A library for optimally generating data with batch active learning in design contexts

Project description
Batch Active Learning for Design Dataset Generation
ALFD generates parametric design data optimally using Batch Active Learning.
Description
ALFD is a package for generating targeted design datasets. It can handle unique constraints for both performance values and design parameter values. It is also compatible with any pair of 2+ dimensional parameter and performance spaces.
Quick Start
- Install ALFD with
pip install AL_for_design - Run:
import numpy as np
from AL_for_design.quantized_learner import TargetPerformanceHyperparam, ContinuousDesignBound, CategoricalDesignBound, HyperparamDataSetup, QuantizedActiveLearner
def random_regression_problem(X):
ret = []
for row in X:
perf1, perf2, perf3, perf4 = row
ret.append([perf1*perf2, perf3**np.abs(np.sin(perf1))-perf4, np.cos(perf1+perf2+perf3+perf4)])
return np.array(ret)
learner = QuantizedActiveLearner(HyperparamDataSetup(
[
ContinuousDesignBound(3,9,"FirstExampleParameter"),
ContinuousDesignBound(5,10,"SecondExampleParameter"),
CategoricalDesignBound(["ExampleCategoryA", "ExampleCategoryB", "ExampleCategoryC"], "ThirdExampleParameter"),
ContinuousDesignBound(1,5,"FourthExampleParameter"),
],
[
TargetPerformanceHyperparam(lambda x: np.ones(x.shape[0]),"FirstExamplePerformanceVal"),
TargetPerformanceHyperparam(lambda x: np.ones(x.shape[0]),"SecondExamplePerformanceVal"),
TargetPerformanceHyperparam(lambda x: np.ones(x.shape[0]),"ThirdExamplePerformanceVal")
]),
DESIGN_SPACE_DENSITY=100000,
UNCERTAINTY_DROP_THRESHOLD=0.01,
skip_redundancy = True
)
num_batches = 5
batch_size = 100
for i in range(num_batches):
queried = learner.query(batch_size)
deleted = learner.teach(queried, np.ones(batch_size), random_regression_problem(queried))
How it Works
Query Strategy
The following steps outline the querying process in the best performing Active Learner ("Quantized Active Learner")
- For all points in the pool, we calculate the harmonic mean of the uncertainties for all the performance regressors and the distance matrix to labeled points.
- Using the testing data, we set the proximity weight accordingly. If the regressors have a high average error, we set the proximity weight high to maximize exploration, whereas if there is a low average error, we set the proximity weight low to maximize exploitation.
- We use the following experimentally derived formula to "score" each point based on the predicted error in step 1: $\text{scores}=(\text{proximity_weight}+(1-\text{proximity_weight})\cdot\text{error})^\text{proximity_weight}$
- We normalize the scores to a probability distribution.
- We select a point at random from the pool, weighted by the probability distribution.
- We create an predicted error interval with an unfixed width of $0.2$. This interval is centered at the predicted error of the point selected point.
- We calculate the distance matrix, and choose the point farthest from a labeled point that has an predicted error score within the range.
- We add the chosen point to the batch, remove the point from the pool, and recompute the distance matrix, treating the chosen point as a labeled one.
- Repeat steps 4-7 until the batch is full.
- Return the batch
Teaching Strategy
The following steps outline the teaching process for the Active Learner. This involves deleting points from the pool that are confidently invalid.
- We uniformly select 20% of the training data for error estimation and testing. This will be used in the estimation of errors.
- We retrain the invalidity classifiers and performance regressors with the training data (not including the testing data).
- We use the following experimentally derived formula to get a value for the probability of a point being invalid: $\displaystyle\prod_{i=1}^{n}P_i^{C_i}$ where $n$ is the number of performance values, $P_i$ is the predicted validity probability for the ith performance value validity classifier, and $C_i$ is the calculated confidence value as a function of the distance to the nearest labeled point. Note that points with a lower confidence are biased towards 1. This lowers the chance of points being falsely dropped from the pool.
- We drop points that have an invalidity score lower than a certain threshold.
- To detect redundant performance values, we train a regressor to predict a certain performance value from all the others. If the accuracy of the regressor is better than a certain threshold, we mark the performance value as redundant. We repeat for all other performance values.
Error Estimation Strategy
To estimate the error of the performance value regressor, we calculate the residuals of the predictions in the testing data. The testing data selection process is described here.
We then normalize the residuals, and train a KNN to predict the error for any point in the design space.
Distance Matrix Computation
To compute the distance between two points, we first need to encode each categorical component as a one-hot vector. This ensures that euclidean distance computations do not depend on category order. However, the the distances between 2 one-hot vectors needs to be normalized, which can be done by dividing by $\sqrt{2}$. Lastly, the distances need to be normalized. This can be done by first normalizing each parameter value and converting the design space into a unit hypercube. Then, we can divide each design vector component by $\sqrt{n}$, where n is the number of performance values. Finally, we get a modified design space, where the maximum distance between 2 points (i.e. the diagonal of the multidimensional design space) is 1, and each parameter is weighted equally when computing the euclidean distance.
Using the above distance computation strategy, we can form a normalized distance matrix for every point in the pool to a labeled point.
Examples of ALFD
Example of 3 ALFD Queries Using Random Regression Problems
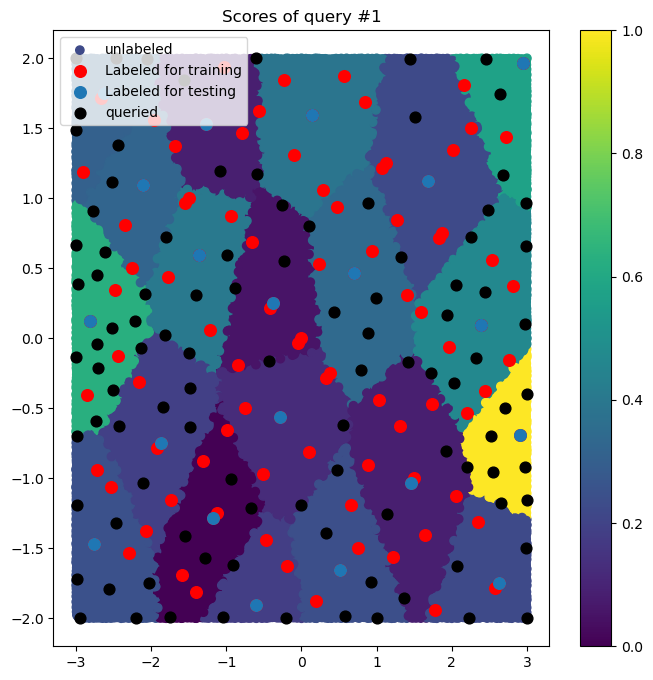
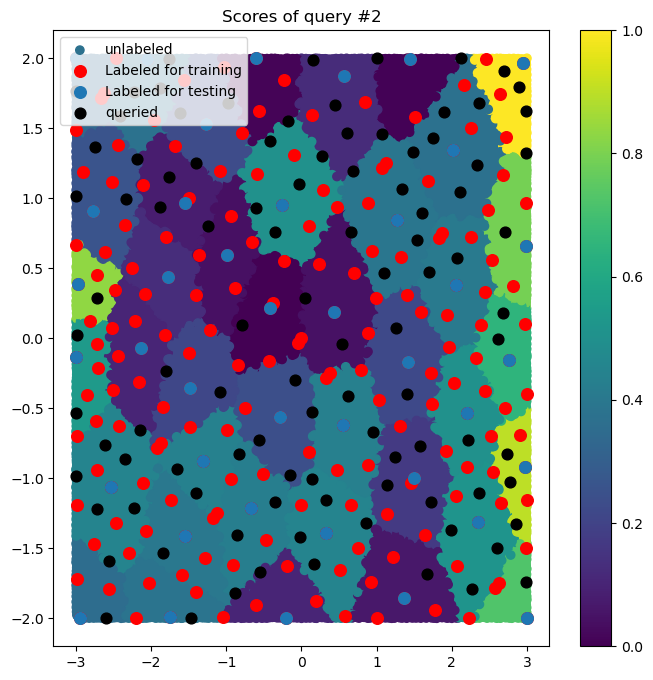
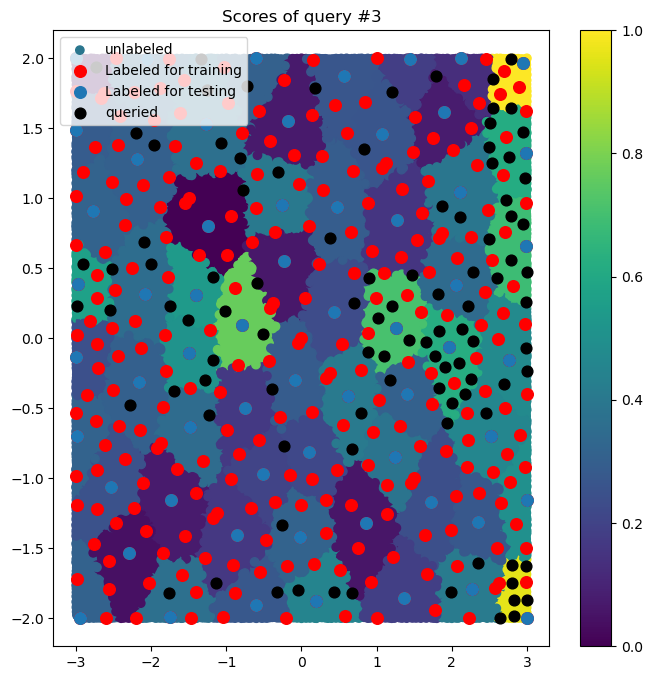
Example of the average MAPE values of the performance value regressors
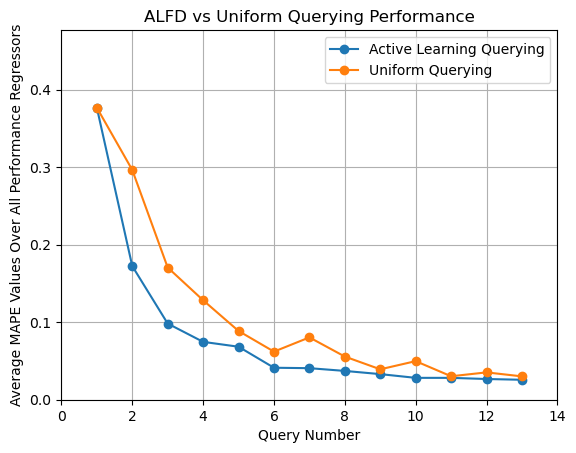
We do not rigorously test this query strategy, but rather propose this as a framework for novel approaches to Active Learning for Design.
License
Open-sourced under the MIT License. See LICENSE for more information.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file al_for_design-0.0.1.tar.gz.
File metadata
- Download URL: al_for_design-0.0.1.tar.gz
- Upload date:
- Size: 24.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
06be344e6d88f0338ea4fbe75b75af5aa8e8120ddde9cd038816a353a08801a5
|
|
| MD5 |
f149c59042afbb42ec24af497f908566
|
|
| BLAKE2b-256 |
1642f590a8fe847cc588d46108733e0a8d3c64de220e60504c5c2750865649da
|
File details
Details for the file al_for_design-0.0.1-py3-none-any.whl.
File metadata
- Download URL: al_for_design-0.0.1-py3-none-any.whl
- Upload date:
- Size: 48.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
663eeaab119ddc311449da23fbb49c447e498f31cfa54918b8202decafe6b51a
|
|
| MD5 |
5749a6651e9ba616b755ec530d8689c3
|
|
| BLAKE2b-256 |
a9a7cf90566db1009bc58d7a801d74ab2cbbe077ab1478fc8373033c371ffccd
|







