An efficient implementation of the DBSCAN algorithm for 1D arrays.

Project description
DBSCAN1D




dbscan1d is a 1D implementation of the DBSCAN algorithm. It was created to efficiently perform clustering on large 1D arrays.
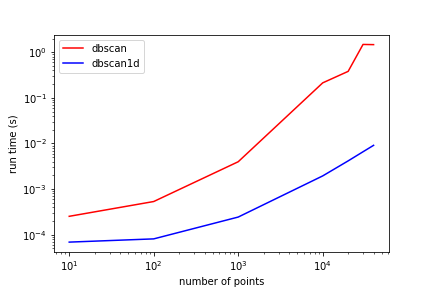
Sci-kit Learn's DBSCAN implementation does not have a special case for 1D, where calculating the full distance matrix is wasteful. It is much better to simply sort the input array and perform efficient bisects for finding closest points. Here are the results of running the simple profile script included with the package. In every case DBSCAN1D is much faster than scikit learn's implementation.
Installation
Simply use pip to install dbscan1d:
pip install dbscan1d
It only requires numpy.
Quickstart
dbscan1d is designed to be interchangeable with sklearn's implementation in almost all cases.
from sklearn.datasets import make_blobs
from dbscan1d.core import DBSCAN1D
# make blobs to test clustering
X = make_blobs(1_000_000, centers=2, n_features=1)[0]
# init dbscan object
dbs = DBSCAN1D(eps=.5, min_samples=4)
# get labels for each point
labels = dbs.fit_predict(X)
# show core point indices
dbs.core_sample_indices_
# get values of core points
dbs.components_
Notes
- dbscan1d can return different group numbers than sklearn for non-core points which are within
eps distances of core points for two separate groups. For example:
--C1--C1--P--C2--C2Here C1 and C2 are core points for group 1 and group 2, respectively. If P is within eps of both C1 and C2, dbscan1d will assign it the same label as the core point that is closest. Sklearn doesn't always do this.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dbscan1d-0.2.4.tar.gz.
File metadata
- Download URL: dbscan1d-0.2.4.tar.gz
- Upload date:
- Size: 12.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
41d39f93b3e3aa1b683000529712f08a9ac9e7c0f700e25b4ad3d5ccd6f94a34
|
|
| MD5 |
4f44c7196f6a5c2ab1d5f4482f4e0636
|
|
| BLAKE2b-256 |
5fdf3a228be0fc71d4b2abe70b8e570e368d122144e7b0a2f54ad589a76a412c
|
File details
Details for the file dbscan1d-0.2.4-py3-none-any.whl.
File metadata
- Download URL: dbscan1d-0.2.4-py3-none-any.whl
- Upload date:
- Size: 10.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
65b4dfcce99683c6e43b1773603e3d1cdec2383ac550aeeca9d9401d735dae52
|
|
| MD5 |
0d198471f9d1781e950db50132572ed1
|
|
| BLAKE2b-256 |
a2c1f1a83805e38ada809c7838749ec267daf96b7340f732596523a3faaf62ef
|







