Library for Bagging of Deep Residual Neural Networks

Project description
baggingrnet: Library for Bagging of Deep Residual Neural Networks
Introduction
This package provides The python Library for Bagging of Deep Residual Neural Networks (baggingrnet). Current version just supports the KERAS package of deep learning and will extend to the others in the future. The following functionaity is provoded in this package: * model multBagging: Major class to parallel bagging of autoencoder-based deep residual networks. You can setup its aruments for optimal effects. See the class and its member functions' help for details. resAutoencoder: Major class of the base model of autoencoder-based deep residual network. See the specifics for its details. ensPrediction: Major class to ensemble predictions and optional evaluation for independent test. * util pmetrics: main metrics including rsquare and rmse etc.
- data data: function to access two sample datas to test and demonstrate parallel training and predictions of multiple models by bagging. simData: function to simulate the dataset for a test.
Installation of the package
-
You can directly install this package using the following command for the latest version:
pip install baggingrnet -
You can also clone the repository and then install:
git clone --recursive https://github.com/lspatial/baggingrnet.git pip install ./setup.py install
Modeling Framework
The modeling is based on bagging of the encoding-decoding antoencoder based deep residual multilayer percepton (MLP). Residual connections were used from the encoding to decoding layers to improve the learning efficiency and use of bagging is to achieve the stable and improved ensemble predictions, with uncertainty metric (standard deviation).
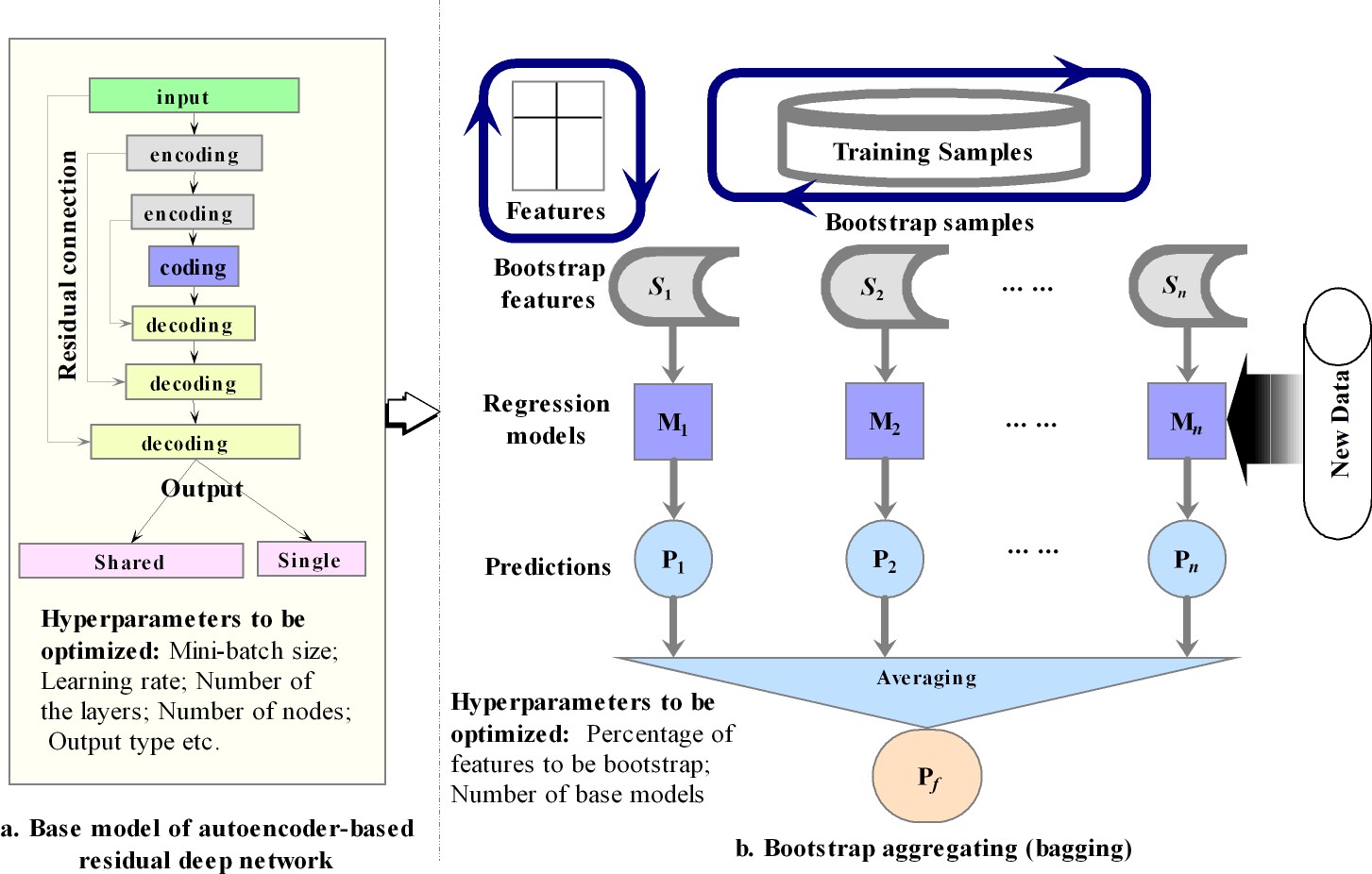
The relevant paper will be published and will update here once published.
Example 1: Regression of Simulated Data
The dataset is simulated using the following formula:
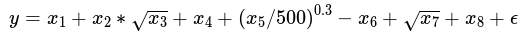
each covariate defined as: x1 ∼ U(1, 100),x2 ∼ U(0, 100),x3 ∼ U(1, 10),x4 ∼ U(1, 100),x5 ∼ U(9, 100),x6 ∼ U(1, 1009),x7 ∼ U(5, 300),x8 U(6 ∼ 200) This example is to illustrate how to use bagging class to train a model and compare the results by the models with and without use of residual connections in the models.
1) Load the dataset:
from baggingrnet.data import data
sim_train=data('sim_train')
sim_train['gindex']=np.array([i for i in range(sim_train.shape[0])])
knitr::kable(py$sim_train[c(1:5),], format = "html")
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | y | gindex | |
|---|---|---|---|---|---|---|---|---|---|---|
| 9842 | 69.59893 | 6.368696 | 5.950720 | 97.97698 | 81.77670 | 38.12578 | 38.71023 | 124.90578 | 168.7697448 | 0 |
| 2513 | 88.83580 | 47.619385 | 8.107348 | 23.95389 | 41.00300 | 256.75319 | 203.75759 | 146.79040 | 184.8472212 | 1 |
| 9116 | 65.32664 | 49.473679 | 5.982418 | 75.99401 | 80.56275 | 849.48435 | 204.52137 | 161.61705 | -444.5390646 | 2 |
| 2673 | 21.72827 | 64.946680 | 2.592348 | 70.32067 | 42.27824 | 387.42060 | 13.15852 | 88.47877 | -166.3553631 | 3 |
| 5607 | 69.45317 | 18.811648 | 5.624373 | 39.81835 | 84.80446 | 333.43811 | 89.22591 | 77.25155 | -0.5405426 | 4 |
# Load the major class for parallel bagging training
from baggingrnet.model.bagging import multBagging
feasList = ['x'+str(i) for i in range(1,9)] #List of the covariates used in training
target='y' # Name of the target variable
bagpath='/tmp/sim_bagging/res' # Path used to
chkpath(bagpath)
mbag=multBagging(bagpath)
mbag.getInputSample(sim_train, feasList,None,'gindex',target)
3) Define the arguments of a model and append it to the list of modeling duties:
name = str(0) # model name as unique identifier
nodes = [32,16,8,4] # List of number of nodes for the encoding and coding layers, adjustable optionally;
minibatch = 512 # Size for mini batch
isresidual = True # Whether to use residual connections in the model
nepoch = 200 #Number of epoches
sampling_fea = False # Whether to bootstrap the predictors/features
noutput = 1 # Number of the output node
islog=False # Whether to make the log transformation
# The following is to add the model's arguments to the list of duties.
mbag.addTask(name,noutput,sampling_fea, nepoch, nodes, minibatch, isresidual,islog)
4) Initiate the training:
mbag.startMProcess(1)
Here, just one core is used for one model.
5) Prediction using the trained models and optional evaluation of the trained model:
from baggingrnet.model.baggingpre import ensPrediction
# Load the test dataset
sim_test=data('sim_test')
sim_test['gindex']=np.array([i for i in range(sim_test.shape[0])]) # Generate the unique id for merging the predicitons of multiple models
# Setup the path and target variable
prepath="/tmp/sim_bagging/res_pre"
chkpath(prepath)
#Load the prdiction class
mbagpre=ensPrediction(bagpath,prepath)
#Load the test data
mbagpre.getInputSample(sim_test, feasList,'gindex')
#Start to make predictions for multiple trained models.
mbagpre.startMProcess(1)
#Obtain the ensemble predictions from those of multiple models and optional evaluation of the models.
mbagpre.aggPredict(isval=True,tfld='y')
The above five steps illustrate the process of loading data, training, testing, and predicting. To compare with the results of residual models, the following code is to get the results for the non-residual models.
mbag.removeTask(name)
bagpath='/tmp/sim_bagging/nores'
chkpath(bagpath)
mbag_nores=multBagging(bagpath)
mbag_nores.getInputSample(sim_train, feasList,None,'gindex','y')
isresidual = False # This is to set no use of residual connections in the models.
mbag_nores.addTask(name,noutput,sampling_fea, nepoch, nodes, minibatch, isresidual,islog)
mbag_nores.startMProcess(1)
prepath="/tmp/sim_bagging/nores_pre"
chkpath(prepath)
mbagpre=ensPrediction(bagpath,prepath)
mbagpre.getInputSample(sim_test, feasList,'gindex')
mbagpre.startMProcess(1)
mbagpre.aggPredict(isval=True,tfld='y')
The comparison of the training/learning curves for residual and non-residual models:
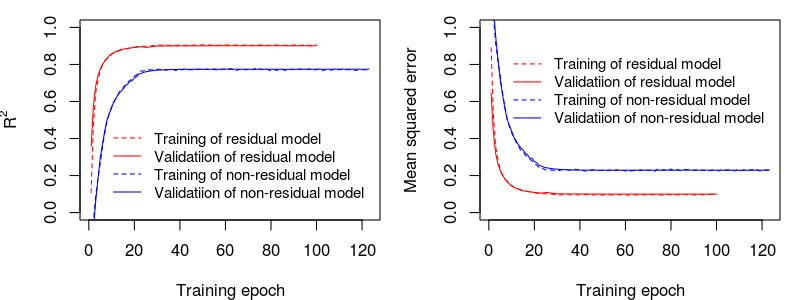
The comparison of the independent test for residual and non-residual models: performance (R2 and RMSE)
## [1] "non residual model r2: 0.78, rmse: 150.17"
## [1] "residual model r2: 0.91, rmse: 98.37"
## [1] "Residual model improved R2 by 12.48%, compared with non-residual model"
## [1] "Residual model decreased rmse by -51.8, compared with non-residual model"
The scatter comparison of residual vs. non-residual models for the independent test:
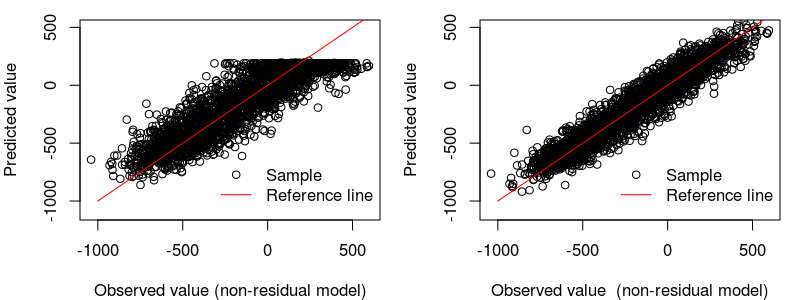
Example 2: Spatiotemporal Estimation of PM2.5
This dataset is the real dataset of the 2015 PM2.5 and the relevant covariates for the Beijing-Tianjin-Tangshan area. Due to data security reason, it has been added with small Gaussian noise.
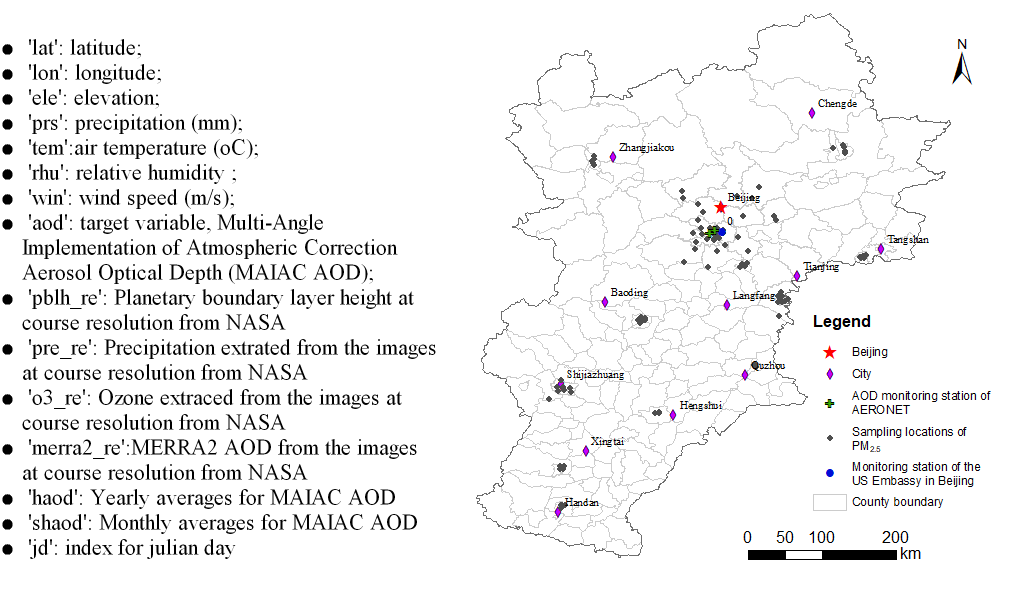
1) Load input data:
Here the PM2.5 dataset is used to test the proposed methods.
from baggingrnet.data import data
pm25_train=data('pm2.5_train')
pm25_train['gindex']=np.array([i for i in range(pm25_train.shape[0])])
| sites | site\_name | city | lon | lat | pm25\_davg | ele | prs | tem | rhu | win | aod | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 23123 | 1010A | 昌平镇 | 北京 | 116.2300 | 40.1952 | 6.80000 | 57.0 | 1007.709 | 20.0859852 | 0.7609952 | 17.39427 | 0.2877372 |
| 1339 | 1014A | 南口路 | 天津 | 117.1930 | 39.1730 | 84.59091 | 8.5 | 1021.859 | -0.2894622 | 0.6565141 | 40.61296 | 0.2245625 |
| 11843 | 1062A | 铁路 | 承德 | 117.9664 | 40.9161 | 21.27273 | 362.0 | 969.876 | 15.3092365 | 0.5288071 | 16.61683 | 0.4272831 |
| 9373 | 榆垡 | 京南榆垡,京南区域点 | 北京 | 116.3000 | 39.5200 | 12.08696 | 18.0 | 1013.116 | 14.0085974 | 0.8100768 | 39.46079 | 0.5075859 |
| 19596 | 1069A | 环境监测监理中心 | 廊坊 | 116.7150 | 39.5571 | 64.20833 | 35.0 | 1005.249 | 24.4960499 | 0.8604047 | 14.01048 | 1.5149391 |
from baggingrnet.model.bagging import multBagging
import random as r
feasList = ['lat', 'lon', 'ele', 'prs', 'tem', 'rhu', 'win', 'pblh_re', 'pre_re', 'o3_re', 'aod', 'merra2_re', 'haod',
'shaod', 'jd','lat2','lon2','latlon']
target='pm25_avg_log'
bagpath='/tmp/baggingpm25_2/res'
chkpath(bagpath)
mbag=multBagging(bagpath)
## initializing ...
mbag.getInputSample(pm25_train, feasList,None,'gindex',target)
## (29475, 31)
3) Define the arguments of multiple models (here 100 models) and append them to the list of modeling duties:
import random as r
for i in range(1,81):
name = str(i)
nodes = [128 + r.randint(-5,5),128+ r.randint(-5,5),96,64,32,12]
minibatch = 2560+r.randint(-5,5)
isresidual = False
nepoch = 120
sampling_fea = False
noutput = 1
islog=True
mbag.addTask(name,noutput,sampling_fea, nepoch, nodes, minibatch, isresidual,islog)
4) Initiate the training:
Initiate the parallel programs using 10 cores
mbag.startMProcess(10)
5) Prediction using the trained models and optional evaluation of the trained model:
from baggingrnet.model.baggingpre import ensPrediction
prepath="/tmp/baggingpm25_2p/res"
chkpath(prepath)
mbagpre=ensPrediction(bagpath,prepath)
mbagpre.getInputSample(pm25_test, feasList,'gindex')
mbagpre.startMProcess(10)
mbagpre.aggPredict(isval=True,tfld='pm25_davg')
Finally, the following results were obtaned.
The results are shown as the following:
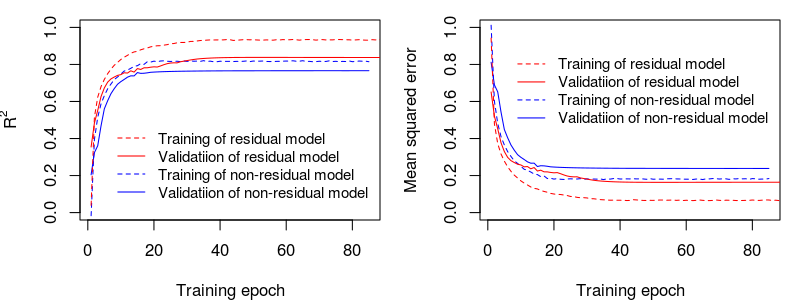
1) Typical learning curves of non-residual vs. residual models are shown as the following:
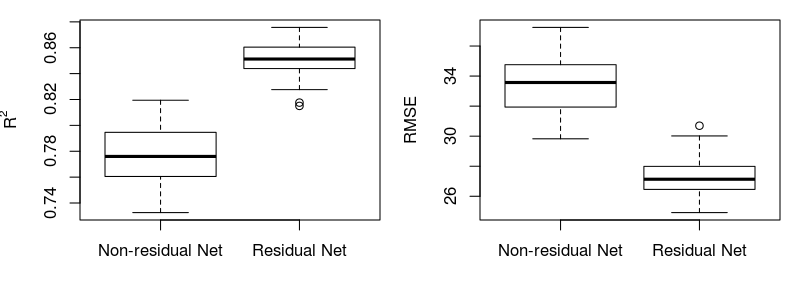
2) Mean performance (R2 and RMSE) of the predictions of multiple non-residual vs residual models for the independent dataset :
3) Performance (R2 and RMSE) of the ensembled predictions based on multiple models for the independent dataset:
## [1] "non residual model r2: 0.88, rmse: 23.55"
## [1] "residual model r2: 0.91, rmse: 20.35"
## [1] "Residual model improved R2 by 2.97%, compared with non-residual model"
## [1] "Residual model decreased rmse by -3.2, compared with non-residual model"
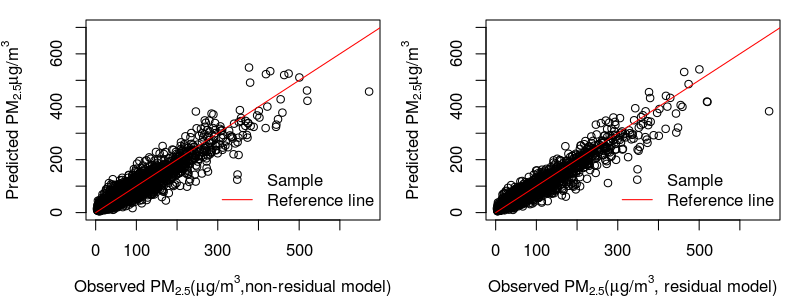
4) Scatter plots for the ensemble predictions of non-residual vs residual models:
5) Comparison of ensemble predictions vs. predictions of single models:
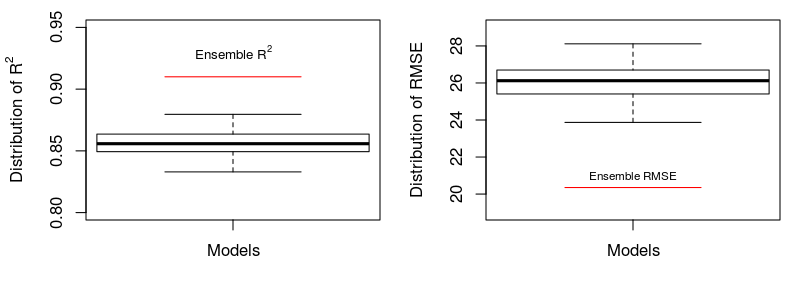
Statistics of the performance for the predictions of multiple models and ensemble predictions are made. The following shows R2 and RMSE, barplots and scatter plots.
Performance digits:
## [1] "Ensemble predictions: R2=0.91, RMSE=20.35"
## [1] "Mean performance of predictions of multiple single models: R2=0.86, RMSE=26.07"
## [1] "Ensemble predictions averagely improved the single predictions by 6% for R2, and reduced -5.72ug/m3 for RMSE"
The boxplot shows considerable improvement by bagging (6% in R2 and -5.72 μg/m3), in comparison with single models.
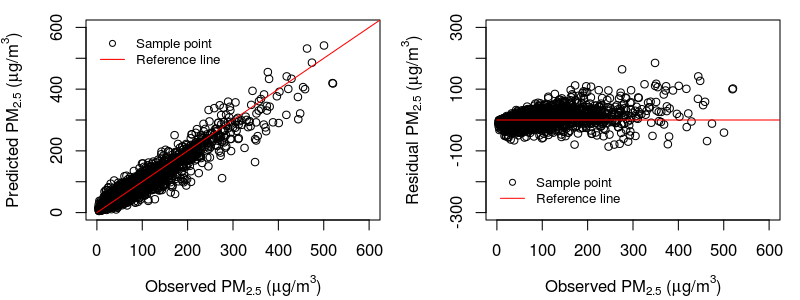
The following shows the scatter plots of observed PM2.5 vs. ensemble predictions/residuals:
Contact
For this library and its relevant complete applications, welcome to contact Dr. Lianfa Li. Email: lspatial@gmail.com or lilf@lreis.ac.cn
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file baggingrnet-0.0.12.tar.gz.
File metadata
- Download URL: baggingrnet-0.0.12.tar.gz
- Upload date:
- Size: 6.1 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.4.2 requests/2.18.4 setuptools/39.2.0 requests-toolbelt/0.8.0 tqdm/4.24.0 CPython/3.4.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7b50a114558e494dce63a047120b90c610b7d88adb71529397419ba0f759130b
|
|
| MD5 |
4c4bba735cccbeb4f0d369de752bf1ec
|
|
| BLAKE2b-256 |
25e70de1749d6dfd19cadd61b3435cb10cccc66d2ac39a4d573bfe3018aa3860
|







