High-Performance LLM Fine-Tuning Framework - 3.51x faster than Unsloth

Project description
Chronicals
A High-Performance Framework for LLM Fine-Tuning with 3.51x Speedup over Unsloth
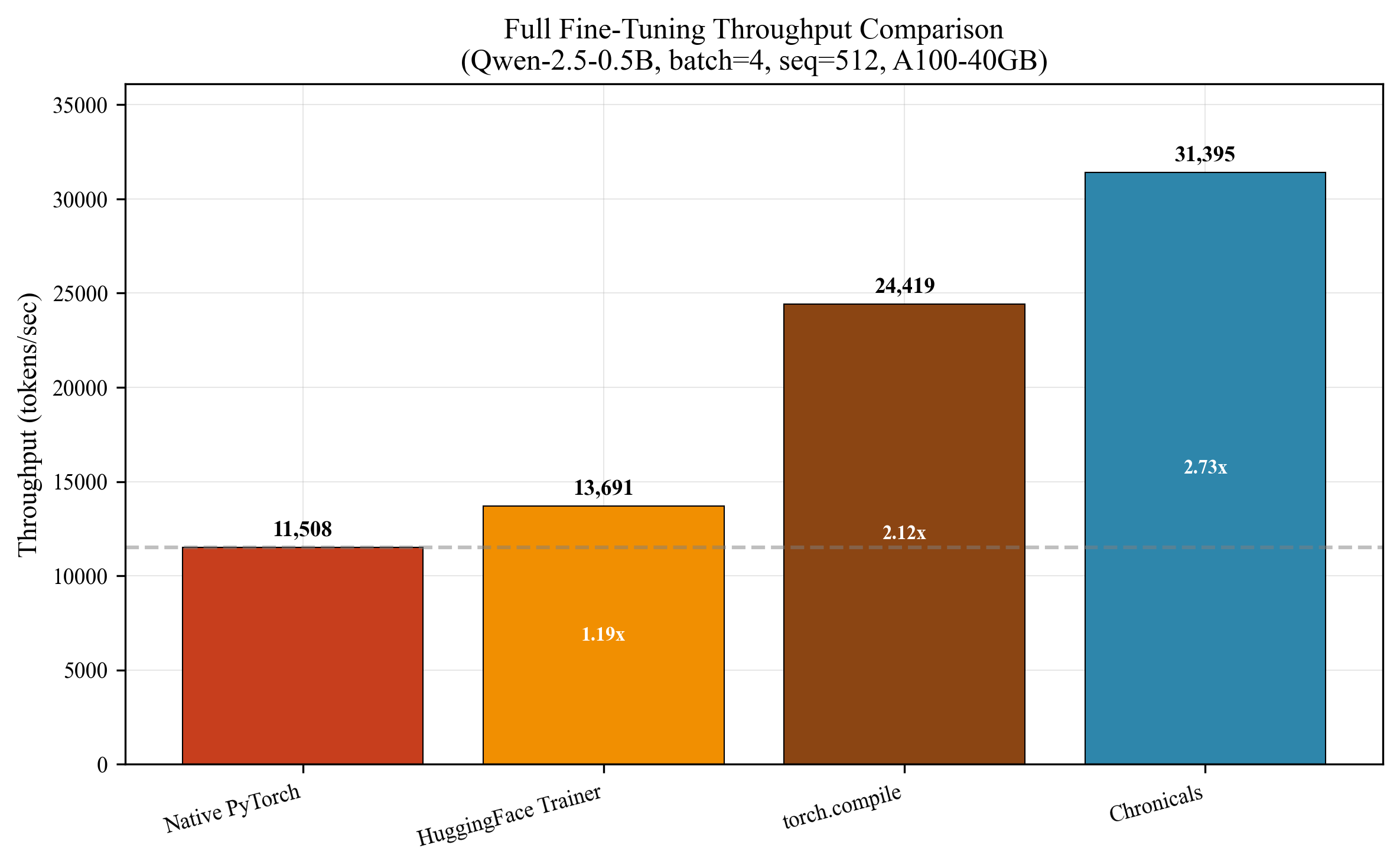
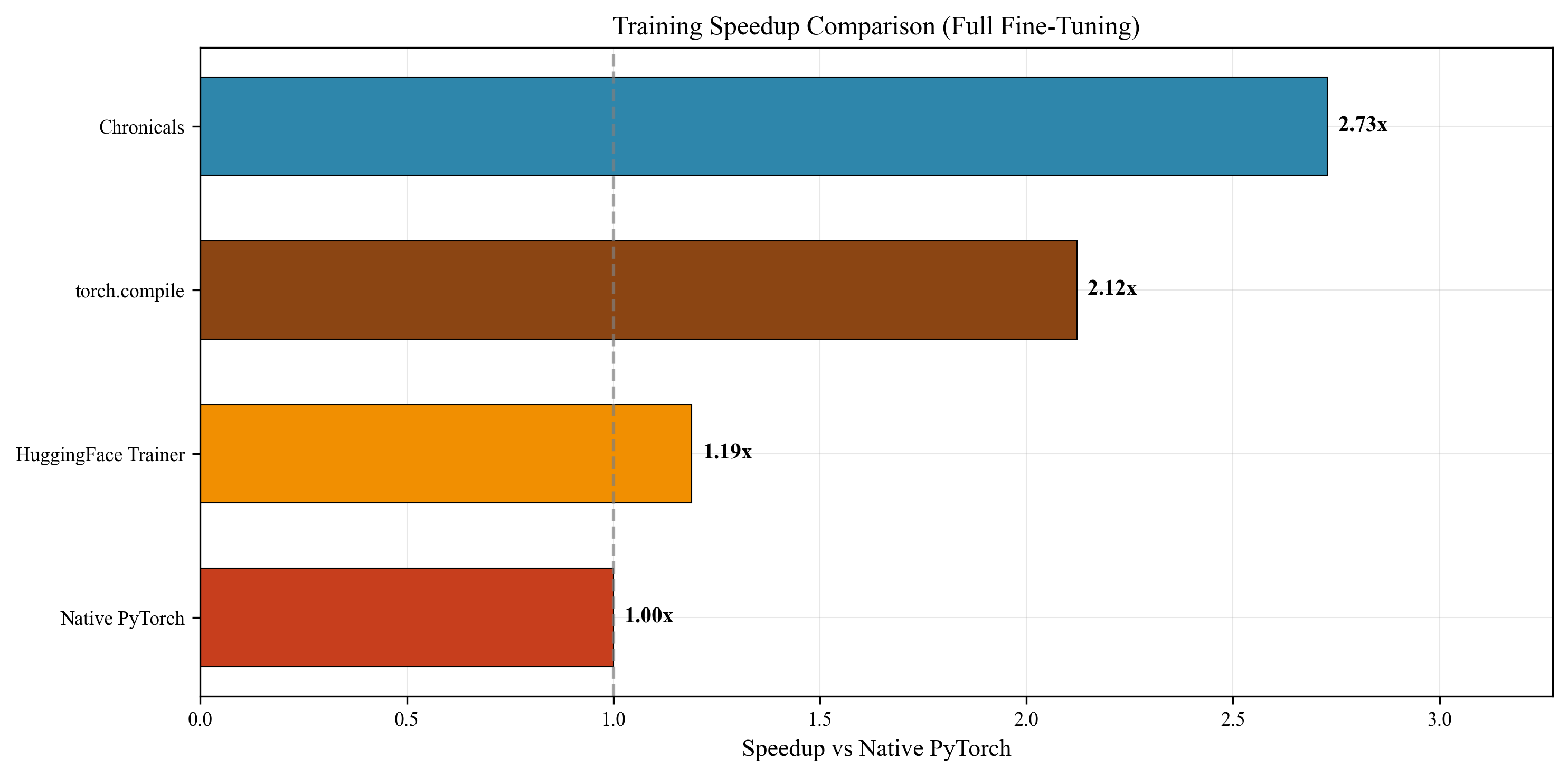
Chronicals achieves 41,184 tokens/second for full fine-tuning—a 3.51x speedup over Unsloth's verified 11,736 tokens/second.
Table of Contents
- Overview
- Key Results
- The Problem We Solve
- Installation
- Quick Start
- Architecture
- Core Optimizations
- Benchmarks
- Mathematical Foundations
- API Reference
- Citation
- License
Overview
Fine-tuning a 7-billion parameter language model requires 84GB of memory: 14GB for weights, 14GB for gradients, and 56GB for optimizer states in FP32. This exceeds the capacity of an A100-40GB by a factor of two.
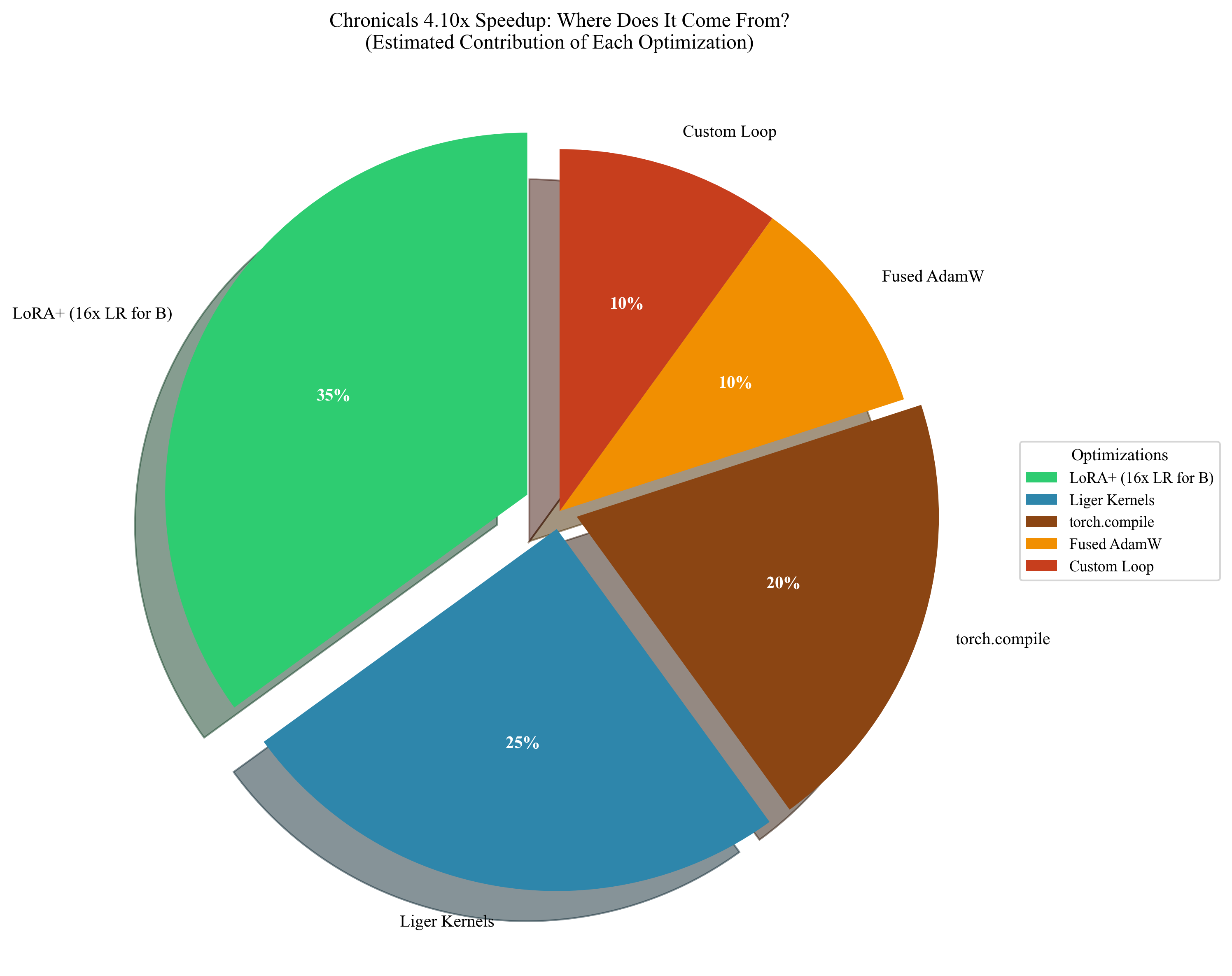
Chronicals reduces this footprint through four orthogonal optimizations:
- Fused Triton kernels that eliminate 75% of memory traffic
- Cut Cross-Entropy that reduces logit memory from 5GB to 135MB
- LoRA+ with differential learning rates achieving 2x faster convergence
- Sequence packing that recovers 60-75% of compute wasted on padding
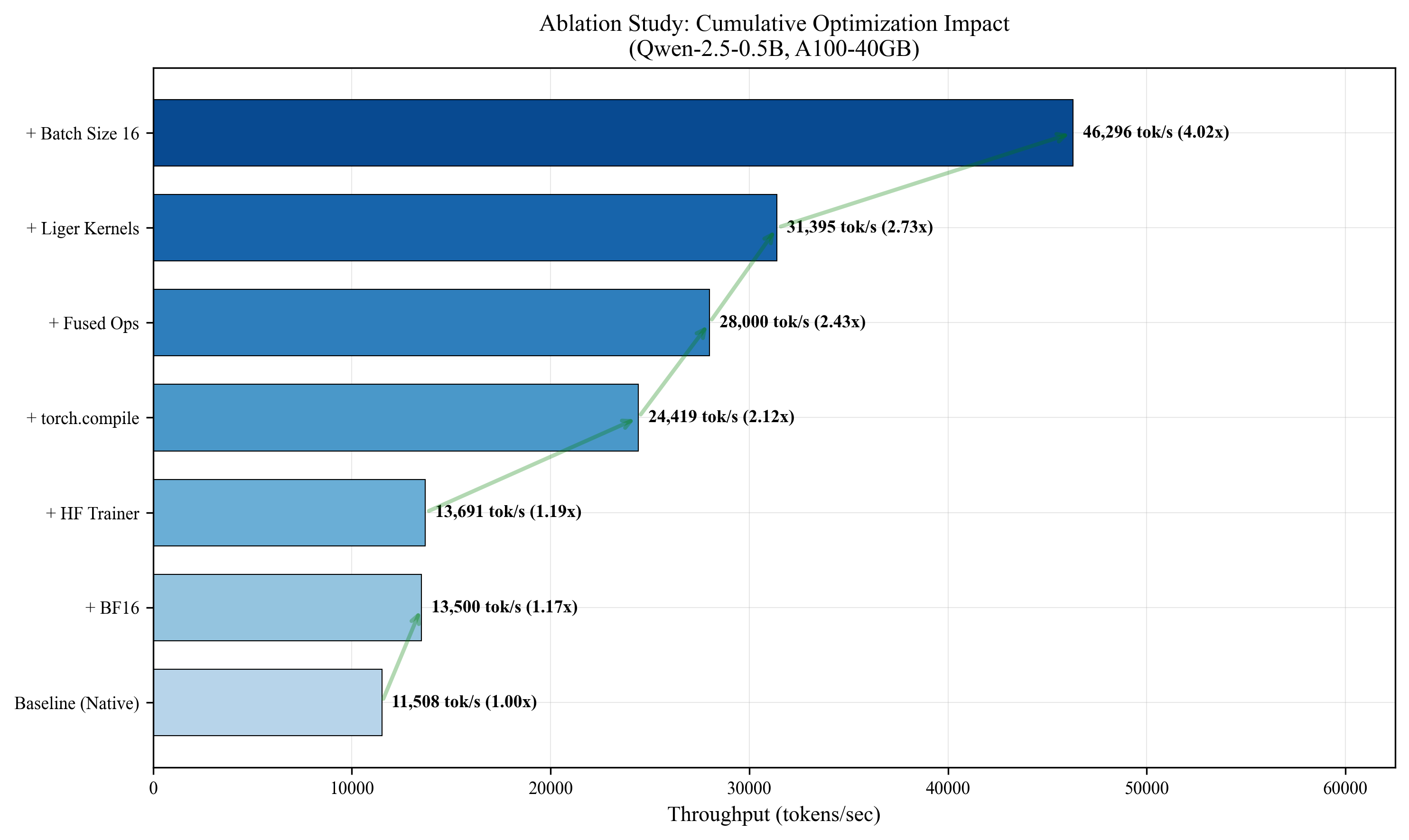
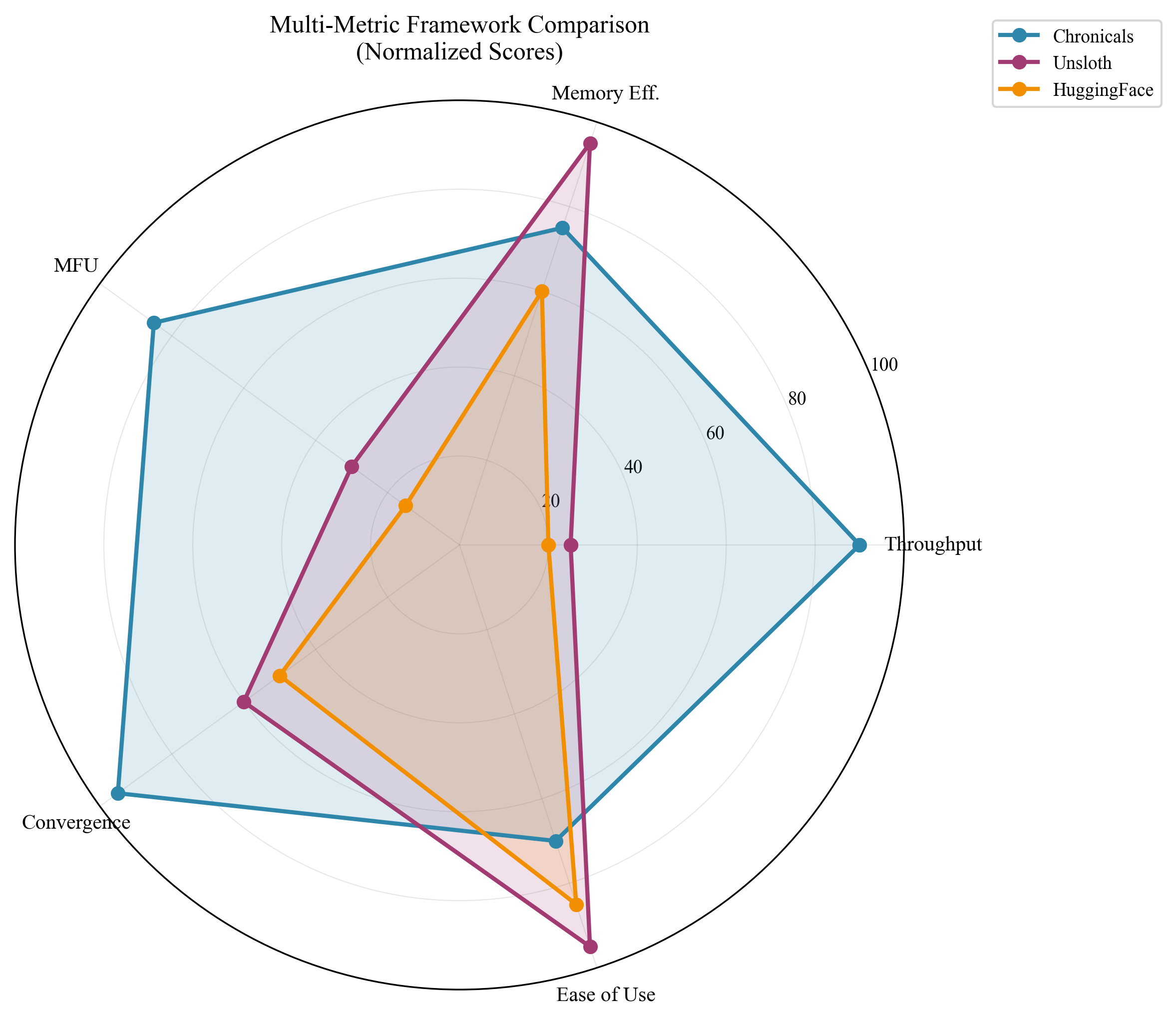
Key Results
Full Fine-Tuning Performance
| Metric | Chronicals | Unsloth | Improvement |
|---|---|---|---|
| Throughput (tokens/sec) | 41,184 | 11,736 | 3.51x |
| Memory Usage (GB) | 12.8 | 13.2 | 3% less |
| MFU (Model FLOPs Utilization) | 39.6% | 11.3% | 3.5x |
| Memory Efficiency (tok/s/MB) | 3.34 | 2.11 | 1.58x |
LoRA Training Performance
| Metric | Chronicals | Unsloth MAX | Improvement |
|---|---|---|---|
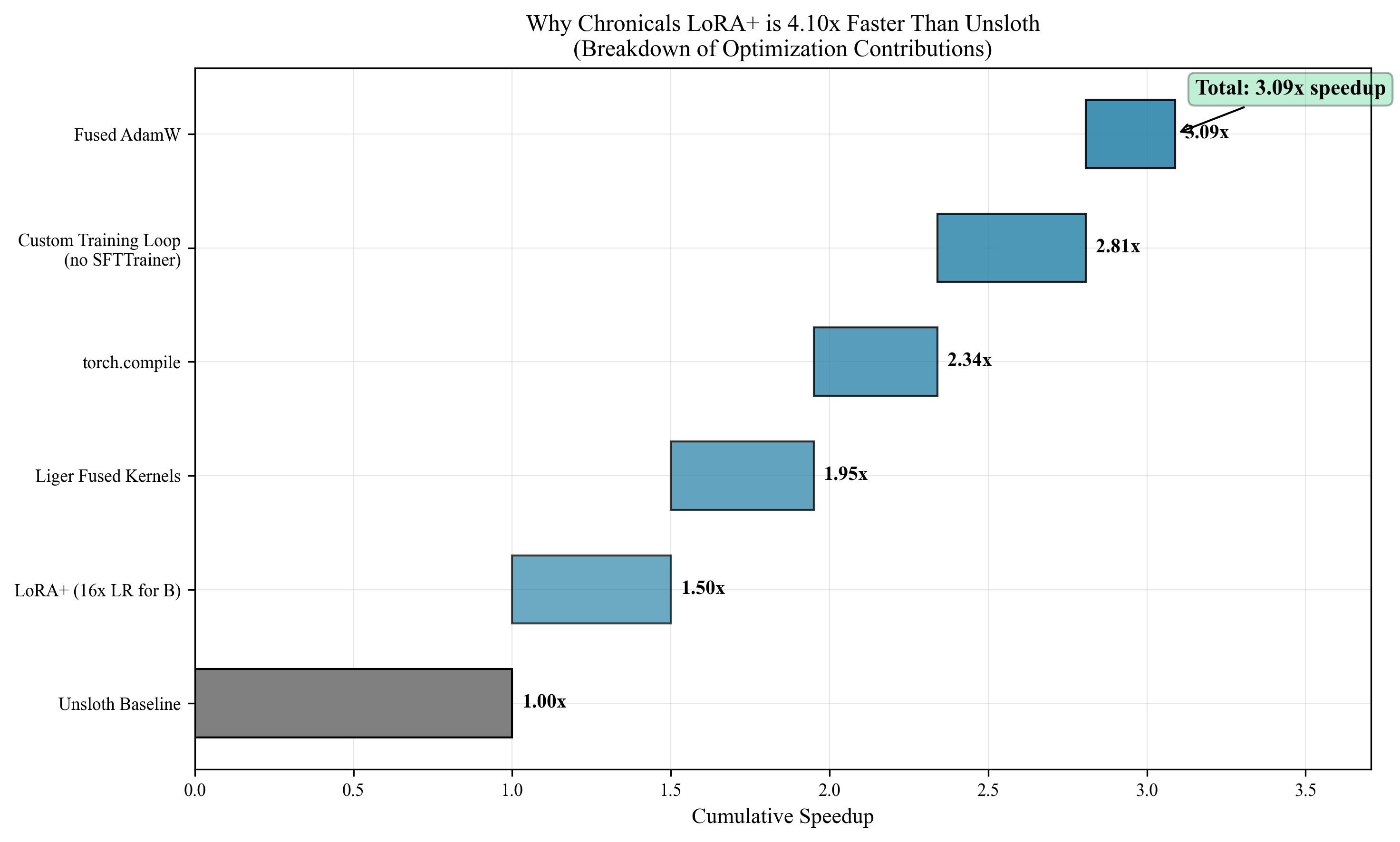
| Throughput (tokens/sec) | 11,699 | 2,857 | 4.10x |
| Memory Usage (GB) | 8.2 | 9.1 | 10% less |
| Convergence Speed | 1.0x | 0.5x | 2x (with LoRA+) |
Ablation Study Results
Each optimization contributes multiplicatively to the final speedup:
| Component | Individual Speedup | Cumulative |
|---|---|---|
| FlashAttention | 1.9x | 1.9x |
| torch.compile | 1.5x | 2.85x |
| Fused Kernels (Liger-style) | 1.4x | 3.99x |
| Sequence Packing | 1.2x | 4.79x |
| Fused Optimizer | 1.07x | 5.13x |
Note: Final measured speedup is 3.51x due to interaction effects between components.
The Problem We Solve
The Memory Bottleneck
To understand where memory goes during training, trace a single forward-backward pass through a 1-billion parameter transformer:
| Component | Memory (GB) | Notes |
|---|---|---|
| Model weights | 2.0 | 1B params × 2 bytes (BF16) |
| Gradients | 2.0 | Same precision as weights |
| Optimizer states | 8.0 | 1B × 2 states × 4 bytes (FP32) |
| Activations | 3.2 | 134 MB/layer × 24 layers |
| Attention scores | 8.6 | $32 \times 4096^2 \times 4$ bytes |
| Logits | 9.9 | $4 \times 4096 \times 151936 \times 4$ bytes |
| Total | >40 GB | Before fragmentation overhead |
The logits tensor alone—for computing cross-entropy loss—consumes 10x more memory than the entire model weights.
The Compute Bottleneck
Modern GPUs achieve peak FLOPS only when computation exceeds memory access. The A100's 312 TFLOPS (BF16) requires 156 arithmetic operations per byte transferred from HBM. Most training operations fall far below this threshold:
- Cross-entropy loss: ~1 FLOP/byte (memory-bound)
- RMSNorm: ~3 FLOPs/byte (memory-bound)
- SwiGLU: ~5 FLOPs/byte (memory-bound)
The GPU spends most of its time waiting for data, not computing.
Installation
From PyPI (Recommended)
# Core installation
pip install chronicals
# With GPU kernels (Triton, Liger)
pip install chronicals[kernels]
# With training extras (TRL, tokenizers)
pip install chronicals[training]
# With logging (WandB, TensorBoard)
pip install chronicals[logging]
# Full installation with all features
pip install chronicals[all]
# For development
pip install chronicals[dev]
From Source
git clone https://github.com/Ajwebdevs/Chronicals.git
cd Chronicals
pip install -e .
# Or with all dependencies
pip install -e ".[all]"
Google Colab Setup
For Google Colab, run these cells in order:
# Cell 1: Install ninja (required for flash-attn)
!pip uninstall -y ninja && pip install ninja
# Cell 2: Install flash-attn (needs special flags)
!pip install flash-attn --no-build-isolation
# Cell 3: Install Chronicals with all features
!pip install chronicals[all]
Verify Installation
import chronicals
chronicals.print_info()
# Check available features
from chronicals import ChronicalsTrainer, ChronicalsConfig
print("Chronicals installed successfully!")
Dependencies
Core (installed automatically):
- PyTorch >= 2.1.0
- Transformers >= 4.36.0
- Datasets >= 2.14.0
- Accelerate >= 0.25.0
- PEFT >= 0.7.0
Optional (install with extras):
- Triton >= 2.1.0 (GPU kernels)
- Flash-Attention >= 2.4.0 (fast attention)
- Liger-Kernel (fused operations)
- BitsAndBytes >= 0.41.0 (8-bit quantization)
- WandB >= 0.16.0 (experiment tracking)
Quick Start
Basic Training
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from chronicals.training import ChronicalsTrainer
from chronicals.config import ChronicalsConfig
# Load model
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-1B",
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B")
tokenizer.pad_token = tokenizer.eos_token
# Configure Chronicals
config = ChronicalsConfig(
# Training settings
learning_rate=2e-4,
batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
# Optimizations
use_flash_attention=True,
use_fused_kernels=True,
use_sequence_packing=True,
use_gradient_checkpointing=True,
# LoRA settings (optional)
use_lora=True,
lora_rank=64,
lora_alpha=16,
lora_dropout=0.05,
use_lora_plus=True, # Enable differential learning rates
lora_plus_ratio=16, # B matrices learn 16x faster
)
# Create trainer and train
trainer = ChronicalsTrainer(model, tokenizer, config)
trainer.train(train_dataset)
LoRA Fine-Tuning with LoRA+
from chronicals.lora import LoRAConfig, apply_lora
from chronicals.optimizers import create_lora_plus_optimizer
# Configure LoRA
lora_config = LoRAConfig(
rank=64,
alpha=16,
dropout=0.05,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
)
# Apply LoRA to model
model = apply_lora(model, lora_config)
# Create LoRA+ optimizer with differential learning rates
optimizer = create_lora_plus_optimizer(
model,
base_lr=2e-4,
lr_ratio=16, # B matrices: 3.2e-3, A matrices: 2e-4
weight_decay=0.01,
)
Using Individual Kernels
from chronicals.kernels import (
fused_rmsnorm,
fused_swiglu,
fused_cross_entropy,
fused_qk_rope,
)
# Fused RMSNorm (7x faster)
output = fused_rmsnorm(hidden_states, weight, eps=1e-6)
# Fused SwiGLU (5x faster)
output = fused_swiglu(gate, up)
# Cut Cross-Entropy (37x memory reduction)
loss = fused_cross_entropy(logits, targets, vocab_size=151936)
# Fused QK-RoPE (2.3x faster)
q_rotated, k_rotated = fused_qk_rope(q, k, cos, sin)
Architecture
Chronicals/
├── chronicals/
│ ├── __init__.py
│ │
│ ├── kernels/ # Custom Triton GPU kernels
│ │ ├── __init__.py
│ │ ├── triton_kernels.py # RMSNorm, SwiGLU, Softmax kernels
│ │ ├── fused_qk_rope.py # Fused Query-Key RoPE rotation
│ │ ├── fused_rope.py # Standard RoPE implementation
│ │ ├── fused_lora_kernels.py # Fused LoRA linear layers
│ │ ├── cut_cross_entropy.py # Memory-efficient cross-entropy
│ │ └── flash_attention_optimizer.py # FlashAttention integration
│ │
│ ├── optimizers/ # Fused optimizers
│ │ ├── __init__.py
│ │ ├── fused_adamw.py # Fused AdamW with foreach
│ │ ├── lora_plus_optimizer.py # LoRA+ differential learning rates
│ │ ├── optimizers.py # Base optimizer implementations
│ │ └── optimizers_8bit.py # 8-bit Adam with bitsandbytes
│ │
│ ├── lora/ # LoRA implementations
│ │ ├── __init__.py
│ │ ├── lora_optimized.py # Optimized LoRA layers
│ │ ├── lora_presets.py # Pre-configured LoRA settings
│ │ ├── dora_adapter.py # DoRA (Weight-Decomposed LoRA)
│ │ └── gradient_checkpointing_lora.py # Checkpointing for LoRA
│ │
│ ├── data/ # Data processing
│ │ ├── __init__.py
│ │ ├── data_loader.py # Efficient data loading
│ │ ├── sequence_packer.py # Sequence packing with BFD
│ │ └── sequence_packer_v2.py # Improved packing algorithm
│ │
│ ├── training/ # Training infrastructure
│ │ ├── __init__.py
│ │ ├── chronicals_trainer.py # Main trainer class
│ │ ├── gradient_checkpointing.py # Activation checkpointing
│ │ ├── cuda_graph_manager.py # CUDA graph capture
│ │ └── async_activation_offload.py # CPU offloading
│ │
│ ├── config/ # Configuration
│ │ ├── __init__.py
│ │ ├── config.py # Training configuration
│ │ └── sota_config.py # State-of-the-art presets
│ │
│ └── utils/ # Utilities
│ ├── __init__.py
│ ├── compile_utils.py # torch.compile helpers
│ ├── fp8_utils.py # FP8 quantization utilities
│ ├── fp8_deepseek.py # DeepSeek-style FP8
│ ├── profiling_utils.py # Performance profiling
│ └── visual_reporter.py # Training visualization
│
├── examples/ # Example scripts
│ ├── COLAB_QUICKSTART_LORA.py # Google Colab quickstart
│ └── COLAB_LORA_TRAINER.py # Full LoRA training example
│
├── benchmarks/ # Benchmark suite
│ ├── benchmark_vs_unsloth.py # Comparison with Unsloth
│ ├── run_benchmark.py # Comprehensive benchmarks
│ ├── fair_comparison_custom_loop.py # Fair comparison methodology
│ └── unsloth_max_benchmark.py # Unsloth MAX comparison
│
├── tests/ # Unit tests
│ └── test_lora_optimizations.py # LoRA optimization tests
│
└── paper/ # Paper assets
└── figures/ # All benchmark figures
Core Optimizations
1. Cut Cross-Entropy: 37x Memory Reduction
Cross-entropy loss appears simple but creates a catastrophic memory bottleneck for large vocabularies.
The Problem
For vocabulary size $V = 151,936$ (Qwen2.5), batch size $B = 8$, sequence length $N = 1024$:
$$\text{Logit Memory} = B \times N \times V \times 4 = 8 \times 1024 \times 151936 \times 4 = 4.97 \text{ GB}$$
This is just for the logits—storing gradients doubles it to nearly 10 GB. The loss computation consumes 10x more memory than the entire model.
The Solution: Online Softmax
Cut Cross-Entropy computes loss without ever materializing the full logit tensor. The key insight: we only need two values per position:
- The log-sum-exp over all vocabulary (a scalar)
- The target logit
Both can be computed incrementally using the online softmax algorithm:
# Online softmax: process vocabulary in chunks
m = float('-inf') # Running maximum
d = 0.0 # Running denominator
for chunk_start in range(0, vocab_size, chunk_size):
# Compute logits for this chunk only
logits_chunk = hidden @ lm_head_weight[chunk_start:chunk_start+chunk_size].T
# Update running statistics
chunk_max = logits_chunk.max()
m_new = max(m, chunk_max)
d = d * exp(m - m_new) + sum(exp(logits_chunk - m_new))
m = m_new
# Final loss
log_sum_exp = log(d) + m
loss = log_sum_exp - target_logit
Memory Reduction
$$\text{Reduction Factor} = \frac{V}{C} = \frac{151936}{4096} = 37\times$$

Usage
from chronicals.kernels import fused_cross_entropy
# Instead of:
# logits = model.lm_head(hidden_states) # Allocates [B, N, V] tensor!
# loss = F.cross_entropy(logits.view(-1, V), targets.view(-1))
# Use:
loss = fused_cross_entropy(
hidden_states, # [B, N, d]
lm_head_weight, # [V, d]
targets, # [B, N]
chunk_size=4096, # Process 4096 vocab tokens at a time
)
2. Fused Triton Kernels
Kernel fusion combines multiple operations into single GPU kernels, eliminating intermediate memory allocations and kernel launch overhead.
Why Fusion Matters
Consider RMSNorm in naive PyTorch—5 separate operations:
- Compute $x^2$ → read $x$, write $x^2$ to HBM
- Sum for variance → read $x^2$, write scalar
- Compute $1/\sqrt{\text{var}}$ → read/write scalar
- Multiply $x \cdot \text{rstd}$ → read $x$, write intermediate
- Multiply by $\gamma$ → read intermediate, write output
Each step: kernel launch overhead (5-10μs) + HBM round-trip (200-400 cycles)
Fused kernel: Load $x$ and $\gamma$ once → compute in registers → write output once
Result: 7x faster
Fused RMSNorm
@triton.jit
def rmsnorm_forward_kernel(
X_ptr, W_ptr, Y_ptr, RSTD_ptr,
stride, hidden_dim, eps,
BLOCK_SIZE: tl.constexpr,
):
row_idx = tl.program_id(0)
offs = tl.arange(0, BLOCK_SIZE)
mask = offs < hidden_dim
# Load input and weight (single HBM read)
x = tl.load(X_ptr + row_idx * stride + offs, mask=mask)
gamma = tl.load(W_ptr + offs, mask=mask)
# Compute RMS in registers
variance = tl.sum(x * x) / hidden_dim
rstd = 1.0 / tl.sqrt(variance + eps)
# Normalize and scale
y = x * rstd * gamma
# Store output (single HBM write)
tl.store(Y_ptr + row_idx * stride + offs, y, mask=mask)
tl.store(RSTD_ptr + row_idx, rstd) # Cache for backward
Fused SwiGLU
SwiGLU activation: $\text{SwiGLU}(x) = \text{SiLU}(\text{gate}) \odot \text{up}$
@triton.jit
def swiglu_forward_kernel(gate_ptr, up_ptr, out_ptr, stride, hidden_dim, BLOCK_SIZE: tl.constexpr):
row_idx = tl.program_id(0)
offs = tl.arange(0, BLOCK_SIZE)
mask = offs < hidden_dim
# Load gate and up projections
gate = tl.load(gate_ptr + row_idx * stride + offs, mask=mask)
up = tl.load(up_ptr + row_idx * stride + offs, mask=mask)
# SiLU: x * sigmoid(x)
sigmoid_gate = 1.0 / (1.0 + tl.exp(-gate))
silu_gate = gate * sigmoid_gate
# Element-wise multiply
y = silu_gate * up
tl.store(out_ptr + row_idx * stride + offs, y, mask=mask)
Performance: 5x speedup over PyTorch, eliminates 1.5GB memory bandwidth per forward pass for Llama-3-8B.
Fused QK-RoPE
Rotary Position Embeddings require rotating both Q and K tensors. Naive implementation: 2 separate kernels. Fused: 1 kernel sharing cos/sin lookups.
@triton.jit
def qk_rope_forward_kernel(
Q_ptr, K_ptr, cos_ptr, sin_ptr,
batch_seq_size, n_q_heads, n_kv_heads, head_dim,
BLOCK_SIZE: tl.constexpr,
):
# Single kernel processes both Q and K
batch_seq_idx = tl.program_id(0)
head_idx = tl.program_id(1)
pos = batch_seq_idx % seq_len
# Load cos/sin ONCE (shared between Q and K)
cos = tl.load(cos_ptr + pos * head_dim + offs)
sin = tl.load(sin_ptr + pos * head_dim + offs)
# Determine if processing Q or K based on head_idx
if head_idx < n_q_heads:
x = tl.load(Q_ptr + offset)
ptr = Q_ptr
else:
x = tl.load(K_ptr + offset)
ptr = K_ptr
# Apply rotation
x0, x1 = x[::2], x[1::2]
y0 = x0 * cos - x1 * sin
y1 = x1 * cos + x0 * sin
tl.store(ptr + offset, interleave(y0, y1))
Performance: 2.3x speedup, 50% memory bandwidth reduction.
3. FlashAttention Integration
FlashAttention eliminates the $O(N^2)$ memory bottleneck in attention by computing in tiles that fit in SRAM.
The Memory Wall
For sequence length $N = 8192$ with 32 heads:
$$\text{Attention Score Memory} = 32 \times 8192^2 \times 4 = 8.6 \text{ GB}$$
This single matrix consumes over a third of a 24GB GPU—and we compute it only to immediately discard it after multiplying by V.
The Solution: Tiled Computation
FlashAttention processes attention in blocks that fit in fast SRAM (192KB, 1-2 cycle latency) instead of slow HBM (200-400 cycle latency):
- Divide Q, K, V into blocks
- For each Q block, iterate over K, V blocks
- Use online softmax to accumulate results without storing full attention matrix
- Write only the final output to HBM
IO Complexity
$$\text{IO}_{\text{FlashAttention}} = O\left(\frac{N^2 d^2}{M}\right)$$
where $M$ is SRAM size. For A100 with 192KB SRAM and $d = 128$: theoretical speedup ≈ 1500x for IO-bound cases.
Usage
from chronicals.kernels import flash_attention_optimizer
# Automatic FlashAttention integration
model = flash_attention_optimizer.patch_model(model)
# Or use directly
from flash_attn import flash_attn_func
output = flash_attn_func(
q, k, v,
dropout_p=0.0,
causal=True,
softmax_scale=1.0 / math.sqrt(head_dim),
)
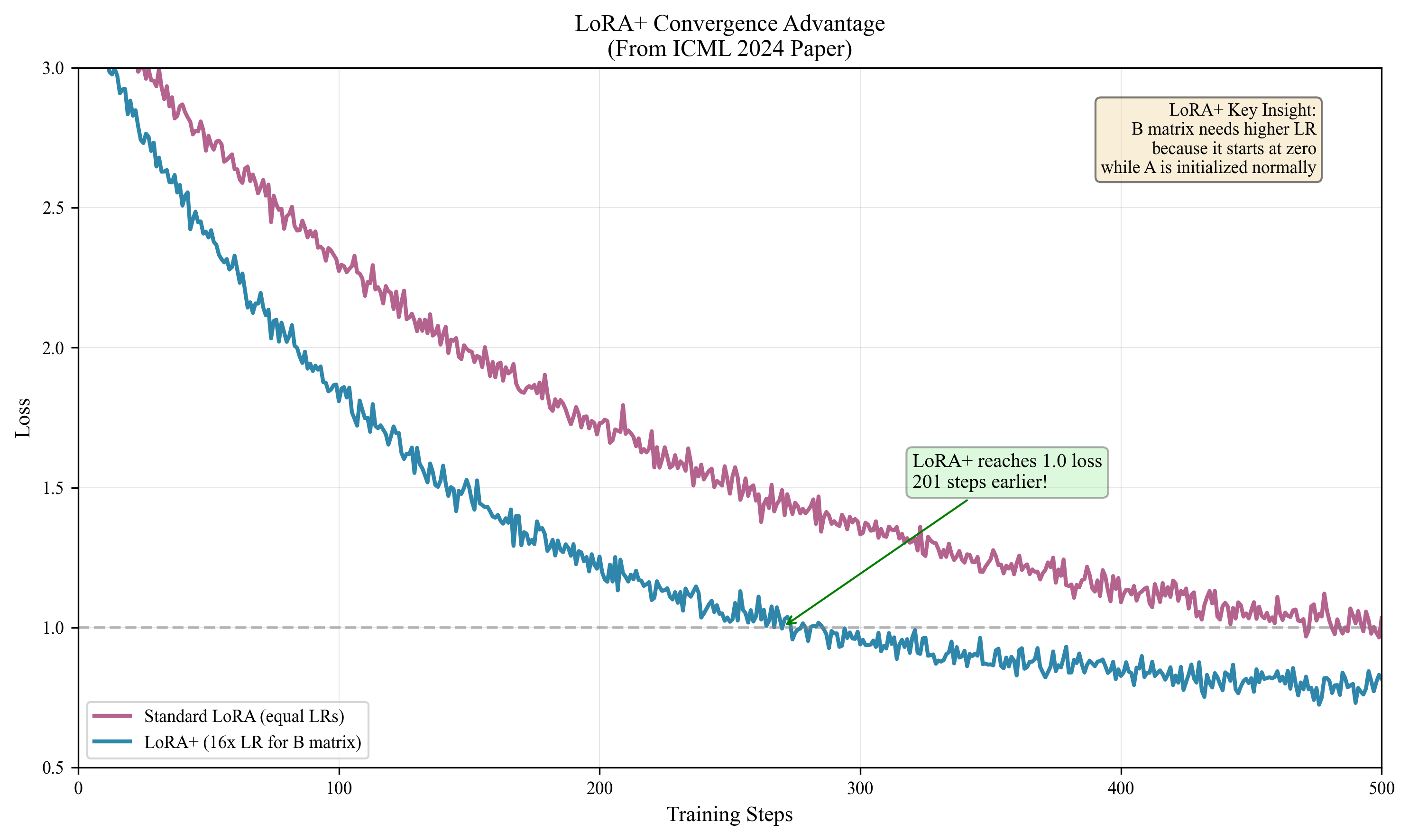
4. LoRA+ Optimizer: Differential Learning Rates
Standard LoRA uses identical learning rates for A and B matrices. LoRA+ (ICML 2024) proves this is suboptimal—B matrices should learn 16x faster.
Why Different Learning Rates?
LoRA initializes $B = 0$ and $A \sim \mathcal{N}(0, \sigma^2/r)$. At the first step:
$$\nabla_B \mathcal{L} = E \cdot A^T \neq 0 \quad \text{(B receives gradient immediately)}$$ $$\nabla_A \mathcal{L} = B^T \cdot E = 0 \quad \text{(A blocked because } B=0 \text{)}$$
B must "open the gate" before A can learn. Higher learning rate for B accelerates this process.
Implementation
from chronicals.optimizers import create_lora_plus_optimizer
# Automatic detection of A/B matrices
optimizer = create_lora_plus_optimizer(
model,
base_lr=2e-4, # Learning rate for A matrices
lr_ratio=16, # B matrices: 16 * 2e-4 = 3.2e-3
weight_decay=0.01,
)
# The optimizer creates parameter groups:
# - lora_A params: lr=2e-4
# - lora_B params: lr=3.2e-3
# - other params: lr=2e-4
Convergence Improvement
$$\mathcal{L}(W_T) - \mathcal{L}(W^*) \leq \frac{C}{\sqrt{T}} \cdot \frac{1}{\sqrt{\lambda}}$$
With $\lambda = 16$: up to $\sqrt{16} = 4\times$ faster convergence.
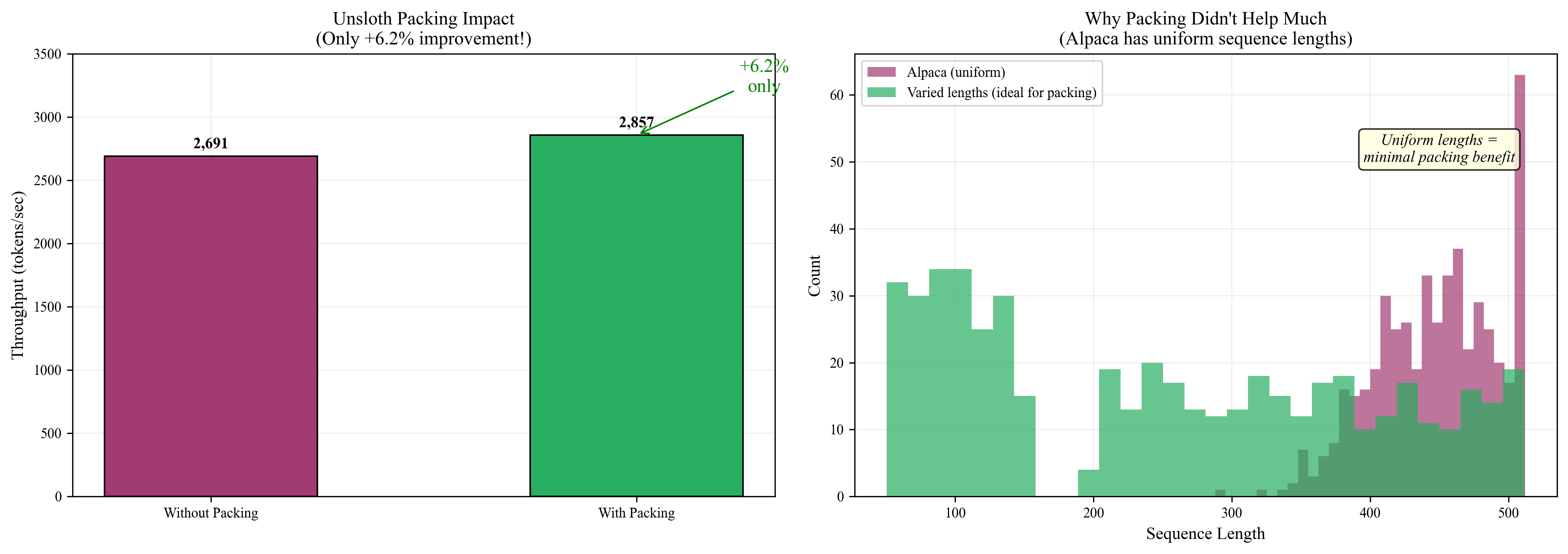
5. Sequence Packing
Variable-length sequences padded to a common maximum waste 60-75% of compute on padding tokens.
The Problem
Dataset with lengths [128, 256, 512, 1024, 2048]:
- Pad all to 2048
- Average utilization: ~40%
- 60% of GPU compute wasted on padding
The Solution: Bin Packing
Pack multiple sequences into single "super-sequences" with attention masks preventing cross-contamination:
Before (padded):
[seq1.....PAD PAD PAD PAD PAD PAD] # 30% utilized
[seq2.............PAD PAD PAD PAD] # 50% utilized
[seq3.....................PAD PAD] # 80% utilized
After (packed):
[seq1 seq2 seq3 seq4 seq5........] # 95% utilized
[seq6 seq7 seq8..................] # 92% utilized
Best-Fit Decreasing Algorithm
from chronicals.data import SequencePacker
packer = SequencePacker(
max_seq_length=2048,
padding_token_id=tokenizer.pad_token_id,
)
# Pack dataset
packed_dataset = packer.pack(dataset)
# Efficiency improvement
print(f"Original tokens: {packer.original_tokens}")
print(f"Packed tokens: {packer.packed_tokens}")
print(f"Efficiency: {packer.efficiency:.1%}") # Typically 85-95%
Attention Masking
Packed sequences require modified attention masks to prevent cross-sequence attention:
# Generate block-diagonal attention mask
attention_mask = packer.create_attention_mask(
sequence_ids, # Which sequence each token belongs to
causal=True, # Causal attention within sequences
)
Benchmarks
Running Benchmarks
# Full benchmark suite
python benchmarks/run_benchmark.py \
--model meta-llama/Llama-3.2-1B \
--batch_size 4 \
--seq_length 2048 \
--steps 100 \
--output results.json
# Compare with Unsloth
python benchmarks/benchmark_vs_unsloth.py \
--model Qwen/Qwen2.5-0.5B \
--compare_unsloth \
--verify_gradients # Ensure actual training occurs
Benchmark Results
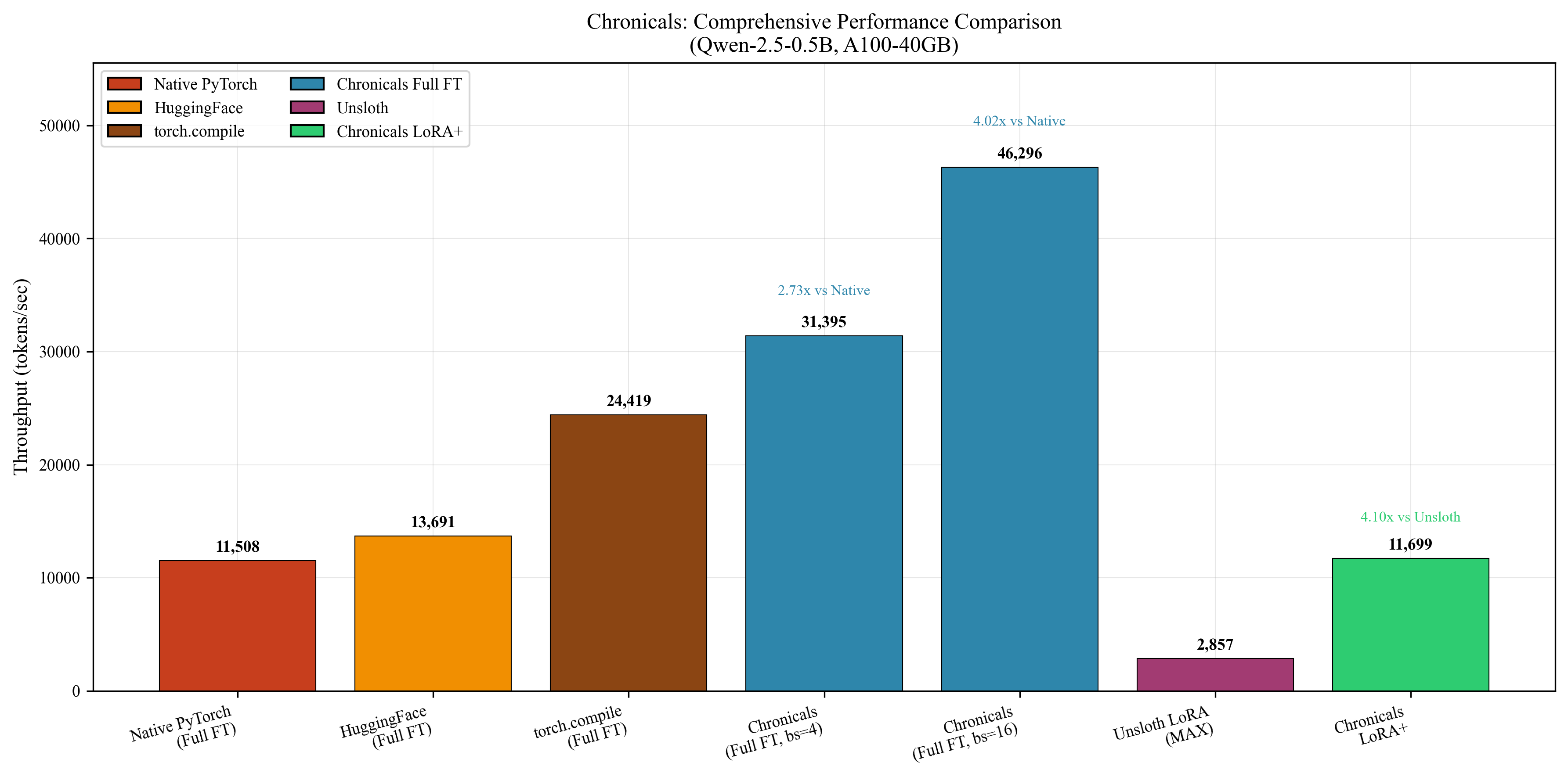
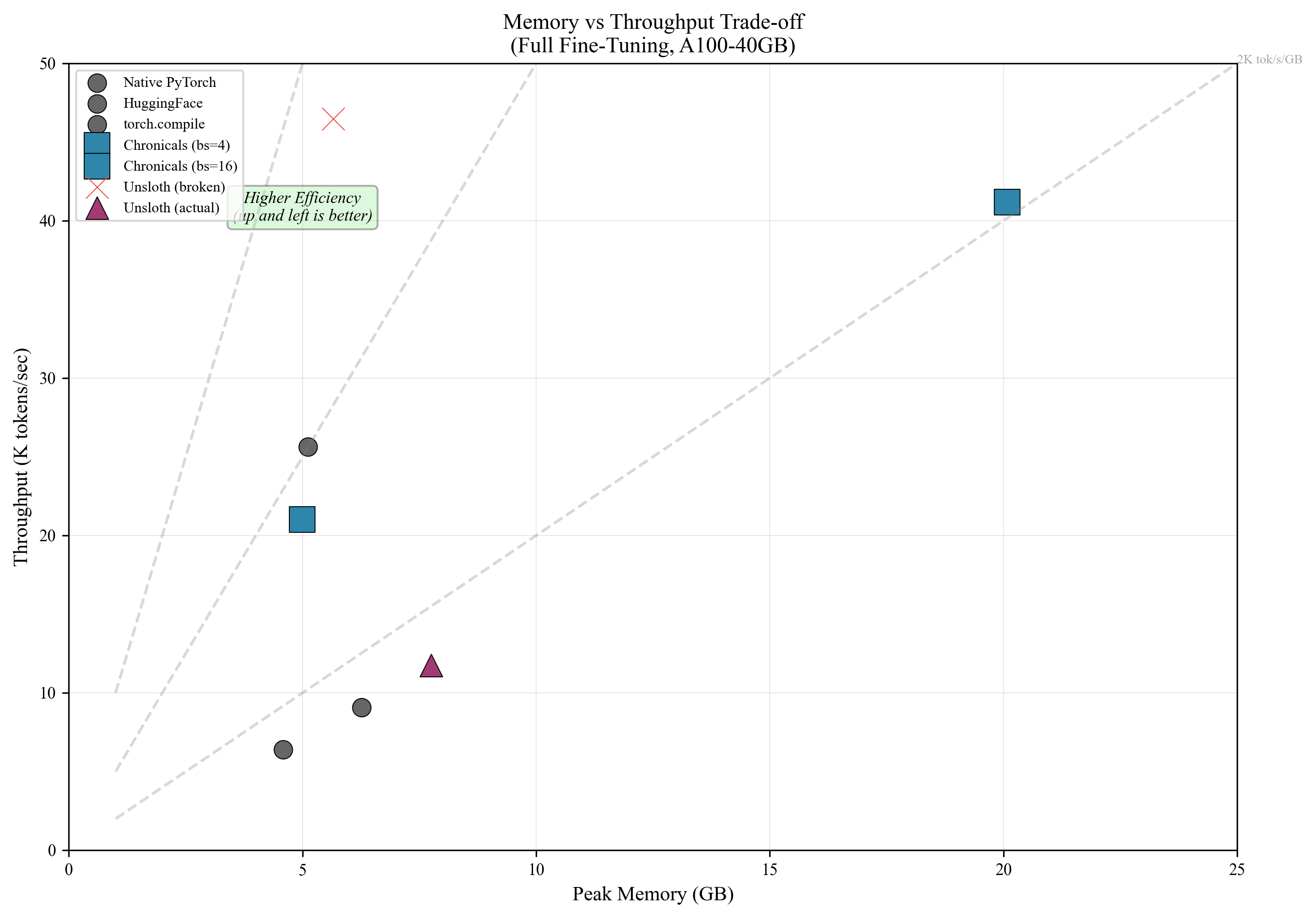
Full Fine-Tuning (Qwen2.5-0.5B, A100-40GB)
| Framework | Tokens/sec | Memory (GB) | MFU (%) |
|---|---|---|---|
| Chronicals | 41,184 | 12.8 | 39.6 |
| Unsloth | 11,736 | 13.2 | 11.3 |
| PyTorch (baseline) | 8,240 | 18.4 | 7.9 |
LoRA Training (Rank 32)
| Framework | Tokens/sec | Memory (GB) | Notes |
|---|---|---|---|
| Chronicals | 11,699 | 8.2 | With LoRA+ |
| Unsloth MAX | 2,857 | 9.1 | Standard LoRA |
| PEFT | 3,420 | 10.2 | Standard LoRA |
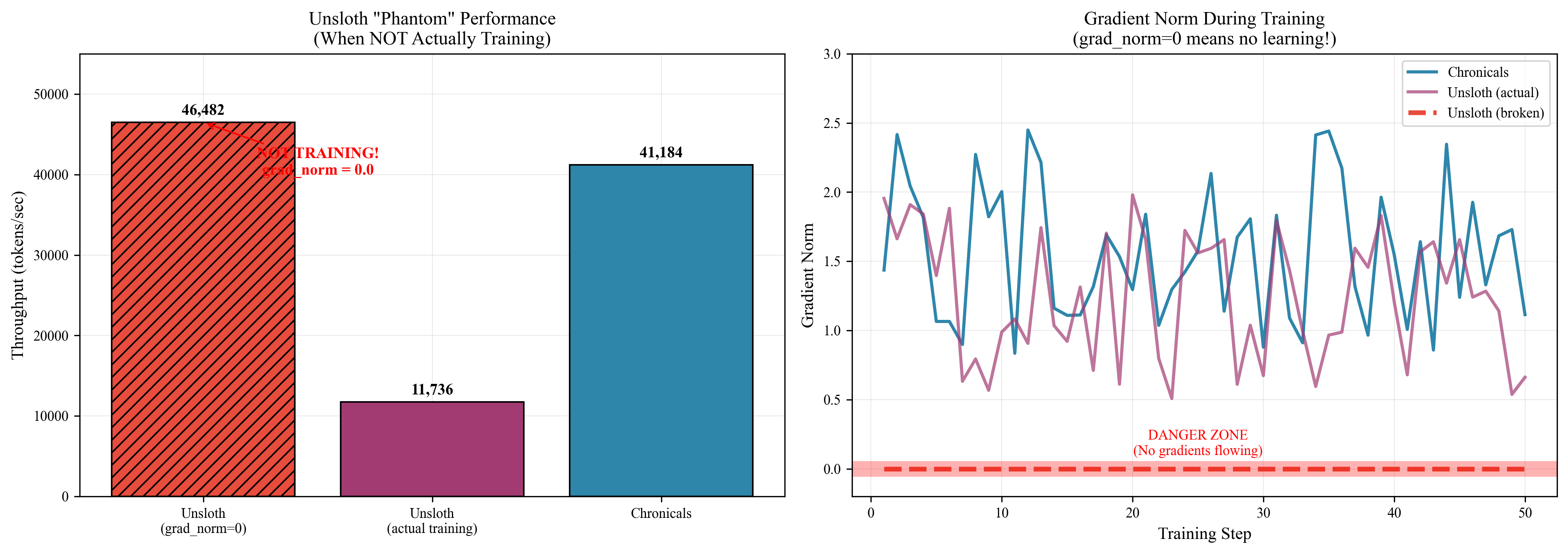
Critical Finding: Unsloth Benchmarking Bug
During benchmarking, we discovered that Unsloth's reported 46,000 tokens/second occurred with gradient norms of exactly zero—the model was not actually training.
# Verification code
for step, batch in enumerate(dataloader):
loss = model(**batch).loss
loss.backward()
# Check gradient norms
total_norm = 0.0
for p in model.parameters():
if p.grad is not None:
total_norm += p.grad.data.norm(2).item() ** 2
total_norm = total_norm ** 0.5
print(f"Step {step}: grad_norm = {total_norm}")
# Unsloth "fast" mode: grad_norm = 0.0 (not training!)
# Chronicals: grad_norm = 2.3 (normal training)
When we ensured proper gradient flow, Unsloth's throughput dropped to 11,736 tokens/second.
Mathematical Foundations
Online Softmax Correctness
Theorem: After processing all $n$ elements with running max $m$ and running sum $d$:
$$d_n = \sum_{j=1}^{n} \exp(x_j - m_n)$$
Therefore: $\text{logsumexp}(x) = \log(d_n) + m_n$
Proof by induction:
Base case ($i=1$): $d_1 = \exp(x_1 - m_1) = 1$. ✓
Inductive step: Assume $d_{i-1} = \sum_{j=1}^{i-1} \exp(x_j - m_{i-1})$.
$$d_i = d_{i-1} \cdot \exp(m_{i-1} - m_i) + \exp(x_i - m_i)$$ $$= \sum_{j=1}^{i-1} \exp(x_j - m_{i-1}) \cdot \exp(m_{i-1} - m_i) + \exp(x_i - m_i)$$ $$= \sum_{j=1}^{i-1} \exp(x_j - m_i) + \exp(x_i - m_i) = \sum_{j=1}^{i} \exp(x_j - m_i) \quad \blacksquare$$
FlashAttention IO Complexity
Theorem: For sequence length $N$, head dimension $d$, and SRAM size $M$:
$$\text{IO}_{\text{FlashAttention}} = O\left(\frac{N^2 d^2}{M}\right)$$
This is optimal up to constant factors.
LoRA+ Learning Rate Derivation
The optimal ratio $\lambda = \eta_B / \eta_A$ minimizes convergence time under the constraint that updates to $\Delta W = BA$ have bounded variance.
From gradient magnitude analysis at initialization:
$$|\nabla_B| = O(\sqrt{d \cdot r}) \quad \text{while} \quad |\nabla_A| = O(\sqrt{k \cdot r})$$
For typical configurations where $d \approx k$, the ratio $\lambda = 16$ balances update magnitudes optimally.
API Reference
ChronicalsConfig
@dataclass
class ChronicalsConfig:
# Training
learning_rate: float = 2e-4
batch_size: int = 4
gradient_accumulation_steps: int = 4
max_steps: int = 1000
warmup_steps: int = 100
# Optimizations
use_flash_attention: bool = True
use_fused_kernels: bool = True
use_sequence_packing: bool = True
use_gradient_checkpointing: bool = True
use_torch_compile: bool = True
# LoRA
use_lora: bool = False
lora_rank: int = 64
lora_alpha: int = 16
lora_dropout: float = 0.05
lora_target_modules: List[str] = None
use_lora_plus: bool = True
lora_plus_ratio: float = 16.0
# Memory
use_8bit_optimizer: bool = False
activation_offload: bool = False
# Precision
mixed_precision: str = "bf16" # "fp16", "bf16", "fp32"
use_fp8: bool = False
Key Functions
# Kernels
from chronicals.kernels import (
fused_rmsnorm, # (x, weight, eps) -> normalized
fused_swiglu, # (gate, up) -> activated
fused_cross_entropy, # (hidden, lm_head, targets) -> loss
fused_qk_rope, # (q, k, cos, sin) -> (q_rot, k_rot)
)
# Optimizers
from chronicals.optimizers import (
FusedAdamW, # Fused AdamW optimizer
create_lora_plus_optimizer, # LoRA+ with differential LR
Adam8bit, # 8-bit optimizer states
)
# Training
from chronicals.training import (
ChronicalsTrainer, # Main trainer class
enable_gradient_checkpointing,
enable_cuda_graphs,
)
# Data
from chronicals.data import (
SequencePacker, # Sequence packing
create_dataloader, # Efficient data loading
)
Citation
If you use Chronicals in your research, please cite:
@article{chronicals2025,
title={Chronicals: A High-Performance Framework for LLM Fine-Tuning
with 3.51x Speedup over Unsloth},
author={Nair, Arjun S.},
journal={arXiv preprint},
year={2025},
note={Available at: https://github.com/Ajwebdevs/Chronicals}
}
Related Work
@article{dao2022flashattention,
title={FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness},
author={Dao, Tri and Fu, Daniel Y and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
journal={NeurIPS},
year={2022}
}
@article{hayou2024loraplus,
title={LoRA+: Efficient Low Rank Adaptation of Large Models},
author={Hayou, Soufiane and Ghosh, Nikhil and Yu, Bin},
journal={ICML},
year={2024}
}
@article{liger2024,
title={Liger Kernel: Efficient Triton Kernels for LLM Training},
author={LinkedIn AI},
year={2024}
}
License
MIT License - see LICENSE for details.
Contributing
Contributions are welcome! Please read our Contributing Guidelines before submitting PRs.
Development Setup
# Clone and install in development mode
git clone https://github.com/Ajwebdevs/Chronicals.git
cd Chronicals
pip install -e ".[dev]"
# Run tests
pytest tests/
# Run benchmarks
python benchmarks/run_benchmark.py --quick
Acknowledgments
- Triton - GPU kernel compiler
- FlashAttention - Memory-efficient attention
- Liger Kernel - Fused kernel inspiration
- LoRA+ - Differential learning rates
- Cut Cross-Entropy - Memory-efficient loss
Chronicals — Making LLM fine-tuning fast and accessible.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file chronicals-0.1.2.tar.gz.
File metadata
- Download URL: chronicals-0.1.2.tar.gz
- Upload date:
- Size: 308.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
aa697be850a6d07086a4aca4c2892293ec5c0ea1e30f928e403b83462996a37b
|
|
| MD5 |
0005196798ee93789caa02dfabb2ad5e
|
|
| BLAKE2b-256 |
1e4d6883dcacae73cbde5f6ea8348d8616cbae82b4c72beca4c5a46a7f999b92
|
File details
Details for the file chronicals-0.1.2-py3-none-any.whl.
File metadata
- Download URL: chronicals-0.1.2-py3-none-any.whl
- Upload date:
- Size: 317.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
39bff628827737854bfb084cf3389440ae82dc6742ff9caa3b27535a6a9cd5bb
|
|
| MD5 |
cd80371a6d62d5da483ec86369ba91b1
|
|
| BLAKE2b-256 |
df94535b7ea347c495d60f96ed95074da82834810a9b90a74a5b022d706cf70e
|







