Downloads websites for long-term archival.

Project description
Crystal: A Website Archiver

Crystal is a tool that downloads high-fidelity copies of websites for long-term archival.
It works best on traditional websites made of distinct pages using limited JavaScript (such as blogs, wikis, and other static websites) although it can also download more dynamic sites which have infinitely scrolling feeds of content (such as social media sites).
To get started downloading your first website with Crystal, please see the Tutorial below.
Download ⬇︎
Either install a binary version of Crystal:
Or install from source, using pipx:
- Install Python >=3.13 and pip:
- Ubuntu/Kubuntu 22.04+:
apt-get update; apt-get install -y python3 python3-pip python3-venv - Fedora 37+:
yum update -y; yum install -y python3 python3-pip
- Ubuntu/Kubuntu 22.04+:
- On Linux, install dependencies of wxPython from your package manager:
- Ubuntu/Kubuntu 22.04+:
apt-get install -y libgtk-3-dev - Fedora 37+:
yum install -y wxGTK-devel gcc gcc-c++ which python3-devel
- Ubuntu/Kubuntu 22.04+:
- Install pipx
python3 -m pip install pipx
- Install Crystal with pipx
pipx install crystal-web- ⏳ On Linux the above step will take a long time (10+ minutes) because wxPython, a dependency of Crystal, will need to be built from source, since it does not offer precompiled wheels for Linux.
- On Linux, install a shortcut to Crystal inside GNOME/KDE applications and on the desktop:
crystal --install-to-desktop
- Run Crystal:
crystal
Tutorial ⭐
Download a simple website
A simple website is created or administered by only a single person, may contain text and images but not video, and does not requiring logging in to view its content.
There are many simple websites you can practice downloading at https://daarchive.net/.
Steps to download xkcd, a simple site:
- Download Crystal. See the Download section above for specific instructions.
- Open Crystal and press "New Project" to create a new untitled project.
- Click the big "New Root URL..." button and type in "xkcd.daarchive.net" for the URL. Optionally type in "Home" for the Name.
- Tick the "Create Group to Download Entire Site" checkbox. The "Download Site Immediately" checkbox should already be ticked. Press the "New" button to create the root URL, create the group for the site, and start downloading the site.
- The newly created "Home" URL at path "/" should already be selected. Click the "View" button to open the downloaded home page in your default web browser.
- Within the web browser you should be able to navigate to any page in the downloaded site.
- Return to the Crystal app. Close the untitled window. Don't worry if download tasks are still running because Crystal will offer to resume any downloads later when the project is reopened.
- You'll be prompted to save the project somewhere permanent. Save it as "Simple Tutorial" on your desktop.
- Find the saved "Simple Tutorial" project on your desktop and double-click it to open it.
- On macOS the project will open in Crystal immediately. On Windows or Linux a window will appear with an "OPEN ME" file. Double-click the "OPEN ME" file to open the project in Crystal.
- The home URL should be selected. Press "View" to see the downloaded home page again in your web browser.
- Congratulations! You've downloaded your first simple website with Crystal!
Download a complex website
Any website that is not simple is a complex website. In particular:
- Sites that contain content from multiple people are complex. Most forums, wikis (like: Wikipedia), and social media sites (like: Facebook, YouTube, or X) are complex.
- Sites that contain large assets such as video (ex: YouTube), files (ex: Hugging Face), or large images are complex.
- Sites that require login to view content like paid blogs (ex: Pragmatic Engineer), paid news sites (ex: The New York Times), and paid video sites (ex: Barre3) are complex.
When downloading a complex website you need to precisely define which pages you want to download because downloading the entire site would take too much space/time.
Each complex website is different. Here is an example of downloading only Guido's blog posts from Artima Weblogs, a complex site containing content from multiple people:
- Download Crystal. See the Download section above for specific instructions.
- Open Crystal and press "New Project" to create a new untitled project.
- Click the big "New Root URL..." button and type in "artima.daarchive.net" for the URL. Optionally type in "Home" for the name.
- The "Download URL Immediately" checkbox should already be ticked. Press the "New" button to create the root URL and start downloading it.
- The newly created "Home" URL at path "/" should already be selected. Click the "View" button to open the downloaded home page in your default web browser.
- In the left navigation where it says "Artima Blogger", look for the link "Guido van van Rossum" [sic]. Click it.
- A Crystal error page appears that says "Page Not in Archive", because
the link you clicked (
https://artima.daarchive.net/index.html$/blogger=guido.html) hasn't been downloaded yet. - Click the "Download" button to individually download and view Guido's first post list page.
- Notice at the top of the page there are links to pages 2, 3, 4, and 5 of Guido's post list. Click the page 2 link.
- Again, a Crystal page saying "Page Not in Archive" appears.
This time though, we want to download all similar pages.
Tick the "Create Group for Similar Pages" checkbox at the bottom of the page
to reveal a form for creating a group.
- A group describes a collection of pages that all have the same URL pattern.
- Crystal automatically populates its best guess for a URL Pattern.
For this example that guessed pattern is:
https://artima.daarchive.net/index.html$/blogger=guido&start=#&thRange=15.html. The "#" wildcard in the pattern will match any number of digits, like "15" or "30". There are other wildcards like "*" which will match any block of text without a "/". - Notice that the Preview Members box displays all URLs matching the currently typed URL Pattern.
- Crystal also automatically populates its best guess for what the source of
the Group should be.
- The source of a group links to all or most members of the group. When Crystal is asked to redownload a group it will redownload the source first to see if the group has any new members.
- For this example Crystal has guessed an appropriate URL Pattern and Source for matching all of Guido's post list pages, so we don't need to change them.
- Optionally type in "Guido Post List, Page 2+" for the name of the group.
- The "Download Group Immediately" checkbox should already be ticked. Press the "Download" button to create the group and start downloading it.
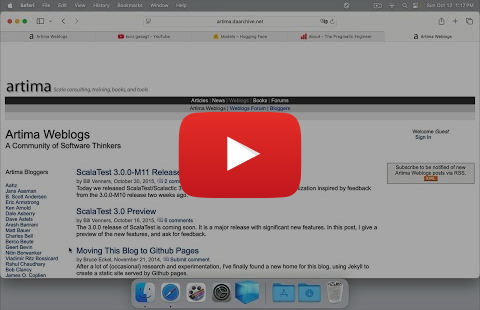
- Return to the Crystal app. The top "Root URLs and Groups" pane displays
each URL and Group you discovered by navigating the downloaded site.
It should say:
- ⚓️ / - Home
- ⚓️ /index.html$/blogger=guido.html
- 📁 /index.html$/blogger=guido&start=#&thRange=15.html - Guido Post List, Page 2+
- Each ⚓️ is a Root URL. Each 📁 is a Group.
- Click the second ⚓️ to select it.
- Click the "Edit" button.
- Type "Guido Post List, Page 1" for the name of the URL.
- Click the "Save" button. Now the displayed URLs and groups should be:
- ⚓️ / - Home
- ⚓️ /index.html$/blogger=guido.html - Guido Post List, Page 1
- 📁 /index.html$/blogger=guido&start=#&thRange=15.html - Guido Post List, Page 2+
- Close the untitled window. You'll be prompted to save the project somewhere permanent. Save it as "Complex Tutorial" on your desktop.
- Congratulations! You've downloaded your first complex website with Crystal!
Tips for downloading more types of complex sites are available on the wiki:
History 📖
David Foster wrote Crystal originally in 2011 because other website downloaders he tried didn't work well for him and because he wanted to write a large Python program, as Python was a new language for him at the time.
Every few years he revisits Crystal to add features allowing him to archive more sites that he cares about and to streamline the downloading process.
Design 📐
A few unique characteristics of Crystal:
-
The Crystal project file format (
*.crystalproj) is suitable for long-term archival:- Downloaded pages are stored in their original form as downloaded from the web including all HTTP headers.
- Metadata is stored in a SQLite database.
-
To download pages automatically, the user must define "groups" of pages with similar URLs (ex: "Blog Posts", "Archive Pages") and specify rules for finding links to members of the group.
- Once a group has been defined in this way, it is possible for the user to instruct Crystal to simply download the group. This involves finding links to all members of the group (possibly by downloading other groups) and then downloading each member of the group, in parallel.
The design is intended for the future addition of the following features:
- Intelligently updating the pages in websites that have already been downloaded.
- This would be done by defining rules on groups that specify how often its members are updated. For example the set of "Archive Pages" on WordPress blogs is expected to change monthly. And the most recently added member of the "Archive Pages" group may change daily, whereas the other members are expected to never change.
- Multiple revisions per downloaded resource are supported to allow multiple versions of the same resource to be tracked over time.
Contributing ⚒
Code contributions to Crystal from users are welcome, particularly if you want to add specialized support for downloading a site you care about that Crystal doesn't already well-support.
Note on Licensing: Crystal uses a noncommercial license rather than a traditional open source license, but this does not prevent you from contributing code. Contributors retain full rights to their contributions and can use their contributed code in other projects under any license they choose. See the License FAQ for more details.
If you'd like to request a feature, report a bug, or ask a question, please create
a new GitHub Issue,
with either the type-feature, type-bug, or type-question tag.
If you'd like to help work on coding new features, please see the code contributor workflow. If you'd like to help moderate the community please see the maintainer workflow.
See CONTRIBUTING.md for more information.
Code Contributors
Poetry is required for dependency management and development. To install the correct version:
python -m pip install poetry==2.1.1
To run the code locally,
run poetry install once in Terminal (Mac) or in Command Prompt (Windows), and
poetry run python -m crystal thereafter.
To build new binaries for Mac or Windows, follow the instructions at COMPILING.txt.
To run non-UI tests, run poetry run pytest in Terminal (Mac) or in Command Prompt (Windows).
To run UI tests, run poetry run python -m crystal test in Terminal (Mac) or in Command Prompt (Windows).
To typecheck, run poetry run mypy in Terminal (Mac) or in Command Prompt (Windows).
To sort imports, run poetry run isort . in Terminal (Mac) or in Command Prompt (Windows).
Related Projects ⎋
- webcrystal: An alternative website archiving tool that focuses on making it easy for automated crawlers (rather than for humans) to download websites.
Release Notes ⋮
See RELEASE_NOTES.md
License ⚖️
Crystal is licensed under the PolyForm Noncommercial License 1.0.0. This means you may use Crystal for any noncommercial purpose, but commercial use requires a separate license agreement.
This license does not restrict code contributions. Contributors retain all rights to their contributions and may use their contributed code in other projects under any license they choose.
For more information about Crystal's license please read the License FAQ.
For commercial licensing inquiries, please contact David Foster.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file crystal_web-2.3.0.tar.gz.
File metadata
- Download URL: crystal_web-2.3.0.tar.gz
- Upload date:
- Size: 5.6 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.1.1 CPython/3.12.2 Darwin/24.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8484ee8bccb5ca90081849d54f86f986de26e67d6740e0d3fb385f29937fca72
|
|
| MD5 |
1ca355db1d638364faba3c7e51be667f
|
|
| BLAKE2b-256 |
353d421488c43f37ce0261e504088649d24bc3a6f1a484dd94cd2e63555e09cc
|
File details
Details for the file crystal_web-2.3.0-py3-none-any.whl.
File metadata
- Download URL: crystal_web-2.3.0-py3-none-any.whl
- Upload date:
- Size: 4.6 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.1.1 CPython/3.12.2 Darwin/24.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
49e8fe06c97c3605ee68ae982765107978e699f2d53bf4b6dc1ba03406a33b46
|
|
| MD5 |
178eeba0cfce1e16e6a9926dea4c4019
|
|
| BLAKE2b-256 |
950d35d74fee7cf351b52de4360b1aaf2af98ccb584a992b5ff811e99f8a3baf
|







