A Handy Little Tool to aid your Data Science Projects

Project description
DataSwissKnife
A Handy Little Tool to aid your Data Science projects

About
A productivity tool for data science operations to make doing data science simpler and faster, especially for the domain-erudite audience. Created by Ramshankar Yadhunath and Srivenkata Srikanth, with the help of Arvind Sudheer.
Description
DSK is primarily software that has been built with the purpose of aiding anybody who is familiar with necessary domain expertise to do preliminary data science. It works as a handy productivity tool, making preliminary data science operations both simpler as well as faster.
DSK lets users load a raw block of tabular data onto it and asks relevant questions about the kind of operations the user wants to do with the data. DSK then performs these operations of data cleaning, pre-processing, auto-generating visualizations and even some preliminary baseline modelling, all based on the user's response to the questions asked. DSK only makes use of these question-response interactions with the user and thus helps users perform preliminary data science without having to write any code to do so.
The diagram below represents the overall high-level functionality of DSK.
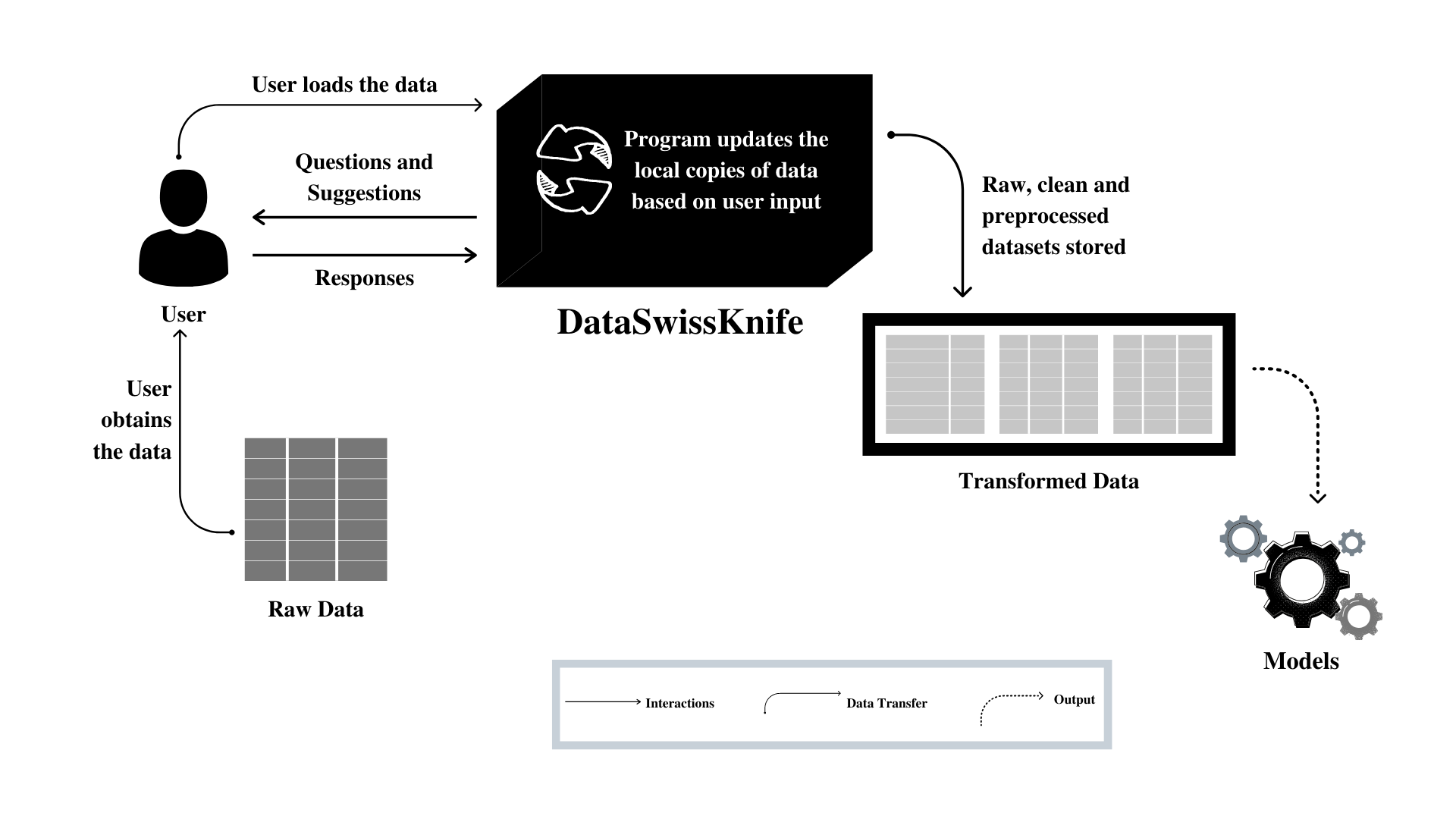
What kind of questions does DSK ask the user?
All questions asked by DSK are ones that require single-character or single-word responses. These include Multiple Choice Questions, Yes/No Questions and Single-Word Answer Questions.
What kind of a tool is DSK?
DSK currently runs only on the command line.
How does DSK help its audience?
Speed and Convenience are two very important considerations for any data science project. Often, the preliminary part of it i.e organizing the project, data cleaning and pre-processing takes up a considerable amount of time, especially if code has to be written for every minor operation that needs to be performed. If data science has to be made simpler and easier for quickly generating essential results(without having to write code), full or partial control has to be transferred from the hands of the user to the system itself. In other words, the system has to be automated.
DSK is an attempt at laying the foundations for a system that will work in automated fashion to help users perform preliminary data science operations without writing code.
Currently, DSK is prototypical and will be scaled to a full product in the future iterations of this project.
Read more about the Vision of DSK here.
DSK has also been created by keeping in the best interests of the research community in mind. Students and researchers from fund-crunched institutes usually cannot afford proprietary tools to help with their research. The non-data technicals, i.e people who are running small businesses are usually discouraged from tapping into data-driven techniques because most tools require an early investment of time and money. The free blogs and articles that talk about data science in general can't convince these businesses. The owners do not know how effectively they could use the data they have. DSK helps bridge this gap. Moreover, DSK is free to use and hence can be of help to anybody who wishes to utilize it.
How does DSK work?
The explanation of data flow through DSK has been moved here. Head over to this link in order to understand how DSK helps an end user. Screenshots of the working have been included.
If you would prefer seeing a video over reading about the working of DSK, this video will help!
Installation and Usage
It is recommended you download and run this project within a virtual environment, in order to ensure that the package installs do not tamper with the versions present in your system. The following links will help you learn why and how to use virtual environments in python.
- http://www.python.education/2017/10/setting-up-virtual-environment-in-python.html (For Windows users)
- https://realpython.com/python-virtual-environments-a-primer/
The instructions to run the tool are as follows :
-
Download or clone this repository onto your local system
-
Extract the repository's contents
-
Navigate to the repository via the command line
-
Run the following command to install all necessary dependencies
pip install -r requirements.txt
-
Run the following command to start the tool
python dataswissknife/main_code.pyTo avoid warnings being displayed, run with
python -W ignore dataswissknife/main_code.py
-
The tool should start in your command line. Follow the prompts.
Contributing
Contributions in the form of feedback or bug reports are most welcome. Currently, we are not accepting code or documentation contributions to the project. We assure you that this is because we have a few more features to add to DSK before we look at the future. As soon as this changes, we will update our guidelines.
How to contribute:
- If you have tried the tool, please do consider leaving your feedback here
- Contact the maintainer at yadramshankar@gmail.com
If you are in need of assistance to use the tool, please contact the maintainer.
Credits
Development Leads
- Ramshankar Yadhunath
- Srivenkata Srikanth
Contributors
- Arvind Sudheer
License
This project is licensed under the MIT License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file dataswissknife-0.1a4.tar.gz.
File metadata
- Download URL: dataswissknife-0.1a4.tar.gz
- Upload date:
- Size: 23.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.23.0 setuptools/46.1.3 requests-toolbelt/0.9.1 tqdm/4.48.0 CPython/3.7.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0bb1c3efa89ee28adb82c2840a280adbf0b4a7a50d0358234b79a6038fe32f4e
|
|
| MD5 |
c4fd3bdb23453756552ab0bf8cd35717
|
|
| BLAKE2b-256 |
d860656f9ec3df5cb0a51dbb3eba1da03ab97e89759da003aac9c0daed1c30e7
|







