Contextualized Topic Models

Project description
Contextualized Topic Models









Contextualized Topic Models (CTM) are a family of topic models that use pre-trained representations of language (e.g., BERT) to support topic modeling. See the papers for details:
Bianchi, F., Terragni, S., & Hovy, D. (2021). Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence. ACL. https://aclanthology.org/2021.acl-short.96/
Bianchi, F., Terragni, S., Hovy, D., Nozza, D., & Fersini, E. (2021). Cross-lingual Contextualized Topic Models with Zero-shot Learning. EACL. https://www.aclweb.org/anthology/2021.eacl-main.143/

Topic Modeling with Contextualized Embeddings
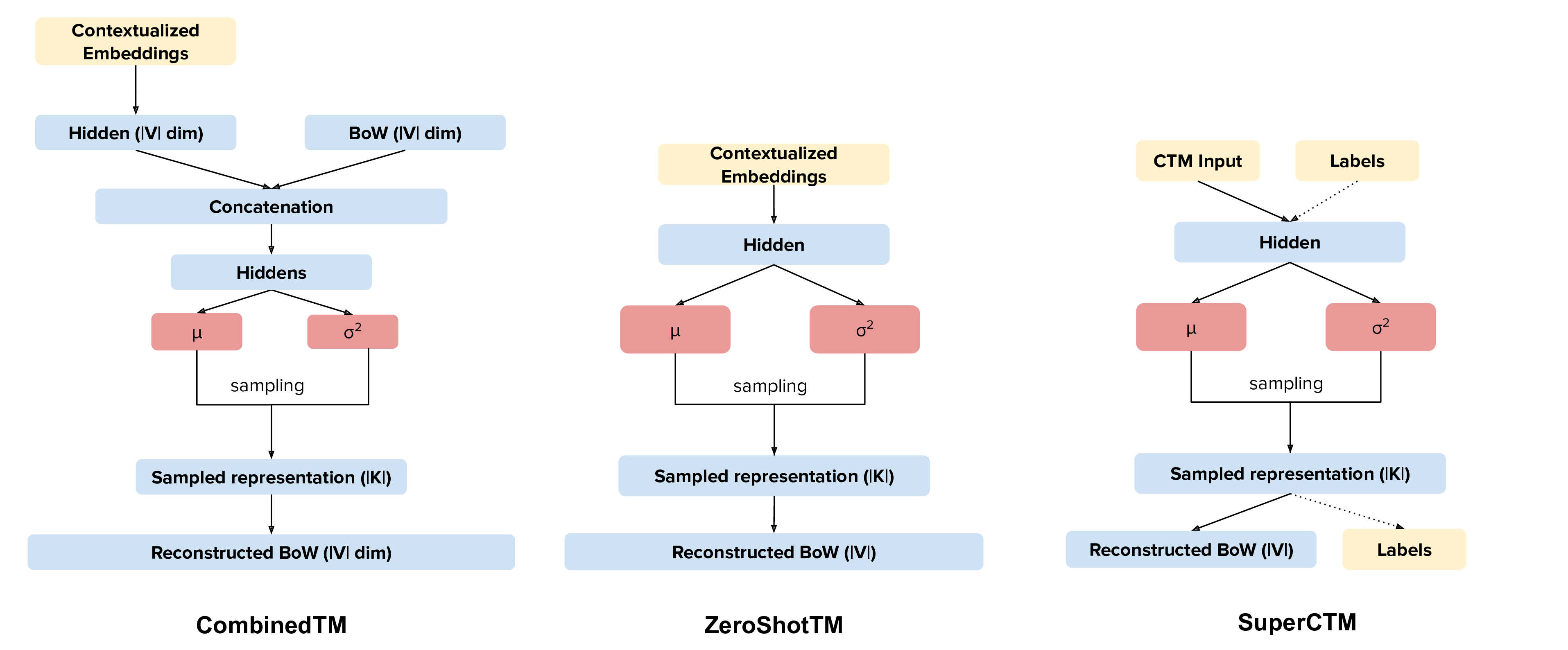
Our new topic modeling family supports many different languages (i.e., the one supported by HuggingFace models) and comes in two versions: CombinedTM combines contextual embeddings with the good old bag of words to make more coherent topics; ZeroShotTM is the perfect topic model for task in which you might have missing words in the test data and also, if trained with multilingual embeddings, inherits the property of being a multilingual topic model!
The big advantage is that you can use different embeddings for CTMs. Thus, when a new embedding method comes out you can use it in the code and improve your results. We are not limited by the BoW anymore.
We also have Kitty! A new submodule that can be used to create a human-in-the-loop classifier to quickly classify your documents and create named clusters.

Tutorials
You can look at our medium blog post or start from one of our Colab Tutorials:
Name |
Link |
|---|---|
Combined TM on Wikipedia Data (Preproc+Saving+Viz) (stable v2.3.0) |
|
Zero-Shot Cross-lingual Topic Modeling (Preproc+Viz) (stable v2.3.0) |
|
Kitty: Human in the loop Classifier (High-level usage) (stable v2.2.0) |
|
SuperCTM and β-CTM (High-level usage) (stable v2.2.0) |
Overview
TL;DR
In CTMs we have two models. CombinedTM and ZeroShotTM, which have different use cases.
CTMs work better when the size of the bag of words has been restricted to a number of terms that does not go over 2000 elements. This is because we have a neural model that reconstructs the input bag of word, Moreover, in CombinedTM we project the contextualized embedding to the vocab space, the bigger the vocab the more parameters you get, with the training being more difficult and prone to bad fitting. This is NOT a strict limit, however, consider preprocessing your dataset. We have a preprocessing pipeline that can help you in dealing with this.
Check the contextual model you are using, the multilingual model one used on English data might not give results that are as good as the pure English trained one.
Preprocessing is key. If you give a contextual model like BERT preprocessed text, it might be difficult to get out a good representation. What we usually do is use the preprocessed text for the bag of word creating and use the NOT preprocessed text for BERT embeddings. Our preprocessing class can take care of this for you.
CTM uses SBERT, you should check it out to better understand how we create embeddings. SBERT allows us to use any embedding model. You might want to check things like max length.
Installing
Important: If you want to use CUDA you need to install the correct version of the CUDA systems that matches your distribution, see pytorch.
Install the package using pip
pip install -U contextualized_topic_modelsModels
An important aspect to take into account is which network you want to use: the one that combines contextualized embeddings and the BoW (CombinedTM) or the one that just uses contextualized embeddings (ZeroShotTM)
But remember that you can do zero-shot cross-lingual topic modeling only with the ZeroShotTM model.
Contextualized Topic Models also support supervision (SuperCTM). You can read more about this on the documentation.
We also have Kitty: a utility you can use to do a simpler human in the loop classification of your documents. This can be very useful to do document filtering. It also works in cross-lingual setting and thus you might be able to filter documents in a language you don’t know!
References
If you find this useful you can cite the following papers :)
ZeroShotTM
@inproceedings{bianchi-etal-2021-cross,
title = "Cross-lingual Contextualized Topic Models with Zero-shot Learning",
author = "Bianchi, Federico and Terragni, Silvia and Hovy, Dirk and
Nozza, Debora and Fersini, Elisabetta",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.eacl-main.143",
pages = "1676--1683",
}
CombinedTM
@inproceedings{bianchi-etal-2021-pre,
title = "Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence",
author = "Bianchi, Federico and
Terragni, Silvia and
Hovy, Dirk",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-short.96",
doi = "10.18653/v1/2021.acl-short.96",
pages = "759--766",
}
Language-Specific and Multilingual
Some of the examples below use a multilingual embedding model
paraphrase-multilingual-mpnet-base-v2.
This means that the representations you are going to use are mutlilingual.
However you might need a broader coverage of languages or just one specific language.
Refer to the page in the documentation to see how to choose a model for another language.
In that case, you can check SBERT to find the perfect model to use.
Here, you can read more about language-specific and mulitlingual.
Quick Overview
You should definitely take a look at the documentation to better understand how these topic models work.
Combined Topic Model
Here is how you can use the CombinedTM. This is a standard topic model that also uses contextualized embeddings. The good thing about CombinedTM is that it makes your topic much more coherent (see the paper https://arxiv.org/abs/2004.03974). n_components=50 specifies the number of topics.
from contextualized_topic_models.models.ctm import CombinedTM
from contextualized_topic_models.utils.data_preparation import TopicModelDataPreparation
from contextualized_topic_models.utils.data_preparation import bert_embeddings_from_file
qt = TopicModelDataPreparation("all-mpnet-base-v2")
training_dataset = qt.fit(text_for_contextual=list_of_unpreprocessed_documents, text_for_bow=list_of_preprocessed_documents)
ctm = CombinedTM(bow_size=len(qt.vocab), contextual_size=768, n_components=50) # 50 topics
ctm.fit(training_dataset) # run the model
ctm.get_topics(2)Advanced Notes: Combined TM combines the BoW with SBERT, a process that seems to increase the coherence of the predicted topics (https://arxiv.org/pdf/2004.03974.pdf).
Zero-Shot Topic Model
Our ZeroShotTM can be used for zero-shot topic modeling. It can handle words that are not used during the training phase. More interestingly, this model can be used for cross-lingual topic modeling (See next sections)! See the paper (https://www.aclweb.org/anthology/2021.eacl-main.143)
from contextualized_topic_models.models.ctm import ZeroShotTM
from contextualized_topic_models.utils.data_preparation import TopicModelDataPreparation
from contextualized_topic_models.utils.data_preparation import bert_embeddings_from_file
text_for_contextual = [
"hello, this is unpreprocessed text you can give to the model",
"have fun with our topic model",
]
text_for_bow = [
"hello unpreprocessed give model",
"fun topic model",
]
qt = TopicModelDataPreparation("paraphrase-multilingual-mpnet-base-v2")
training_dataset = qt.fit(text_for_contextual=text_for_contextual, text_for_bow=text_for_bow)
ctm = ZeroShotTM(bow_size=len(qt.vocab), contextual_size=768, n_components=50)
ctm.fit(training_dataset) # run the model
ctm.get_topics(2)As you can see, the high-level API to handle the text is pretty easy to use; text_for_bert should be used to pass to the model a list of documents that are not preprocessed. Instead, to text_for_bow you should pass the preprocessed text used to build the BoW.
Advanced Notes: in this way, SBERT can use all the information in the text to generate the representations.
Using The Topic Models
Getting The Topics
Once the model is trained, it is very easy to get the topics!
ctm.get_topics()Predicting Topics For Unseen Documents
The transform method will take care of most things for you, for example the generation of a corresponding BoW by considering only the words that the model has seen in training. However, this comes with some bumps when dealing with the ZeroShotTM, as we will se in the next section.
You can, however, manually load the embeddings if you like (see the Advanced part of this documentation).
Mono-Lingual Topic Modeling
If you use CombinedTM you need to include the test text for the BOW:
testing_dataset = qt.transform(text_for_contextual=testing_text_for_contextual, text_for_bow=testing_text_for_bow)
# n_sample how many times to sample the distribution (see the doc)
ctm.get_doc_topic_distribution(testing_dataset, n_samples=20) # returns a (n_documents, n_topics) matrix with the topic distribution of each documentIf you use ZeroShotTM you do not need to use the testing_text_for_bow because if you are using a different set of test documents, this will create a BoW of a different size. Thus, the best way to do this is to pass just the text that is going to be given in input to the contexual model:
testing_dataset = qt.transform(text_for_contextual=testing_text_for_contextual)
# n_sample how many times to sample the distribution (see the doc)
ctm.get_doc_topic_distribution(testing_dataset, n_samples=20)Cross-Lingual Topic Modeling
Once you have trained the ZeroShotTM model with multilingual embeddings, you can use this simple pipeline to predict the topics for documents in a different language (as long as this language is covered by paraphrase-multilingual-mpnet-base-v2).
# here we have a Spanish document
testing_text_for_contextual = [
"hola, bienvenido",
]
# since we are doing multilingual topic modeling, we do not need the BoW in
# ZeroShotTM when doing cross-lingual experiments (it does not make sense, since we trained with an english Bow
# to use the spanish BoW)
testing_dataset = qt.transform(testing_text_for_contextual)
# n_sample how many times to sample the distribution (see the doc)
ctm.get_doc_topic_distribution(testing_dataset, n_samples=20) # returns a (n_documents, n_topics) matrix with the topic distribution of each documentAdvanced Notes: We do not need to pass the Spanish bag of word: the bag of words of the two languages will not be comparable! We are passing it to the model for compatibility reasons, but you cannot get the output of the model (i.e., the predicted BoW of the trained language) and compare it with the testing language one.
More Advanced Stuff
Preprocessing
Do you need a quick script to run the preprocessing pipeline? We got you covered! Load your documents and then use our SimplePreprocessing class. It will automatically filter infrequent words and remove documents that are empty after training. The preprocess method will return the preprocessed and the unpreprocessed documents. We generally use the unpreprocessed for BERT and the preprocessed for the Bag Of Word.
from contextualized_topic_models.utils.preprocessing import WhiteSpacePreprocessing
documents = [line.strip() for line in open("unpreprocessed_documents.txt").readlines()]
sp = WhiteSpacePreprocessing(documents, "english")
preprocessed_documents, unpreprocessed_corpus, vocab, retained_indices = sp.preprocess()Using Custom Embeddings with Kitty
Do you have custom embeddings and want to use them for faster results? Just give them to Kitty!
from contextualized_topic_models.models.kitty_classifier import Kitty
import numpy as np
# read the training data
training_data = list(map(lambda x : x.strip(), open("train_data").readlines()))
custom_embeddings = np.load('custom_embeddings.npy')
kt = Kitty()
kt.train(training_data, custom_embeddings=custom_embeddings, stopwords_list=["stopwords"])
print(kt.pretty_print_word_classes())Note: Custom embeddings must be numpy.arrays.
Development Team
Federico Bianchi <f.bianchi@unibocconi.it> Bocconi University
Silvia Terragni <s.terragni4@campus.unimib.it> University of Milan-Bicocca
Dirk Hovy <dirk.hovy@unibocconi.it> Bocconi University
Software Details
Free software: MIT license
Documentation: https://contextualized-topic-models.readthedocs.io.
Super big shout-out to Stephen Carrow for creating the awesome https://github.com/estebandito22/PyTorchAVITM package from which we constructed the foundations of this package. We are happy to redistribute this software again under the MIT License.
Credits
This package was created with Cookiecutter and the audreyr/cookiecutter-pypackage project template. To ease the use of the library we have also included the rbo package, all the rights reserved to the author of that package.
Note
Remember that this is a research tool :)
History
2.6.0 (2025-07-23)
making the package run on modern python
2.2.2 (2021-11-09)
kitty now takes in input a stopword list instead of a language (from which it gathered the stopwords)
solving a bug in the whitespace preprocessing function
adding a new preprocessing function that supports passing the stopwords as a list
deprecating whitespace preprocessing
minor fixes to kitty API
breaking change to kitty API, now uses WhiteSpacePreprocessingStopwords.
2.2.0 (2021-09-20)
introducing kitty
improving the documentation a lot
2.1.2 (2021-09-03)
2.1.0 (2021-07-16)
new model introduced SuperCTM
new model introduced β-CTM
2.0.0 (2021-xx-xx)
- warning, breaking changes were introduced:
the order of the parameters in CTMDataset was changed (now first is contextual embeddings)
CTM takes in input bow_size, contextual_size instead of input_size and bert_size
changed the name of the parameters in the dataset
introduced early stopping
introduced visualization with pyldavis
1.8.2 (2021-02-08)
removed constraint over pytorch version. This should solve problems for Windows users
1.8.0 (2021-01-11)
novel way to handle text, we now allow for an easy usage of training and testing data
better visualization of the training progress and of the sampling process
removed old stuff from the documentation
1.7.1 (2020-12-17)
some minor updates to the documentation
adding a new method to visualize the topic using a wordcloud
save and load will now generate a warning since the feature has not been tested
1.7.0 (2020-12-10)
adding a new and much simpler way to handle text for topic modeling
1.6.0 (2020-11-03)
introducing the two different classes for ZeroShotTM and CombinedTM
depracating CTM class in favor of ZeroShotTM and CombinedTM
1.5.3 (2020-11-03)
adding support for Windows encoding by defaulting file load to UTF-8
1.5.2 (2020-11-03)
updated sentence-transformers version to 0.3.6
beta support for model saving and loading
new evaluation metrics based on coherence
1.5.0 (2020-09-14)
Introduced a method to predict the topics for a set of documents (supports multiple sampling to reduce variation)
Adding some features to bert embeddings creation like increased batch size and progress bar
Supporting training directly from lists without the need to deal with files
Adding a simple quick preprocessing pipeline
1.4.3 (2020-09-03)
Updating sentence-transformers package to avoid errors
1.4.2 (2020-08-04)
Changed the encoding on file load for the SBERT embedding function
1.4.1 (2020-08-04)
Fixed bug over sparse matrices
1.4.0 (2020-08-01)
New feature handling sparse bow for optimized processing
New method to return topic distributions for words
1.0.0 (2020-04-05)
Released models with the main features implemented
0.1.0 (2020-04-04)
First release on PyPI.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file contextualized_topic_models-2.6.1.tar.gz.
File metadata
- Download URL: contextualized_topic_models-2.6.1.tar.gz
- Upload date:
- Size: 59.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.23
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e9b5014eb4057acac6092345fa5eabe6145dc54f4ccc6e05d7d4b8ec90f7a916
|
|
| MD5 |
e37c20b9248c740bb1821ae393ccd6d8
|
|
| BLAKE2b-256 |
ed4b63b0470bf8efd70d4bfdf107f24d1f03d3d81b52bdb6f3c4c98396b026bd
|
File details
Details for the file contextualized_topic_models-2.6.1-py2.py3-none-any.whl.
File metadata
- Download URL: contextualized_topic_models-2.6.1-py2.py3-none-any.whl
- Upload date:
- Size: 36.6 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.23
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
36dfe0676dc621e1b6b9d74bb1c93b9d334329ffb8f319c93347a5adb6361cd9
|
|
| MD5 |
b7237aae9e0f9884ffe8dd94f8433f05
|
|
| BLAKE2b-256 |
c0a38e24034febb49084e3925a52237b22e80489390efe331028bd6fcb488c14
|







