Build Goal-driven Models of the Sensorimotor Cortex with Ease.

Project description







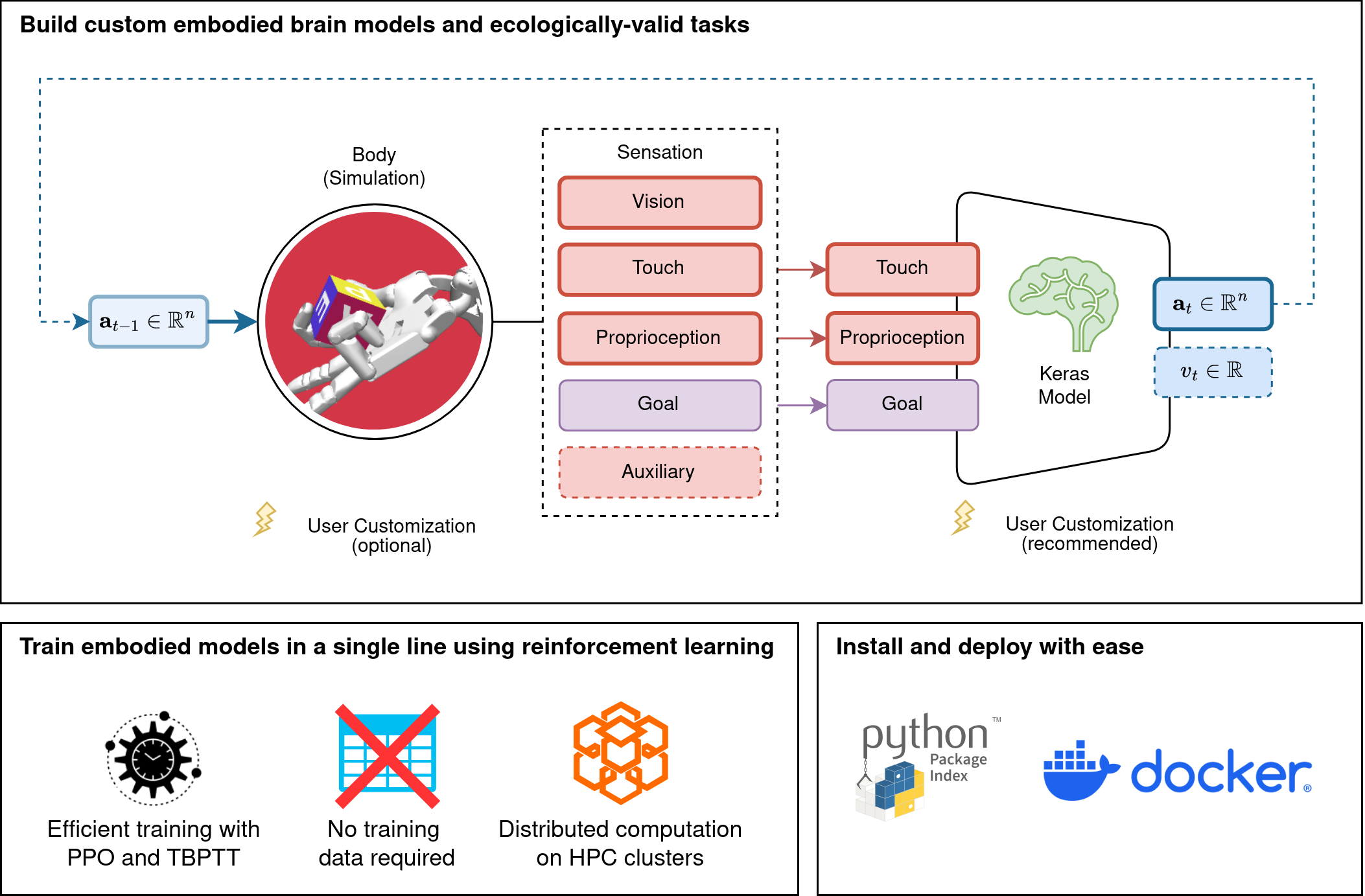
Build Embodied Brain Models with Ease
AngoraPy is an open source modeling library for buidling goal-driven embodied brain models. It provides an easy-to-us API to build and train deep neural network models of the brain on various, customizable, sensorimotor tasks, using reinforcement learning. AngoraPy employs state-of-the-art machine learning techniques, optimized for distributed computation scaling from local workstations to high-performance computing clusters. We aim to hide as much of this under the hood of an intuitive, high-level API but preserve the option for customizing most aspects of the pipeline.
:sparkles: Features
📥 Installation
Prerequisites
AngoraPy requires Python 3.6 or higher. It is recommended to use a virtual environment to install AngoraPy and its dependencies. Additionally, some prerequisites are required.
On Ubuntu, these can be installed by running
sudo apt-get install swig
Additionally, to run AngoraPy with its native distribution, you need MPI installed. On Ubuntu, this can be done by running
sudo apt-get install libopenmpi-dev
However, any other MPI implementation should work as well.
Installing AngoraPy
Binaries
AngoraPy is available as a binary package on PyPI. To install it, run
pip install angorapy
in your terminal.
If you would like to install a specific version, you can specify it by appending ==<version> to the command above. For example, to install version 0.9.0, run
pip install angorapy==0.10.8
Source Installation
To install AngoraPy from source, clone the repository and run pip install -e . in the root directory.
Test Your Installation
You can test your installation by running the following command in your terminal:
python -m angorapy.train CartPole-v1
To test your MPI installation, run
mpirun -np <numthreads> --use-hwthread-cpus python -m angorapy.train LunarLanderContinuous-v2
where <numthreads> is the number of threads you want to (and can) use.
Docker
Alternatively, you can install AngoraPy and all its dependencies in a docker container using the Dockerfile provided in this repository (/docker/Dockerfile). To this end, download the repository and build the docker image from the /docker directory:
sudo docker build -t angorapy:master https://github.com/ccnmaastricht/angorapy.git#master -f - < Dockerfile
To install different versions, replace #master in the source by the tag/branch of the respective version you want to install.
🚀 Getting Started
➡️ Tutorial Section on Getting Started
The scripts train.py, evaluate.py and observe.py provide ready-made scripts for training and evaluating an agent in any environment. With pretrain.py, it is possible to pretrain the visual component. benchmark.py provides functionality for training a batch of agents possibly using different configs for comparison of strategies.
Training an Agent
The train.py commandline interface provides a convenient entry-point for running all sorts of experiments using the builtin models and environments in angorapy. You can train an agent on any environment with optional hyperparameters. Additionally, a monitor will be automatically linked to the training of the agent. For more detail consult the README on monitoring.
Base usage of train.py is as follows:
python -m angorapy.train ENV --architecture MODEL
For instance, training LunarLanderContinuous-v2 using the deeper architecture is possible by running:
python -m angorapy.train LunarLanderContinuous-v2 --architecture deeper
For more advanced options like custom hyperparameters, consult
python -m angorapy.train -h
Evaluating and Observing an Agent
➡️ Tutorial Section on Agent Analysis
There are two more entry points for evaluating and observing an agent: evaluate and observe. General usage is as follows
python -m angorapy.evaluate ID
python -m angorapy.observe ID
Where ID is the agent's ID given when its created (train.py prints this outt, in custom scripts get it with agent.agent_id).
Writing a Training Script
To train agents with custom models, environments, etc. you write your own script. The following is a minimal example:
from angorapy import make_task
from angorapy.models import get_model_builder
from angorapy.agent.ppo_agent import PPOAgent
env = make_task("LunarLanderContinuous-v2")
model_builder = get_model_builder("simple", "ffn")
agent = PPOAgent(model_builder, env)
agent.drill(100, 10, 512)
For more details, consult the examples.
Customizing the Models and Environments
➡️ Tutorial Section on Customization
🎓 Documentation
Detailed documentation of AngoraPy is provided in the READMEs of most subpackages. Additionally, we provide examples and tutorials that get you started with writing your own scripts using AngoraPy. For further readings on specific modules, consult the following READMEs:
If you are missing a documentation for a specific part of AngoraPy, feel free to open an issue and we will do our best to add it.
🔀 Distributed Computation
PPO is an asynchronous algorithm, allowing multiple parallel workers to generate experience independently. We allow parallel gathering and optimization through MPI. Agents will automatically distribute their workers evenly on the available CPU cores, while optimization is distributed over all available GPUs. If no GPUs are available, all CPUs share the task of optimizing.
Distribution is possible locally on your workstation and on HPC sites.
💻 Local Distributed Computing with MPI
To use MPI locally, you need to have a running MPI implementation, e.g. Open MPI 4 on Ubuntu.
To execute train.py via MPI, run
mpirun -np 12 --use-hwthread-cpus python -m angorapy.train ...
where, in this example, 12 is the number of locally available CPU threads and --use-hwthread-cpus
makes available threads (as opposed to only cores). Usage of train.py is as described previously.
:cloud: Distributed Training on SLURM-based HPC clusters
Please note that the following is optimized and tested on the specific cluster we use, but should extend to at least any SLURM based setup.
On any SLURM-based HPC cluster you may submit your job with sbatch usising the following script template:
#!/bin/bash -l
#SBATCH --job-name="angorapy"
#SBATCH --account=xxx
#SBATCH --time=24:00:00
#SBATCH --nodes=32
#SBATCH --ntasks-per-core=1
#SBATCH --ntasks-per-node=12
#SBATCH --cpus-per-task=1
#SBATCH --partition=normal
#SBATCH --constraint=gpu&startx
#SBATCH --hint=nomultithread
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK
export CRAY_CUDA_MPS=1
# load virtual environment
source ${HOME}/robovenv/bin/activate
export DISPLAY=:0
srun python3 -u train.py ...
The number of parallel workers will equal the number of nodes times the number of CPUs per node (32 x 12 = 384 in the template above).
🔗 Citing AngoraPy
If you use AngoraPy for your research, please cite the technical paper
Weidler, T., Goebel, R., & Senden, M. (2023). AngoraPy: A Python toolkit for modeling anthropomorphic goal-driven sensorimotor systems. Frontiers in Neuroinformatics, 17. 10.3389/fninf.2023.1223687
Or using bibtex
@software{weidler_angorapy_2023,
AUTHOR = {Weidler, Tonio and Goebel, Rainer and Senden, Mario },
TITLE = {AngoraPy: A Python toolkit for modeling anthropomorphic goal-driven sensorimotor systems},
JOURNAL = {Frontiers in Neuroinformatics},
VOLUME = {17},
YEAR = {2023},
DOI = {10.3389/fninf.2023.1223687},
ISSN = {1662-5196},
}
Funding
This project was supported by the European Union's Horizon 2020 Framework Programme for Research and Innovation under the Specific Grant Agreement No. 945539 (Human Brain Project SGA3). It is further supported by an Open Science Fund from the Dutch Research Council (Nederlandse Organisatie voor Wetenschappelijk Onderzoek; NWO). We are grateful for their support.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file angorapy-0.11.0.tar.gz.
File metadata
- Download URL: angorapy-0.11.0.tar.gz
- Upload date:
- Size: 1.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6828711c1e28f03c695475866df52fa3c4f0f80d0639501c5aecfd9b462ecbb9
|
|
| MD5 |
b753df1c91c459e9fa8ce44f638035e6
|
|
| BLAKE2b-256 |
91d3e8ef53dae9ce5c89a816e62014eaf0740bd5000d097ea4b0dcc4d059dee4
|
File details
Details for the file angorapy-0.11.0-py3-none-any.whl.
File metadata
- Download URL: angorapy-0.11.0-py3-none-any.whl
- Upload date:
- Size: 1.9 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
69e9ba541a0b00c247fddce2133d114bd862aa2ba3814dde15717cc54b5d7390
|
|
| MD5 |
101b42e4a3c7ee0496b4391558fe7ba1
|
|
| BLAKE2b-256 |
5bcc9625a9668352e94266989ae7e2289fd1daff854bf642e401d881a2355bda
|







