Interactive web-based wizard for importing structured data into Django models.
Project description

Django Data Wizard is an interactive tool for mapping tabular data (e.g. Excel, CSV, XML, JSON) into a normalized database structure via Django REST Framework and IterTable. Django Data Wizard allows novice users to map spreadsheet columns to serializer fields (and cell values to foreign keys) on-the-fly during the import process. This reduces the need for preset spreadsheet formats, which most data import solutions require.
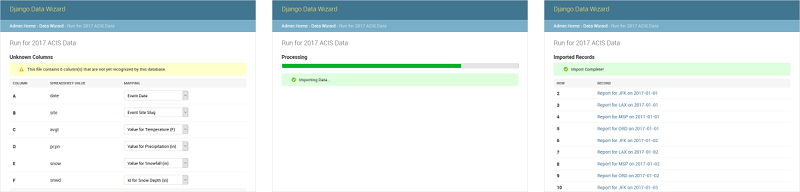
The Data Wizard supports straightforward one-to-one mappings from spreadsheet columns to database fields, as well as more complex scenarios like natural keys and Entity-Attribute-Value (or "wide") table mappings.









Documentation
Django Data Wizard provides a web interface, JSON API, and CLI for specifying a data source to import (e.g. a previously-uploaded file), selecting a serializer, mapping the data columns and identifiers, and (asynchronously) importing the data into any target model in the database.
Data Wizard is designed to allow users to iteratively refine their data import flow. For example, decisions made during an initial data import are preserved for future imports of files with the same structure. The included data model makes this workflow possible.
- Getting Started
- API Documentation
- Advanced Customization
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file data-wizard-2.0.0.tar.gz.
File metadata
- Download URL: data-wizard-2.0.0.tar.gz
- Upload date:
- Size: 246.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.1.0 requests-toolbelt/0.9.1 tqdm/4.41.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d66637824d1636246f891a32ecfb9da759ed78c2dc2ebc057602442fc344538a
|
|
| MD5 |
f41aae962dd16316de945f7459580390
|
|
| BLAKE2b-256 |
e330ddfdf6f1ab46ce9223f954ff0153070e480b96ba13abf8848dde58ddf247
|
File details
Details for the file data_wizard-2.0.0-py3-none-any.whl.
File metadata
- Download URL: data_wizard-2.0.0-py3-none-any.whl
- Upload date:
- Size: 115.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.1.0 requests-toolbelt/0.9.1 tqdm/4.41.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f0e66e807d8509141be7feae62613c39fbb3d72fe672f620810f11ee3b6e6fab
|
|
| MD5 |
be60ddfb5a09023e68b08fad4f45651f
|
|
| BLAKE2b-256 |
f2459346db890ef66f719c1ae67165794214e9ec0d234833697b5b91cfc29954
|







