Convert trained traditional machine learning models into tensor computations

Project description
Introduction
Hummingbird is a library for compiling trained traditional ML models into tensor computations. Hummingbird allows users to seamlessly leverage neural network frameworks (such as PyTorch) to accelerate traditional ML models. Thanks to Hummingbird, users can benefit from: (1) all the current and future optimizations implemented in neural network frameworks; (2) native hardware acceleration; (3) having a unique platform to support for both traditional and neural network models; and have all of this (4) without having to re-engineer their models.
Currently, you can use Hummingbird to convert your trained traditional ML models into PyTorch, TorchScript, ONNX, and TVM). Hummingbird supports a variety of ML models and featurizers. These models include scikit-learn Decision Trees and Random Forest, and also LightGBM and XGBoost Classifiers/Regressors. Support for other neural network backends and models is on our roadmap.
Hummingbird also provides a convenient uniform "inference" API following the Sklearn API. This allows swapping Sklearn models with Hummingbird-generated ones without having to change the inference code. By converting the models to PyTorch and TorchScript it also becomes possible to serve them using TorchServe.
How Hummingbird Works
Hummingbird works by reconfiguring algorithmic operators such that we can perform more regular computations which are amenable to vectorized and GPU execution. Each operator is slightly different, and we incorporate multiple strategies. This example explains one of Hummingbird's strategies for translating a decision tree into tensors involving GEMM (GEneric Matrix Multiplication), where we implement the traversal of the tree using matrix multiplications. (GEMM is one of the three tree conversion strategies we currently support.)
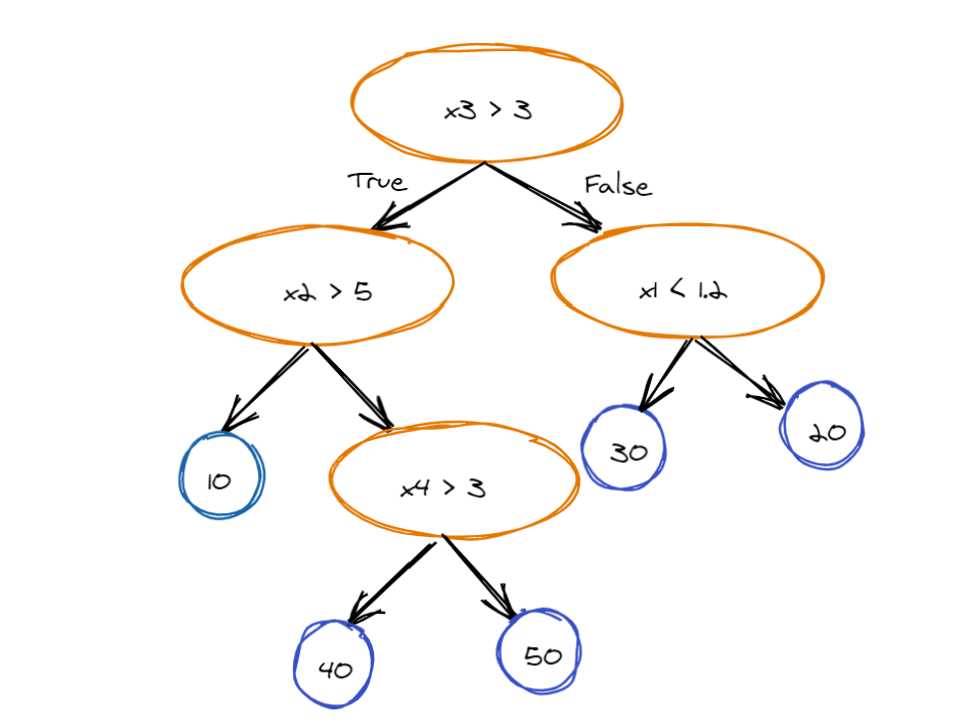
Simple decision tree
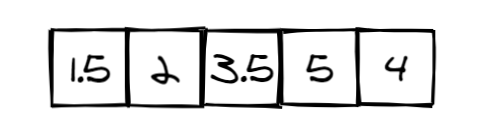
In this example, the decision tree has four decision nodes (orange), and five leaf nodes (blue). The tree takes a feature vector with five elements as input. For example, assume that we want to calculate the output of this observation:
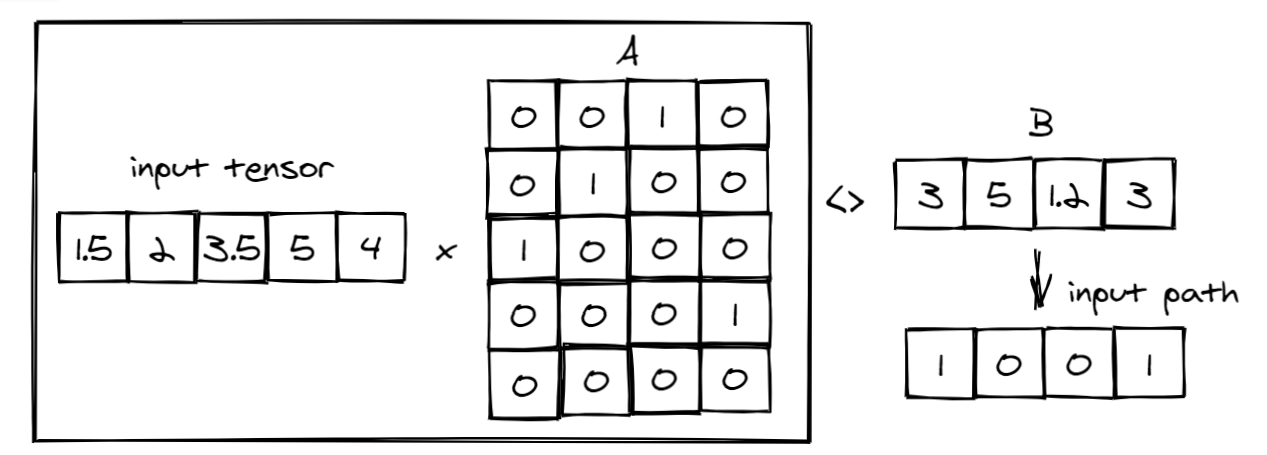
Step 1: Multiply the input tensor with tensor A (computed from the decision tree model above) that captures the relationship between input features and internal nodes. Then compare it with tensor B which is set to the value of each internal node (orange) to create the tensor input path that represents the path from input to node. In this case, the tree model has 4 conditions and the input vector is 5, therefore, the shape of tensor A is 5x4 and tensor B is 1x4.
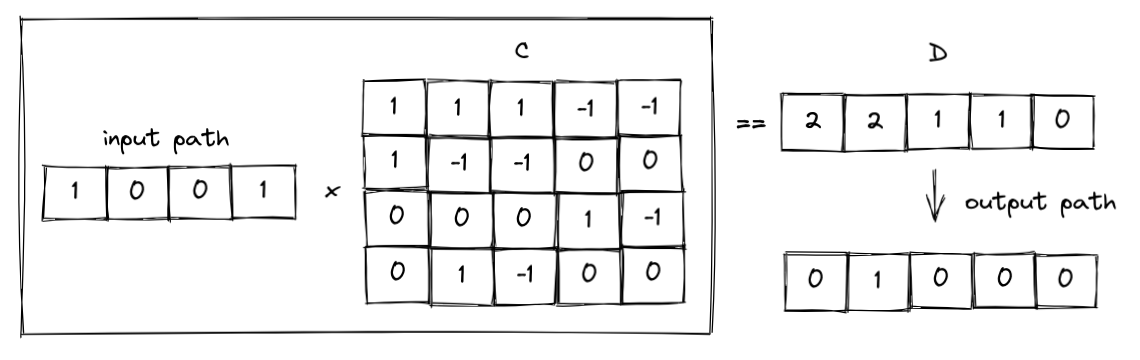
Step 2: The input path tensor will be multiplied with tensor C that captures whether the internal node is a parent of that internal node, and if so, whether it is in the left or right sub-tree (left = 1, right =-1, otherwise =0) and then check the equals with tensor D that captures the count of the left child of its parent in the path from a leaf node to the tree root to create the tenor output path that represents the path from node to output. In this case, this tree model has 5 outputs with 4 conditions, therefore, the shape of tensor C is 4x5 and tensor D is 1x5.
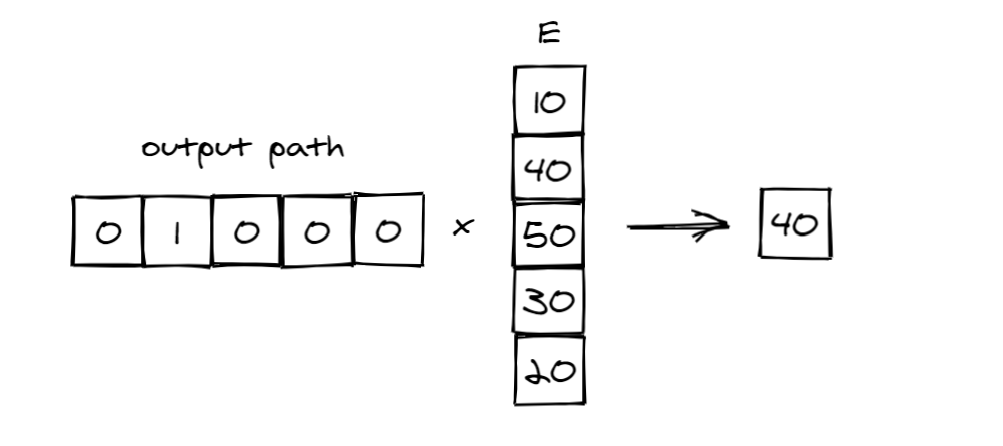
Step 3: The output path will be multiplied with tensor E that captures the mapping between leaf nodes to infer the final prediction. In this case, tree model has 5 outputs, therefore, shape of tensor E is 5x1.
And now Hummingbird has compiled a tree-based model using the GEMM strategy! For more details, please see Figure 3 of our paper.
Thank you to Chien Vu for contributing the graphics and descriptions in his blog for this example!
Installation
Hummingbird was tested on Python >= 3.7 on Linux, Windows and MacOS machines. (Python 3.6 is supported up to hummingbird-ml==0.4.2.) It is recommended to use a virtual environment (See: python3 venv doc or Using Python environments in VS Code.)
Hummingbird requires PyTorch >= 1.6.0. Please go here for instructions on how to install PyTorch based on your platform and hardware.
Once PyTorch is installed, you can get Hummingbird from pip with:
pip install hummingbird-ml
If you require the optional dependencies lightgbm and xgboost, you can use:
pip install hummingbird-ml[extra]
See also Troubleshooting for common problems.
Examples
See the notebooks section for examples that demonstrate use and speedups.
In general, Hummingbird syntax is very intuitive and minimal. To run your traditional ML model on DNN frameworks, you only need to import hummingbird.ml and add convert(model, 'dnn_framework') to your code. Below is an example using a scikit-learn random forest model and PyTorch as target framework.
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from hummingbird.ml import convert, load
# Create some random data for binary classification
num_classes = 2
X = np.random.rand(100000, 28)
y = np.random.randint(num_classes, size=100000)
# Create and train a model (scikit-learn RandomForestClassifier in this case)
skl_model = RandomForestClassifier(n_estimators=10, max_depth=10)
skl_model.fit(X, y)
# Use Hummingbird to convert the model to PyTorch
model = convert(skl_model, 'pytorch')
# Run predictions on CPU
model.predict(X)
# Run predictions on GPU
model.to('cuda')
model.predict(X)
# Save the model
model.save('hb_model')
# Load the model back
model = load('hb_model')
Documentation
The API documentation is here.
You can also read about Hummingbird in our blog post here.
For more details on the vision and on the technical details related to Hummingbird, please check our papers:
-
Tensors: An abstraction for general data processing. Dimitrios Koutsoukos, Supun Nakandala, Konstantinos Karanasos, Karla Saur, Gustavo Alonso, Matteo Interlandi. PVLDB 2021.
-
A Tensor Compiler for Unified Machine Learning Prediction Serving. Supun Nakandala, Karla Saur, Gyeong-In Yu, Konstantinos Karanasos, Carlo Curino, Markus Weimer, Matteo Interlandi. OSDI 2020.
-
Compiling Classical ML Pipelines into Tensor Computations for One-size-fits-all Prediction Serving. Supun Nakandala, Gyeong-In Yu, Markus Weimer, Matteo Interlandi. System for ML Workshop. NeurIPS 2019
Contributing
We welcome contributions! Please see the guide on Contributing.
Also, see our roadmap of planned features.
Community
Join our community!

For more formal enquiries, you can contact us.
Authors
- Supun Nakandala
- Matteo Interlandi
- Karla Saur
License
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file concrete_ml_extensions_hb-0.4.2.2-py2.py3-none-any.whl.
File metadata
- Download URL: concrete_ml_extensions_hb-0.4.2.2-py2.py3-none-any.whl
- Upload date:
- Size: 152.1 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3c630a9cfed4edc987bf07af0711a148da5d54746b16cf1dcdbe0715e804f2ea
|
|
| MD5 |
8fde69a8007a32218e83ca646dd3fcad
|
|
| BLAKE2b-256 |
094415989cb9b41846347df76943efff2e4557420299376459fa0f8ac2c1b86e
|







