Tensorflow implementation for structured tabular data

Project description

DatRet: Tensorflow implementation for structured tabular data
Rete neurale per la previsione di Dati tabulari. (it.)
What is it?
A simple implementation of a deep neural network architecture for tabular data with automatic layer-by-layer reduction in the number of neurons and functionality similar to classical machine learning methods.
Main Features
-
simplicity and ease of use. Fit and Predict et Voila!
-
quick adjustment of model parameters
-
GPU support
-
high prediction accuracy
-
support for multilabel classification
-
Tensorflow under the hood;)
Where to get it?
The source code is currently hosted on GitHub at: GitHub - AbdualimovTP/datret: Tensorflow implementation for structured tabular data Binary installers for the latest released version are available at the Python Package Index (PyPI)
# PyPI
pip install datret
Dependencies
- Tensorflow - An open-source library primarily for deep learning applications
- NumPy - Adds support for large, multi-dimensional arrays, matrices and high-level mathematical functions to operate on these arrays
- [Pandas - Python data analysis toolkit](pandas documentation — pandas 1.5.2 documentation)
- Scikit-Learn - machine learning in Python
Quick start
Training and prediction of the model is implemented as in scikit-learn. Prepare your test and train set and run the fit. Support for automatic data normalization for neural networks.
NB! Don't forget to install the dependencies before using the model. You will need Tensorflow, Numpy, Pandas and Scikit-Learn installed.
NB! No need to do one-hot encoding of predictive features. The model will do automatically.
# load library
from datret.datret import DatRetClassifier, DatRetRegressor, DatRetMultilabelClassifier
# prepare train, test split. As in sklearn.
# for example
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=i)
# Call the regressor or classifier and train the model.
DR = DatRetClassifier() # DatRetRegressor works on the same principle
DR.fit(X_train, y_train)
# predict the actual label (or class) over a new set of data.
DR_predict = DR.predict(X_test)
# predict the class probabilities for each data point.
DR_predict_proba = DR.predict_proba(X_test) # Missing in DatRetRegressor, DatRetMultilabelClassifier
Custom model options
Parameters:
-
epoch: int, default = 30. Number of epochs to train the model.
-
optimizer: string (name of optimizer) or optimizer instance. See tf.keras.optimizers, default =
Adam(learning_rate=0.001). On DatRetRegressor defaut learning rate = 0.01. Built-in tensorflow optimizer classes. -
loss: Loss function. May be a string (name of loss function). See tf.keras.losses, default for DatRetClassifier =
CategoricalCrossentropy(), for DatRetRegressor =MeanSquaredError(). Built-in loss functions. -
verbose: 'auto', 0, 1, or 2, default=0. Verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch. 'auto' defaults to 1 for most cases, but 2 when used with ParameterServerStrategy=0.
-
number_neurons: int, default = 500. The number of layers in the first fully connected layer. Subsequent layers are generated automatically with half as many neurons.
-
validation_split: Float between 0 and 1, default = 0. Fraction of the training data to be used as validation data. The model will set apart this fraction of the training data, will not train on it, and will evaluate the loss and any model metrics on this data at the end of each epoch.
-
batch_size: int, default =1. Number of samples per gradient update. Steps_per_epoch s calculated automatically,
X_train.shape[0] // batch_size -
shuffle: True or False, default = True. This argument is ignored when
xis a generator or an object of tf.data.Dataset. 'batch' is a special option for dealing with the limitations of HDF5 data; it shuffles in batch-sized chunks. -
callback:
[], default =[EarlyStopping(monitor='loss', mode='auto', patience=7, verbose=1), ReduceLROnPlateau(monitor='loss', factor=0.2, patience=3, min_lr=0.00001, verbose=1)]. Callbacks: utilities called at certain points during model training.
Adjustable fit method parameters
Parameters:
- normalize: True or False ,default True. Automatic normalization of input data. Used MinMaxScaler.
Example:
# load library
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, Nadam
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from tensorflow.keras.losses import CategoricalCrossentropy, MeanSquaredError, BinaryCrossentropy
from datret.datret import DatRetClassifier, DatRetRegressor, DatRetMultilabelClassifier
# prepare train, test split. As in sklearn.
# for example
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=i)
# Call the regressor or classifier and train the model.
DR = DatRetClassifier(epoch=50,
optimizer=Nadam(learning_rate=0.001),
loss=BinaryCrossentropy(),
verbose=1,
number_neurons=1000,
validation_split = 0.1,
batch_size=100,
shuffle=True,
callback=[])
DR.fit(X_train, y_train, normalize=True)
# predict the actual label (or class) over a new set of data.
DR_predict = DR.predict(X_test)
# predict the class probabilities for each data point.
DR_predict_proba = DR.predict_proba(X_test)
Model architecture
As an example, when using number_neurons = 500 input neurons and 2 predictable classes, the model will automatically have this architecture.
Model: "DatRet with number_neurons = 500"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, X_train.shape[0)] 0
dense (Dense) (None, 500) 150500
dense_1 (Dense) (None, 250) 125250
dense_2 (Dense) (None, 125) 31375
dense_3 (Dense) (None, 62) 7812
dense_4 (Dense) (None, 31) 1953
dense_5 (Dense) (None, 15) 480
dense_6 (Dense) (None, 7) 112
dense_7 (Dense) (None, 3) 24
dense_8 (Dense) (None, 2) 8
(2 predictable classes)
=================================================================
Total params: 317,514
Trainable params: 317,514
Non-trainable params: 0
_________________________________________________________________
Comparison of accuracy with classical machine learning methods
- DatRetClassifier
To assess the accuracy of the classifier, we will use Pima Indians Diabetes Database | Kaggle. Comparable metric RocAucScore. We will compare DatRet with RandomForest and CatBoost out "of the box".
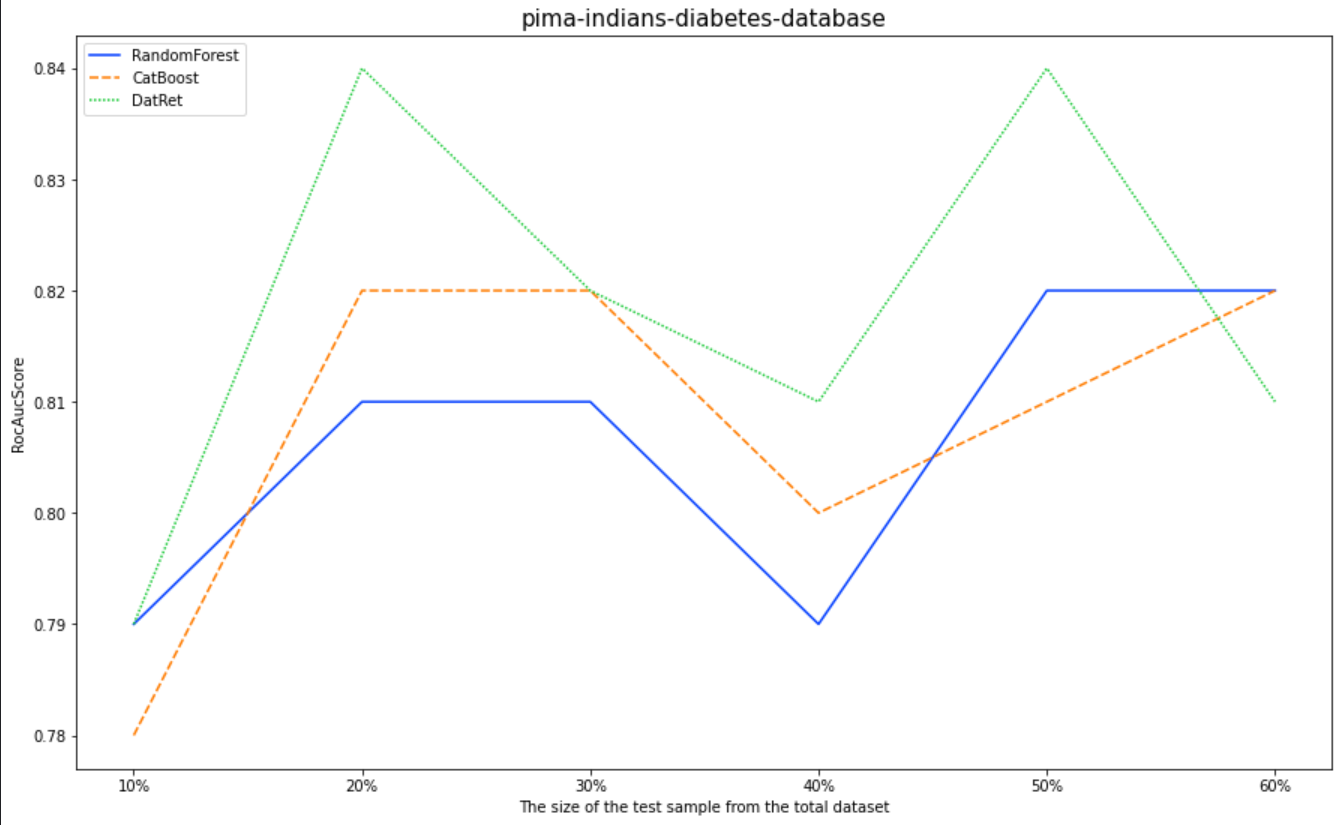
| 10% | 20% | 30% | 40% | 50% | 60% | |
|---|---|---|---|---|---|---|
| RandomForest | 0.79 | 0.81 | 0.81 | 0.79 | 0.82 | 0.82 |
| CatBoost | 0.78 | 0.82 | 0.82 | 0.8 | 0.81 | 0.82 |
| DatRet | 0.79 | 0.84 | 0.82 | 0.81 | 0.84 | 0.81 |
- DatRetRegressor
To assess the accuracy of the regressor, we will use Medical Cost Personal Datasets | Kaggle. Comparable metric Root Mean Square Error. We will compare DatRet with RandomForest and CatBoost out "of the box".
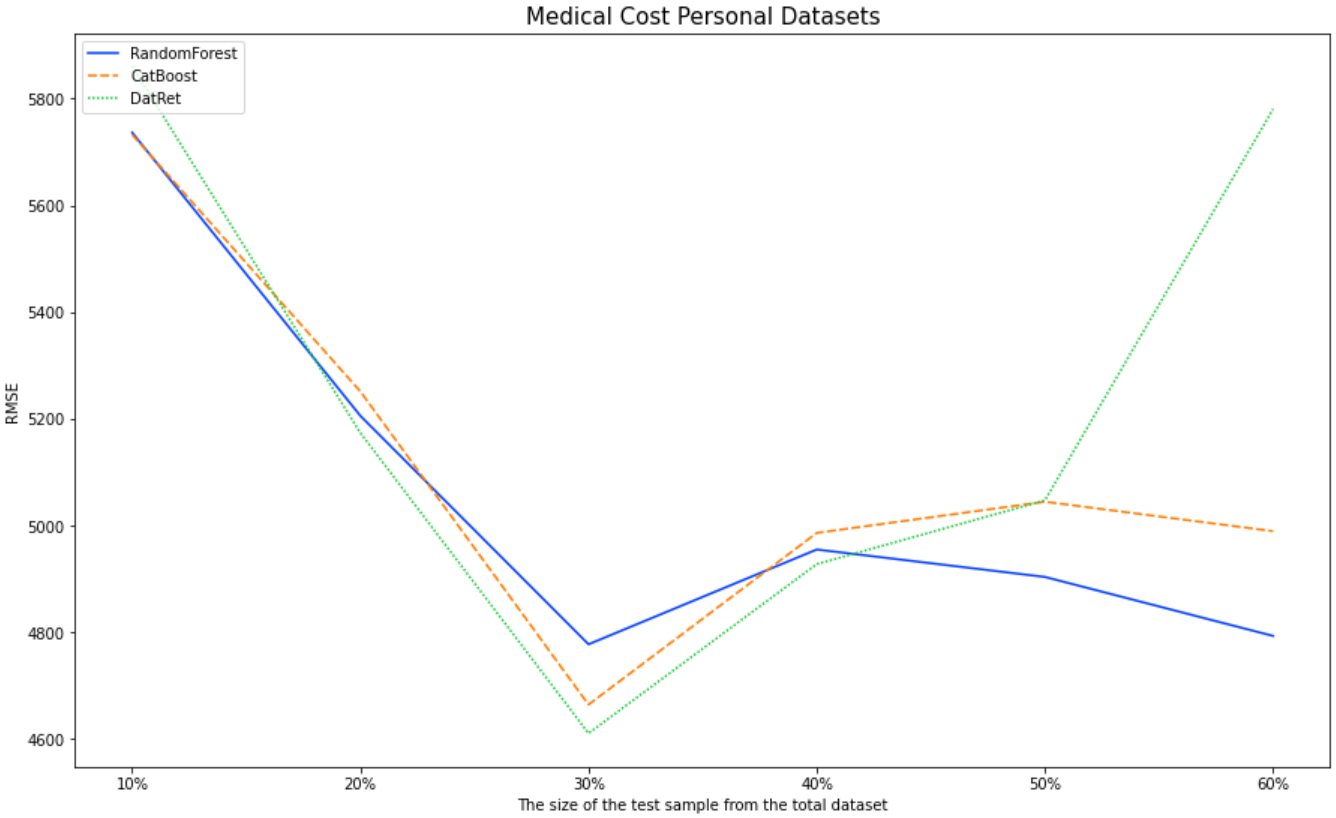
| 10% | 20% | 30% | 40% | 50% | 60% | |
|---|---|---|---|---|---|---|
| RandomForest | 5736 | 5295 | 4777 | 4956 | 4904 | 4793 |
| CatBoost | 5732 | 5251 | 4664 | 4986 | 5044 | 4989 |
| DatRet | 5860 | 5173 | 4610 | 4927 | 5047 | 5780 |
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file datret-1.0.0.tar.gz.
File metadata
- Download URL: datret-1.0.0.tar.gz
- Upload date:
- Size: 6.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9e45e9694cf87f1f8265ac4baa5c114d5408c8b84359e3256d647ff2a2452f46
|
|
| MD5 |
c20ec7aa897c4d034c030c83ef884191
|
|
| BLAKE2b-256 |
32c067a3f3b3037802dcf195e5ca297cdd0eae3b943430d3b87bab2decdc3cba
|
File details
Details for the file datret-1.0.0-py3-none-any.whl.
File metadata
- Download URL: datret-1.0.0-py3-none-any.whl
- Upload date:
- Size: 7.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
791eb8250a1206ac975a44222ee45e8aa8d3f6d0d776a28b4c85c442b07e3750
|
|
| MD5 |
0be236e5a9398d7a405bd98e1c7e76da
|
|
| BLAKE2b-256 |
68fa3d33f4dffde6161299716a447b3f3d344b124787d2e29de0f2d1b2d11dbd
|







