ClearML Agent - Auto-Magical DevOps for Deep Learning


Project description

ClearML Agent - MLOps/LLMOps made easy
MLOps/LLMOps scheduler & orchestration solution supporting Linux, macOS and Windows





🌟 ClearML is open-source - Leave a star to support the project! 🌟
ClearML-Agent
Formerly known as Trains Agent
- Run jobs (experiments) on any local or cloud based resource
- Implement optimized resource utilization policies
- Deploy execution environments with either virtualenv or fully docker containerized with zero effort
- Launch-and-Forget service containers
- Cloud autoscaling
- Customizable cleanup
- Advanced pipeline building and execution
It is a zero configuration fire-and-forget execution agent, providing a full ML/DL cluster solution.
Full Automation in 5 steps
- ClearML Server self-hosted or free tier hosting
pip install clearml-agent(install the ClearML Agent on any GPU machine: on-premises / cloud / ...)- Create a job or add ClearML to your code with just 2 lines of code
- Change the parameters in the UI & schedule for execution (or automate with an AutoML pipeline)
- :chart_with_downwards_trend: :chart_with_upwards_trend: :eyes: :beer:
"All the Deep/Machine-Learning DevOps your research needs, and then some... Because ain't nobody got time for that"
Try ClearML now Self Hosted
or Free tier Hosting
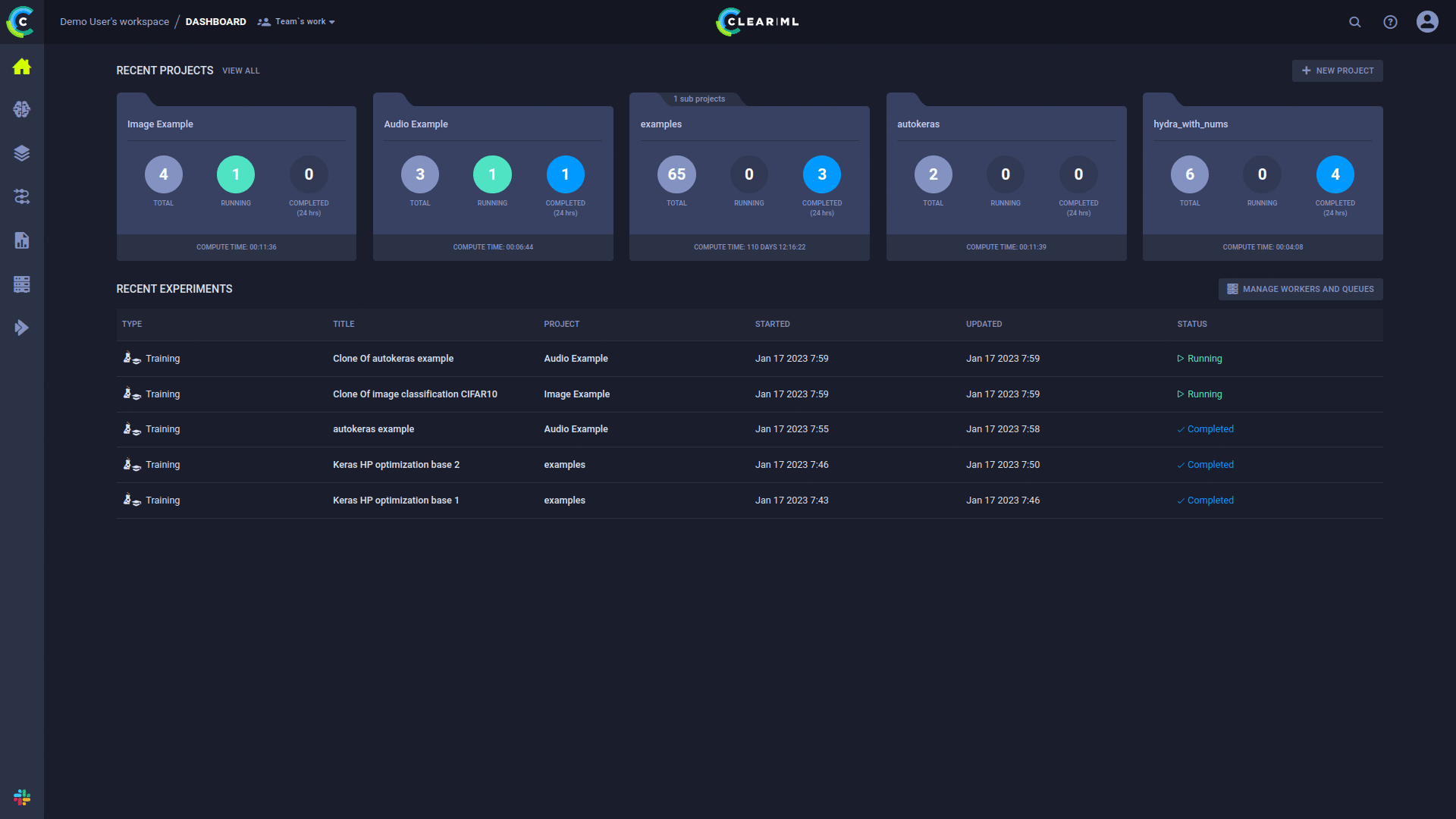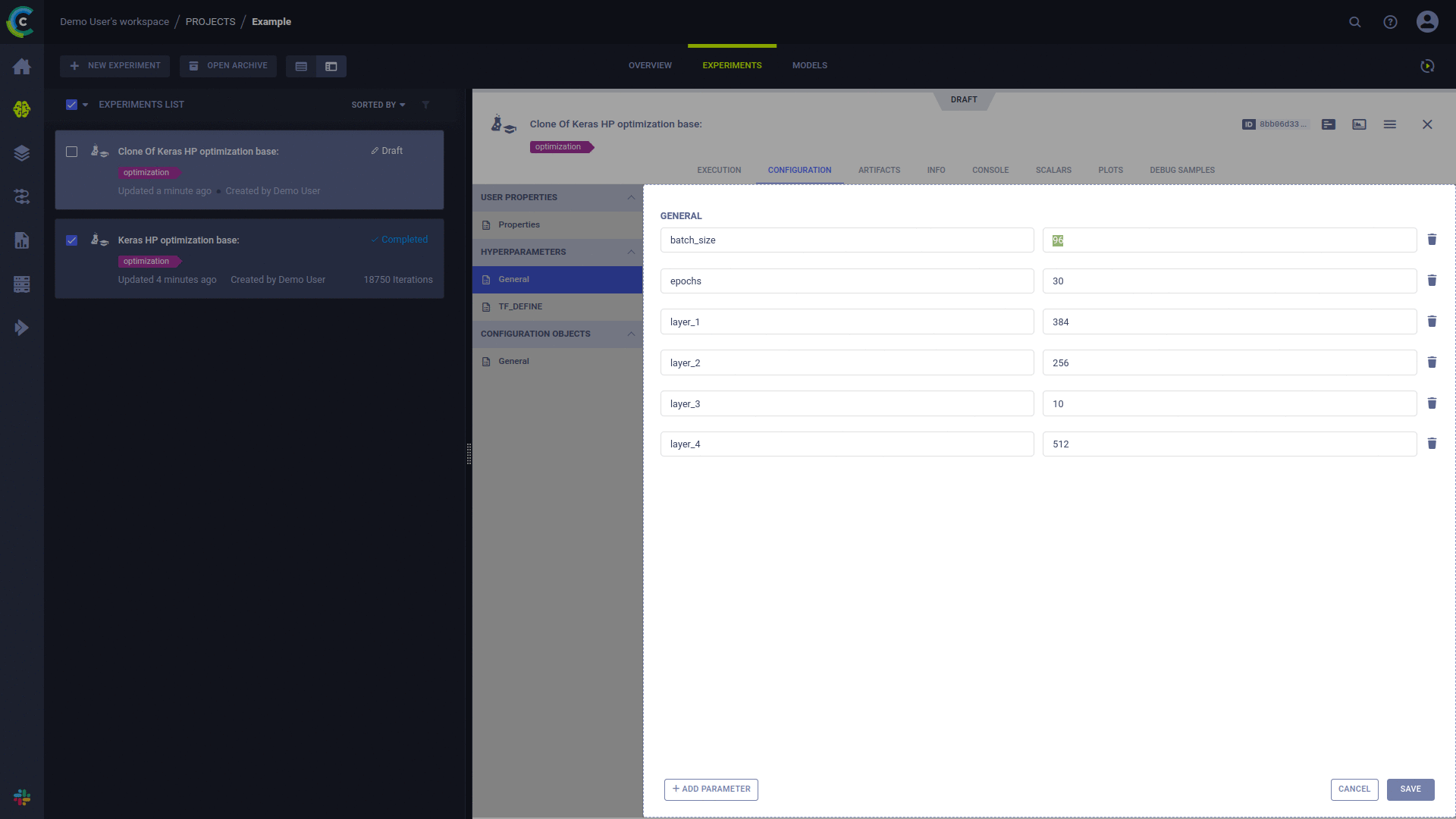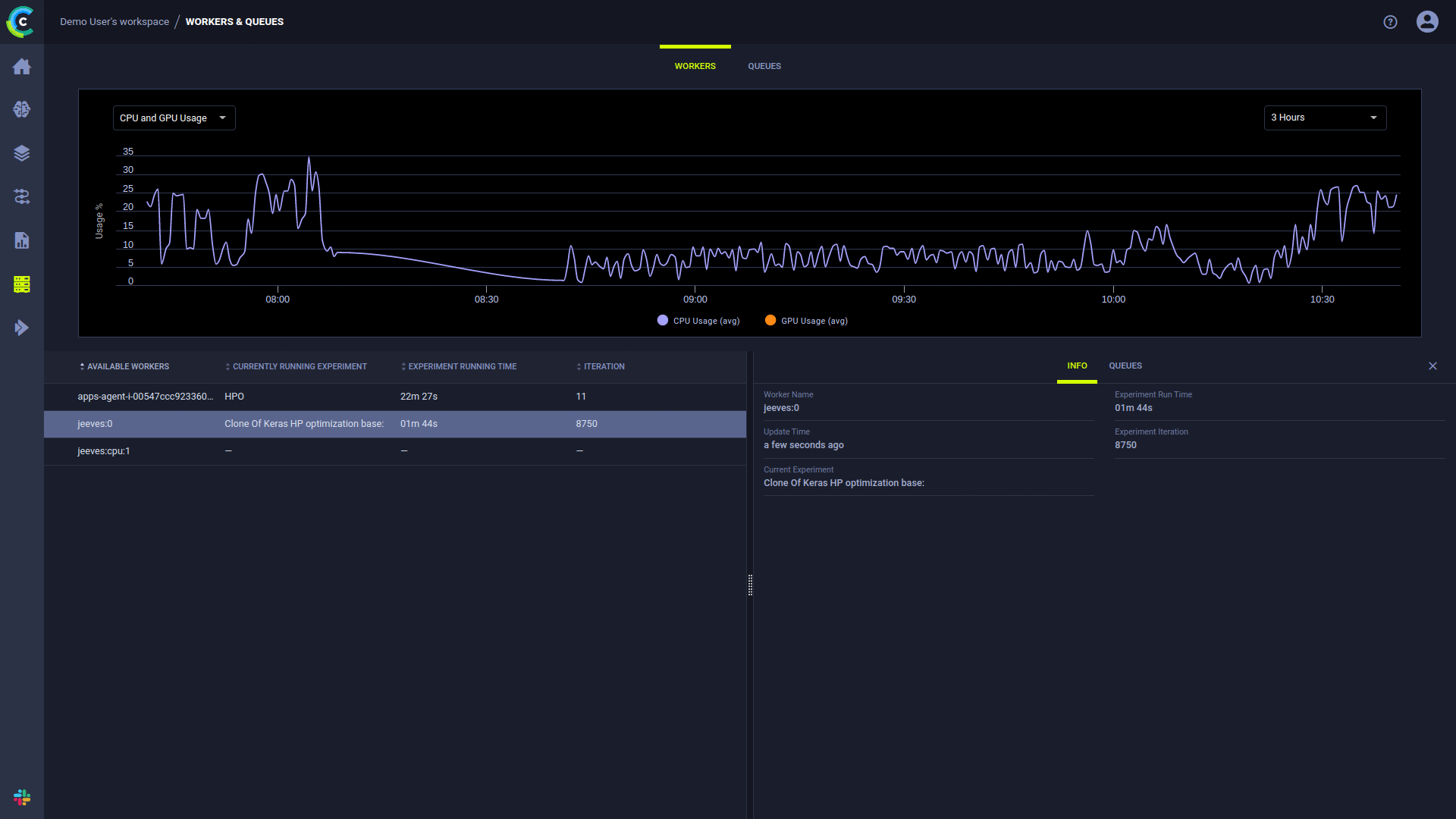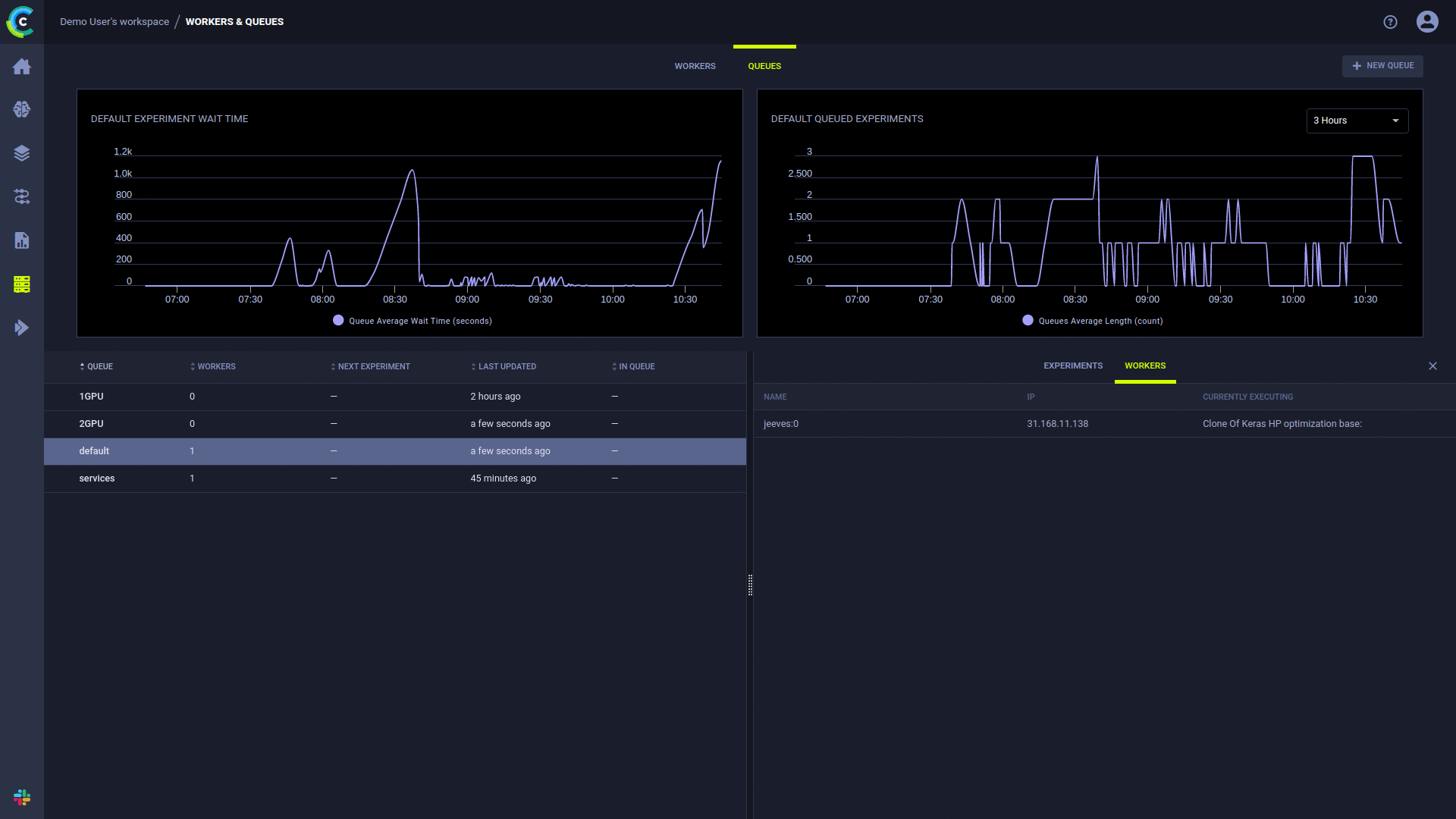
Simple, Flexible Experiment Orchestration
The ClearML Agent was built to address the DL/ML R&D DevOps needs:
- Easily add & remove machines from the cluster
- Reuse machines without the need for any dedicated containers or images
- Combine GPU resources across any cloud and on-prem
- No need for yaml / json / template configuration of any kind
- User friendly UI
- Manageable resource allocation that can be used by researchers and engineers
- Flexible and controllable scheduler with priority support
- Automatic instance spinning in the cloud
Using the ClearML Agent, you can now set up a dynamic cluster with *epsilon DevOps
*epsilon - Because we are :triangular_ruler: and nothing is really zero work
Kubernetes Integration (Optional)
We think Kubernetes is awesome, but it is not a must to get started with remote execution agents and cluster management.
We designed clearml-agent so you can run both bare-metal and on top of Kubernetes, in any combination that fits your environment.
You can find the Dockerfiles in the docker folder and the helm Chart in https://github.com/clearml/clearml-helm-charts
Benefits of integrating existing Kubernetes cluster with ClearML
- ClearML-Agent adds the missing scheduling capabilities to your Kubernetes cluster
- Users do not need to have direct Kubernetes access!
- Easy learning curve with UI and CLI requiring no DevOps knowledge from end users
- Unlike other solutions, ClearML-Agents work in tandem with other customers of your Kubernetes cluster
- Allows for more flexible automation from code, building pipelines and visibility
- A programmatic interface for easy CI/CD workflows, enabling GitOps to trigger jobs inside your cluster
- Seamless integration with the ClearML ML/DL/GenAI experiment manager
- Web UI for customization, scheduling & prioritization of jobs
- Enterprise Features: RBAC, vault, multi-tenancy, scheduler, quota management, fractional GPU support
Run the agent in Kubernetes Glue mode an map ClearML jobs directly to K8s jobs:
- Use the ClearML Agent Helm Chart to spin an agent pod acting as a controller
- Or run the clearml-k8s glue on a Kubernetes cpu node
- The clearml-k8s glue pulls jobs from the ClearML job execution queue and prepares a Kubernetes job (based on provided yaml template)
- Inside each pod the clearml-agent will install the job (experiment) environment and spin and monitor the experiment's process, fully visible in the clearml UI
- Benefits: Kubernetes full view of all running jobs in the system
- Enterprise Features
- Full scheduler features added on Top of Kubernetes, with quota/over-quota management, priorities and order.
- Fractional GPU support, allowing multiple isolated containers sharing the same GPU with memory/compute limit per container
SLURM (Optional)
Yes! Slurm integration is available, check the documentation for further details
Using the ClearML Agent
Full scale HPC with a click of a button
The ClearML Agent is a job scheduler that listens on job queue(s), pulls jobs, sets the job environments, executes the job and monitors its progress.
Any 'Draft' experiment can be scheduled for execution by a ClearML agent.
A previously run experiment can be put into 'Draft' state by either of two methods:
- Using the 'Reset' action from the experiment right-click context menu in the ClearML UI - This will clear any results and artifacts the previous run had created.
- Using the 'Clone' action from the experiment right-click context menu in the ClearML UI - This will create a new 'Draft' experiment with the same configuration as the original experiment.
An experiment is scheduled for execution using the 'Enqueue' action from the experiment right-click context menu in the ClearML UI and selecting the execution queue.
See creating an experiment and enqueuing it for execution.
Once an experiment is enqueued, it will be picked up and executed by a ClearML Agent monitoring this queue.
The ClearML UI Workers & Queues page provides ongoing execution information:
- Workers Tab: Monitor you cluster
- Review available resources
- Monitor machines statistics (CPU / GPU / Disk / Network)
- Queues Tab:
- Control the scheduling order of jobs
- Cancel or abort job execution
- Move jobs between execution queues
What The ClearML Agent Actually Does
The ClearML Agent executes experiments using the following process:
- Create a new virtual environment (or launch the selected docker image)
- Clone the code into the virtual-environment (or inside the docker)
- Install python packages based on the package requirements listed for the experiment
- Special note for PyTorch: The ClearML Agent will automatically select the torch packages based on the CUDA_VERSION environment variable of the machine
- Execute the code, while monitoring the process
- Log all stdout/stderr in the ClearML UI, including the cloning and installation process, for easy debugging
- Monitor the execution and allow you to manually abort the job using the ClearML UI (or, in the unfortunate case of a code crash, catch the error and signal the experiment has failed)
System Design & Flow

Installing the ClearML Agent
pip install clearml-agent
ClearML Agent Usage Examples
Full Interface and capabilities are available with
clearml-agent --help
clearml-agent daemon --help
Configuring the ClearML Agent
clearml-agent init
Note: The ClearML Agent uses a cache folder to cache pip packages, apt packages and cloned repositories. The default
ClearML Agent cache folder is ~/.clearml.
See full details in your configuration file at ~/clearml.conf.
Note: The ClearML Agent extends the ClearML configuration file ~/clearml.conf.
They are designed to share the same configuration file, see example here
Running the ClearML Agent
For debug and experimentation, start the ClearML agent in foreground mode, where all the output is printed to screen:
clearml-agent daemon --queue default --foreground
For actual service mode, all the stdout will be stored automatically into a temporary file (no need to pipe).
Notice: with --detached flag, the clearml-agent will be running in the background
clearml-agent daemon --detached --queue default
GPU allocation is controlled via the standard OS environment NVIDIA_VISIBLE_DEVICES or --gpus flag (or disabled
with --cpu-only).
If no flag is set, and NVIDIA_VISIBLE_DEVICES variable doesn't exist, all GPUs will be allocated for
the clearml-agent.
If --cpu-only flag is set, or NVIDIA_VISIBLE_DEVICES="none", no gpu will be allocated for
the clearml-agent.
Example: spin two agents, one per GPU on the same machine:
Notice: with --detached flag, the clearml-agent will run in the background
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default
Example: spin two agents, pulling from dedicated dual_gpu queue, two GPUs per agent
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu
Starting the ClearML Agent in docker mode
For debug and experimentation, start the ClearML agent in foreground mode, where all the output is printed to screen
clearml-agent daemon --queue default --docker --foreground
For actual service mode, all the stdout will be stored automatically into a file (no need to pipe).
Notice: with --detached flag, the clearml-agent will run in the background
clearml-agent daemon --detached --queue default --docker
Example: spin two agents, one per gpu on the same machine, with default nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
docker:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
Example: spin two agents, pulling from dedicated dual_gpu queue, two GPUs per agent, with default
nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 docker:
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
Starting the ClearML Agent - Priority Queues
Priority Queues are also supported, example use case:
High priority queue: important_jobs, low priority queue: default
clearml-agent daemon --queue important_jobs default
The ClearML Agent will first try to pull jobs from the important_jobs queue, and only if it is empty, the agent
will try to pull from the default queue.
Adding queues, managing job order within a queue, and moving jobs between queues, is available using the Web UI, see example on our free server
Stopping the ClearML Agent
To stop a ClearML Agent running in the background, run the same command line used to start the agent with --stop
appended. For example, to stop the first of the above shown same machine, single gpu agents:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stop
ClearML Agent Bootstrap
Bootstrap is supported when using ClearML Agent version
3.0.0and up.
The clearml-agent-bootstrap package is a self-contained
initialization system that runs inside any container launched by the ClearML Agent. It ships precompiled binaries for
Python, Git, ClearML Agent, and essential utilities, so task containers do not need these tools
pre-installed.
When the agent launches a containerized task, the bootstrap script runs first: it detects the container's architecture and distribution, sets up a working Python environment, ensures Git is available, and then hands off to the ClearML Agent to execute the task.
Why use it
- Faster cold starts — precompiled binaries avoid slow package-manager installs at task launch time.
- Broader container compatibility — tasks can run in minimal images (Alpine, slim, distroless-adjacent) that lack Python or Git.
- Consistent environments — every task gets the same known-good toolchain regardless of the base image.
- Offline support — all critical binaries are bundled, no internet access is required for the initial setup.
Supports x86_64 and aarch64 architectures on any Linux distribution that provides apt-get, dnf, yum, or apk
(Ubuntu, Debian, CentOS, RHEL, Fedora, Rocky Linux, Alpine, ...).
Bare-metal / VM usage
Install the agent (version 3.0.0 and up) and then install the bootstrap support:
pip install clearml-agent
clearml-agent install-bootstrap
This downloads the latest clearml-agent-bootstrap distribution and installs it locally. From this point on, when the
agent runs in docker mode, it will automatically unpack the bootstrap binaries, mount them into task containers, and
make sure the bootstrap script runs on container startup. The install-bootstrap command does not require a ClearML
server connection and can be run before clearml-agent init.
Common flags:
--check— preview a dry-run of the command without making changes.--force— force reinstall even if the same version is already installed.--version TAG— install a specific release version (e.g.,v1.0.0).--from-file PATH— install from a local.whlfile instead of downloading from the official GitHub Releases.
Kubernetes (Enterprise Helm chart)
Bootstrap support for Kubernetes is available only in the ClearML Enterprise Agent Helm chart.
Enable bootstrap in your clearml-agent-values.override.yaml:
bootstrap:
enabled: true
More details
See the agent-bootstrap README and the ClearML Agent Bootstrap docs for full details.
How do I create an experiment on the ClearML Server?
-
Integrate ClearML with your code
-
Execute the code on your machine (Manually / PyCharm / Jupyter Notebook)
-
As your code is running, ClearML creates an experiment logging all the necessary execution information:
- Git repository link and commit ID (or an entire jupyter notebook)
- Git diff (we’re not saying you never commit and push, but still...)
- Python packages used by your code (including specific versions used)
- Hyperparameters
- Input artifacts
You now have a 'template' of your experiment with everything required for automated execution
-
In the ClearML UI, right-click on the experiment and select 'clone'. A copy of your experiment will be created.
-
You now have a new draft experiment cloned from your original experiment, feel free to edit it
- Change the hyperparameters
- Switch to the latest code base of the repository
- Update package versions
- Select a specific docker image to run in (see docker execution mode section)
- Or simply change nothing to run the same experiment again...
-
Schedule the newly created experiment for execution: right-click the experiment and select 'enqueue'
ClearML-Agent Services Mode
ClearML-Agent Services is a special mode of ClearML-Agent that provides the ability to launch long-lasting jobs that previously had to be executed on local / dedicated machines. It allows a single agent to launch multiple dockers (Tasks) for different use cases:
- Auto-scaler service (spinning instances when the need arises and the budget allows)
- Controllers (Implementing pipelines and more sophisticated DevOps logic)
- Optimizer (such as Hyperparameter Optimization or sweeping)
- Application (such as interactive Bokeh apps for increased data transparency)
ClearML-Agent Services mode will spin any task enqueued into the specified queue. Every task launched by ClearML-Agent Services will be registered as a new node in the system, providing tracking and transparency capabilities. Currently, clearml-agent in services-mode supports CPU only configuration. ClearML-Agent services mode can be launched alongside GPU agents.
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-only
Note: It is the user's responsibility to make sure the proper tasks are pushed into the specified queue.
AutoML and Orchestration Pipelines
The ClearML Agent can also be used to implement AutoML orchestration and Experiment Pipelines in conjunction with the ClearML package.
Sample AutoML & Orchestration examples can be found in the ClearML example/automation folder.
AutoML examples:
- Toy Keras training experiment
- In order to create an experiment-template in the system, this code must be executed once manually
- Random Search over the above Keras experiment-template
- This example will create multiple copies of the Keras experiment-template, with different hyperparameter combinations
Experiment Pipeline examples:
- First step experiment
- This example will "process data", and once done, will launch a copy of the 'second step' experiment-template
- Second step experiment
- In order to create an experiment-template in the system, this code must be executed once manually
License
Apache License, Version 2.0 (see the LICENSE for more information)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file clearml_agent-3.0.3-py3-none-any.whl.
File metadata
- Download URL: clearml_agent-3.0.3-py3-none-any.whl
- Upload date:
- Size: 1.4 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.10.0 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/1.0.0 urllib3/1.26.20 tqdm/4.64.1 importlib-metadata/4.8.3 keyring/23.4.1 rfc3986/1.5.0 colorama/0.4.5 CPython/3.6.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0f0f071f516c26df04e84e664d4f4dd95c6be26b85b5c64fb75122266abb0e77
|
|
| MD5 |
7f2551b586e9d944c4a445ffab01b788
|
|
| BLAKE2b-256 |
633d58aa24788f132f93d34b60d5081f21ae3c20b74deec21cd3a21cee321c1f
|







