Feature Importance Analysis of Models

Project description
anamod





Overview
anamod is a python library that implements model-agnostic algorithms for the feature importance analysis of trained black-box models. It is designed to serve the larger goal of interpretable machine learning by using different abstractions over features to interpret models. At a high level, anamod implements the following algorithms:
Given a learned model and a hierarchy over features, (i) it tests feature groups, in addition to base features, and tries to determine the level of resolution at which important features can be determined, (ii) uses hypothesis testing to rigorously assess the effect of each feature on the model’s loss, (iii) employs a hierarchical approach to control the false discovery rate when testing feature groups and individual base features for importance, and (iv) uses hypothesis testing to identify important interactions among features and feature groups. More details may be found in the following paper:
Lee, Kyubin, Akshay Sood, and Mark Craven. 2019. “Understanding Learned Models by Identifying Important Features at the Right Resolution.” In Proceedings of the AAAI Conference on Artificial Intelligence, 33:4155–63. https://doi.org/10.1609/aaai.v33i01.33014155.
Given a learned temporal or sequence model, it identifies its important features, windows as well as its dependence on temporal ordering. More details may be found in the following paper:
Sood, Akshay, and Mark Craven. “Feature Importance Explanations for Temporal Black-Box Models.” ArXiv:2102.11934 [Cs, Stat], February 23, 2021. http://arxiv.org/abs/2102.11934.
anamod supersedes the library mihifepe, based on the first paper (https://github.com/Craven-Biostat-Lab/mihifepe). mihifepe is maintained for legacy reasons but will not receive further updates.
anamod uses the library synmod to generate synthetic data, including time-series data, to test and validate the algorithms (https://github.com/cloudbopper/synmod).
Usage
See detailed API documentation here. Here are some examples of how the package may be used:
Analyzing a scikit-learn binary classification model:
# Train a model from sklearn.linear_model import LogisticRegression from sklearn import datasets model = LogisticRegression() dataset = datasets.load_breast_cancer() X, y, feature_names = (dataset.data, dataset.target, dataset.feature_names) model.fit(X, y) # Analyze the model import anamod output_dir = "example_sklearn_classifier" model.predict = lambda X: model.predict_proba(X)[:, 1] # To return a vector of probabilities when model.predict is called analyzer = anamod.ModelAnalyzer(model, X, y, feature_names=feature_names, output_dir=output_dir) features = analyzer.analyze() # Show list of important features sorted in decreasing order of importance score, along with importance score and model coefficient from pprint import pprint important_features = sorted([feature for feature in features if feature.important], key=lambda feature: feature.importance_score, reverse=True) pprint([(feature.name, feature.importance_score, model.coef_[0][feature.idx[0]]) for feature in important_features])
Analyzing a scikit-learn regression model:
# Train a model from sklearn.linear_model import Ridge from sklearn import datasets model = Ridge(alpha=1e-2) dataset = datasets.load_diabetes() X, y, feature_names = (dataset.data, dataset.target, dataset.feature_names) model.fit(X, y) # Analyze the model import anamod output_dir = "example_sklearn_regressor" analyzer = anamod.ModelAnalyzer(model, X, y, feature_names=feature_names, output_dir=output_dir) features = analyzer.analyze() # Show list of important features sorted in decreasing order of importance score, along with importance score and model coefficient from pprint import pprint important_features = sorted([feature for feature in features if feature.important], key=lambda feature: feature.importance_score, reverse=True) pprint([(feature.name, feature.importance_score, model.coef_[feature.idx[0]]) for feature in important_features])
The outputs can be visualized in other ways as well. To show a table indicating feature importance:
import subprocess
subprocess.run(["open", f"{output_dir}/feature_importance.csv"], check=True)

To visualize the feature importance hierarchy (since no hierarchy is provided in this case, a flat hierarchy is automatically created):
subprocess.run(["open", f"{output_dir}/feature_importance_hierarchy.png"], check=True)

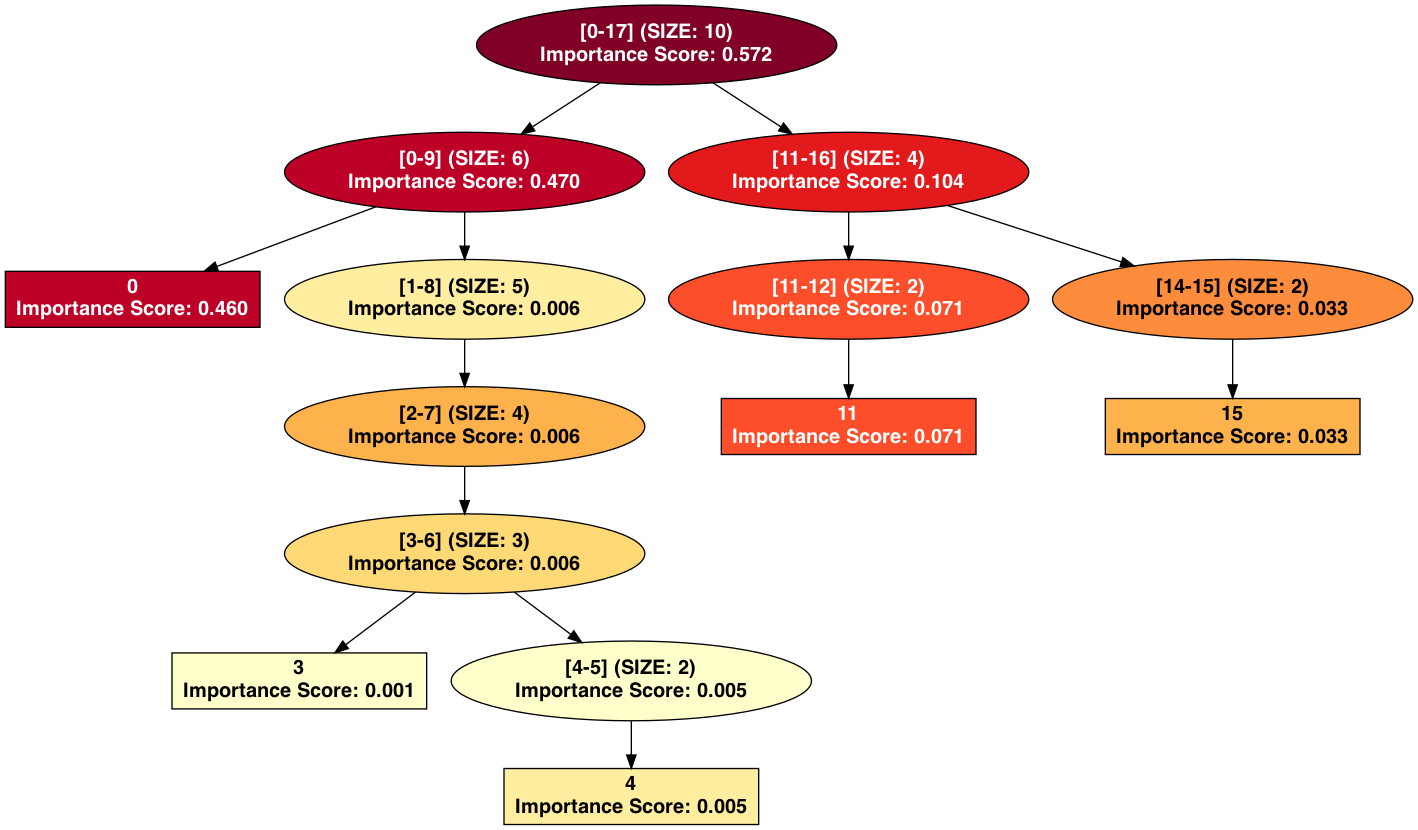
Analyzing a synthentic model with a hierarchy generated using hierarchical clustering:
# Generate synthetic data and model
import synmod
output_dir = "example_synthetic_non_temporal"
num_features = 10
synthesized_features, X, model = synmod.synthesize(output_dir=output_dir, num_instances=100, seed=100,
num_features=num_features, fraction_relevant_features=0.5,
synthesis_type="static", model_type="regressor")
y = model.predict(X, labels=True)
# Generate hierarchy using hierarchical clustering
from types import SimpleNamespace
from anamod.simulation import simulation
args = SimpleNamespace(hierarchy_type="cluster_from_data", contiguous_node_names=True, num_features=num_features)
feature_hierarchy, _ = simulation.gen_hierarchy(args, X)
# Analyze the model
from anamod import ModelAnalyzer
analyzer = ModelAnalyzer(model, X, y, feature_hierarchy=feature_hierarchy, output_dir=output_dir)
features = analyzer.analyze()
# Visualize feature importance hierarchy
import subprocess
subprocess.run(["open", f"{output_dir}/feature_importance_hierarchy.png"], check=True)
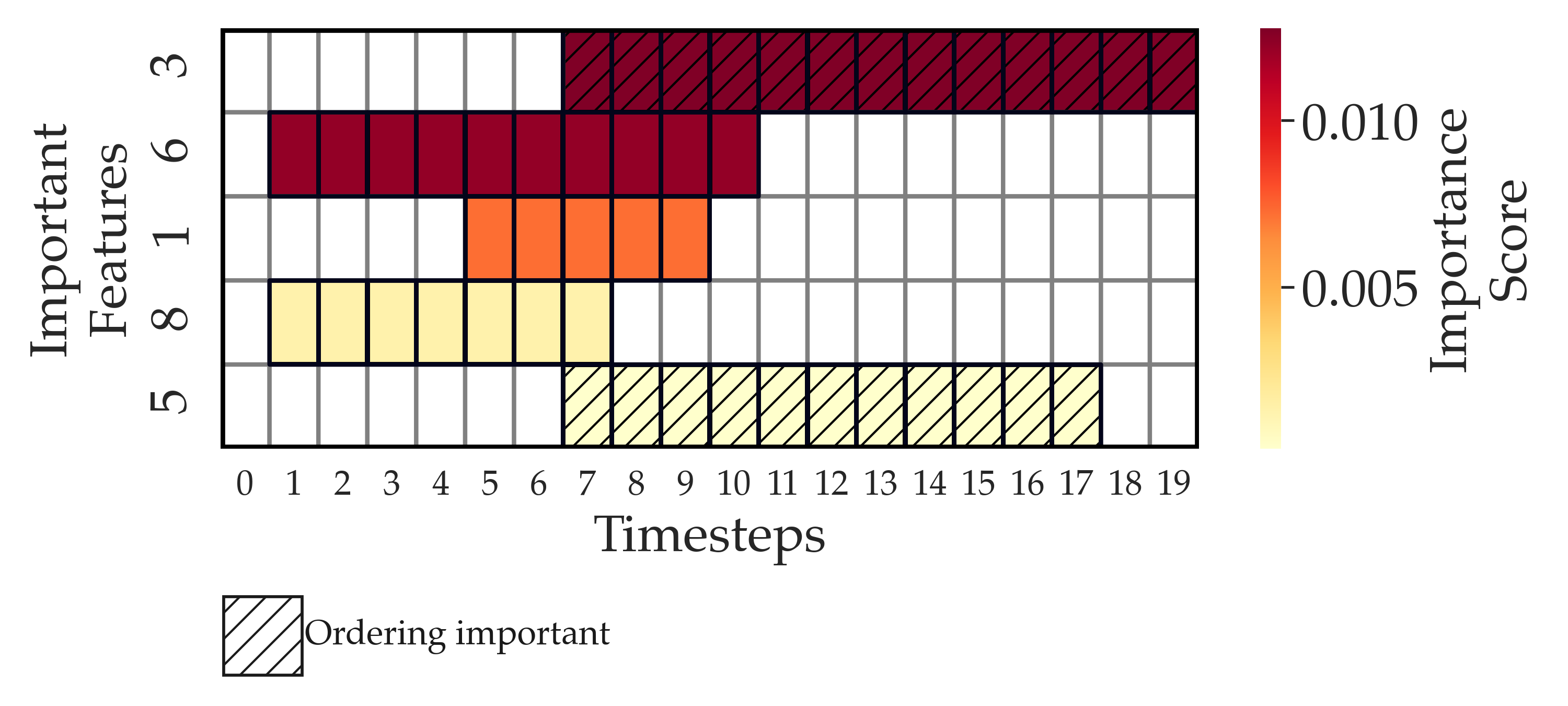
Analyzing a synthetic temporal model:
# Generate synthetic data and model
import synmod
output_dir = "example_synthetic_temporal"
num_features = 10
synthesized_features, X, model = synmod.synthesize(output_dir=output_dir, num_instances=100, seed=100,
num_features=num_features, fraction_relevant_features=0.5,
synthesis_type="temporal", sequence_length=20, model_type="regressor")
y = model.predict(X, labels=True)
# Analyze the model
from anamod import TemporalModelAnalyzer
analyzer = TemporalModelAnalyzer(model, X, y, output_dir=output_dir)
features = analyzer.analyze()
# Visualize feature importance for temporal windows
import subprocess
subprocess.run(["open", f"{output_dir}/feature_importance_windows.png"], check=True)
The package supports parallelization using HTCondor, which can significantly improve running time for large models. If HTCondor is available on your system, you can enable it by providing the “condor” keyword argument. The python package htcondor must be installed (see Installation). Additional condor options may be viewed in the API documentation:
analyzer = anamod.ModelAnalyzer(model, X, y, condor=True)
Installation
The recommended installation method is via virtual environments and pip. In addition, you also need graphviz installed on your system to visualize feature importance hierarchies.
To install the latest stable release:
pip install anamod
Or to install the latest development version from GitHub:
pip install git+https://github.com/cloudbopper/anamod.git@master#egg=anamod
If HTCondor is available on your platform, install the htcondor PyPi package using pip. To enable it, see Usage:
pip install htcondor
Development
Collaborations and contributions are welcome. If you are interested in helping with development, please take a look at https://anamod.readthedocs.io/en/latest/contributing.html.
License
anamod is free, open source software, released under the MIT license. See LICENSE for details.
Contact
Changelog


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file anamod-0.1.4.tar.gz.
File metadata
- Download URL: anamod-0.1.4.tar.gz
- Upload date:
- Size: 440.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.9 tqdm/4.63.0 importlib-metadata/4.11.3 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.8.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a9f1f5f7b12cff0c6fa65a5a7062d55ca497e130b1841a92271667dc4eda1a03
|
|
| MD5 |
de6df89f0e75de2570b3a13923bae12f
|
|
| BLAKE2b-256 |
15a4f1665eeefaa9cf4b44d3fe26b8e16e50dae029c4534a9e447a64f48ab70f
|
File details
Details for the file anamod-0.1.4-py2.py3-none-any.whl.
File metadata
- Download URL: anamod-0.1.4-py2.py3-none-any.whl
- Upload date:
- Size: 99.8 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.9 tqdm/4.63.0 importlib-metadata/4.11.3 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.8.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cfb448387e9b6af6ee6fe2a76f4f43d99319ae718f3c18eeca0582e61d686e63
|
|
| MD5 |
ff32d6ac3c1f66c1280b4e812a9e6eaf
|
|
| BLAKE2b-256 |
eb8bd6330668e023dda2baa7c26c2b48d7fec1e18b684b5398ede49142ab0c49
|







