A Nextflow pipeline assembler for genomics. Pick your modules. Assemble them. Run the pipeline.

Project description
Assemblerflow :whale2::package:







A Nextflow pipeline assembler for genomics. Pick your modules. Assemble them. Run the pipeline.
The premisse
Build a pipeline
What if building your own genomics pipeline would be as simple as:
assemblerflow.py build -t "trimmomatic fastqc skesa pilon" -o my_pipeline.nf
Seems pretty simple right? What if we could run this pipeline with a single command on any linux machine or cluster by leveraging the awesomeness of nextflow and docker/singularity containers without having to install any of the pipeline dependencies?
Run the pipeline
nextflow run my_pipeline.nf --fastq path/to/fastq
N E X T F L O W ~ version 0.28.0
Launching `my_pipeline` [prickly_mcnulty] - revision: 041b7b793f
============================================================
M Y P I P E L I N E
============================================================
Built using assemblerflow v1.0.2
Input FastQ : 2
Input samples : 1
Reports are found in : ./reports
Results are found in : ./results
Profile : standard
Starting pipeline at Sun Apr 08 18:22:24 WEST 2018
[warm up] executor > local
[7c/eb5f2f] Submitted process > integrity_coverage_1_1 (02AR0553)
(...)
[31/7d90a1] Submitted process > compile_pilon_report_1_6
Completed at: Sun Apr 08 18:43:41 WEST 2018
Duration : 21m 17s
Success : true
Exit status : 0
Congratulations! You just built and executed your own pipeline with only two commands! :tada:
Installation
Assemblerflow is available as a bioconda package, which already brings nextflow:
conda install assemblerflow
Container engines
Pipelines built with assemblerflow require at least one container
engine to be installed, among docker, singularity or shifter.
If you already have any one of these installed, you're good to go.
If not, we recommend installing singularity, which also has a bioconda
package:
conda install singularity
How to use it
The complete user guide of assemblerflow can be found on readthedocs.org. For a quick and dirty demonstration, see below.
Quick guide
Building a pipeline
Assemblerflow comes with a number of ready-to-use components to build your
own pipeline. Following some basic rules, such as the output type of one process
must match the input type of the next process, assembling a pipeline is done
using the build mode and the -t option:
assemblerflow build -t "trimmomatic spades abricate" -o my_pipeline.nf -n "assembly pipe"
This command will generate everything that is necessary to run the
pipeline automatically, but the main pipeline executable
file will be my_pipeline.nf. This file will contain a nextflow pipeline
for genome assembly starts with trimmomatic and finishes with anti-microbial
gene annotation using abricate.
Wait... what about the software parameters?
Each component in the pipeline has its own set of parameters that can be
modified before or when executing the pipeline. These parameters are
described in the documentation of each process and you can check the options
of your particular pipeline using the help option:
nextflow my_pipeline.nf --help
N E X T F L O W ~ version 0.28.0
Launching `my_pipeline.nf` [prickly_keller] - revision: 1b3fec5658
============================================================
A S S E M B L Y P I P E
============================================================
Built using assemblerflow v1.0.2
Usage:
nextflow run my_pipeline.nf
--fastq Path expression to paired-end fastq files. (default: fastq/*_{1,2}.*) (integrity_coverage)
--genomeSize Genome size estimate for the samples. It is used to estimate the coverage and other assembly parameters andchecks (default: 2.1) (integrity_coverage)
--minCoverage Minimum coverage for a sample to proceed. Can be set to0 to allow any coverage (default: 15) (integrity_coverage)
--adapters Path to adapters files, if any (default: None) (trimmomatic)
--trimSlidingWindow Perform sliding window trimming, cutting once the average quality within the window falls below a threshold (default: 5:20) (trimmomatic)
--trimLeading Cut bases off the start of a read, if below a threshold quality (default: 3 (trimmomatic)
--trimTrailing Cut bases of the end of a read, if below a threshold quality (default: 3) (trimmomatic)
--trimMinLength Drop the read if it is below a specified length (default: 55) (trimmomatic)
--spadesMinCoverage The minimum number of reads to consider an edge in the de Bruijn graph during the assembly (default: 2) (spades)
--spadesMinKmerCoverage Minimum contigs K-mer coverage. After assembly only keep contigs with reported k-mer coverage equal or above this value (default: 2) (spades)
--spadesKmers If 'auto' the SPAdes k-mer lengths will be determined from the maximum read length of each assembly. If 'default', SPAdes will use the default k-mer lengths. (default: auto) (spades)
--abricateDatabases Specify the databases for abricate. (abricate)
This help message is dynamically generated depending on the pipeline you build.
Since this pipeline starts with trimmomatic, which receives fastq files as input,
--fastq is the default parameter for providing paired-end fastq files.
Running a pipeline
Now that we have our nextflow pipeline built, we are ready to executed it by
providing input data. By default, assemblerflow pipelines will run locally and use
singularity to run the containers of each component. This can be
changed in multiple ways, but for convenience assemblerflow has already defined
profiles for most configurations of executors and container engines.
Running a pipeline locally with singularity can be done with:
# Pattern for paired-end fastq is '<sample>_1.fastq.gz <sample>_2.fastq.gz'
nextflow run my_pipeline --fastq "path/to/fastq/*_{1,2}.*"
If you want to run a pipeline in a cluster with SLURM and singularity, just use the appropriate profile:
nextflow run my_pipeline --fastq "path/to/fastq/*_{1,2}.*" -profile slurm_sing
During the execution of the pipeline, the results and reports for each component
are continuously saved to the results and reports directory, respectively.
Why not just write a Nextflow pipeline?
In many cases, building a static nextflow pipeline is sufficient for our goals. However, when building our own pipelines, we often felt the need to add dynamism to this process, particularly if we take into account how fast new tools arise and existing ones change. Our biological goals also change over time and we might need different pipelines to answer different questions. Assemblerflow makes this very easy, by having a set of pre-made and ready-to-use components that can be freely assembled.
For instance, changing the assembly software in a genome assembly pipeline becomes as easy as:
# Use spades
trimmomatic spades pilon
# Use skesa
trimmomatic skesa pilon

If you are interested in having some sort of genome annotation, simply add those components at the end, using a fork syntax:
# Run prokka and abricate at the end of the assembly
trimmomatic spades pilon (prokka | abricate)
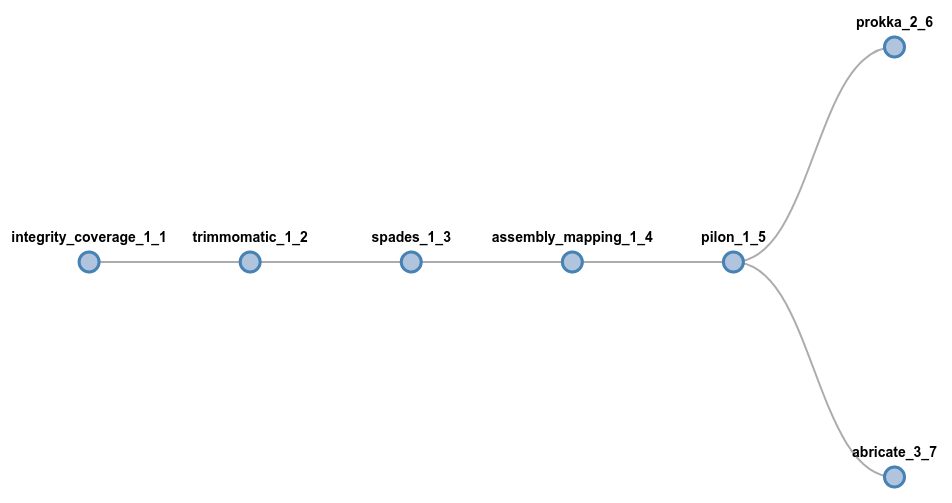
On the other hand, if you are interest in just perform allele calling for wgMLST,
simply add chewbbaca:
trimmomatic spades pilon chewbbaca

Since nextflow handles parallelism of large sets of data so well, simple pipelines of two components are also useful to build:
trimmomatic fastqc
As the number of existing components grow, so does your freedom to build pipelines.
Developer guide
Adding new components
Is there a missing component that you would like to see included? We would love to expand! You could make a component request in our issue tracker.
If you want to be part of the team, you can contribute with the code as well. Each component in assemblerflow can be independently added without having to worry about the rest of the code base. You'll just need to have some knowledge of python and nextflow. Check the developer documentation for how-to guides
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file assemblerflow-1.1.0.post3.tar.gz.
File metadata
- Download URL: assemblerflow-1.1.0.post3.tar.gz
- Upload date:
- Size: 111.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b0390727602e90dad1c3afa8dd408e5c30471a0f6d35b323989e9df4e8aa70fb
|
|
| MD5 |
fc4796ad457f7e201685ba569fde282b
|
|
| BLAKE2b-256 |
5299c6d141ccbb454b71e912d1c87234178b07f797a88086d998644336aa2ddc
|
File details
Details for the file assemblerflow-1.1.0.post3-py3-none-any.whl.
File metadata
- Download URL: assemblerflow-1.1.0.post3-py3-none-any.whl
- Upload date:
- Size: 151.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d5760eb578afdce1a9696a93cd0fb423d6de17868504f908e4a31cc78b16f608
|
|
| MD5 |
d0f43f314ecacbe17aae7f1e94d70ac8
|
|
| BLAKE2b-256 |
f513f0984f7b3d40a909ebfc95d39ccbcedfa45a5ca98261fdd3a581096038f9
|







