A light-weight Python app for classifying scientific documents with the topics from the Computer Science Ontology (https://cso.kmi.open.ac.uk/home).

Project description
CSO-Classifier



Abstract
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this repository, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science. The CSO Classifier takes as input the metadata associated with a research paper (title, abstract, keywords) and returns a selection of research concepts drawn from the ontology. The approach was evaluated on a gold standard of manually annotated articles yielding a significant improvement over alternative methods.
Read more: https://skm.kmi.open.ac.uk/cso-classifier/
Table of contents
- CSO-Classifier
About
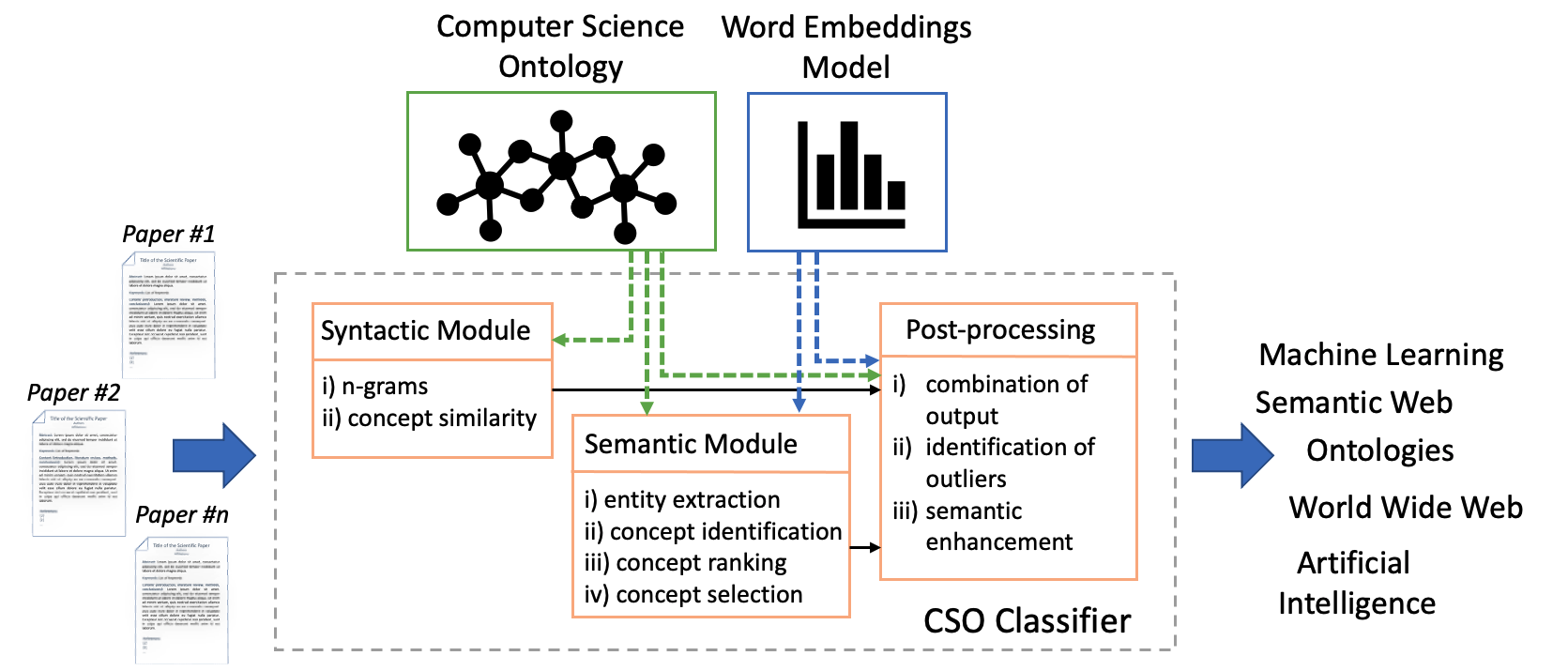
The CSO Classifier is a novel application that takes as input the text from the abstract, title, and keywords of a research paper and outputs a list of relevant concepts from CSO. It consists of three main components: (i) the syntactic module, (ii) the semantic module and (iii) the post-processing module. Figure 1 depicts its architecture. The syntactic module parses the input documents and identifies CSO concepts that are explicitly referred to in the document. The semantic module uses part-of-speech tagging to identify promising terms and then exploits word embeddings to infer semantically related topics. Finally, the post-processing module combines the results of these two modules, removes outliers, and enhances them by including relevant super-areas.
Getting started
Installation using PIP
- Ensure you have Python 3.11, or 3.12. Download them from here. Perhaps, you may want to use a virtual environment. Here is how to create and activate a virtual environment.
- Use pip to install the classifier:
pip install cso-classifier - Setting up the classifier. Go to Setup for finalising the installation.
Installation using Github
- Ensure you have Python 3.11, or 3.12. Download them from here. Perhaps, you may want to use a virtual environment. Here is how to create and activate a virtual environment.
- Download this repository using:
git clone https://github.com/angelosalatino/cso-classifier.git - Install the package by running the following command:
pip install ./cso-classifier - Setting up the classifier. Go to Setup for finalising the installation.
Troubleshooting
Although, we have worked hard to fix many issues occurring at testing phase, some of them could still arise for reasons that go beyond our control. Here is the list of the common issues we have encountered.
Unable to install requirements
Most likely this issue is due to the version of pip you are currently using. Make sure to update to the latest version of pip: pip install --upgrade pip.
Unable to install python-Levenshtein
Many users found difficulties in installing the python-Levenshtein library on some Linux servers. One way to get around this issue is to install the python3-devel package. You might need sudo rights on the hosting machine.
-- Special thanks to Panagiotis Mavridis for suggesting the solution.
"python setup.py egg_info" failed
More specifically: Command "python setup.py egg_info" failed with error code 1. This error is due to the setup.py file. The occurrence of this issue is rare. If you are experiencing it, please do get in touch with us. We will work with you to fix it.
Setup
After installing the CSO Classifier, it is important to set it up with the right dependencies. To set up the classifier, please run the following code:
from cso_classifier import CSOClassifier as cc
cc.setup()
exit() # it is important to close the current console, to make those changes effective
This function downloads the latest version of Computer Science Ontology and the latest version of the word2vec model, which will be used across all modules.
Then, in the background, it will also downloads the English package of spaCy, which is equivalent to run python -m spacy download en_core_web_sm, and the stopwords from nltk, which is equivalent to run:
>>> import nltk
>>> nltk.download()
Update
This functionality allows to update both ontology and word2vec model.
from cso_classifier import CSOClassifier as cc
cc.update()
#or
cc.update(force = True)
By just running update() without parameters, the system will check the version of the ontology/model that is currently using, against the lastest available version. The update will be performed if one of the two or both are outdated.
Instead with update(force = True) the system will force the update by deleting the ontology/model that is currently using, and downloading their latest version.
Version
This functionality returns the version of the CSO Classifier and CSO ontology you are currently using. It will also check online if there is a newer version, for both of them, and suggest how to update.
from cso_classifier import CSOClassifier as cc
cc.version()
Instead, if you just want to know the package version use:
import cso_classifier
print(cso_classifier.__version__)
Test
This functionality allows you to test whether the classifier has been properly installed.
import cso_classifier as test
test.test_classifier_single_paper() # to test it with one paper
test.test_classifier_batch_mode() # to test it with multiple papers
To ensure that the classifier has been installed successfully, these two functions test_classifier_single_paper() and test_classifier_batch_mode() print out both paper(s) info and the result of their classification.
Usage examples
In this section, we explain how to run the CSO Classifier to classify a single or multiple (batch mode) papers.
Classifying a single paper (SP)
Sample Input (SP)
The sample input can be either a dictionary containing title, abstract and keywords as keys, or a string:
paper = {
"title": "De-anonymizing Social Networks",
"abstract": "Operators of online social networks are increasingly sharing potentially "
"sensitive information about users and their relationships with advertisers, application "
"developers, and data-mining researchers. Privacy is typically protected by anonymization, "
"i.e., removing names, addresses, etc. We present a framework for analyzing privacy and "
"anonymity in social networks and develop a new re-identification algorithm targeting "
"anonymized social-network graphs. To demonstrate its effectiveness on real-world networks, "
"we show that a third of the users who can be verified to have accounts on both Twitter, a "
"popular microblogging service, and Flickr, an online photo-sharing site, can be re-identified "
"in the anonymous Twitter graph with only a 12% error rate. Our de-anonymization algorithm is "
"based purely on the network topology, does not require creation of a large number of dummy "
"\"sybil\" nodes, is robust to noise and all existing defenses, and works even when the overlap "
"between the target network and the adversary's auxiliary information is small.",
"keywords": "data mining, data privacy, graph theory, social networking (online)"
}
#or
paper = """De-anonymizing Social Networks
Operators of online social networks are increasingly sharing potentially sensitive information about users and their relationships with advertisers, application developers, and data-mining researchers. Privacy is typically protected by anonymization, i.e., removing names, addresses, etc. We present a framework for analyzing privacy and anonymity in social networks and develop a new re-identification algorithm targeting anonymized social-network graphs. To demonstrate its effectiveness on real-world networks, we show that a third of the users who can be verified to have accounts on both Twitter, a popular microblogging service, and Flickr, an online photo-sharing site, can be re-identified in the anonymous Twitter graph with only a 12% error rate. Our de-anonymization algorithm is based purely on the network topology, does not require creation of a large number of dummy "sybil" nodes, is robust to noise and all existing defenses, and works even when the overlap between the target network and the adversary's auxiliary information is small.
data mining, data privacy, graph theory, social networking (online)"""
In case the input variable is a dictionary, the classifier checks only the fields title, abstract and keywords. However, there is no need for filling all three of them. Indeed, if for instance you do not have keywords, you can just use the title and abstract.
Run (SP)
Just import the classifier and run it:
from cso_classifier import CSOClassifier
cc = CSOClassifier(modules = "both", enhancement = "first", explanation = True)
result = cc.run(paper)
print(result)
To observe the available settings please refer to the Parameters section.
If you have more than one paper to classify, you can use the following example:
from cso_classifier import CSOClassifier
cc = CSOClassifier(modules = "both", enhancement = "first", explanation = True)
results = list()
for paper in papers:
results.append(cc.run(paper))
print(results)
Even if you are running multiple classifications, the current implementation of the CSO Classifier will load the CSO and the model only once, saving computational time.
Sample Output (SP)
As output, the classifier returns a dictionary with seven components: (i) syntactic, (ii) semantic, (iii) union, (iv) enhanced, (v) explanation, (vi) syntactic_weights and (vii) semantic_weights. The explanation field is available only if the explanation flag is set to True. The last two fields are available only if the get_weights is set to True.
Below you can find an example. The keys syntactic and semantic respectively contain the topics returned by the syntactic and semantic module. Union contains the unique topics found by the previous two modules. In enhanced you can find the relevant super-areas. For the sake of clarity, we run the example with all the flag on, and hence it contains the enhanced field and both syntactic_weights and semantic_weights.
Please be aware that the results may change according to the version of Computer Science Ontology.
{
"syntactic": [
"graph theory",
"anonymization",
"anonymity",
"online social networks",
"real-world networks",
"data privacy",
"privacy",
"twitter",
"sensitive informations",
"network topology",
"social networks",
"data mining",
"micro-blog"
],
"semantic": [
"graph theory",
"anonymization",
"anonymity",
"online social networks",
"data privacy",
"topology",
"data mining",
"privacy",
"twitter",
"social networks",
"network topology",
"micro-blog"
],
"union": [
"graph theory",
"anonymization",
"anonymity",
"online social networks",
"real-world networks",
"data privacy",
"topology",
"privacy",
"twitter",
"sensitive informations",
"network topology",
"social networks",
"data mining",
"micro-blog"
],
"enhanced": [
"theoretical computer science",
"privacy preserving",
"authentication",
"network security",
"online systems",
"complex networks",
"computer security",
"social media",
"access control",
"computer networks",
"world wide web",
"computer science"
],
"explanation": {
"social networks": ["online social networks","microblogging","social-network","social network","real-world networks","social networking","twitter","social networks"],
"online social networks": ["social networks","social network","online social networks"],
"sensitive informations": ["sensitive information"],
"data mining": ["data mining","mining","data-mining"],
"privacy": ["sensitive information","privacy","anonymity","anonymous","data privacy"],
"anonymization": ["anonymization"],
"anonymity": ["anonymity","anonymous"],
"real-world networks": ["real-world networks"],
"twitter": ["twitter","twitter graph","microblogging","anonymous twitter","microblogging service"],
"micro-blog": ["twitter graph","twitter","microblogging","anonymous twitter","microblogging service"],
"network topology": ["network topology","topology"],
"data privacy": ["privacy","data privacy"],
"graph theory": ["graph theory"],
"topology": ["network topology","topology"],
"theoretical computer science": ["graph theory"],
"privacy preserving": ["anonymization"],
"authentication": ["anonymity","anonymous"],
"network security": ["sensitive information","anonymity","anonymous"],
"online systems": ["social networks","social network","online social networks"],
"complex networks": ["real-world networks"],
"computer security": ["sensitive information","privacy","anonymity","anonymous","data privacy"],
"social media": ["twitter","microblogging"],
"access control": ["sensitive information"],
"computer networks": ["network topology","topology"],
"world wide web": ["online social networks","microblogging","social-network","social network","real-world networks","social networking","twitter","social networks"],
"computer science": ["data mining","mining","data-mining"]
},
"syntactic_weights": {
"social networks": 1.0,
"online social networks": 1.0,
"sensitive informations": 0.9545454545454546,
"data mining": 1.0,
"privacy": 1.0,
"anonymization": 1.0,
"anonymity": 1.0,
"real-world networks": 1.0,
"twitter": 1.0,
"micro-blog": 1.0,
"network topology": 1.0,
"data privacy": 1.0,
"graph theory": 1.0
},
"semantic_weights": {
"social networks": 1.0,
"online social networks": 1.0,
"data mining": 1.0,
"privacy": 1.0,
"data privacy": 1.0,
"anonymization": 1.0,
"anonymity": 1.0,
"twitter": 1.0,
"micro-blog": 1.0,
"topology": 1.0,
"network topology": 1.0,
"graph theory": 1.0
}
}
Run on Single Paper with filter_by
In this example, we will run the CSO Classifier by filtering topics in computer security (look at how the filter_by parameter is set).
from cso_classifier import CSOClassifier
cc = CSOClassifier(modules = "both", enhancement = "first", explanation = True, filter_by=["computer security"])
result = cc.run(paper)
print(result)
Sample Output when using the filter_by parameter
The JSON below it the produced output, and as you can see there 4 additional keys (filtered_XXXX) at the bottom containing only a subset of topics within the field of computer security.
{
"syntactic": [
"real-world networks",
"anonymization",
"network topology",
"data privacy",
"social networks",
"privacy",
"twitter",
"graph theory",
"online social networks",
"anonymity",
"data mining",
"micro-blog",
"sensitive informations"
],
"semantic": [
"anonymization",
"network topology",
"topology",
"data privacy",
"social networks",
"privacy",
"twitter",
"graph theory",
"online social networks",
"anonymity",
"data mining",
"micro-blog"
],
"union": [
"real-world networks",
"anonymization",
"network topology",
"topology",
"data privacy",
"social networks",
"privacy",
"twitter",
"graph theory",
"online social networks",
"anonymity",
"data mining",
"micro-blog",
"sensitive informations"
],
"enhanced": [
"complex networks",
"privacy preserving",
"computer networks",
"world wide web",
"computer security",
"social media",
"theoretical computer science",
"online systems",
"authentication",
"network security",
"computer science",
"access control"
],
"explanation": {
"social networks": ["real-world networks", "social networks", "twitter", "social-network", "online social networks", "social network", "microblogging", "social networking"],
"online social networks": ["online social networks", "social networks", "social network"],
"sensitive informations": ["sensitive information"],
"data mining": ["data mining", "mining", "data-mining"],
"privacy": ["anonymous", "anonymity", "sensitive information", "data privacy", "privacy"],
"anonymization": ["anonymization"],
"anonymity": ["anonymous", "anonymity"],
"real-world networks": ["real-world networks"],
"twitter": ["twitter graph", "anonymous twitter", "microblogging", "microblogging service", "twitter"],
"micro-blog": ["twitter graph", "anonymous twitter", "microblogging", "microblogging service", "twitter"],
"network topology": ["network topology", "topology"],
"data privacy": ["data privacy", "privacy"],
"graph theory": ["graph theory"],
"topology": ["network topology", "topology"],
"complex networks": ["real-world networks"],
"privacy preserving": ["anonymization"],
"computer networks": ["network topology", "topology"],
"world wide web": ["real-world networks", "social networks", "twitter", "social-network", "online social networks", "social network", "microblogging", "social networking"],
"computer security": ["anonymous", "anonymity", "sensitive information", "data privacy", "privacy"],
"social media": ["microblogging", "twitter"],
"theoretical computer science": ["graph theory"],
"online systems": ["online social networks", "social networks", "social network"],
"authentication": ["anonymous", "anonymity"],
"network security": ["anonymous", "anonymity", "sensitive information"],
"computer science": ["data mining", "mining", "data-mining"],
"access control": ["sensitive information"]
},
"filtered_syntactic": [
"anonymization",
"data privacy",
"privacy",
"anonymity",
"sensitive informations"
],
"filtered_semantic": [
"anonymization",
"data privacy",
"privacy",
"anonymity"
],
"filtered_union": [
"anonymization",
"data privacy",
"privacy",
"anonymity",
"sensitive informations"
],
"filtered_enhanced": [
"privacy preserving",
"computer security",
"authentication",
"network security",
"access control"
]
}
Classifying in batch mode (BM)
Sample Input (BM)
The sample input is a dictionary of papers. Each key is an identifier (example id1, see below) and its value is either a dictionary containing title, abstract and keywords as keys, or a string, as shown for Classifying a single paper (SP).
papers = {
"id1": {
"title": "De-anonymizing Social Networks",
"abstract": "Operators of online social networks are increasingly sharing potentially sensitive information about users and their relationships with advertisers, application developers, and data-mining researchers. Privacy is typically protected by anonymization, i.e., removing names, addresses, etc. We present a framework for analyzing privacy and anonymity in social networks and develop a new re-identification algorithm targeting anonymized social-network graphs. To demonstrate its effectiveness on real-world networks, we show that a third of the users who can be verified to have accounts on both Twitter, a popular microblogging service, and Flickr, an online photo-sharing site, can be re-identified in the anonymous Twitter graph with only a 12% error rate. Our de-anonymization algorithm is based purely on the network topology, does not require creation of a large number of dummy \"sybil\" nodes, is robust to noise and all existing defenses, and works even when the overlap between the target network and the adversary's auxiliary information is small.",
"keywords": "data mining, data privacy, graph theory, social networking (online)"
},
"id2": {
"title": "Title of sample paper id2",
"abstract": "Abstract of sample paper id2",
"keywords": "keyword1, keyword2, ..., keywordN"
}
}
Run (BM)
Import the python script and run the classifier:
from cso_classifier import CSOClassifier
cc = CSOClassifier(workers = 1, modules = "both", enhancement = "first", explanation = True)
result = cc.batch_run(papers)
print(result)
To observe the available settings please refer to the Parameters section.
Sample Output (BM)
As output the classifier returns a dictionary of dictionaries. For each classified paper (identified by their id), it returns a dictionary containing five components: (i) syntactic, (ii) semantic, (iii) union, (iv) enhanced, and (v) explanation. The latter field is available only if the explanation flag is set to True.
Below you can find an example. The keys syntactic and semantic respectively contain the topics returned by the syntactic and semantic module. Union contains the unique topics found by the previous two modules. In ehancement you can find the relevant super-areas. In explanation, you can find all chunks of text that allowed the classifier to infer a given topic. Please be aware that the results may change according to the version of Computer Science Ontology.
{
"id1": {
"syntactic": ["network topology", "online social networks", "real-world networks", "anonymization", "privacy", "social networks", "data privacy", "graph theory", "data mining", "sensitive informations", "anonymity", "micro-blog", "twitter"],
"semantic": ["network topology", "online social networks", "topology", "data privacy", "social networks", "privacy", "anonymization", "graph theory", "data mining", "anonymity", "micro-blog", "twitter"],
"union": ["network topology", "online social networks", "topology", "real-world networks", "anonymization", "privacy", "social networks", "data privacy", "graph theory", "data mining", "sensitive informations", "anonymity", "micro-blog", "twitter"],
"enhanced": ["computer networks", "online systems", "complex networks", "privacy preserving", "computer security", "world wide web", "theoretical computer science", "computer science", "access control", "network security", "authentication", "social media"],
"explanation": {
"social networks": ["social network", "online social networks", "microblogging service", "real-world networks", "social networks", "microblogging", "social networking", "twitter graph", "anonymous twitter", "twitter"],
"online social networks": ["online social networks", "social network", "social networks"],
"sensitive informations": ["sensitive information"],
"privacy": ["sensitive information", "anonymity", "anonymous", "data privacy", "privacy"],
"anonymization": ["anonymization"],
"anonymity": ["anonymity", "anonymous"],
"real-world networks": ["real-world networks"],
"twitter": ["twitter graph", "twitter", "microblogging service", "anonymous twitter", "microblogging"],
"micro-blog": ["twitter graph", "twitter", "microblogging service", "anonymous twitter", "microblogging"],
"network topology": ["topology", "network topology"],
"data mining": ["data mining", "mining"],
"data privacy": ["data privacy", "privacy"],
"graph theory": ["graph theory"],
"topology": ["topology", "network topology"],
"computer networks": ["topology", "network topology"],
"online systems": ["online social networks", "social network", "social networks"],
"complex networks": ["real-world networks"],
"privacy preserving": ["anonymization"],
"computer security": ["anonymity", "data privacy", "privacy"],
"world wide web": ["social network", "online social networks", "microblogging service", "real-world networks", "social networks", "microblogging", "social networking", "twitter graph", "anonymous twitter", "twitter"],
"theoretical computer science": ["graph theory"],
"computer science": ["data mining", "mining"],
"access control": ["sensitive information"],
"network security": ["anonymity", "sensitive information", "anonymous"],
"authentication": ["anonymity", "anonymous"],
"social media": ["microblogging service", "microblogging", "twitter graph", "anonymous twitter", "twitter"]
}
},
"id2": {
"syntactic": [...],
"semantic": [...],
"union": [...],
"enhanced": [...],
"explanation": {...}
}
}
Parameters
Beside the paper(s), the function running the CSO Classifier accepts seven additional parameters: (i) workers, (ii) modules, (iii) enhancement, (iv) explanation, (v) delete_outliers, (vi) fast_classification, (vii) silent, and (ix) filter_by. There is no particular order on how to specify these paramaters. Here we explain their usage. The workers parameters is an integer (equal or greater than 1), modules and enhancement are strings that define a particular behaviour for the classifier. The explanation, delete_outliers, fast_classification, and silent parameters are booleans. Finally, filter_by is a list
(i) The parameter workers defines the number of threads to run for classifying the input corpus. For instance, if workers = 4, there will be 4 instances of the CSO Classifier, each one receiving a chunk (equally split) of the corpus to process. Once all processes are completed, the results will be aggregated and returned. The default value for workers is 1. This parameter is available only when running the classifier in batch mode.
(ii) The parameter modules can be either "syntactic", "semantic", or "both". Using the value "syntactic", the classifier will run only the syntactic module. Using the "semantic" value, instead, the classifier will use only the semantic module. Finally, using "both", the classifier will run both syntactic and semantic modules and combine their results. The default value for modules is both.
(iii) The parameter enhancement can be either "first", "all", or "no". This parameter controls whether the classifier will try to infer, given a topic (e.g., Linked Data), only the direct super-topics (e.g., Semantic Web) or all its super-topics (e.g., Semantic Web, WWW, Computer Science). Using "first" as a value will infer only the direct super topics. Instead, if using "all", the classifier will infer all its super-topics. Using "no" the classifier will not perform any enhancement. The default value for enhancement is first.
(iv) The parameter explanation can be either True or False. This parameter defines whether the classifier should return an explanation. This explanation consists of chunks of text, coming from the input paper, that allowed the classifier to return a given topic. This supports the user in better understanding why a certain topic has been inferred. The classifier will return an explanation for all topics, even for the enhanced ones. In this case, it will join all the text chunks of all its sub-topics. The default value for explanation is False.
(v) The parameter delete_outliers can be either True or False. This parameter controls whether to run the outlier detection component within the post-processing module. This component improves the results by removing erroneous topics that were conceptually distant from the others. Due to their computation, users might experience slowdowns. For this reason, users can decide between good results and low computational time or improved results and slower computation. The default value for delete_outliers is True.
(vi) The parameter fast_classification can be either True or False. This parameter determines whether the semantic module should use the full model or the cached one. Using the full model provides slightly better results than the cached one. However, using the cached model is more than 15x faster. Read here for more details about these two models. The default value for fast_classification is True.
(vii) The parameter get_weights can be either True or False. This determines whether the classifier returns the weights associated to the identified topics. For the syntactic topics these represent the value of string similarity (Levenshtein) of topics compared the chunks of text identified in the input text. Whereas, the weights for the semantic topics correspond to the normalised values from the topic distribution obtained from running the semantic module.
(viii) The parameter silent can be either True or False. This determines whether the classifier prints its progress in the console. If set to True, the classifier will be silent and will not print any output while classifying. The default value for silent is False.
(ix) The parameter filter_by is a list, containing CSO topic, and lets you focus the classification on specific sub-branches of CSO. For instance, to narrow down the results to subtopics within artificial intelligence and semantic web you can set filter_by = ["artificial intelligence", "semantic web"]. This will produce four extra outputs (syntactic_filtered, semantic_filtered, union_filtered, enhanced_filtered) containing only the CSO topics that fall under the hierarchical structure of the specified areas. By default this parameter is an empty list, and therefore the classifier will consider all CSO topics as usual. You can check Run on Single Paper with filter_by to see how it works.
| # | Parameter | Single Paper | Batch Mode |
|---|---|---|---|
| i | workers | :x: | :white_check_mark: |
| ii | modules | :white_check_mark: | :white_check_mark: |
| iii | enhancement | :white_check_mark: | :white_check_mark: |
| iv | explanation | :white_check_mark: | :white_check_mark: |
| v | delete_outliers | :white_check_mark: | :white_check_mark: |
| vi | fast_classification | :white_check_mark: | :white_check_mark: |
| vii | get_weights | :white_check_mark: | :white_check_mark: |
| viii | silent | :white_check_mark: | :white_check_mark: |
| ix | filter_by | :white_check_mark: | :white_check_mark: |
Table 1: Parameters availability when using CSO Classifier
Croissant Specification
From CSO Classifier v4.0.0 it is possible to retrieve the croissant specifications of the performed classifications. This will generate a metadata file in json format containing the description of the dataset produced by the classifier. This feature is particularly useful for organising the data and the metadata of the newly produced dataset using the CSO Classifier, adhering to the Croissant format for ML-ready datasets.
The structure of the generated specification depends on the parameters used during the initialization of the classifier (e.g., explanation, get_weights). For instance, if explanation is set to True, the metadata will include the field description for the explanation.
To generate the Croissant specification, you can use the get_croissant_specification method:
from cso_classifier import CSOClassifier
cc = CSOClassifier(modules = "both", enhancement = "first", explanation = True)
cc.get_croissant_specification(filename="metadata.json", print_output=True)
A speciment of Croissant 🥐 specification can be found https://cso.kmi.open.ac.uk/download/resources/croissant_base.json.
Releases
Here we list the available releases for the CSO Classifier. These releases are available for download both from Github and Zenodo.
v4.0.1
This minor release introduces a bug fix related to package dependencies. In particular, we removed the click requirement, which was causing conflicts with nltk and other packages. This change ensures a smoother installation process and better compatibility across different environments.
v4.0.0
This major release marks a significant milestone for the CSO Classifier, bringing it up to speed with the latest Python standards and enhancing its core capabilities. Key updates include:
- Python 3.11 and 3.12 support: The classifier now officially supports Python versions 3.11 and 3.12.
- Updated Word2vec Model: The underlying Word2vec model has been updated with papers up to 2025, enhancing its semantic understanding. See here.
- Croissant Specification: The classifier now supports the generation of Croissant metadata for the classification results. See here.
- Extended Documentation: The documentation has been expanded to provide more comprehensive guidance and examples.
- Improved Codebase: General code improvements have been implemented for better performance and maintainability.
For the development of this version, we would like to thank Faisal Ramzan, PhD Student at the University of Cagliari for supporting the development of this new version and the deployment of the recent word2vec model.
v3.3
This release extends version 3.2 with a new feature that lets you refine the classification process by focusing on specific areas within the Computer Science Ontology. Specifically, providing one or more topics within the parameter filter_by (type list), the classifier will extract the sub-branches of such CSO topics, and when classifying will narrow down the output to the only sub-topics available in those areas. This is especially helpful when you are interested in exploring specific branches of the CSO, such as identifying only the concepts related to artificial intelligence and semantic web within a given paper, and can be achieved by setting filter_by = ["artificial intelligence", "semantic web"] (see Parameters). If this parameter is set, the classifier will return the standard classification results, with four extra sets of results (syntactic_filtered, semantic_filtered, union_filtered, enhanced_filtered) containing only the filtered topics. This gives users the full picture and a focused view within the chosen areas.
Download from:

We would like to express our gratitude to Stanford University, specifically Dr. Loredana Fattorini and Dr. Nestor Maslej, for their financial support in developing this version. Their application of the CSO Classifier in the 2025 AI Index report was instrumental to this project. Additional details can be found: https://www.salatino.org/wp/artificial-intelligence-index-report-2025/.
v3.2
This release extends version 3.1 by supporting users in exporting the weights associated to the identified topics. If enabled, within the result of the classification, the classifier include two new keys syntactic_weights and semantic_weights which respectively contain the identified syntactic and semantic topics as keys, and their weights as values.
This component is disabled by default and can be enabled by setting get_weights = True when calling the CSO Classifier (see Parameters).
v3.1
This release brings in two main changes. The first change is related to the library (and the code) to perform the Levenshtein similarity. Before we relied on python-Levenshtein which required python3-devel. This new version uses rapidfuzz which as fast as the previous library and it is much easier to install on the various systems.
The second change is related to an updated list of dependencies. We updated some libraries including igraph.
Download from:

v3.0
This release welcomes some improvements under the hood. In particular:
- we refactored the code, reorganising scripts into more elegant classes
- we added functionalities to automatically setup and update the classifier to the latest version of CSO
- we added the explanation feature, which returns chunks of text that allowed the classifier to infer a given topic
- the syntactic module takes now advantage of Spacy POS tagger (as previously done only by semantic module)
- the grammar for the chunk parser is now more robust:
{<JJ.*>*<HYPH>*<JJ.*>*<HYPH>*<NN.*>*<HYPH>*<NN.*>+}
In addition, in the post-processing module, we added the outlier detection component. This component improves the accuracy of the result set, by removing erroneous topics that were conceptually distant from the others. This component is enabled by default and can be disabled by setting delete_outliers = False when calling the CSO Classifier (see Parameters).
Please, be aware that having substantially restructured the code into classes, the way of running the classifier has changed too. Thus, if you are using a previous version of the classifier, we encourage you to update it (pip install -U cso-classifier) and modify your calls to the classifier, accordingly. Read our usage examples.
We would like to thank James Dunham @jamesdunham from CSET (Georgetown University) for suggesting to us how to improve the code.
More details about this version of the classifier can be found within:
Salatino, A., Osborne, F., & Motta, E. (2022). CSO Classifier 3.0: a Scalable Unsupervised Method for Classifying Documents in terms of Research Topics. International Journal on Digital Libraries, 1-20. Read more
Download from:

v2.3.2
Version alignement with Pypi. Similar to version 2.3.1.
Download from:

v2.3.1
Bug Fix. Added some exception handles. Notice: Please note that during the upload of this version on Pypi (python index), we encountered some issues. We can't guarantee this version will work properly. To this end, we created a new release: v2.3.2. Use this last one, please. Apologies for any inconvenience.
v2.3
This new release contains a bug fix and the latest version of the CSO ontology.
Bug Fix: When running in batch mode, the classifier was treating the keyword field as an array instead of a string. In this way, instead of processing keywords (separated by comma), it was processing each single letters, hence inferring wrong topics. This now has been fixed. In addition, if the keyword field is actually an array, the classifier will first 'stringify' it and then process it.
We also downloaded and packed the latest version of the CSO ontology.
Download from:

v2.2
In this version (release v2.2), we (i) updated the requirements needed to run the classifier, (ii) removed all unnecessary warnings, and (iii) enabled multiprocessing. In particular, we removed all useless requirements that were installed in development mode, by cleaning the requirements.txt file.
When computing certain research papers, the classifier display warnings raised by the kneed library. Since the classifier can automatically adapt to such warnings, we decided to hide them and prevent users from being concerned about such an outcome.
This version of the classifier provides improved scalability through multiprocessing. Once the number of workers is set (i.e. num_workers >= 1), each worker will be given a copy of the CSO Classifier with a chunk of the corpus to process. Then, the results will be aggregated once all processes are completed. Please be aware that this function is only available in batch mode. See section Classifying in batch mode (BM) for more details.
Download from:

v2.1
This new release (version v2.1) makes the CSO Classifier more scalable. Compared to its previous version (v2.0), the classifier relies on a cached word2vec model which connects the words within the model vocabulary directly with the CSO topics. Thanks to this cache, the classifier is able to quickly retrieve all CSO topics that could be inferred by given tokens, speeding up the processing time. In addition, this cache is lighter (~64M) compared to the actual word2vec model (~366MB), which allows saving additional time at loading time.
Thanks to this improvement the CSO Classifier is around 24x faster and can be easily run on a large corpus of scholarly data.
Download from:

v2.0
The second version (v2.0) implements the CSO Classifier as described in the about section. It combines the topics of both the syntactic and semantic modules and enriches them with their super-topics. Compared to v1.0, it adds a semantic layer that allows generating a more comprehensive result, identifying research topics that are not explicitly available in the metadata. The semantic module relies on a Word2vec model trained on over 4.5M papers in Computer Science. Below we show more in detail how we trained such a model. In this version of the classifier, we pickled the model to speed up the process of loading into memory (~4.5 times faster).
Salatino, A.A., Osborne, F., Thanapalasingam, T., Motta, E.: The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles. In: TPDL 2019: 23rd International Conference on Theory and Practice of Digital Libraries. Springer. Read More
Download from:

v1.0
The first version (v1.0) of the CSO Classifier is an implementation of the syntactic module, which was also previously used to support the semi-automatic annotation of proceedings at Springer Nature [1]. This classifier aims at syntactically match n-grams (unigrams, bigrams and trigrams) of the input document with concepts within CSO.
More details about this version of the classifier can be found within:
Salatino, A.A., Thanapalasingam, T., Mannocci, A., Osborne, F. and Motta, E. 2018. Classifying Research Papers with the Computer Science Ontology. ISWC-P&D-Industry-BlueSky 2018 (2018). Read more
Download from:
List of Files
- CSO-Classifier.ipynb: :page_facing_up: Python notebook for executing the classifier
- CSO-Classifier.py: :page_facing_up: Python script for executing the classifier
- images: :file_folder: folder containing some pictures, e.g., the workflow showed above
- cso_classifier: :file_folder: Folder containing the main functionalities of the classifier
- classifier.py: :page_facing_up: class that implements the CSO Classifier
- syntacticmodule.py: :page_facing_up: class that implements the syntactic module
- semanticmodule.py: :page_facing_up: class that implements the semantic module
- postprocmodule.py: :page_facing_up:
- paper.py: :page_facing_up: class that implements the functionalities to operate on papers, such as POS tagger, grammar-based chunk parser
- result.py: :page_facing_up: class that implements the functionality to operate on the results
- ontology.py: :page_facing_up: class that implements the functionalities to operate on the ontology: get primary label, get topics and so on
- model.py: :page_facing_up: class that implements the functionalities to operate on the word2vec model: get similar words and so on
- misc.py: :page_facing_up: some miscellaneous functionalities
- test.py: :page_facing_up: some test functionalities
- config.py: :page_facing_up: class that implements the functionalities to operate on the config file
- config.ini: :page_facing_up: config file. It contains all information about packaage, ontology and model.
- assets: :file_folder: Folder containing the word2vec model and CSO
- cso.csv: :page_facing_up: file containing the Computer Science Ontology in csv
- cso.p: :page_facing_up: serialised file containing the Computer Science Ontology (pickled)
- cso_graph.p :page_facing_up: file containing the Computer Science Ontology as an iGraph object
- model.p: :page_facing_up: the trained word2vec model (pickled)
- token-to-cso-combined.json: :page_facing_up: file containing the cached word2vec model. This json file contains a dictionary in which each token of the corpus vocabulary, has been mapped with the corresponding CSO topics. Below we explain how this file has been generated.
- croissant_base.json: :page_facing_up: file containing the base structure for the Croissant metadata specification. It is used to generate a JSON-LD file that describes the dataset produced by the classifier, adhering to the Croissant format for ML-ready datasets.
Word2vec model and token-to-cso-combined file generation
In this section, we describe how we generated the word2vec model used within the CSO Classifier and what is the token-to-cso-combined file.
Word Embedding generation
To support semantic topic inference at scale, we trained a Word2Vec model on a large collection of scholarly metadata from the Semantic Scholar dataset (≈ 100M papers). The training corpus consists of titles and abstracts (English-only after filtering and cleaning). In our main training run, we processed a dataset containing ~264M text lines.
A key design goal is to preserve ontology concepts and frequent multi-word expressions as single semantic units. We therefore pre-processed the corpus by (i) injecting CSO concept labels into the text and (ii) normalizing multi-word terms into underscore-connected tokens (e.g., “computer science” → computer_science, “large language models” → large_language_models). This ensures that Word2Vec learns dedicated embeddings for ontology concepts rather than distributing their meaning across individual words. In addition, we build bigrams and trigrams from the corpus to stabilize other frequent phrases that are not explicitly present in the ontology but are common in scholarly writing.
We train Word2Vec using the latest Gensim 4.x implementation with the following hyperparameters:
| parameter | value |
|---|---|
| architecture | skip-gram |
| vector size | 256 |
| window size | 10 |
| min count | 10 |
Upon completion of training, we generated a gensim.models.keyedvectors.KeyedVectors object with a file size of approximately 2GB. We serialized (pickled) this model to ensure it loads significantly faster than using the standard loading method, making it efficient for use in any Python workspace. You can download this model from here.
For CSO Classifier versions before 4.0.0, we employed a gensim.models.keyedvectors.Word2VecKeyedVectors object weighing 366MB, which can be downloaded from here.
Cached semantic mapping (token-to-cso-combined.json)
Direct semantic inference can be expensive at inference time because it requires repeatedly querying the embedding model (e.g., retrieving nearest neighbors) and matching results back to ontology concepts. To eliminate this bottleneck, from the original model we precomputed a cached mapping file named token-to-cso-combined.json.
The cache is a dictionary that links each token in the Word2Vec vocabulary to the CSO concepts it can trigger. The cached mapping is generated as follows:
- Collect all tokens in the Word2Vec vocabulary.
- For each token, retrieve its top-N nearest neighbors using
most_similar()(defaulttop_n = 10) and keep only neighbors above a cosine similarity threshold (word_similarity = 0.7). - Compare each retrieved neighbor term against the normalized CSO concept labels using Levenshtein string similarity.
- If the similarity exceeds a strict threshold (
min_similarity = 0.90), store a mapping from the original token to the matching CSO concept(s).
This cached model allows the classifier to infer ontology topics in near-constant time per token, avoiding repeated nearest-neighbor searches and repeated ontology matching during document classification. As a result, the runtime bottleneck shifts from semantic lookup to lightweight text preprocessing, significantly improving throughput for large-scale annotation.
The code for pre-processing data, training the model, and generating the cached mapping file can be found in this GitHub repository. We are thankful to Faisal Ramzan (PhD student at the University of Cagliari) for his support.
Use the CSO Classifier in other domains of Science
In order to use the CSO Classifier in other domains of Science, it is necessary to replace the two external sources mentioned in the previous section. In particular, there is a need for a comprehensive ontology or taxonomy of research areas, within the new domain, which will work as a controlled list of research topics. In addition, it is important to train a new word2vec model that fits the language model and the semantic of the terms, in this particular domain. We wrote a blog article on how to integrate knowledge from other fields of Science within the CSO Classifier.
Please read here for more info: How to use the CSO Classifier in other domains
How to Cite CSO Classifier
We kindly ask that any published research making use of the CSO Classifier cites our paper listed below:
Salatino, A.A., Osborne, F., Thanapalasingam, T., Motta, E.: The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles. In: TPDL 2019: 23rd International Conference on Theory and Practice of Digital Libraries. Springer.
License
References
[1] Osborne, F., Salatino, A., Birukou, A. and Motta, E. 2016. Automatic Classification of Springer Nature Proceedings with Smart Topic Miner. The Semantic Web -- ISWC 2016. 9982 LNCS, (2016), 383–399. DOI:https://doi.org/10.1007/978-3-319-46547-0_33
[2] Mikolov, T., Chen, K., Corrado, G. and Dean, J. 2013. Efficient Estimation of Word Representations in Vector Space. (Jan. 2013).
[3] Mikolov, T., Chen, K., Corrado, G. and Dean, J. 2013. Distributed Representations of Words and Phrases and their Compositionality. Advances in neural information processing systems. 3111–3119.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file cso_classifier-4.0.1.tar.gz.
File metadata
- Download URL: cso_classifier-4.0.1.tar.gz
- Upload date:
- Size: 78.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d20643e6a0571da9e2f52b110b5b27c7a9c2a688602f97534c4de61bf66a84df
|
|
| MD5 |
7afc5821877f1af37ff379f4445faaec
|
|
| BLAKE2b-256 |
ebe1ba6d7b29a161766c08694aaff7f2cf3a01f7981742397fb30e4616974b2d
|
File details
Details for the file cso_classifier-4.0.1-py3-none-any.whl.
File metadata
- Download URL: cso_classifier-4.0.1-py3-none-any.whl
- Upload date:
- Size: 56.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0599a42524d75868458777f46ed65508f2fb8841f8fec291ca46538770247dac
|
|
| MD5 |
39c2405bfb7182250ec8c64ff0b62720
|
|
| BLAKE2b-256 |
985e37a9daa4f918841aff8ab10a9fba3241242793ef10591bf3ee5b46793a85
|







