ContrXT

Project description

ContrXT
A global, model-agnostic, contrastive explainer for any text classifier
Why do we might need ContrXT?
Imagine we have a text classifier, let's say M1, that is retrained with new data generating M2.
- Can we estimate to what extent M2 classifies new data coherently to the past predictions made by the previous model M1?
- Why does the criteria used by M1 result in class c, but M2 does not use the same criteria to classify as c anymore?
- Can we use natural language to explain the differences between models making them more comprehensible to final users?
What ContrXT can do?
ContrXT is about explaining how a classifier changed its predictions through time. Also, it can be used to explain the differences in the classification behaviours of two distinct classifiers at a time.
ContrXT takes as input the predictions of two distinct classifiers M1 and M2. Then, it traces the decision criteria of both classifiers by encoding the changes in the decision logic through Binary Decision Diagrams. Then (ii) it provides "global, model-agnostic, time-contrastive (T-contrast) "explanations in natural language, estimating why -and to what extent- the model has modified its behaviour over time.
Details on how ContrXT works can be found in this paper
Below a link to the demo video.
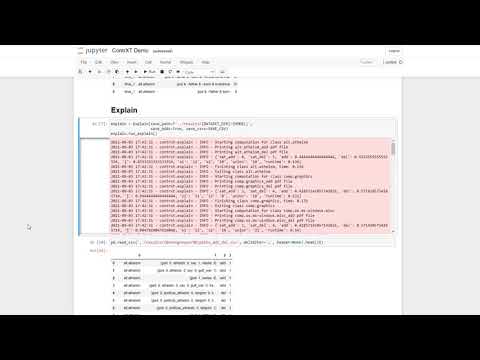
What ContrXT needs as input?
ContrXT takes as input the "feature data" (can be training or test, labelled or unlabelled) and the corresponding "labels" predicted by the classifier. This means you don't need to wrap ContrXT within your code at all! As optional parameters, the user can specify:
- the coverage of the dataset to be used (default is 100%); otherwise, a sampling procedure is used;
- to obtain explanations either for the multiclass case (default: one class vs all) or the two-class case (class vs class, by restricting the surrogate generation to those classes);
What ContrXT provides as output?
ContrXT provides two outputs:
(1) Indicators to estimate which classes are changing more!
A picture estimating the differences among the classification criteria of both classifiers M1 and M2, that are Add and Del values. To estimate the degree of changes among classes, ContrXT also provides add_global and del_global. In the case of a multiclass classifier, ContrXT suggests focusing on classes that went through major alterations from M1 to M2, distinguishing between three groups according to their Add and Del values being above or below the 75th percentile.

The picture above is generated by ContrXT automatically. It provides indicators of changes in classification criteria from model M1 to M2 for each 20newsgroup class, using a DT as a surrogate (0.8 fidelity) to explain two BERT classifiers.
(2) Natural Language Explanations for each class
The indicators allow the user to concentrate on classes that have changed more. For example, one might closely look at class atheism as for this class, the number of deleted paths is higher than the added ones

The Natural Language Explanation for atheism reveals the presence of the word bill leads the retrained classifier M2 to assign the label atheism to a specific record, whilst the presence of such a feature was not a criterion for the previous classifier M1. Conversely, the explanation shows that M1 used the feature keith to assign the label, whilst M2 discarded this rule.
Both terms refer to the name of the posts' authors: Bill's posts are only contained within the dataset used to retrain whilst Keith's ones are more frequent in the initial dataset rather than the second one (dataset taken from Jin, P., Zhang, Y., Chen, X., & Xia, Y. Bag-of-embeddings for text classification. In IJCAI-2016).
Finally, M2 discarded the rule having political atheist that was sufficient for M1 for classifying the instance.
Do explanations lead to new insights?
Our experiments reveal Add/Del is not correlated with the models' accuracy. For example, we assessed a correlation between Add/Del and the change in performance of the classifiers in terms of F1-score on 20newsgroup. To this end, we computed the Spearman's \rho between the Add of every class and its change in f1-score between the two classifiers. The correlation values are not significant, p=0.91$, ro=-0.11 for the Add and p=0.65, ro=-0.04 for Del indicator. This confirms that Add/Del are not related to the f1-score of the trained model. Instead, they estimate its behaviour change handling new data, considering which rules have been added or deleted to the past.
Installation
To install ContrXT, clone this repository and then run in the main directory:
pip install .
The PyEDA package is required but has not been added to the dependencies. This is due to installation errors on Windows. If you are on Linux or Mac, you should be able to install it by running:
pip3 install pyeda
However, if you are on Windows, we found that the best way to install is through Christophe Gohlke's pythonlibs page. For further information, please consult the official PyEDA installation documentation.
To produce the PDF files, a Graphviz installation is also required. Full documentation on how to install Graphviz on any platform is available here.
Tutorials and Usage
A complete example of ContrXT usage is provided in the notebook "ContrXT Demo" inside of the main repository folder. A notebook example with ML model training is also available in this repository, which can also be accessed in this Google Colab notebook. Complete documentation of the package functions will also be available shortly.
Running tests
Basic unit tests are provided. To run them, after installation, execute the following command while in the main directory:
python -m unittest discover
ContrXT as a Service through REST-API
ContrXT provides REST-API to generate explanations for any text classifier. Our API enables users to get the outcome of ContrXT as discussed above (i.e., Indicators and Natural language explanations) with no need to install or configure the tool locally. The required input from a user are (i) the training data and (ii) the predicted labels by the classifier of their choice. Users are required to upload two csv files for two datasets for which the schema is shown in the following JSON.
schema = {
"type" : "csv",
"columns" : {
"corpus" : {"type" : "string"},
"predicted" : {"type" : "string"},
},
}
The ContrXT's API can be invoked using a few lines code shown in Code below.
import requests, io
from zipfile import ZipFile
files = {
'time_1': open(t1_csv_path, 'rb'),
'time_2': open(t2_csv_path, 'rb')
}
r = requests.post('[URLandPort]', files=files)
result = ZipFile(io.BytesIO(r.content))
Notice. To avoid improper use of ContrXT'server resources, we ask users to ask for free credentials through this link.
Limitation
Currently, we support explaining predictions for text classifiers only, but we are working to extend it to deal with tabular data.
References
To cite ContrXT please refer to the following paper
@article{ContrXT,
author = {Lorenzo Malandri and Fabio Mercorio and Mario Mezzanzanica and Andrea Seveso and Navid Nobani},
title = {ContrXT: Generating Contrastive Explanations from any Text Classifier},
year = {2021},
publisher = {Elsevier},
issn = {1566-2535},
year = {2021},
issn = {1566-2535},
doi = {https://doi.org/10.1016/j.inffus.2021.11.016},
url = {https://www.sciencedirect.com/science/article/pii/S1566253521002426},
journal = {Information Fusion}
}
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file contrxt-0.0.1.tar.gz.
File metadata
- Download URL: contrxt-0.0.1.tar.gz
- Upload date:
- Size: 37.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.2 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
86f3dd68dad1b7944106791d2a31489bb74aea583e87d3dcf138906a2c5e5988
|
|
| MD5 |
8a0045dbbb856e21d27c92fbde3866da
|
|
| BLAKE2b-256 |
0bd6ed35100ba730a81831bb07d3dd5c3ea946d6830a7c90b9cb1db837d84b68
|
File details
Details for the file contrxt-0.0.1-py3-none-any.whl.
File metadata
- Download URL: contrxt-0.0.1-py3-none-any.whl
- Upload date:
- Size: 37.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.2 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7c91d6277d492ebd120830d75be132d037d5ce8a85af5152e9669926fd49fc0c
|
|
| MD5 |
6bd47d95279c643ba0b29ec411f009c1
|
|
| BLAKE2b-256 |
a1b396b6ac0d4bb2dd0bf00cc5ebd79af577a445332322990a271ecf5c82da70
|







