Responsible Machine Learning in Python


Project description
dalex
dalex: Responsible Machine Learning in Python




Overview
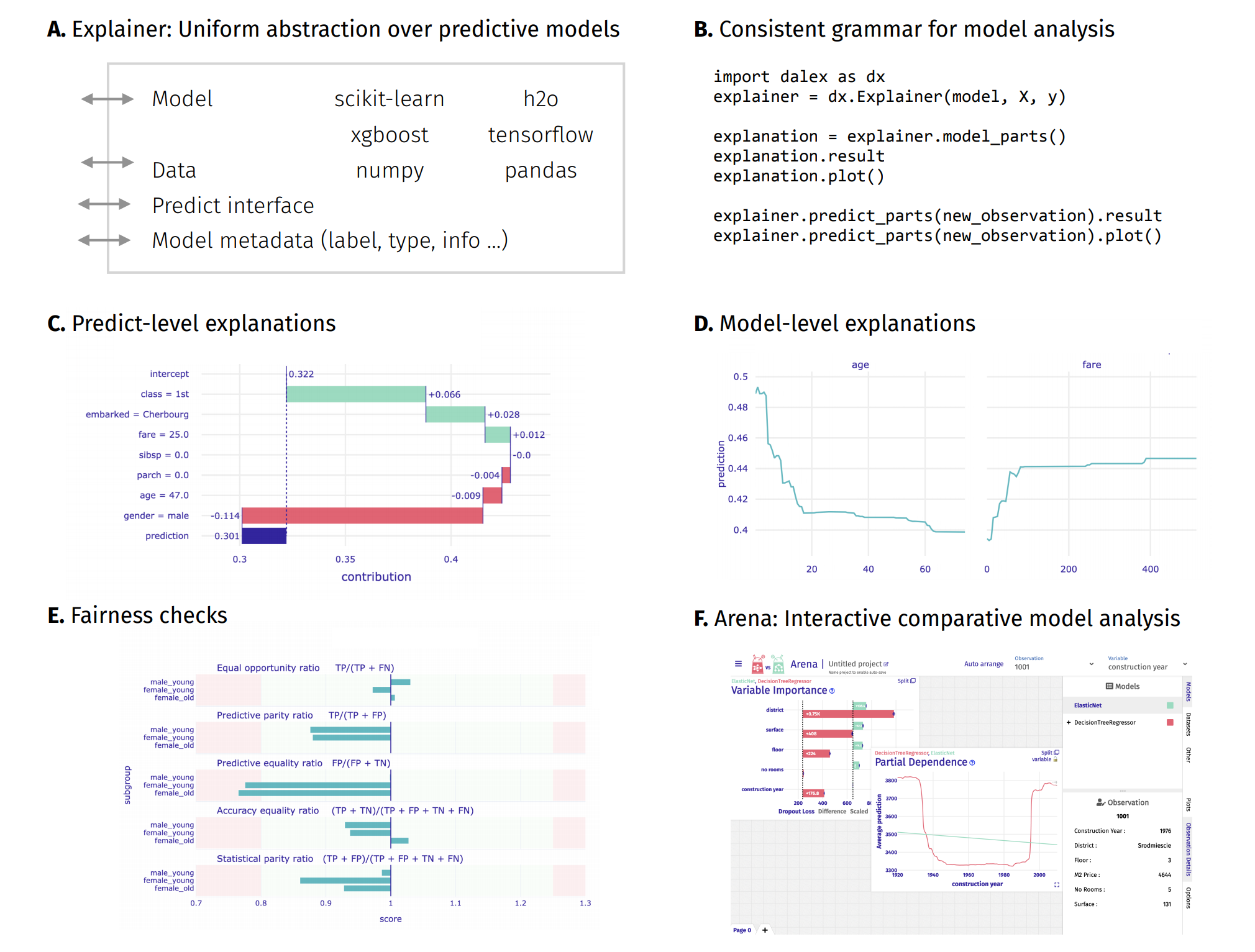
Unverified black box model is the path to the failure. Opaqueness leads to distrust. Distrust leads to ignoration. Ignoration leads to rejection.
The dalex package xrays any model and helps to explore and explain its behaviour, helps to understand how complex models are working.
The main Explainer object creates a wrapper around a predictive model. Wrapped models may then be explored and compared with a collection of model-level and predict-level explanations. Moreover, there are fairness methods and interactive exploration dashboards available to the user.
The philosophy behind dalex explanations is described in the Explanatory Model Analysis book.
Installation
The dalex package is available on PyPI and conda-forge.
pip install dalex -U
conda install -c conda-forge dalex
One can install optional dependencies for all additional features using pip install dalex[full].
Resources: https://dalex.drwhy.ai/python
API reference: https://dalex.drwhy.ai/python/api
Authors
The authors of the dalex package are:
- Hubert Baniecki
- Wojciech Kretowicz
- Piotr Piatyszek maintains the
arenamodule - Jakub Wisniewski maintains the
fairnessmodule - Mateusz Krzyzinski maintains the
aspectmodule - Artur Zolkowski maintains the
aspectmodule - Przemyslaw Biecek
We welcome contributions: start by opening an issue on GitHub.
Citation
If you use dalex, please cite our JMLR paper:
@article{JMLR:v22:20-1473,
author = {Hubert Baniecki and
Wojciech Kretowicz and
Piotr Piatyszek and
Jakub Wisniewski and
Przemyslaw Biecek},
title = {dalex: Responsible Machine Learning
with Interactive Explainability and Fairness in Python},
journal = {Journal of Machine Learning Research},
year = {2021},
volume = {22},
number = {214},
pages = {1-7},
url = {http://jmlr.org/papers/v22/20-1473.html}
}
Changelog
v1.8.0 (2026-01-20)
- substitute the deprecated
pkg_resourcesdependency that breaksdalex(#579) - increase the
plotlydependency to>=6.0.0and fix compatibility issues with the new version, e.g.titlefontis nowtitle_font(#573) - restrict the
pandasdependency to<3.0.0to counteract future api changes, e.g.pd.stack(..., future_stack=False). - remove the
ppscoreoptional dependency used by theaspectmodule fromdalex[full]as it imposespandas<2.0.0 - increase the dependency to
python>=3.9and addpython==3.13to CI
v1.7.2 (2025-02-12)
- temporarily restrict the
plotlydependency to<6.0.0, fixing compatibility issues with the new version, e.g.titlefontis nowtitle_font(#573 contributed by @lionelkusch)
v1.7.1 (2024-10-02)
numpy>=2.0.0compatibility: replace instances ofx.ptp()withnp.ptp(x)andnp.Infwithnp.inf(#571)- added a way to pass
sample_weightto loss functions inmodel_parts()(variable importance) usingweightsfromdx.Explainer(#563) - fixed the visualization of
shap_wrapperforshap==0.45.0
v1.7.0 (2024-02-28)
- increase the dependencies to
python>=3.8,pandas>=1.5.0,numpy>=1.23.3and addpython==3.11to CI - added
keras.src.models.sequential.Sequentialto classes with a knownpredict_function; it should fix changes inkeras==3.0.0andtensorflow==2.16.0 - turn off
verbosein the predict method of tensorflow/keras models that changed intensorflow>=2.9.0 - update the warning occurring when specifying
variable_splits(#558) - fix an error occuring in
predict_profile()when a DataFrame has MultiIndex inpandas>=1.3.0(#550) - fix gaussian
norm()calculation inmodel_profile()frompi*sqrt(2)tosqrt(2*pi) - fix a warning (future error) between
prepare_numerical_categorical()andprepare_x()withpandas==2.1.0 - fix a warning (future error) concerning the default value of
numeric_onlyinpandas.DataFrame.corr()indalex.aspect.calculate_assoc_matrix()
v1.6.0 (2023-02-16)
- add
ZeroDivisionErrorto precision and recall functions (#532) - add a warning to
calculate_depend_matrix()when there is a variable with only one value (#537) - fix missing EDA plots in (Python) Arena (#544)
- fix baseline positions in the subplots of the predict parts explanations: BreakDown, Shap (#545)
v1.5.0 (2022-09-07)
This release consists of mostly maintenance updates and, after a year, marks the Beta -> Stable release.
- increase the dependency from
python>=3.6topython>=3.7(at this moment, bothnumpyandpandasdepend onpython>=3.8), and addpython==3.10to CI - increase the dependencies to
pandas>=1.2.5,numpy>=1.20.3(#526),scipy>=1.6.3,plotly>=5.1.0, andtqdm>=4.61.2due to errors withpandas(see tqdm/#1199) - remove the use of
pd.Series.append()(#489) - remove the use of
np.isnancausing error indalex.fairness(#491) - fix iBreakDown plot y-axis labels (#493)
- stop the Arena's
werkzeugserver using a clearner and still supported API (#518)
v1.4.1 (2021-11-08)
features
- added fairness plot for regression models to
Arena(dalex/#408) - added new
facet_scalesparameter toAP.plotandCP.plot, which allows to free the y-axis withfacet_scales="free"(dalex/#469); consistent with R (DALEX/#468, ingredients/#140)
fixes
- fixed
APandCPprogress bars
v1.4.0 (2021-09-09)
- added new
aspectmodule, which will focus on groups of dependent variables @krzyzinskim & @arturzolkowski - added new
scipy>=1.5.4dependency
breaking changes
- improved the calculation of AUC, ROC plot (#459)
fixes
- wrong yaxis labels in
VariableImportance.plot(split="variable")(#451) repr_html()didn't work for explanation objects before using thefitmethod (#449)
features
- added new
Aspectobject with thepredict_triplot,model_triplot,predict_parts,model_parts,get_aspectsmethods - added new
PredictTriplot,ModelTriplot,PredictAspectImportance,ModelAspectImportanceobjects with theplotmethod
v1.3.0 (2021-07-17)
features
- added bias mitigation techniques (
resample,reweight,roc_pivot) into thefairnessmodule (#432)
v1.2.0 (2021-05-31)
breaking changes
- method
set_optionsin Arena now takiesoption_categoryinstead ofplot_type(SHAPValues=>ShapleyValues,FeatureImportance=>VariableImportance) (#420) - methods using the
Nparameter now properly sample rows fromdata
fixes
- fixed wrong error value when no
predict_functionis found inExplainer(77ca90d) - set multiprocessing context to
'spawn'(#412) - fixed bug in
metric_scoresplot that made only one subgroup appear on y-axis (#416) - added support for older keras models (#415)
features
- added a resource mechanism to Arena (#419)
- added
ShapleyValuesImportanceandShapleyValuesDependenceplots to Arena (#420) - return
errorinstead ofNaNwhen AUC is calculated on observations from one class only (#415)
v1.1.0 (2021-04-18)
breaking changes
- fixed concurrent random seeds when
processes > 1(#392), which means that the results of parallel computation will vary betweenv1.1.0and previous versions
fixes
GroupFairnessX.plot(type='fairness_check')generates ticks according to the x-axis range (#409)GroupFainressRegression.plot(type='density')has a more readable hover - only for outliers (#409)BreakDown.plot()wrongly displayed the "+all factors" bar whenmax_vars < p(#401)GroupFairnessClassification.plot(type='metric_scores')did not handleNaN's (#399)
features
- Experimental support for regression models in the
fairnessmodule. AddedGroupFairnessRegressionobject, with theplotmethod having two types:fairness_checkanddensity.Explainer.model_fairnessmethod now depends on themodel_typeattribute. (#391) - added
Nparameter to thepredict_partsmethod which isNoneby default (#402) epsilonis now an argument of theGroupFairnessClassificationobject (#397)
v1.0.1 (2021-02-19)
fixes
- fixed broken range on
yaxisinfairness_checkplot (#376) - warnings because
np.floatis depracated sincenumpyv1.20 (#384)
other
- added
ipythonto test dependencies
v1.0.0 (2020-12-29)
breaking changes
These are summed up in (#368):
- rename modules:
dataset_levelintomodel_explanations,instance_levelintopredict_explanations,_arenamodule intoarena - use
__dir__method to define autocompletion in IPython environment - show only['Explainer', 'Arena', 'fairness', 'datasets'] - add
plotmethod andresultattribute toLimeExplanation(uselime.explanation.Explanation.as_pyplot_figure()andlime.explanation.Explanation.as_list()) CeterisParibus.plot(variable_type='categorical')now has horizontal barplots -horizontal_spacing=Noneby default (varies onvariable_type). Also, once again added the "dot" for observation value.predict_fninpredict_surrogatenow usespredict_function(trying to make it work for more frameworks)
fixes
- fixed wrong verbose output when any value in
y_hat/residualswas anintnotfloat - added proper
"-"sign to negative dropout losses inVariableImportance.plot
features
- added
geom='bars'toAggregateProfiles.plotto force the categorical plot - added
geom='roc'andgeom='lift'toModelPerformance.plot - added Fairness plot to Arena
other
- remove
colorizefromExplainer - updated the documentation, refactored code (import modules not functions, unify variable names in
object.py, move utils funcitons fromchecks.pytoutils.py, etc.) - added license notice next to data
v0.4.1 (2020-12-03)
- added support for
h2o.estimators.*(#332) - added
tensorflow.python.keras.engine.functional.Functionalto thetensorflowlist - updated the
plotlydependency to>=4.12.0 - code maintenance:
yhat,check_data
fixes
- fixed
check_if_empty_fields()used in loading theExplainerfrom a pickle file, since several checks were changed - fixed
plot()method inGroupFairnessClassificationas it omitted plotting a metric whenNaNwas present in metric ratios (result) - fixed
dragonsandHRdatasets having,delimeter instead of., which transformed numerical columns into categorical. - fixed representation of the
ShapWrapperclass (removed_repr_html_method)
features
- allow for
yto be apandas.DataFrame(converted) - allow for
data,yto be aH2OFrame(converted) - added
labelparameter to all the relevantdx.Explainermethods, which overrides the default label in explanation'sresult - now using
GradientExplainerfortf.keras.engine.sequential.Sequential, added proper warning whenshap_explainer_typeisNone(#366)
defaults
- unify verbose output of
Explainer
v0.4.0 (2020-11-17)
- added new
arenamodule, which adds the backend for Arena dashboard @piotrpiatyszek
features
- added new aliases to
dx.Explainermethods (#350) inmodel_partsit is{'permutational': 'variable_importance', 'feature_importance': 'variable_importance'}, inmodel_profileit is{'pdp': 'partial', 'ale': 'accumulated'} - added
Arenaobject for dashboard backend. See https://github.com/ModelOriented/Arena - new
fairnessplot types:stacked,radar,performance_and_fairness,heatmap,ceteris_paribus_cutoff - upgraded
fairness_check()
v0.3.0 (2020-10-26)
- added new
fairnessmodule, which will focus on bias detection, visualization and mitigation @jakwisn
fixes
- removed unnecessary warning when
precalculate=False and verbose=False(#340)
features
- added
model_fairnessmethod to theExplainer, which performs fairness explanation - added
GroupFairnessClassificationobject, with theplotmethod having two types:fairness_checkandmetric_scores
defaults
- added the
N=50000argument toResidualDiagnostics.plot, which samples observations from theresultparameter to omit performance issues whensmooth=True(#341)
v0.2.2 (2020-09-21)
- added support for
tensorflow.python.keras.engine.sequential.Sequentialandtensorflow.python.keras.engine.training.Model(#326) - updated the
tqdmdependency to>=4.48.2,pandasdependency to>=1.1.2andnumpydependency to>=1.18.4
fixes
- fixed the wrong order of
Explainerverbose messages - fixed a bug that caused
model_infoparameter to be overwritten by the default values - fixed a bug occurring when the variable from
groupswas not ofstrtype (#327) - fixed
model_profile:variable_type='categorical'not working when user passedvariablesparameter (#329) + the reverse order of bars in'categorical'plots + (again) addedvariable_splits_typeparameter tomodel_profileto specify how grid points shall be calculated (#266) + allow for both'quantile'and'quantiles'types (alias)
features
- added informative error messages when importing optional dependencies (#316)
- allow for
dataandyto beNone- added checks inExplainermethods
defaults
- wrong parameter name
title_xchanged toy_titleinCeterisParibus.plotandAggregatedProfiles.plot(#317) - now warning the user in
Explainerwhenpredict_functionreturns an error or doesn't returnnumpy.ndarray (1d)(#325)
v0.2.1 (2020-08-31)
- updated the
pandasdependency to>=1.1.0
fixes
ModelPerformance.plotnow uses a drwhy color palette- use
uniquemethod instead ofnp.uniqueinvariable_splits(#293) v0.2.0didn't export new datasets- fixed a bug where
predict_parts(type='shap')calculated wrongcontributions(#300) model_profileuses observation mean instead of profile mean in_yhat_centering- fixed barplot baseline in categorical
model_profileandpredict_profileplots (#297) - fixed
model_profile(type='accumulated')giving wrong results (#302) - vertical/horizontal lines in plots now end on the plot edges
features
- added new
type='shap_wrapper'topredict_partsandmodel_partsmethods, which returns a newShapWrapperobject. It contains the main result attribute (shapley_values) and the plot method (force_plotandsummary_plotrespectively). These come from the shap package Explainer.predictmethod now acceptsnumpy.ndarray- added the
ResidualDiagnosticsobject with aplotmethod - added
model_diagnosticsmethod to theExplainer, which performs residual diagnostics - added
predict_surrogatemethod to theExplainer, which is a wrapper for thelimetabular explanation from the lime package - added
model_surrogatemethod to theExplainer, which creates a basic surrogate decision tree or linear model from the black-box model using the scikit-learn package - added a
_repr_html_method to all of the explanation objects (it prints theresultattribute) - added
dalex.__version__ - added informative error messages in
Explainermethods whenyis of wrong type (#294) CeterisParibus.plot(variable_type='categorical')now allows for multiple observations- new verbose checks for
model_type - add
typetomodel_infoindumpanddumpsfor R compatibility (#303) ModelPerformance.resultnow haslabelas index
defaults
- removed
_grid_column inAggregatedProfiles.resultandcenteronly works withtype=accumulated - use
Pipeline._final_estimatorto extractmodel_classof the actual model - use
model._estimator_typeto extractmodel_typeif possible
v0.2.0 (2020-08-07)
- major documentation update (#270)
- unified the order of function parameters
fixes
v0.1.9had wrong_original_column inpredict_profilevertical_spacingacts as intended inVariableImportance.plotwhensplit='variable'loss_function='auc'now usesloss_one_minus_aucas this should be a descending measure- plots are now saved with the original height and width
model_profilenow properly passes thevariablesparameter toCeterisParibusvariablesparameter inpredict_profilenow can also be a string
features
- use
px.expressinstead of coreplotlyto makemodel_profileandpredict_profileplots; thus, enhance performance and scalability - added
verboseparameter wheretqdmis used to verbose progress bar - added
loss_one_minus_aucfunction that can be used withloss_function='1-auc'inmodel_parts - added new example data sets:
apartments,dragonsandhr - added
color,opacity,title_xparameters tomodel_profileandpredict_profileplots (#236), changed tooltips and legends (#262) - added
geom='profiles'parameter tomodel_profileplot andraw_profilesattribute toAggregatedProfiles - added
variable_splits_typeparameter topredict_profileto specify how grid points shall be calculated (#266) - added
variable_splits_with_obsparameter topredict_profilefunction to extend split points with observation variable values (#269) - added
variable_splitsparameter tomodel_profile
defaults
- use different
loss_functionfor classification and regression (#248) - models that use
probayhats now getmodel_type='classification'if it's not specified - use uniform way of grid points calculation in
predict_profileandmodel_profile(seevariable_splits_typeparameter) - add the variable values of
new_observationtovariable_splitsinpredict_profile(seevariable_splits_with_obsparameter) - use
N=1000inmodel_partsandN=300inmodel_profileto comply with the R version keep_raw_permutationis now set toFalseinstead ofNoneinmodel_partsinterceptparameter inmodel_profileis now namedcenter
v0.1.9 (2020-07-01)
- feature: added
random_stateparameter forpredict_parts(type='shap')andmodel_profilefor reproducible calculations - fix: fixed
random_stateparameter inmodel_parts - feature: multiprocessing added for:
model_profile,model_parts,predict_profileandpredict_parts(type='shap'), through theprocessesparameter - fix: significantly improved the speed of
accumulatedandconditionaltypes inmodel_profile - bugfix: use pd.api.types.is_numeric_dtype()
instead of
np.issubdtype()to cover more types; e.g. it caused errors withstringtype - defaults: use pd.convert_dtypes()
on the result of
CeterisParibusto fix variable dtypes and later allow for a concatenation without the dtype conversion - fix:
variablesparameter now can be a singlestrvalue - fix: number rounding in
predict_parts,model_parts(#245) - fix: CP calculations for models that take only variables as an input
v0.1.8 (2020-05-28)
- bugfix:
variable_splitsparameter now works correctly inpredict_profile - bugfix: fix baseline for 3+ models in
AggregatedProfiles.plot(#234) - printing: now rounding numbers in
Explainermessages - fix: minor checks fixes in
instance_level - bugfix:
AggregatedProfiles.plotnow works withgroups
v0.1.7 (2020-05-10)
- feature: parameter
Ninmodel_profilecan be set toNone, to select all observations - input:
groupsandvariableparameters inmodel_profilecan be:str,list,numpy.ndarray,pandas.Series - fix:
check_labelreturned only a first letter - bugfix: removed the conversion of
all_variablestostrinprepare_all_variables, which caused an error inmodel_profile(#214) - defaults: change numpy data variable names from numbers to strings
v0.1.6 (2020-04-30)
- fix: change
short_nameencoding infifadataset (utf8->ascii) - fix: remove
scipydependency - defaults: default
loss_root_mean_squarein model parts changed tormse - bugfix: checks related to
new_observationinBreakDown, Shap, CeterisParibusnow work for multiple inputs (#207) - bugfix:
CeterisParibus.fitandCeterisParibus.plotnow work for more types ofnew_observation.index, but won't work for aboleantype (#211)
v0.1.5 (2020-04-21)
- feature: add
xgboostpackage compatibility (#188) - feature: added
model_classparameter toExplainerto handle wrapped models - feature:
Exaplainerattributemodel_inforemembers if parameters are default - bugfix:
variable_groupsparameter now works correctly inmodel_parts - fix: changed parameter order in
Explainer:model_type,model_info,colorize - documentation:
model_partsdocumentation is updated - feature: new
showparameter inplotmethods that (if False) returnsplotly Figure(#190) - feature:
load_fifa()function which loads the preprocessed players_20 dataset - fix:
CeterisParibus.plottooltip
v0.1.4 (2020-04-14)
- feature: new
Explainer.residualmethod which usesresidual_functionto calculateresiduals - feature: new
dumpanddumpsmethods for savingExplainerin a binary form;loadandloadsmethods for loadingExplainerfrom binary form - fix:
Explainerconstructor verbose text - bugfix:
B:=B+1-Shapnow stores average results asB=0and path results asB=1,2,... - bugfix:
Explainer.model_performancemethod usesself.model_typewhenmodel_typeisNone - bugfix: values in
BreakDownandShapare now rounded to 4 significant places (#180) - bugfix:
Shapby default usespath='average',signcolumn is properly updated and bars inplotare sorted byabs(contribution)
v0.1.3 (2020-04-10)
- release of the
dalexpackage Explainerobject withpredict,predict_parts,predict_profile,model_performance,model_partsandmodel_profilemethodsBreakDown,Shap,CeterisParibus,ModelPerformance,VariableImportanceandAggregatedProfilesobjects with aplotmethodload_titanic()function which loads thetitanic_imputeddataset
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dalex-1.8.0.tar.gz.
File metadata
- Download URL: dalex-1.8.0.tar.gz
- Upload date:
- Size: 1.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b81249605fb7b78855f0ac7c81a58a19edf78b0e95e949d08803a54e2fd7ba71
|
|
| MD5 |
33ec830f4a4b3ef59f0028c728db83fb
|
|
| BLAKE2b-256 |
db1fbbb0c0d21d070ed6e356a8fbc76ce8320e5ca1d064e13d02fd0f5c81e14c
|
File details
Details for the file dalex-1.8.0-py3-none-any.whl.
File metadata
- Download URL: dalex-1.8.0-py3-none-any.whl
- Upload date:
- Size: 1.0 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
42493cab3da1fef4f05815f55173066960cbf7d56e0cb0c210965db76b26b95e
|
|
| MD5 |
5ac1365fc9cc43b50ef609babc91b8a5
|
|
| BLAKE2b-256 |
709c39f0a55b3347db8b3d0a76c8060e637dfd1328fd19c05a637533f636b18c
|







