Mixture modeling for working-memory experiments

Project description
Biased Memory Toolbox
A Python toolbox for mixture modeling of data from visual-working-memory experiments
Cherie Zhou (@cherieai) and Sebastiaan Mathôt (@smathot)
Copyright 2020 - 2022

Contents
Citation
Zhou, C., Lorist, M., Mathôt, S., (2021). Categorical bias in visual working memory: The effect of memory load and retention interval. Cortex. https://osf.io/puq4v/
This manuscript is a Stage 1 in-principle acceptance of a registered report
Installation
pip install biased_memory_toolbox
Usage
This section focuses on using the module, assuming that you have a basic understanding of mixture modeling of working memory data. If you want to know more about the theory behind mixture modeling, please read (for example) the manuscript cited above.
We start by reading in a data file using DataMatrix. The data should contain a column that contains the memoranda (here: memory_hue) and a column that contains the responses (here: response_hue), both in degrees with values between 0 and 360.
from datamatrix import io
dm = io.readtxt('example-data/example-participant.csv')
As a first step, which is not related to mixture modeling per se, we check whether the participant performed significantly (p < .05) above chance. This is done with a permutation test that is implemented as test_chance_performance(). Here, low p-values indicate that performance deviates from chance.
import biased_memory_toolbox as bmt
t, p = bmt.test_chance_performance(dm.memory_hue, dm.response_hue)
print('testing performance: t = {:.4f}, p = {:.4f}'.format(t, p))
Output:
testing performance: t = -56.7786, p = 0.0000
Now let's fit the mixture model. We start with a basic model in which only precision and guess rate are estimated, as in the original Zhang and Luck (2008) paper.
To do so, we first calculate the response error, which is simply the circular distance between the memory hue (the color that the participant needed to remember) and the response hue (the color that the participant reproduced). This is done with response_bias(), which, when no categories are provided, simply calculates the response error.
dm.response_error = bmt.response_bias(dm.memory_hue, dm.response_hue)
We can fit the model with a simple call to fix_mixture_model(). By specifying include_bias=False, we fix the bias parameter (the mean of the distribution) at 0, and thus
only get two parameters: the precision and the guess rate.
precision, guess_rate = bmt.fit_mixture_model(
dm.response_error,
include_bias=False
)
print('precision: {:.4f}, guess rate: {:.4f}'.format(precision, guess_rate))
Output:
precision: 1721.6386, guess rate: 0.0627
Now let's fit a slightly more complex model that also includes a bias parameter. To do so, we first calculate the response 'bias', which is similar to the response error except that it is recoded such that positive values reflect a response error towards the prototype of the category that the memorandum belongs to. For example, if the participant saw a slightly aqua-ish shade of green but reproduced a pure green, then this would correspond to a positive response bias for that response.
To calculate the response bias we need to specify a dict with category boundaries and prototypes when calling response_bias(). A sensible default (DEFAULT_CATEGORIES), based on ratings of human participants from Zhou, Mathôt, & Lorist, 2021b, is provided with the toolbox. Another set of ratings, from Zhou, Mathôt, & Lorist, 2021a, is provided as CORTEX_CATEGORIES.
dm.response_bias = bmt.response_bias(
dm.memory_hue,
dm.response_hue,
categories=bmt.DEFAULT_CATEGORIES
)
Next we fit the model again by calling fit_mixture_model(). We now also get a bias parameter (because we did not specify include_bias=False) as described in Zhou, Lorist, and Mathôt (2021).
precision, guess_rate, bias = bmt.fit_mixture_model(dm.response_bias)
print(
'precision: {:.4f}, guess rate: {:.4f}, bias: {:.4f}'.format(
precision,
guess_rate,
bias
)
)
Output:
precision: 1725.9568, guess rate: 0.0626, bias: 0.5481
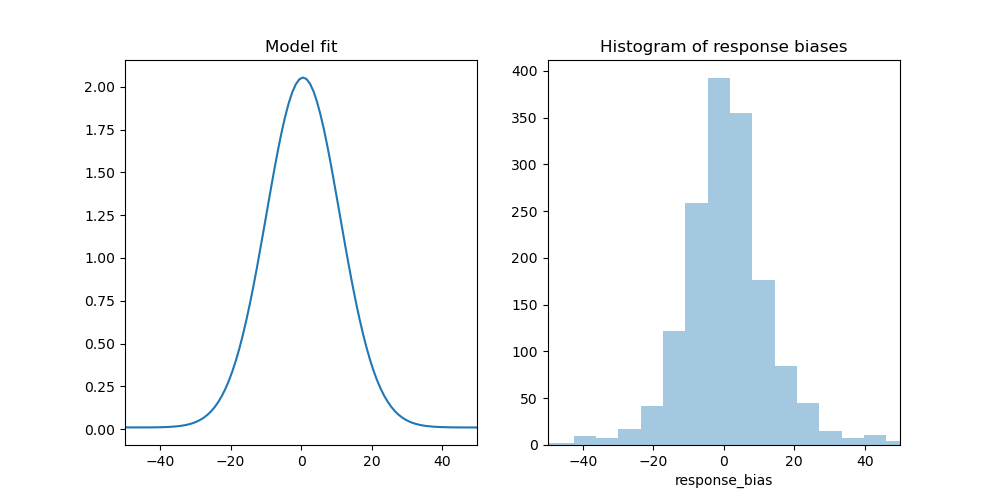
It also makes sense to visualize the model fit, to see if the model accurately captures the pattern of responses. We can do this by plotting a probability density function, which can be generated by mixture_model_pdf().
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
x = np.linspace(-180, 180, 360)
y = bmt.mixture_model_pdf(x, precision, guess_rate, bias)
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.title('Model fit')
plt.xlim(-50, 50)
plt.plot(x, y)
plt.subplot(122)
plt.title('Histogram of response biases')
plt.xlim(-50, 50)
sns.distplot(dm.response_bias, kde=False)
plt.savefig('example.png')
We can also fit a model that takes into account swap errors, as described by Bays, Catalao, and Husain (2009). To do so, we need to also specify the response bias (or plain error) with respect to the non-target items.
Here, we select only those trials in which the set size was 3, and then create two new columns for the response bias with respect to the second and third memory colors, which were non-targets in this experiment. (The first color was the target color.)
dm3 = dm.set_size == 3
dm3.response_bias_nontarget2 = bmt.response_bias(
dm3.hue2,
dm3.response_hue,
categories=bmt.DEFAULT_CATEGORIES
)
dm3.response_bias_nontarget3 = bmt.response_bias(
dm3.hue3,
dm3.response_hue,
categories=bmt.DEFAULT_CATEGORIES
)
By passing a list of non-target response biases, we get a fourth parameter: swap rate.
precision, guess_rate, bias, swap_rate = bmt.fit_mixture_model(
x=dm3.response_bias,
x_nontargets=[
dm3.response_bias_nontarget2,
dm3.response_bias_nontarget3
],
)
print(
'precision: {:.4f}, guess rate: {:.4f}, bias: {:.4f}, swap_rate: {:.4f}'.format(
precision,
guess_rate,
bias,
swap_rate
)
)
Output:
precision: 1458.9628, guess rate: 0.0502, bias: 1.2271, swap_rate: 0.0191
Function reference
biased_memory_toolbox.category(x, categories)
Gets the category to which x belongs. For example, if x corresponds to a slightly orangy shade of red, then the category would be 'red'.
Parameters
- x: float or int : A value in degrees (0 - 360)
- categories: dict : See reponse_bias()
Returns
str A category label
biased_memory_toolbox.fit_mixture_model(x, x_nontargets=None, include_bias=True, x0=None, bounds=None)
Fits the biased mixture model to a dataset. The input to the mixture
model should generally be a response bias as determined by
response_bias() when the bias parameter is fit, or a signed response
error when no bias parameter is fit.
Parameters
- x: array_like : An array, DataMatrix column, or other iterable object of response biases
- x_nontargets: list, optional : A list of arrays, DataMatrix columns, or other iterable objects of response biases relative to non-targets. If this argument is provided, a swap rate is returned as a final parameter.
- include_bias: bool, optional : Indicates whether the bias parameter should be fit as well.
- x0: list, optional : A list of starting values for the parameters. Order: precision, guess
rate, bias. If no starting value is provided for a parameter, then it
is left at the default value of
mixture_model_pdf(). - bounds: list, optional : A list of (upper, lower) bound tuples for the parameters. If no value is provided, then default values are used.
Returns
tuple A tuple with parameters. Depending on the arguments these are on of the following:
- (precision, guess rate)
- (precision, guess rate, bias)
- (precision, guess rate, swap rate)
- (precision, guess rate, bias, swap rate)
biased_memory_toolbox.mixture_model_pdf(x, precision=500, guess_rate=0.1, bias=0)
Returns a probability density function for a mixture model.
Parameters
- x: array_like : A list (or other iterable object) of values for the x axis. For example
range(-180, 181)would generate the PDF for every relevant value. - precision: float, optional : The precision (or kappa) parameter. This is inversely related to the standard deviation, and is a value in degrees.
- guess_rate: float, optional : The proportion of guess responses (0 - 1).
- bias: float, optional : The bias (or loc) parameter in degrees.
Returns
array An array with probability densities for each value of x.
biased_memory_toolbox.prototype(x, categories)
Gets the prototype for the category to which x belongs. For example, if x corresponds to a slightly orangy shade of red, then the prototype would be the hue of a prototypical shade of red.
Parameters
- x: float or int : A value in degrees (0 - 360)
- categories: dict : See reponse_bias()
Returns
float or int A prototype value in degrees (0 360)
biased_memory_toolbox.response_bias(memoranda, responses, categories=None)
Calculates the response bias, which is the error between a response and a memorandum in the direction of the prototype for the category to which the memorandum belongs. For example, if the memorandum was an orangy shade of red, then a positive value would indicate an error towards a prototypical red, and a negative value would indicate an error towards the yellow category.
Parameters
-
memoranda: array_like : An array, DataMatrix column, or other iterable object with memoranda values in degrees (0 - 360)
-
responses: array_like : An array, DataMatrix column, or other iterable object with response values in degrees (0 - 360)
-
categories: dict, optional : A dict that defines the categories. Keys are names of categories and values are (start_value, end_value, prototype) values that indicate where categories begin and end, and what the prototypical value is. The start_value and prototpe can be negative and should be smaller than the end value.
See
biased_memory_toolbox.DEFAULT_CATEGORIESandbiased_memory_toolbox.CORTEX_CATEGORIESfor two sets of category ratings.
Returns
list A list of response_bias values.
biased_memory_toolbox.test_chance_performance(memoranda, responses)
Tests whether responses are above chance. This is done by first determining the real error and the memoranda, and then determinining the shuffled error between the memoranda and the shuffled responses. Finally, an independent t-test is done to compare the real and shuffled error. The exact values will vary because the shuffling is random.
Parameters
- memoranda: array_like : An array, DataMatrix column, or other iterable object with memoranda values in degrees (0 - 360)
- responses: array_like : An array, DataMatrix column, or other iterable object with response values in degrees (0 - 360)
Returns
tuple A (t_value, p_value) tuple.
License
biased_memory_toolbox is licensed under the GNU General Public License
v3.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file biased_memory_toolbox-1.3.0.tar.gz.
File metadata
- Download URL: biased_memory_toolbox-1.3.0.tar.gz
- Upload date:
- Size: 8.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.5.0 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.60.0 CPython/3.9.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
19fe3bd4c914ce6e1cf3350d951d42fb654016360ceadc2b5618640c12f9c7ab
|
|
| MD5 |
c2d40313ec6f3bc27467e586a42b2393
|
|
| BLAKE2b-256 |
d99bcfe1a1e4178052423853b9944a8678e05bdf388a15e513091edb2049fa2d
|
File details
Details for the file biased_memory_toolbox-1.3.0-py3-none-any.whl.
File metadata
- Download URL: biased_memory_toolbox-1.3.0-py3-none-any.whl
- Upload date:
- Size: 21.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.5.0 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.60.0 CPython/3.9.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ccc399915d7e8d97c768c21a71ac9ae927caf7b1a36d448ea0c0521ddbe9a3dc
|
|
| MD5 |
2df69b4152ddd41f29728ed1f354cea6
|
|
| BLAKE2b-256 |
676b2a41afa22f12e8b4af320103cb3486c80477d514ffcf970ea17eaea70b51
|







