on A100 40GB nodes, whereas ART and TRL required A100 80GB nodes due to a lack of optimizations. AgileRL runs significantly outperformed those using the ART and TRL frameworks.
Classic RL
Reinforcement learning algorithms and libraries are usually benchmarked once the optimal hyperparameters for training are known, but it often takes hundreds or thousands of experiments to discover these. This is unrealistic and does not reflect the true, total time taken for training. What if we could remove the need to conduct all these prior experiments?
In the charts below, a single AgileRL run, which automatically tunes hyperparameters, is benchmarked against Optuna's multiple training runs traditionally required for hyperparameter optimization, demonstrating the real time savings possible. Global steps is the sum of every step taken by any agent in the environment, including across an entire population.
AgileRL offers an order of magnitude speed up in hyperparameter optimization vs popular reinforcement learning training frameworks combined with Optuna. Remove the need for multiple training runs and save yourself hours.
AgileRL also supports multi-agent reinforcement learning using the Petting Zoo-style (parallel API). The charts below highlight the performance of our MADDPG and MATD3 algorithms with evolutionary hyper-parameter optimisation (HPO), benchmarked against epymarl's MADDPG algorithm with grid-search HPO for the simple speaker listener and simple spread environments.
Get Started
To see the full AgileRL documentation, including tutorials, visit our documentation site. To ask questions and get help, collaborate, or discuss anything related to reinforcement learning, join the AgileRL Discord Server.
Install as a package with pip:
pip install agilerl
Or install in development mode:
git clone https://github.com/AgileRL/AgileRL.git && cd AgileRL
pip install -e .
AgileRL ships optional dependency groups that you can install as needed:
| Installation | Description |
|---|---|
agilerl[box2d] |
Box2D physics engine for Gymnasium environments |
agilerl[arena] |
Arena SDK & CLI. Validate custom environments, and train & deploy agents on managed cloud infrastructure. |
agilerl[llm] |
LLM reinforcement fine-tuning. |
agilerl[all] |
Cover all functionalities of AgileRL. |
In development mode, quote the extras:
pip install -e ".[arena]"
To install the nightly version of AgileRL with the latest features, use:
pip install git+https://github.com/AgileRL/AgileRL.git@nightly
Training Locally
AgileRL provides the tools to train RL algorithms in a variety of ways, focusing on flexibility and modularity as a stepping stone for efficiently training arbitrarily large populations of agents in a distributed manner on Arena.
Training a Single Agent without Evolutionary HPO
The simplest way to train an RL agent with AgileRL is through the
LocalTrainer. Here is an example of training a DQN agent on the LunarLander-v3 environment:
from agilerl import LocalTrainer
trainer = LocalTrainer(algorithm="DQN", environment="LunarLander-v3")
population, fitnesses = trainer.train()
With no other arguments provided,
LocalTrainerdefaults to 1,000,000 steps with a single agent and the algorithm's default hyperparameters — no evolutionary HPO is applied.
Training a Population with Evolutionary HPO
To unlock AgileRL's evolutionary hyperparameter optimization, train a population of agents whose hyperparameters will evolve and mutate towards their optimal values:
from agilerl import LocalTrainer
from agilerl.models import TrainingSpec
trainer = LocalTrainer(
algorithm="DQN",
environment="LunarLander-v3",
training=TrainingSpec(pop_size=4), # Train four agents simultaneously
hpo=True, # Enable evolutionary HPO using default settings
)
population, fitnesses = trainer.train()
This trains a population of four DQN agents that share experiences but learn individually. Every 10,000 steps
(default value for evo_steps in TrainingSpec), tournament selection identifies the best
performers and mutations are applied to explore the hyperparameter space. See Evolutionary Hyperparameter Optimization for details on how evolutionary HPO works in AgileRL.
Or via a YAML manifest:
DQN-LunarLander-v3 manifest (configs/training/dqn/dqn.yaml)
---
algorithm:
name: DQN
batch_size: 128
lr: 6.3e-4
learn_step: 4
gamma: 0.99
tau: 0.001
double: false
cudagraphs: false
environment:
name: LunarLander-v3
num_envs: 16
mutation:
probabilities:
no_mut: 0.4
arch_mut: 0.2
new_layer: 0.2
params_mut: 0.2
act_mut: 0.2
rl_hp_mut: 0.2
rl_hp_selection:
lr:
min: 0.0000625
max: 0.01
batch_size:
min: 8
max: 512
learn_step:
min: 1
max: 10
mutation_sd: 0.1
rand_seed: 42
network:
latent_dim: 128
arch: mlp
encoder_config:
hidden_size:
- 128
head_config:
hidden_size:
- 128
replay_buffer:
max_size: 100_000
tournament_selection:
tournament_size: 2
elitism: true
training:
max_steps: 1_000_000
target_score: 200.0
pop_size: 4
evo_steps: 10_000
eval_steps:
eval_loop: 1
learning_delay: 0
eps_start: 1.0
eps_end: 0.1
eps_decay: 0.99
Python
from agilerl import LocalTrainer
trainer = LocalTrainer.from_manifest("configs/training/dqn/dqn.yaml")
population, fitnesses = trainer.train()
CLI
python -m agilerl.train configs/training/dqn/dqn.yaml
Every aspect of the training pipeline is customisable — from modifying hyperparameters and mutation strategies in our off-the-shelf tools, to implementing your own evolvable algorithms, network architectures, and training loops.
Custom Training Pipelines
For full control over training, you can build each component individually:
Custom RL pipeline example
import torch
from agilerl.algorithms import DQN
from agilerl.utils.utils import make_vect_envs
from agilerl.components.replay_buffer import ReplayBuffer
from agilerl.hpo.tournament import TournamentSelection
from agilerl.hpo.mutation import Mutations
from agilerl.training.train_off_policy import train_off_policy
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Initialize environment
env = make_vect_envs(env_name="LunarLander-v3", num_envs=16)
# Network configuration
net_config = {
"latent_dim": 64,
"encoder_config": {"hidden_size": [64]},
"head_config": {"hidden_size": [64]}
}
# Algorithm hyperparameters
init_hp = {
"double": True,
"batch_size": 256,
"lr": 1e-3,
"gamma": 0.99,
"learn_step": 1,
"tau": 1e-3
}
# Create a population of DQN agents
population_size=6
agent_pop = DQN.population(
size=population_size,
observation_space=env.single_observation_space,
action_space=env.single_action_space,
net_config=net_config,
device=device,
**init_hp
)
# Replay buffer
memory = ReplayBuffer(max_size=10_000, device=device)
# Evolutionary HPO
tournament = TournamentSelection(
tournament_size=2,
elitism=True,
population_size=population_size
)
mutations = Mutations(
no_mutation=0.4,
architecture=0.2,
new_layer_prob=0.2,
parameters=0.2,
activation=0.0,
rl_hp=0.2,
mutation_sd=0.1,
rand_seed=42,
device=device,
)
trained_pop, pop_fitnesses = train_off_policy(
env=env,
env_name="LunarLander-v3",
algo="DQN",
pop=agent_pop,
memory=memory,
max_steps=1_000_000,
evo_steps=10_000,
target=200.0,
tournament=tournament,
mutation=mutations,
)
This approach gives you the flexibility to swap in your own Gymnasium or PettingZoo environments, custom evolvable networks, or entirely custom training loops while still leveraging AgileRL's evolutionary HPO.
Training on Arena
Arena is the RLOps platform from AgileRL. We provide tools to create and validate custom reinforcement learning environments on the platform and train RL agents on managed cloud infrastructure specifically tailored to RL workloads.
AgileRL ships a Python SDK and a CLI for interacting with the platform through the agilerl-arena package. It is a separate PyPI distribution that contributes the agilerl.arena namespace. Install it directly, or via the AgileRL extra:
pip install agilerl-arena
# or
pip install "agilerl[arena]"
Python
Use the ArenaClient to interact with Arena programmatically from scripts or notebooks:
from agilerl.arena import ArenaClient
client = ArenaClient()
client.login() # OAuth2 device-flow authentication
# Upload and validate a custom environment
client.validate_environment(name="my-custom-env", source="path/to/my_env.py")
# Train on validated custom environment
client.submit_experiment(
manifest="path/to/manifest.yaml",
project="my-project",
)
Arena CLI
The same operations are available from the command line:
# Authenticate with Arena
arena login
# Upload and validate
arena env validate my-custom-env --source path/to/my_env.py
# Train on validated custom environment
arena experiments submit path/to/manifest.yaml --project my-project
For the full CLI and Python SDK reference, including authentication, environment validation, experiments, and deployment, see the Arena Client documentation.
Tutorials
We are constantly updating our tutorials to showcase the latest features of AgileRL and how users can leverage our evolutionary HPO to achieve 10x faster hyperparameter optimization. Please see the available tutorials below.
| Tutorial Type | Description | Tutorials |
|---|---|---|
| Single-agent tasks | Guides for training both on and off-policy agents to beat a variety of Gymnasium environments. | PPO - Acrobot TD3 - Lunar Lander Rainbow DQN - CartPole Recurrent PPO - Masked Pendulum |
| Multi-agent tasks | Use of PettingZoo environments such as training DQN to play Connect Four with curriculum learning and self-play, and for multi-agent tasks in MPE environments. | DQN - Connect Four MADDPG - Space Invaders MATD3 - Speaker Listener |
| Hierarchical curriculum learning | Shows how to teach agents Skills and combine them to achieve an end goal. | PPO - Lunar Lander |
| Contextual multi-arm bandits | Learn to make the correct decision in environments that only have one timestep. | NeuralUCB - Iris Dataset NeuralTS - PenDigits |
| Custom Modules & Networks | Learn how to create custom evolvable modules and networks for RL algorithms. | Dueling Distributional Q Network EvolvableSimBa |
| Training on Arena | Upload and validate custom environments, submit training jobs on managed cloud infrastructure, and deploy trained agents for inference. | PPO - Acrobot Custom Environment |
| LLM Finetuning | Learn how to finetune an LLM using AgileRL. | GRPO |
Evolvable Algorithms (more coming soon!)
Single-agent
Multi-agent
| RL | Algorithm |
|---|---|
| Multi-agent | Multi-Agent Deep Deterministic Policy Gradient (MADDPG) Multi-Agent Twin-Delayed Deep Deterministic Policy Gradient (MATD3) Independent Proximal Policy Optimization (IPPO) |
Contextual multi-armed bandit
| RL | Algorithm |
|---|---|
| Bandits | Neural Contextual Bandits with UCB-based Exploration (NeuralUCB) Neural Contextual Bandits with Thompson Sampling (NeuralTS) |
LLM Fine-tuning
Citing AgileRL
If you use AgileRL in your work, please cite the repository:
@software{Ustaran-Anderegg_AgileRL,
author = {Ustaran-Anderegg, Nicholas and Pratt, Michael and Sabal-Bermudez, Jaime},
license = {Apache-2.0},
title = {{AgileRL}},
url = {https://github.com/AgileRL/AgileRL}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file agilerl-2.8.4.tar.gz.
File metadata
- Download URL: agilerl-2.8.4.tar.gz
- Upload date:
- Size: 560.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.25 {"installer":{"name":"uv","version":"0.9.25","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0acc7166ad0631e62cd71d91a0d836b7324b2a650a06ba42b64d1f60f024365d
|
|
| MD5 |
e39ca65f27476cad7048d50809cb3114
|
|
| BLAKE2b-256 |
c287d7800ad56da61004945bf3735824dba3c2d4d3b4a3572ee0ded714e41a5b
|
File details
Details for the file agilerl-2.8.4-py3-none-any.whl.
File metadata
- Download URL: agilerl-2.8.4-py3-none-any.whl
- Upload date:
- Size: 669.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.25 {"installer":{"name":"uv","version":"0.9.25","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
167c7d39a6662a3646d60fb4e109708a9a45ee4f6188c3abe58288ef4d5bb174
|
|
| MD5 |
01ca380bf251248aa308be2bbe9d57d9
|
|
| BLAKE2b-256 |
8304558edde391f6b7ae966d64e96fa7df6d8c045a225127910993703db1e3dc
|







