Sequence labeling library using Keras.

Project description
# anaGo
**anaGo** is a Python library for sequence labeling(NER, PoS Tagging,...), implemented in Keras.
anaGo can solve sequence labeling tasks such as named entity recognition (NER), part-of-speech tagging (POS tagging), semantic role labeling (SRL) and so on. Unlike traditional sequence labeling solver, anaGo don't need to define any language dependent features. Thus, we can easily use anaGo for any languages.
As an example of anaGo, the following image shows named entity recognition in English:
[anaGo Demo](https://anago.herokuapp.com/)

<!--
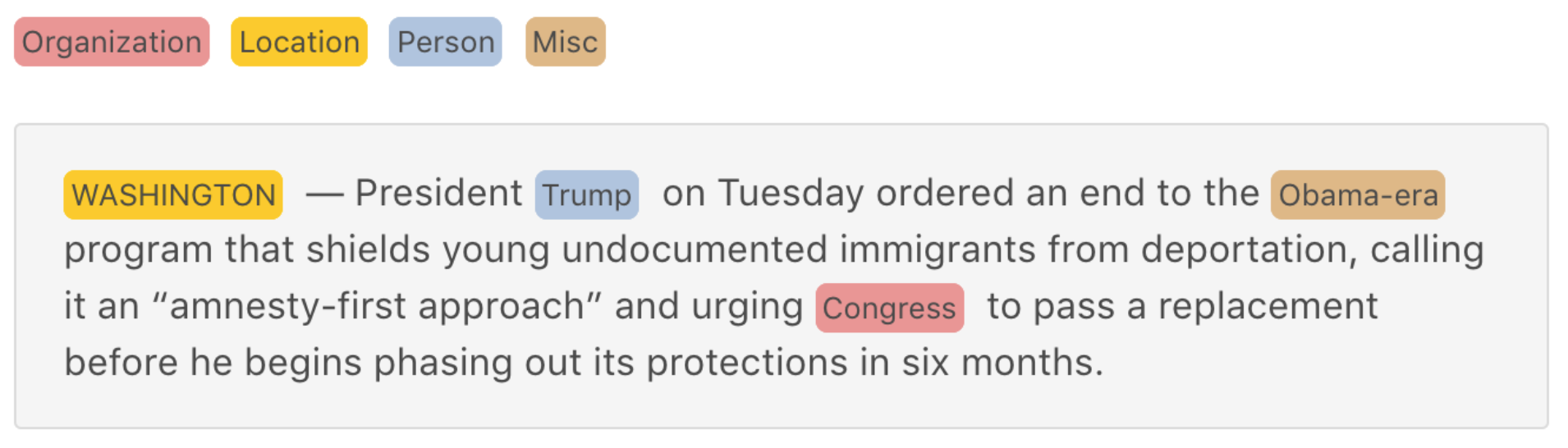

-->
## Get Started
In anaGo, the simplest type of model is the `Sequence` model. Sequence model includes essential methods like `fit`, `score`, `analyze` and `save`/`load`. For more complex features, you should use the anaGo modules such as `models`, `preprocessing` and so on.
Here is the data loader:
```python
>>> from anago.utils import load_data_and_labels
>>> x_train, y_train = load_data_and_labels('train.txt')
>>> x_test, y_test = load_data_and_labels('test.txt')
>>> x_train[0]
['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
>>> y_train[0]
['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
```
You can now iterate on your training data in batches:
```python
>>> import anago
>>> model = anago.Sequence()
>>> model.fit(x_train, y_train, epochs=15)
Epoch 1/15
541/541 [==============================] - 166s 307ms/step - loss: 12.9774
...
```
Evaluate your performance in one line:
```python
>>> model.score(x_test, y_test)
80.20 # f1-micro score
# For more performance, you have to use pre-trained word embeddings.
# For now, anaGo's best score is 90.90 f1-micro score.
```
Or tagging text on new data:
```python
>>> text = 'President Obama is speaking at the White House.'
>>> model.analyze(text)
{
"words": [
"President",
"Obama",
"is",
"speaking",
"at",
"the",
"White",
"House."
],
"entities": [
{
"beginOffset": 1,
"endOffset": 2,
"score": 1,
"text": "Obama",
"type": "PER"
},
{
"beginOffset": 6,
"endOffset": 8,
"score": 1,
"text": "White House.",
"type": "LOC"
}
]
}
```
To download a pre-trained model, call `download` function:
```python
>>> from anago.utils import download
>>> url = 'https://storage.googleapis.com/chakki/datasets/public/ner/conll2003_en.zip'
>>> weights, params, preprocessor = download(url)
>>> model = anago.Sequence.load(weights, params, preprocessor)
>>> model.score(x_test, y_test)
0.9090262970859986
```
## Feature Support
anaGo supports following features:
* Model Training
* Model Evaluation
* Tagging Text
* Custom Model Support
* Downloading pre-trained model
* GPU Support
* Character feature
* CRF Support
* Custom Callback Support
anaGo officially supports Python 3.4–3.6.
## Installation
To install anaGo, simply use `pip`:
```bash
$ pip install anago
```
or install from the repository:
```bash
$ git clone https://github.com/Hironsan/anago.git
$ cd anago
$ python setup.py install
```
## Documentation
(coming soon)
Fantastic documentation is available at [http://example.com/](http://example.com/).
<!--
## Data and Word Vectors
Training data takes a tsv format.
The following text is an example of training data:
```
EU B-ORG
rejects O
German B-MISC
call O
to O
boycott O
British B-MISC
lamb O
. O
Peter B-PER
Blackburn I-PER
```
anaGo supports pre-trained word embeddings like [GloVe vectors](https://nlp.stanford.edu/projects/glove/).
-->
## Reference
This library uses bidirectional LSTM + CRF model based on
[Neural Architectures for Named Entity Recognition](https://arxiv.org/abs/1603.01360)
by Lample, Guillaume, et al., NAACL 2016.
**anaGo** is a Python library for sequence labeling(NER, PoS Tagging,...), implemented in Keras.
anaGo can solve sequence labeling tasks such as named entity recognition (NER), part-of-speech tagging (POS tagging), semantic role labeling (SRL) and so on. Unlike traditional sequence labeling solver, anaGo don't need to define any language dependent features. Thus, we can easily use anaGo for any languages.
As an example of anaGo, the following image shows named entity recognition in English:
[anaGo Demo](https://anago.herokuapp.com/)

<!--


-->
## Get Started
In anaGo, the simplest type of model is the `Sequence` model. Sequence model includes essential methods like `fit`, `score`, `analyze` and `save`/`load`. For more complex features, you should use the anaGo modules such as `models`, `preprocessing` and so on.
Here is the data loader:
```python
>>> from anago.utils import load_data_and_labels
>>> x_train, y_train = load_data_and_labels('train.txt')
>>> x_test, y_test = load_data_and_labels('test.txt')
>>> x_train[0]
['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
>>> y_train[0]
['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
```
You can now iterate on your training data in batches:
```python
>>> import anago
>>> model = anago.Sequence()
>>> model.fit(x_train, y_train, epochs=15)
Epoch 1/15
541/541 [==============================] - 166s 307ms/step - loss: 12.9774
...
```
Evaluate your performance in one line:
```python
>>> model.score(x_test, y_test)
80.20 # f1-micro score
# For more performance, you have to use pre-trained word embeddings.
# For now, anaGo's best score is 90.90 f1-micro score.
```
Or tagging text on new data:
```python
>>> text = 'President Obama is speaking at the White House.'
>>> model.analyze(text)
{
"words": [
"President",
"Obama",
"is",
"speaking",
"at",
"the",
"White",
"House."
],
"entities": [
{
"beginOffset": 1,
"endOffset": 2,
"score": 1,
"text": "Obama",
"type": "PER"
},
{
"beginOffset": 6,
"endOffset": 8,
"score": 1,
"text": "White House.",
"type": "LOC"
}
]
}
```
To download a pre-trained model, call `download` function:
```python
>>> from anago.utils import download
>>> url = 'https://storage.googleapis.com/chakki/datasets/public/ner/conll2003_en.zip'
>>> weights, params, preprocessor = download(url)
>>> model = anago.Sequence.load(weights, params, preprocessor)
>>> model.score(x_test, y_test)
0.9090262970859986
```
## Feature Support
anaGo supports following features:
* Model Training
* Model Evaluation
* Tagging Text
* Custom Model Support
* Downloading pre-trained model
* GPU Support
* Character feature
* CRF Support
* Custom Callback Support
anaGo officially supports Python 3.4–3.6.
## Installation
To install anaGo, simply use `pip`:
```bash
$ pip install anago
```
or install from the repository:
```bash
$ git clone https://github.com/Hironsan/anago.git
$ cd anago
$ python setup.py install
```
## Documentation
(coming soon)
Fantastic documentation is available at [http://example.com/](http://example.com/).
<!--
## Data and Word Vectors
Training data takes a tsv format.
The following text is an example of training data:
```
EU B-ORG
rejects O
German B-MISC
call O
to O
boycott O
British B-MISC
lamb O
. O
Peter B-PER
Blackburn I-PER
```
anaGo supports pre-trained word embeddings like [GloVe vectors](https://nlp.stanford.edu/projects/glove/).
-->
## Reference
This library uses bidirectional LSTM + CRF model based on
[Neural Architectures for Named Entity Recognition](https://arxiv.org/abs/1603.01360)
by Lample, Guillaume, et al., NAACL 2016.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
No source distribution files available for this release.See tutorial on generating distribution archives.
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
anago-1.0.8-py3-none-any.whl
(22.6 kB
view details)
File details
Details for the file anago-1.0.8-py3-none-any.whl.
File metadata
- Download URL: anago-1.0.8-py3-none-any.whl
- Upload date:
- Size: 22.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f6c75c28dfd7c75c7e401e960c0e61ffd5d4531aa55d20cc5e220e7a108d7b60
|
|
| MD5 |
686b8b564d9b542ef2d4fec8cb649cb0
|
|
| BLAKE2b-256 |
0e09a62ba9564e488376966f771105522c4d7783ec141964c0b955230b1f5f63
|







