Probabilistic models of user behavior on a search engine result page

Project description
ClickModels
ClickModels is a small set of Python scripts for the user click models initially developed at Yandex. A Click Model is a probabilistic graphical model used to predict search engine click data from past observations. This project is aimed to deal with click models used in Information Retrieval (see next section) and intended to be easy-to-read and easy-to-modify. If it’s not, please let me know how to improve it :)
If you are using this code for your research work, consider citing one of our papers when appropriate (see References section below).
If you are looking for a general-purpose framework to work with probabilistic graphical models you might want to examine Infer.NET. It should also work with IronPython.
Quick Start
cp clickmodels/config_sample.py config.py
vim config.py
python bin/run_inference.py < data/click_log_sample.tsv 2>inference.log
More details about the config and input data formats below.
System-Wide Install
If you wish, you can install the ClickModels core (parameter inference and click simulation) to a system-wide location:
sudo python setup.py install
Uninstall:
sudo pip uninstall clickmodels
New!
Now, thanks to agrotov, the models can also be run in a click generation mode and predict relevance (DBN only). Check out ClickModel.get_model_relevances() and ClickModels.generate_clicks() methods.
N.B.: Use this code with care as it is not fully tested yet.
Models Implemented
Dynamic Bayesian Network ( DBN ) model: Chapelle, O. and Zhang, Y. 2009. A dynamic bayesian network click model for web search ranking. WWW (2009).
User Browsing Model ( UBM ): Dupret, G. and Piwowarski, B. 2008. A user browsing model to predict search engine click data from past observations. SIGIR (2008).
Exploration Bias User Browsing Model ( EB_UBM ): Chen, D. et al. 2012. Beyond ten blue links: enabling user click modeling in federated web search. WSDM (2012).
Dependent Click Model ( DCM ): Guo, F. et al. 2009. Efficient multiple-click models in web search. WSDM (2009).
Intent-Aware Models ( DBN-IA, UBM-IA, EB_UBM-IA, DCM-IA ): Chuklin, A. et al. 2013. Using Intent Information to Model User Behavior in Diversified Search. ECIR (2013).
Format of the Input Data (Click Log)
A small example can be found under data/click_log_sample.tsv. This is a tab-separated file, where each line has 7 elements. For example, the line 1dd100500 QUERY1 50 0.259109 ["http://1", "http://2", "http://3","http://4","http://5","http://6","http://7","http://8","http://9","Http://10"] [false, false, false, false, true, true, false, false, false, false] [0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0] has the following fields:
1dd100500 — some identifier (currently not used)
QUERY1 — text of the query. It can contain any UTF-8 characters except tab sign \t
50 — integer identifier of the region (country, city) of the user who submitted the query. If you don’t want this, just put some constant (e.g., ``0``) in this column. At Yandex user region is heavily used by ranking, so throughout the code the pair (query, region) is used to identify the query, i.e., if we have the same query string from two different region we consider them as two separate queries.
0.259109 — float value, corresponding to the probability P(I = V) that user has a vertical intent V, i.e., he or she is interested more in the vertical documents than in organic web documents. If you do not want any of this intent stuff just put ``0`` in this column. We assume that the user has one of the two intents: vertical intent V with probability P(I = V) and regular web intent with probability 1 - P(I = V). For example, if we want to take into account user’s interest in images and we somehow know the probability that the user is interested more in images than organic web results, we can make use of intent-aware click models. See Chuklin, A. et al. 2013. Using Intent Information to Model User Behavior in Diversified Search. ECIR (2013) for more details.
json list of the URLs of the documents that make up SERP (search engine result page). Document’s url is an identifier, so in principle you can use any (string) id you want. NB: this is not a python list, so yuo have to use double quotes and no comma after the last element.
json list with the presentation types (vertical types) of the documents (see Chuklin, A. et al. 2013. Using Intent Information to Model User Behavior in Diversified Search. ECIR (2013).). If you do not want to know this just set it to the list of false of the same length as the previous list.
json list of clicks. Each element is the number of times corresponding URL was clicked
If you need more data to experiment with you can use any publicly available dataset and convert it to the format described above. For example, you can use a dataset provided by one of the Yandex challenges (you need to register to get access to the data): - http://imat-relpred.yandex.ru/en/datasets - http://switchdetect.yandex.ru/en/datasets
Files
README.md
This file.
setup.py
Python package installation file: python setup.py --help
bin/
Directory with the scripts.
clickmodels/
Directory with the core code. This is the directory that gets installed by setup.py.
data/
data/ directory contains an example of click log (see format description above) as well as two examples of result pages with fresh block included (see makeGluedSERP.py description above): data/serp_sample.json is used in an example above, while data/serp_sample2.json was used to create a picture in the paper Chuklin, A. et al. 2013. Using Intent Information to Model User Behavior in Diversified Search. ECIR (2013).
doc/
Automaticaly generated documentation. Also available online.
html/
Directory with the CSS/JS files for bin/generate_serp.py; it outputs there a number of HTML files for you to examine to get an idea what kind of SERPs we address with the intent-aware click models.
bin/generate_serp.py
{not used by the other, does not use other code} Create html of the SERP containing fresh block item. This is used just to illustrate the notion of presentation types used by Intent-Aware models. Run as: bin/generate_serp.py < data/serp_sample.json. Output is placed in html/ directory.
WARNING: all previously generated html files in this directory will be removed
bin/compare_click_models.py
{not used by other scripts} Script used to compare different models and output significance of the difference. The pair of models to compare is specified in the code by modifying TESTED_MODEL_PAIRS variable. Model pair is a text string which is mapped to the pair of functions returning model objects (see MODEL_CONSTRUCTORS dict for the mapping). E.g. UBMvsDBN is used to compare UBM model (UbmModel()) to the default DBN model (DbnModel((0.9, 0.9, 0.9, 0.9))). NB: we may have a list of models needed to be compared to each other. For this purpose the same notion of pair is abused. For instance, MODEL_CONSTRUCTORS['EB_UBM'] contains 3 algorithms to be compared to each other: UBM, EB_UBM, EB_UBM-IA.
Usage: bin/compare_click_models.py directory_with_click_logs 2>run.log
Input: directory_with_click_logs — directory containing files with click logs. Each file is in the format described above. These files are then sorted alphabetically and split into pairs where first file is used for training, the second one is used for testing. For example, if the directory contains files f01, f02, f03, f04 then f02 will be used to test models trained using f01, f04 will be used to test models trained using f03 and so on. Two models are evaluated on the test set and their performances (Average Perplexity or Log Likelihood) are compared using appropriate formula (see perpGain and llGain functions respectively). NB: Multiple train and test files are needed to calculate confidence interval for the gains (bootstrap.py is used for this purpose).
Output: some progress output is printend to sys.stderr which might be useful for a long run. Finally the gains of one model over another is output in the following format:
UBM (0, 1) [-0.0115, 0.0659, 0.075, 0.0778, 0.0623, 0.0403, 0.0593, -0.040] (0.0095, 0.0662)
It first outputs the name of the “pair” pairName specified in the TESTED_MODEL_PAIRS, then pair of indeces (i, j) which mean that the model compared are MODEL_CONSTRUCTORS[pairName][i] and MODEL_CONSTRUCTORS[pairName][j] which is UBM and UBM-IA in our example. Next is the list of gains of model j over model i for each pair of the train/test logs (in our example we had 8 pairs of files under directory_with_click_logs). The next element is the confidence interval according to bootstrap test (with 95% confidence level and 1000 bootstrap samples). This line will be printed for all the “pairs” listed under TESTED_MODEL_PAIRS and for both Average Perplexity (PERPLEXITY) and Log Likelihood (LL). For perplexity measure also the gains for individual position (rank) are printed. Like this: UBM POSITION PERPLEXITY GAINS: (0, 1) [[average_gain_for_pos1, confidence_interval_for_pos_1], …]
bin/run_inference.py
Run click model inference and evaluate the models:
Usage: bin/run_inference.py < data/click_log_sample.tsv 2>inference.log
Input: click log in the format described above (sys.stdin)
Output (assuming that TRAIN_FOR_METRIC = False): ModelName (LogLikelihood, Perplexity)
clickmodels/inference.py
This file contains implementation of all the click models, probabilistic inference and helper functions needed to work with them. This is the core of the codebase. More details about the classes/functions below.
clickmodels/bootstrap.py
Copyright © Ernesto P. Adorio: code we use to perform a bootstrap test.
clickmodels/config_sample.py
Copy this file to config.py and modify it; it will be used by bin/run_inference.py and bin/compare_click_models.py. This is the file with default settings for different parameters of the inference, input and output data.
MAX_ITERATIONS — maximum number of iterations in Expectation Maximization (EM) algorithm (applicable only for models using EM algorithm).
DEBUG — perform some additional tests when running algorithm (makes it slower)
PRETTY_LOG — make log output prettier. If False then more information is put into log.
USED_MODELS — list of model names to be tested in __main__ section of the script. Possible names are ['Baseline', 'SDBN', 'UBM', 'UBM-IA', 'EB_UBM', 'EB_UBM-IA', 'DCM', 'DCM-IA', 'DBN', 'DBN-IA']. Please refer to the __main__ section of inference.py to see how these names are expressed in terms of our class hierarchy (all those nasty if 'XXX' in USED_MODELS).
MIN_DOCS_PER_QUERY, MAX_DOCS_PER_QUERY – number of documents per query. Set to 10 by default as most of search engines return list of 10 doucments.
SERP_SIZE - size of the search engine result page (SERP). Used if we want to model clicks beyond the first result page. See the section named Beyond the First Result Page below for more details.
EXTENDED_LOG_FORMAT - if set to True the urls, layout and clicks are dicts instead of lists (see Format of the Click Log section above). Example: data/click_log_sample_extended_format.tsv.
TRANSFORM_LOG - transform the click log by inserting the fake documents for pagination button (currently works only with EXTENDED_LOG_FORMAT = True). See the section named Beyond the First Result Page below.
QUERY_INDEPENDENT_PAGER - used to switch between SDBN(P) / SDBN(P-Q). Only used with TRANSFORM_LOG = True.
TRAIN_FOR_METRIC – if True the model will be trained such that its parameters can be used in a metric (like Chuklin, A. et al. 2013. Click Model-Based Information Retrieval Metrics. SIGIR (2013).). See the section below for more details.
PRINT_EBU_STATS — if True the parameters of the EBU metric will be printed first (Yilmaz, E. et al. 2010. Expected browsing utility for web search evaluation. CIKM. (2010)).
DEFAULT_REL - default (prior) relevance (attractiveness, satisfaction) parameter values used in click models like DBN or EBU.
clickmodels/input_reader.py
A class used for reading input data in a click log format described above.
Class Hierarchy
Also see epydoc-generated documentation.
Click Models
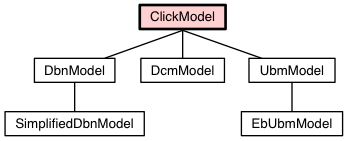
The base class for all the click models is the class called ClickModel. In order to define a new click model you should create a clas inherited from it and re-define methods train and _getClickProbs.
train function
Note, that test method is already implemented and uses _getClickProbs function. If you redefine __init__ method, then be sure to invoke the __init__ of the parent class to set the ignoreIntents and ignoreLayout parameters (they should be set to True unless you are using Intent Aware model)
ClickModel class by itself represents a baseline click model which sets probability 0.5 to any click event.
DbnModel
This class is, in fact an implementation of a more general DBN-IA model (Chuklin, A. et al. 2013. Using Intent Information to Model User Behavior in Diversified Search. ECIR (2013). ) that makes use of intent and presentation type of the documents when ignoreIntent and/or ignoreLayout is set to False. The train method is a probabilistic EM inference.
If all what you want is just original DBN model by Chapelle et al. you should creat it as DbnModel((0.9, 0.9, 0.9, 0.9)) (ignoreIntent and ignoreLayout is True by default).
SimplifiedDbnModel (DbnModel)
This is the same as DbnModel((1.0, 1.0, 1.0, 1.0), ignoreIntents, ignoreLayout), but train method is just counting instead of EM algorithm. See Chapelle, O. and Zhang, Y. 2009. A Dynamic Bayesian Network click model for web search ranking. WWW (2009)., Section 5 (Algorithm 1).
UbmModel
This is the most general case for all UBM-like intent-aware models. Changing ignoreIntents, ignoreLayout and explorationBias parameters you can get different models: UBM, UBM-intent, UBM-layout, UBM-IA, EB_UBM, EB_UBM-intent, EB_UBM-layout, EB_UBM-IA (for the names see Chuklin, A. et al. 2013. Using Intent Information to Model User Behavior in Diversified Search. ECIR (2013).).
EbUbmModel (UbmModel)
Just a shortcut for UbmModel(ignoreIntents, ignoreLayout, explorationBias=True) which correspond to the model called Exploration Bias UBM in Chen, D. et al. 2012. Beyond ten blue links: enabling user click modeling in federated web search. WSDM (2012).
DcmModel
This model is, again, more general DCM-IA model which reduces to DCM when ignoreIntents = True, ignoreLayout = True. train method is a simple counting, no EM algorithm.
Please note, that getGamma method invokes DbnModel.getGamma, so be careful when changing that.
InputReader
This class intented to read input (click log) in the format described above. To save memory, it maps queries and urls to ids. It means, that you need to use the same instance of the InputReader class even if you read multiple click log files. Otherwise you will end up with two different ids assigned to the same query.
Performance Issues
If you experience performance issues consider using PyPy instead of regular cPython. It may lead to 10x spead up. You can also install and use simplejson module instead of json.
TRAIN_FOR_METRIC
If you set TRAIN_FOR_METRIC = True the code will expect you to provide document relevances instead of URLs. We make an assumption, that document attractiveness and/or satisfaction probability only depends on its human-assigned relevance grade. A model will then be trained to assign the same attractiveness / satisfaction probabilities to all the documents with the same relevance.
Input Format
The format in this case is similar to the one descirbed above with only difference that URLs should be replaced by the relevance grade of the corresponding document to the corresponding query. The query field will be ignored in that case. The relevance grade should take one of the following values:
IRRELEVANT — lowest relevance scorn, document is not relevant to the query
RELEVANT — combines marginally relevant and just relevant documents
USEFUL — document is more than just relevant, it is really useful
VITAL — highest relevance score, the document is essential
Please note, that if you also have PRINT_EBU_STATS set to True, then the parameters of the EBU / rrDBN metric will be printed out first (these ones can be computed directly without need to train a model).
Output
For each model corresponding parametres will be printed out:
UBM — attractiveness probabilities alpha and position discount parameters gamma
DCM — attractiveness probabilities alpha (named as urlRelevances in the code) and position discount parameters gamma
For more conceptual details about converting click models into evaluation metrics please refer to the paper Chuklin, A. et al. 2013. Click Model-Based Information Retrieval Metrics. SIGIR (2013).
Beyond the First Result Page
If you want to model the clicks beyond the first result page you may want to model pagination button separately. We implemented the models described in the paper A. Chuklin, P. Serdyukov, and M. de Rijke. Modeling Clicks Beyond the First Result Page. In CIKM. ACM, 2013.. Namely, by setting the following config options you will get:
TRANSFORM_LOG = True, QUERY_INDEPENDENT_PAGER = False: SDBN(P) model
TRANSFORM_LOG = True, QUERY_INDEPENDENT_PAGER = True: SDBN(P-Q) model
TRANSFORM_LOG = False: reqular SDBN model
Please, refer to the paper for more details. ***
References
A. Chuklin, P. Serdyukov, and M. de Rijke. Using Intent Information to Model User Behavior in Diversified Search. In ECIR, 2013. [pdf]
A. Chuklin, P. Serdyukov, and M. de Rijke. Click model-based information retrieval metrics. In SIGIR. ACM, 2013. [pdf]
A. Chuklin, P. Serdyukov, and M. de Rijke. Modeling Clicks Beyond the First Result Page. In CIKM. ACM, 2013. [pdf]
Copyright and License
Copyright © Yandex 2012-2013, varepsilon 2012-∞
Published under the BSD license.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file clickmodels-1.0.2.tar.gz.
File metadata
- Download URL: clickmodels-1.0.2.tar.gz
- Upload date:
- Size: 21.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
419a1562f2c5d6d38289322ea55030b8f5d2fecc37e1c668ac0359ba19211cad
|
|
| MD5 |
90ded537733a5a078f872a69e4173362
|
|
| BLAKE2b-256 |
507cc40372822c8177febc6593d5b785f069b3ab2134c1b509de98036f5c41e7
|







