direct api via copilot to its large language models

Project description
co·la·la·mo
breaking :octocat: copilot out of ⛓️ IDE ⛓️
so it can tell me "why is the sky blue?"
🧬 what I do
GitHub Copilot is a well known piece of software that primarily lives inside IDE, as a plugin, and is able to help developers with autocomplete and code snippets.
At times it feels Copilot is quite lonely to exist "as an IDE plugin" only, since it not open to be:
- called as a function
- called via an HTTP call
this is where colalamo comes in, because, as they say:
"with every Copilot comes great Large Language Model that makes it work"
colalamo breaks Copilot free from the IDE, and makes it available:
- as a function call
- as a proxy server that accepts HTTP requests
By bringing Copilot closer to developers it opens it up to anything an LLM can do: communicating agents, retrieval augmented generation, creating and validate user stories, explaining several source files at once, etc.
🕹️ can I play?
of course!
in order to use colalamo, you'll need a Github Copilot subsciption.
it is free for open source use or/and you may have it from a company (i.e. a business subscription)
once/if you're subscribed you'll see something like this in your settings:
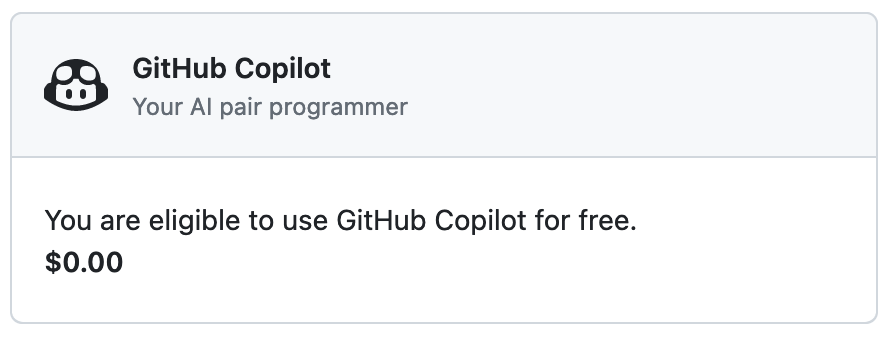
install me
$ pip install colalamo
ready to rock! :metal:
talk to me
colalamo can be used as a library or as an HTTP proxy server
as a library
when it is used as a library:
$ python
>>> from colalamo import Copilot
>>> copilot = Copilot()
>>>
>>> copilot.ask([{'content': 'how does murmur3 hash work?', 'role': 'user'}])
{'status': 200, 'text': {'reply': 'Murmur3 hash is a non-cryptographic hash function that takes an input (usually a string or binary data) and produces a fixed-size hash value as output. It was designed to be fast and efficient while providing a good distribution of hash values.\n\nHere is a simplified explanation of how Murmur3 hash works:\n\n1. Initialization: The hash function is initialized with a seed value, which is an arbitrary number chosen by the user.\n\n2. Chunking: The input data is divided into chunks of 4 bytes (32 bits) each. If the input length is not a multiple of 4, padding is added to the last chunk.\n\n3. Processing: Each chunk is processed individually. The hash function performs a series of bitwise operations, such as XOR, shift, and multiplication, on the chunk and the seed value. These operations are designed to mix the bits of the chunk and distribute them across the hash value.\n\n4. Finalization: After processing all the chunks, a finalization step is performed. It involves additional bitwise operations to further mix the bits and ensure a good distribution of the hash value.\n\n5. Output: The resulting hash value is returned as the output of the Murmur3 hash function.\n\nMurmur3 hash has several desirable properties, such as good distribution, low collision rate, and high performance. It is commonly used in applications like hash tables, bloom filters, and data indexing.', 'usage': {'completion_tokens': 286, 'prompt_tokens': 15, 'total_tokens': 301}}}
>>>
>>> ## parameters are very familiar with the ones from OpenAI API requests: top_p, temperature, n, etc.
>>> copilot.ask(messages = [{'content': 'how does murmur3 hash work?', 'role': 'user'}], temperature = 0.6)
{'status': 200, 'text': {'reply': 'MurmurHash3 is a non-cryptographic hash function that is designed to be fast and efficient while maintaining a good distribution of hash values. It was created by Austin Appleby in 2008.\n\nHere is a high-level overview of how MurmurHash3 works:\n\n1. Initialization: The hash function is initialized with a seed value that determines the output hash values.\n\n2. Chunk Processing: The input data is divided into fixed-length chunks (usually 4-byte or 8-byte chunks). These chunks are processed one at a time.\n\n3. Mixing: For each chunk, a series of bitwise operations, multiplications, and rotations are performed to mix the bits of the chunk. This mixing step helps to ensure that small changes in the input data result in significantly different hash values.\n\n4. Finalization: After all the chunks have been processed, a finalization step is performed to mix the remaining bits and produce the final hash value. This step typically involves applying additional bitwise operations and mixing the bits further.\n\n5. Output: The resulting hash value is returned as the output. It is usually a 32-bit or 64-bit integer, depending on the desired output size.\n\nMurmurHash3 is known for its speed and good distribution properties, making it suitable for a wide range of applications such as hash tables, hash-based data structures, and checksum verification. However, it is important to note that MurmurHash3 is not designed for cryptographic purposes, as it lacks the security properties required for cryptographic hash functions.', 'usage': {'completion_tokens': 307, 'prompt_tokens': 15, 'total_tokens': 322}}}
to check out the real use in the production code, see how jemma uses colalamo
as a server
when it is used as a server, after it is installed all that is needed is to call it:
$ colalamo
colalamo is listening on 0.0.0.0:4242
ask away at "/ask"
example: curl http://localhost:4242/ask -X POST -d '{"messages": [{"role": "user", "content": "explain how multi-head attention work"}]}'
and in a different terminal / HTTP client / IDE / server, etc.
$ curl http://localhost:4242/ask -X POST -d '{"messages": [{"role": "user", "content": "explain how multi-head attention work"}]}'
{
"reply": "Multi-head attention is a key component of the Transformer model, which is widely used in natural language processing tasks such as machine translation and text summarization. The main idea behind multi-head attention is to allow the model to focus on different parts of the input sequence simultaneously, capturing various aspects of the information.\n\nHere's a step-by-step explanation of how it works:\n\n1. **Linear Projections**: The input to the multi-head attention mechanism is a set of vectors (usually the embeddings of the words in a sentence). These vectors are linearly transformed into multiple sets of Query (Q), Key (K), and Value (V) vectors. Each set is called a \"head\". The number of heads is a hyperparameter of the model.\n\n2. **Scaled Dot-Product Attention**: For each head, the model computes the attention scores by taking the dot product of the Q and K vectors, and then scaling the result by the square root of the dimension of these vectors. This is to prevent the dot product from growing too large as the dimension increases. The attention scores indicate how much each word in the sentence should be attended to.\n\n3. **Softmax Normalization**: The attention scores are then passed through a softmax function to normalize them into probabilities. This ensures that the scores are positive and sum up to 1.\n\n4. **Weighted Sum**: The softmax output is used to weight the V vectors. The weighted sum of the V vectors is the output of each head.\n\n5. **Concatenation**: The outputs of all heads are concatenated and linearly transformed to produce the final output.\n\nThe multi-head attention mechanism allows the model to capture different types of information from the input sequence. For example, one head might focus on syntactic information (e.g., the grammatical structure of the sentence), while another head might focus on semantic information (e.g., the meaning of the words).",
"usage": {
"completion_tokens": 381,
"prompt_tokens": 13,
"total_tokens": 394
}
}
login
regardless whether "colalamo" is used as a library or a server, the first time you use it,
it would generate a code that would need to be entered on the github in order to approve this "plugin":
$ python (master ✱ )
>>> from colalamo import Copilot
>>> copilot = Copilot()
don't see a token file: .copilot-token
browse to https://github.com/login/device and enter this code "4A3D-3957" to authenticate
waiting for user authorization...
after you go to "https://github.com/login/device" and enter the code, you'll see something similar to:
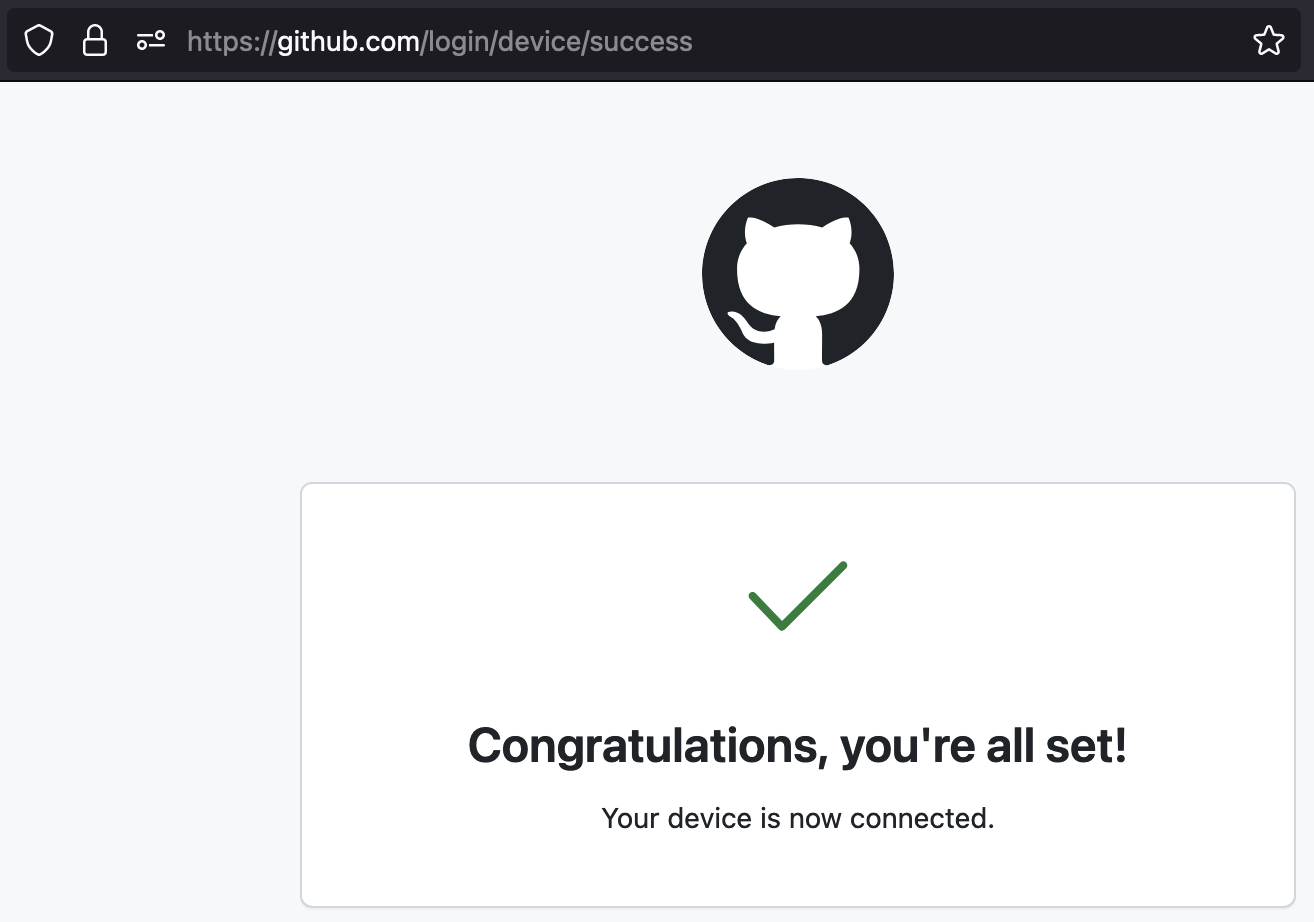
colalamo will create a ".copilot-token" file that it will be using for all the future calls.
license
Copyright © 2024 tolitius
Distributed under the Eclipse Public License either version 1.0 or (at your option) any later version.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file colalamo-0.1.2106.tar.gz.
File metadata
- Download URL: colalamo-0.1.2106.tar.gz
- Upload date:
- Size: 12.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9c8444afe546c25be016cabed9f047cc09a704ff8cc865efd0c20ca1f2d6a515
|
|
| MD5 |
df149ea8cd995030bba93eabb8978110
|
|
| BLAKE2b-256 |
f2d77af6fdf7f854815585738a929922022023f03139efac358017421ce55f3f
|
File details
Details for the file colalamo-0.1.2106-py3-none-any.whl.
File metadata
- Download URL: colalamo-0.1.2106-py3-none-any.whl
- Upload date:
- Size: 9.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b57b6d5d6750bb3a60b51f41b2756a09ffcb222beaacae27af1f0a122082714d
|
|
| MD5 |
a89a10411469e659f4ad5f3faa6fca09
|
|
| BLAKE2b-256 |
84bb33301b90631b99516e1bcb03db1069b118d4e99f6a5d91e660942fc4939f
|







