The Upsolver adapter plugin for dbt

Project description
dbt-upsolver
Using Upsolver udapter for dbt
- What is Upsolver
- SQLake
- What is dbt
- What is dbt Core
- Getting started
- Supported dbt commands
- Supported Upsolver SQLake functionality
- Further reading
What is Upsolver
Upsolver enables you to use familiar SQL syntaxto quickly build and deploy data pipelines, powered by a stream processing engine designed for cloud data lakes.
SQLake
SQLake is Upsolvers new UI and SQL console allowing to execute commands and monitor pipelines in the UI. It also includes freee trial and access to variety of examples and tutorials.
What is dbt
dbt is a transformation workflow that helps you get more work done while producing higher quality results.
What is dbt Core
dbt Core is an open-source tool that enables data teams to transform data using analytics engineering best practices. You can install and use dbt Core on the command line.
Getting started
Install dbt-upsolver adapter :
pip install dbt-upsolver
Make sure the adapter is installed:
dbt --version
Expect to see:
Core:
- installed: <version>
- latest: <version>
Plugins:
- upsolver: <version>
Register Upsolver account
To register just navigate to SQL Lake Sign Up form. You'll have access to SQL workbench with examples and tutorials after completing the registration.
Create API token
After login navigate to "Settings" and then to "API Tokens"
You will need API token and API Url to access Upsolver programatically.
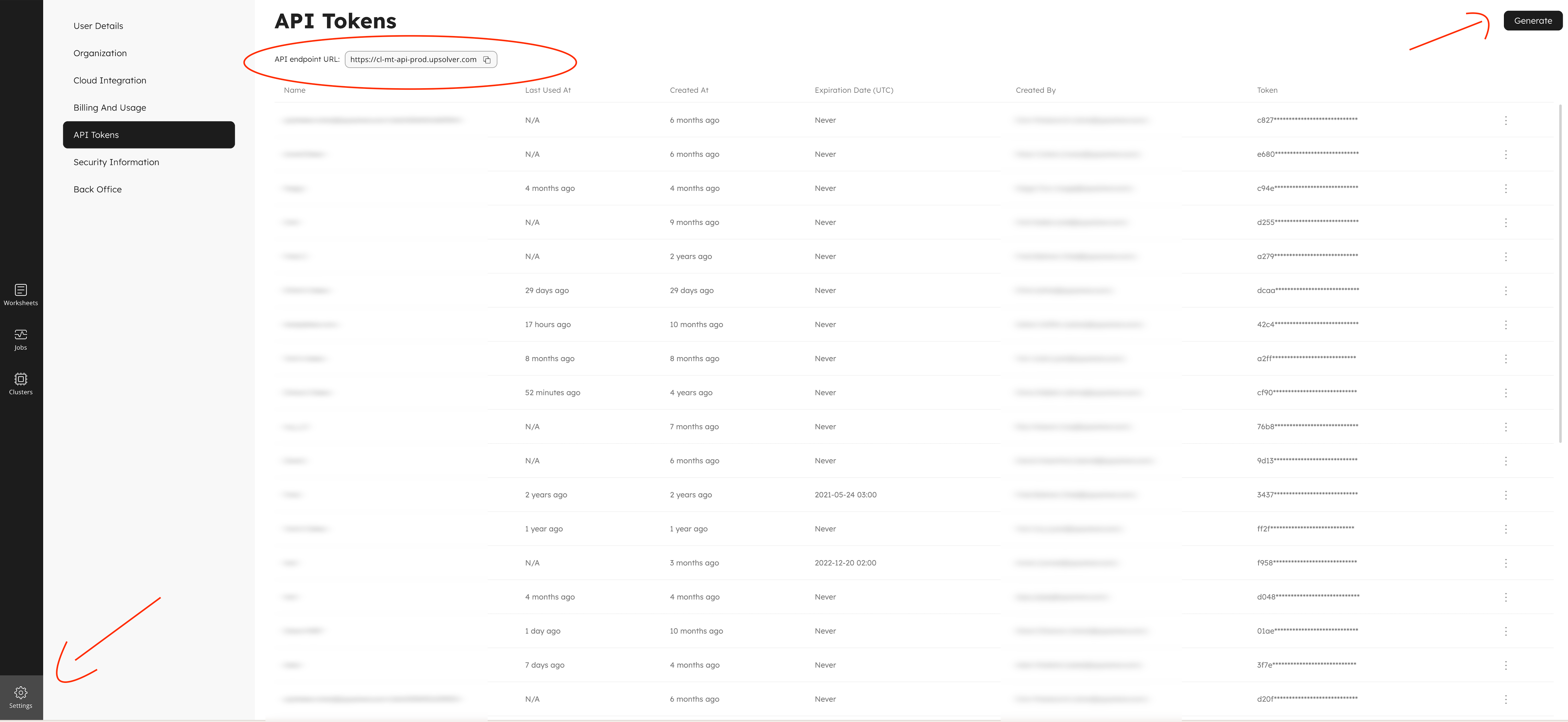
Then click "Generate" new token and save it for future use.
Get your user name, database and schema
For user name navigate to Settings -> User details and copy user name For database and schema navigate to Worksheets and click New. You will find database name and schema(catalog) name under Entities panel
Create new dbt-upsolver project
dbt init <project_name>
Prompt:
Which database would you like to use? [1] upsolver
Enter a number:
api_url (your api_url): https://mt-api-prod.upsolver.com
token (your token): <token>
user (dev username): <username>
database (default database): <database>
schema (default schema): <schema>
threads (1 or more) [1]: <number>
profiles.yml should look like this:
profiles.yml location is something like /Users//.dbt/profiles.yml
project_name:
target: dev
outputs:
dev:
api_url: https://mt-api-prod.upsolver.com
database: ...
schema: ...
threads: 1
token: ...
type: upsolver
user: ...
Check connection
dbt debug
- To run all models
dbt run
- To run the specific model
dbt run --select <model name>
Supported Upsolver SQLake functionality:
| COMMAND | STATE | MATERIALIZED |
|---|---|---|
| SQL compute cluster | not supported | - |
| SQL connections | supported | connection |
| SQL copy job | supported | incremental |
| SQL merge job | supported | incremental |
| SQL insert job | supported | incremental |
| SQL materialized views | supported | materializedview |
| Expectations | supported | incremental |
Configs materialization
| Config | Required | Materialization | Description | Example |
|---|---|---|---|---|
| connection_type | Yes | connection | Connection identifier: S3/GLUE_CATALOG/KINESIS | connection_type='S3' |
| connection_options | Yes | connection | Dictionary of options supported by selected connection | connection_options={ 'aws_role': 'aws_role', 'external_id': 'SAMPLES', 'read_only': True } |
| incremental_strategy | No | incremental | Define one of incremental strategies: merge/copy/insert. Default: copy | incremental_strategy='merge' |
| source | No | incremental | Define source to copy from: S3/KAFKA/KINESIS | source = 'S3' |
| target_type | No | incremental | Define target type REDSHIFT/ELASTICSEARCH/S3/SNOWFLAKE/POSTGRES. Default None for Data lake | target_type='Snowflake' |
| target_prefix | False | incremental | Define PREFIX for ELASTICSEARCH target type | target_prefix = 'orders' |
| target_location | False | incremental | Define LOCATION for S3 target type | target_location = 's3://your-bucket-name/path/to/folder/' |
| schema | Yes/No | incremental | Define target schema. Required if target_type, no table created in a metastore connection | schema = 'target_schema' |
| database | Yes/No | incremental | Define target connection. Required if target_type, no table created in a metastore connection | database = 'target_connection' |
| alias | Yes/No | incremental | Define target table. Required if target_type, no table created in a metastore connection | alias = 'target_table' |
| delete_condition | No | incremental | Records that match the ON condition and a delete condition can be deleted | delete_condition='nettotal > 1000' |
| partition_by | No | incremental | List of dictionaries to define partition_by for target metastore table | partition_by=[{'field':'$field_name'}] |
| primary_key | No | incremental | List of dictionaries to define partition_by for target metastore table | primary_key=[{'field':'customer_email', 'type':'string'}] |
| map_columns_by_name | No | incremental | Maps columns from the SELECT statement to the table. Boolean. Default: False | map_columns_by_name=True |
| sync | No | incremental/materializedview | Boolean option to define if job is synchronized or non-msynchronized. Default: False | sync=True |
| options | No | incremental/materializedview | Dictionary of job options | options={ 'START_FROM': 'BEGINNING', 'ADD_MISSING_COLUMNS': True } |
SQL connection
Connections are used to provide Upsolver with the proper credentials to bring your data into SQLake as well as to write out your transformed data to various services. More details on "Upsolver SQL connections" As a dbt model connection is a model with materialized='connection'
{{ config(
materialized='connection',
connection_type={ 'S3' | 'GLUE_CATALOG' | 'KINESIS' | 'KAFKA'| 'SNOWFLAKE' },
connection_options={}
)
}}
Running this model will compile CREATE CONNECTION(or ALTER CONNECTION if exists) SQL and send it to Upsolver engine. Name of the connection will be name of the model.
SQL copy job
A COPY FROM job allows you to copy your data from a given source into a table created in a metastore connection. This table then serves as your staging table and can be used with SQLake transformation jobs to write to various target locations. More details on "Upsolver SQL copy-from"
As a dbt model copy job is model with materialized='incremental'
{{ config( materialized='incremental',
sync=True|False,
source = 'S3'| 'KAFKA' | ... ,
options={
'option_name': 'option_value'
},
partition_by=[{}]
)
}}
SELECT * FROM {{ ref(<model>) }}
Running this model will compile CREATE TABLE SQL for target type Data lake (or ALTER TABLE if exists) and CREATE COPY JOB(or ALTER COPY JOB if exists) SQL and send it to Upsolver engine. Name of the table will be name of the model. Name of the job will be name of the model plus '_job'
SQL insert job
An INSERT job defines a query that pulls in a set of data based on the given SELECT statement and inserts it into the designated target. This query is then run periodically based on the RUN_INTERVAL defined within the job. More details on "Upsolver SQL insert".
As a dbt model insert job is model with materialized='incremental' and incremental_strategy='insert'
{{ config( materialized='incremental',
sync=True|False,
map_columns_by_name=True|False,
incremental_strategy='insert',
options={
'option_name': 'option_value'
},
primary_key=[{}]
)
}}
SELECT ...
FROM {{ ref(<model>) }}
WHERE ...
GROUP BY ...
HAVING COUNT(DISTINCT orderid::string) ...
Running this model will compile CREATE TABLE SQL for target type Data lake(or ALTER TABLE if exists) and CREATE INSERT JOB(or ALTER INSERT JOB if exists) SQL and send it to Upsolver engine. Name of the table will be name of the model. Name of the job will be name of the model plus '_job'
SQL merge job
A MERGE job defines a query that pulls in a set of data based on the given SELECT statement and inserts into, replaces, or deletes the data from the designated target based on the job definition. This query is then run periodically based on the RUN_INTERVAL defined within the job. More details on "Upsolver SQL merge".
As a dbt model merge job is model with materialized='incremental' and incremental_strategy='merge'
{{ config( materialized='incremental',
sync=True|False,
map_columns_by_name=True|False,
incremental_strategy='merge',
options={
'option_name': 'option_value'
},
primary_key=[{}]
)
}}
SELECT ...
FROM {{ ref(<model>) }}
WHERE ...
GROUP BY ...
HAVING COUNT ...
Running this model will compile CREATE TABLE SQL for target type Data lake(or ALTER TABLE if exists) and CREATE MERGE JOB(or ALTER MERGE JOB if exists) SQL and send it to Upsolver engine. Name of the table will be name of the model. Name of the job will be name of the model plus '_job'
SQL materialized views
When transforming your data, you may find that you need data from multiple source tables in order to achieve your desired result. In such a case, you can create a materialized view from one SQLake table in order to join it with your other table (which in this case is considered the main table). More details on "Upsolver SQL materialized views".
As a dbt model materialized views is model with materialized='materializedview'.
{{ config( materialized='materializedview',
sync=True|False,
options={'option_name': 'option_value'}
)
}}
SELECT ...
FROM {{ ref(<model>) }}
WHERE ...
GROUP BY ...
Running this model will compile CREATE MATERIALIZED VIEW SQL(or ALTER MATERIALIZED VIEW if exists) and send it to Upsolver engine. Name of the materializedview will be name of the model.
Expectations/constraints
Data quality conditions can be added to your job to drop a row or trigger a warning when a column violates a predefined condition.
WITH EXPECTATION <expectation_name> EXPECT <sql_predicate>
ON VIOLATION WARN
Expectations can be implemented with dbt constraints Supported constraints: check and not_null
models:
- name: <model name>
# required
config:
contract:
enforced: true
# model-level constraints
constraints:
- type: check
columns: ['<column1>', '<column2>']
expression: "column1 <= column2"
name: <constraint_name>
- type: not_null
columns: ['column1', 'column2']
name: <constraint_name>
columns:
- name: <column3>
data_type: string
# column-level constraints
constraints:
- type: not_null
- type: check
expression: "REGEXP_LIKE(<column3>, '^[0-9]{4}[a-z]{5}$')"
name: <constraint_name>
Projects examples
projects examples link: github.com/dbt-upsolver/examples/
Connection options
| Option | Storage | Editable | Optional | Config Syntax |
|---|---|---|---|---|
| aws_role | s3 | True | True | 'aws_role': '<aws_role>' |
| external_id | s3 | True | True | 'external_id': '<external_id>' |
| aws_access_key_id | s3 | True | True | 'aws_access_key_id': '<aws_access_key_id>' |
| aws_secret_access_key | s3 | True | True | 'aws_secret_access_key_id': '<aws_secret_access_key_id>' |
| path_display_filter | s3 | True | True | 'path_display_filter': '<path_display_filter>' |
| path_display_filters | s3 | True | True | 'path_display_filters': ('<filter>', ...) |
| read_only | s3 | True | True | 'read_only': True/False |
| encryption_kms_key | s3 | True | True | 'encryption_kms_key': '<encryption_kms_key>' |
| encryption_customer_managed_key | s3 | True | True | 'encryption_customer_kms_key': '<encryption_customer_kms_key>' |
| comment | s3 | True | True | 'comment': '<comment>' |
| host | kafka | False | False | 'host': '<host>' |
| hosts | kafka | False | False | 'hosts': ('<host>', ...) |
| consumer_properties | kafka | True | True | 'consumer_properties': '<consumer_properties>' |
| version | kafka | False | True | 'version': '<value>' |
| require_static_ip | kafka | True | True | 'require_static_ip': True/False |
| ssl | kafka | True | True | 'ssl': True/False |
| topic_display_filter | kafka | True | True | 'topic_display_filter': '<topic_display_filter>' |
| topic_display_filters | kafka | True | True | 'topic_display_filter': ('<filter>', ...) |
| comment | kafka | True | True | 'comment': '<comment>' |
| aws_role | glue_catalog | True | True | 'aws_role': '<aws_role>' |
| external_id | glue_catalog | True | True | 'external_id': '<external_id>' |
| aws_access_key_id | glue_catalog | True | True | 'aws_access_key_id': '<aws_access_key_id>' |
| aws_secret_access_key | glue_catalog | True | True | 'aws_secret_access_key': '<aws_secret_access_key>' |
| default_storage_connection | glue_catalog | False | False | 'default_storage_connection': '<default_storage_connection>' |
| default_storage_location | glue_catalog | False | False | 'default_storage_location': '<default_storage_location>' |
| region | glue_catalog | False | True | 'region': '<region>' |
| database_display_filter | glue_catalog | True | True | 'database_display_filter': '<database_display_filter>' |
| database_display_filters | glue_catalog | True | True | 'database_display_filters': ('<filter>', ...) |
| comment | glue_catalog | True | True | 'comment': '<comment>' |
| aws_role | kinesis | True | True | 'aws_role': '<aws_role>' |
| external_id | kinesis | True | True | 'external_id': '<external_id>' |
| aws_access_key_id | kinesis | True | True | 'aws_access_key_id': '<aws_access_key_id>' |
| aws_secret_access_key | kinesis | True | True | 'aws_secret_access_key': '<aws_secret_access_key>' |
| region | kinesis | False | False | 'region': '<region>' |
| read_only | kinesis | False | True | 'read_only': True/False |
| max_writers | kinesis | True | True | 'max_writers': <integer> |
| stream_display_filter | kinesis | True | True | 'stream_display_filter': '<stream_display_filter>' |
| stream_display_filters | kinesis | True | True | 'stream_display_filters': ('<filter>', ...) |
| comment | kinesis | True | True | 'comment': '<comment>' |
| connection_string | snowflake | True | False | 'connection_string': '<connection_string>' |
| user_name | snowflake | True | False | 'user_name': '<user_name>' |
| password | snowflake | True | False | 'password': '<password>' |
| max_concurrent_connections | snowflake | True | True | 'max_concurrent_connections': <integer> |
| comment | snowflake | True | True | 'comment': '<comment>' |
| connection_string | redshift | True | False | 'connection_string': '<connection_string>' |
| user_name | redshift | True | False | 'user_name': '<user_name>' |
| password | redshift | True | False | 'password': '<password>' |
| max_concurrent_connections | redshift | True | True | 'max_concurrent_connections': <integer> |
| comment | redshift | True | True | 'comment': '<comment>' |
| connection_string | mysql | True | False | 'connection_string': '<connection_string>' |
| user_name | mysql | True | False | 'user_name': '<user_name>' |
| password | mysql | True | False | 'password': '<password>' |
| comment | mysql | True | True | 'comment': '<comment>' |
| connection_string | postgres | True | False | 'connection_string': '<connection_string>' |
| user_name | postgres | True | False | 'user_name': '<user_name>' |
| password | postgres | True | False | 'password': '<password>' |
| comment | postgres | True | True | 'comment': '<comment>' |
| connection_string | elasticsearch | True | False | 'connection_string': '<connection_string>' |
| user_name | elasticsearch | True | False | 'user_name': '<user_name>' |
| password | elasticsearch | True | False | 'password': '<password>' |
| comment | elasticsearch | True | True | 'comment': '<comment>' |
| connection_string | mongodb | True | False | 'connection_string': '<connection_string>' |
| user_name | mongodb | True | False | 'user_name': '<user_name>' |
| password | mongodb | True | False | 'password': '<password>' |
| timeout | mongodb | True | True | 'timeout': "INTERVAL 'N' SECONDS" |
| comment | mongodb | True | True | 'comment': '<comment>' |
| connection_string | mssql | True | False | 'connection_string': '<connection_string>' |
| user_name | mssql | True | False | 'user_name': '<user_name>' |
| password | mssql | True | False | 'password': '<password>' |
| comment | mssql | True | True | 'comment': '<comment>' |
Target options
| Option | Storage | Editable | Optional | Config Syntax |
|---|---|---|---|---|
| globally_unique_keys | datalake | False | True | 'globally_unique_keys': True/False |
| storage_connection | datalake | False | True | 'storage_connection': '<storage_connection>' |
| storage_location | datalake | False | True | 'storage_location': '<storage_location>' |
| compute_cluster | datalake | True | True | 'compute_cluster': '<compute_cluster>' |
| compression | datalake | True | True | 'compression': 'SNAPPY/GZIP' |
| compaction_processes | datalake | True | True | 'compaction_processes': <integer> |
| disable_compaction | datalake | True | True | 'disable_compaction': True/False |
| retention_date_partition | datalake | False | True | 'retention_date_partition': '<column>' |
| table_data_retention | datalake | True | True | 'table_data_retention': '<N DAYS>' |
| column_data_retention | datalake | True | True | 'column_data_retention': ({'COLUMN' : '<column>','DURATION': '<N DAYS>'}) |
| comment | datalake | True | True | 'comment': '<comment>' |
| storage_connection | materialized_view | False | True | 'storage_connection': '<storage_connection>' |
| storage_location | materialized_view | False | True | 'storage_location': '<storage_location>' |
| max_time_travel_duration | materialized_view | True | True | 'max_time_travel_duration': '<N DAYS>' |
| compute_cluster | materialized_view | True | True | 'compute_cluster': '<compute_cluster>' |
| column_transformations | snowflake | False | True | 'column_transformations': {'<column>' : '<expression>' , ...} |
| deduplicate_with | snowflake | False | True | 'deduplicate_with': {'COLUMNS' : ['col1', 'col2'],'WINDOW': 'N HOURS'} |
| exclude_columns | snowflake | False | True | 'exclude_columns': ('<exclude_column>', ...) |
| create_table_if_missing | snowflake | False | True | 'create_table_if_missing': True/False} |
| run_interval | snowflake | False | True | 'run_interval': '<N MINUTES/HOURS/DAYS>' |
Transformation options
| Option | Storage | Editable | Optional | Config Syntax |
|---|---|---|---|---|
| run_interval | s3 | False | True | 'run_interval': '<N MINUTES/HOURS/DAYS>' |
| start_from | s3 | False | True | 'start_from': '<timestamp>/NOW/BEGINNING' |
| end_at | s3 | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | s3 | True | True | 'compute_cluster': '<compute_cluster>' |
| comment | s3 | True | True | 'comment': '<comment>' |
| skip_validations | s3 | False | True | 'skip_validations': ('ALLOW_CARTESIAN_PRODUCT', ...) |
| skip_all_validations | s3 | False | True | 'skip_all_validations': True/False |
| aggregation_parallelism | s3 | True | True | 'aggregation_parallelism': <integer> |
| run_parallelism | s3 | True | True | 'run_parallelism': <integer> |
| file_format | s3 | False | False | 'file_format': '(type = <file_format>)' |
| compression | s3 | False | True | 'compression': 'SNAPPY/GZIP ...' |
| date_pattern | s3 | False | True | 'date_pattern': '<date_pattern>' |
| output_offset | s3 | False | True | 'output_offset': '<N MINUTES/HOURS/DAYS>' |
| run_interval | elasticsearch | False | True | 'run_interval': '<N MINUTES/HOURS/DAYS>' |
| routing_field_name | elasticsearch | True | True | 'routing_field_name': '<routing_field_name>' |
| start_from | elasticsearch | False | True | 'start_from': '<timestamp>/NOW/BEGINNING' |
| end_at | elasticsearch | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | elasticsearch | True | True | 'compute_cluster': '<compute_cluster>' |
| skip_validations | elasticsearch | False | True | 'skip_validations': ('ALLOW_CARTESIAN_PRODUCT', ...) |
| skip_all_validations | elasticsearch | False | True | 'skip_all_validations': True/False |
| aggregation_parallelism | elasticsearch | True | True | 'aggregation_parallelism': <integer> |
| run_parallelism | elasticsearch | True | True | 'run_parallelism': <integer> |
| bulk_max_size_bytes | elasticsearch | True | True | 'bulk_max_size_bytes': <integer> |
| index_partition_size | elasticsearch | True | True | 'index_partition_size': 'HOURLY/DAILY ...' |
| comment | elasticsearch | True | True | 'comment': '<comment>' |
| custom_insert_expressions | snowflake | True | True | 'custom_insert_expressions': {'INSERT_TIME' : 'CURRENT_TIMESTAMP()','MY_VALUE': '<value>'} |
| custom_update_expressions | snowflake | True | True | 'custom_update_expressions': {'UPDATE_TIME' : 'CURRENT_TIMESTAMP()','MY_VALUE': '<value>'} |
| keep_existing_values_when_null | snowflake | True | True | 'keep_existing_values_when_null': True/False |
| add_missing_columns | snowflake | False | True | 'add_missing_columns': True/False |
| run_interval | snowflake | False | True | 'run_interval': '<N MINUTES/HOURS/DAYS>' |
| commit_interval | snowflake | True | True | 'commit_interval': '<N MINUTE[S]/HOUR[S]/DAY[S]>' |
| start_from | snowflake | False | True | 'start_from': '<timestamp>/NOW/BEGINNING' |
| end_at | snowflake | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | snowflake | True | True | 'compute_cluster': '<compute_cluster>' |
| skip_validations | snowflake | False | True | 'skip_validations': ('ALLOW_CARTESIAN_PRODUCT', ...) |
| skip_all_validations | snowflake | False | True | 'skip_all_validations': True/False |
| aggregation_parallelism | snowflake | True | True | 'aggregation_parallelism': <integer> |
| run_parallelism | snowflake | True | True | 'run_parallelism': <integer> |
| comment | snowflake | True | True | 'comment': '<comment>' |
| add_missing_columns | datalake | False | True | 'add_missing_columns': True/False |
| run_interval | datalake | False | True | 'run_interval': '<N MINUTES/HOURS/DAYS>' |
| start_from | datalake | False | True | 'start_from': '<timestamp>/NOW/BEGINNING' |
| end_at | datalake | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | datalake | True | True | 'compute_cluster': '<compute_cluster>' |
| skip_validations | datalake | False | True | 'skip_validations': ('ALLOW_CARTESIAN_PRODUCT', ...) |
| skip_all_validations | datalake | False | True | 'skip_all_validations': True/False |
| aggregation_parallelism | datalake | True | True | 'aggregation_parallelism': <integer> |
| run_parallelism | datalake | True | True | 'run_parallelism': <integer> |
| comment | datalake | True | True | 'comment': '<comment>' |
| run_interval | redshift | False | True | 'run_interval': '<N MINUTES/HOURS/DAYS>' |
| start_from | redshift | False | True | 'start_from': '<timestamp>/NOW/BEGINNING' |
| end_at | redshift | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | redshift | True | True | 'compute_cluster': '<compute_cluster>' |
| skip_validations | redshift | False | True | 'skip_validations': ('ALLOW_CARTESIAN_PRODUCT', ...) |
| skip_all_validations | redshift | False | True | 'skip_all_validations': True/False |
| aggregation_parallelism | redshift | True | True | 'aggregation_parallelism': <integer> |
| run_parallelism | redshift | True | True | 'run_parallelism': <integer> |
| skip_failed_files | redshift | False | True | 'skip_failed_files': True/False |
| fail_on_write_error | redshift | False | True | 'fail_on_write_error': True/False |
| comment | redshift | True | True | 'comment': '<comment>' |
| run_interval | postgres | False | True | 'run_interval': '<N MINUTES/HOURS/DAYS>' |
| start_from | postgres | False | True | 'start_from': '<timestamp>/NOW/BEGINNING' |
| end_at | postgres | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | postgres | True | True | 'compute_cluster': '<compute_cluster>' |
| skip_validations | postgres | False | True | 'skip_validations': ('ALLOW_CARTESIAN_PRODUCT', ...) |
| skip_all_validations | postgres | False | True | 'skip_all_validations': True/False |
| aggregation_parallelism | postgres | True | True | 'aggregation_parallelism': <integer> |
| run_parallelism | postgres | True | True | 'run_parallelism': <integer> |
| comment | postgres | True | True | 'comment': '<comment>' |
Copy options
| Option | Storage | Category | Editable | Optional | Config Syntax |
|---|---|---|---|---|---|
| topic | kafka | source_options | False | False | 'topic': '<topic>' |
| exclude_columns | kafka | job_options | False | True | 'exclude_columns': ('<exclude_column>', ...) |
| deduplicate_with | kafka | job_options | False | True | 'deduplicate_with': {'COLUMNS' : ['col1', 'col2'],'WINDOW': 'N HOURS'} |
| consumer_properties | kafka | job_options | True | True | 'consumer_properties': '<consumer_properties>' |
| reader_shards | kafka | job_options | True | True | 'reader_shards': <integer> |
| store_raw_data | kafka | job_options | False | True | 'store_raw_data': True/False |
| start_from | kafka | job_options | False | True | 'start_from': 'BEGINNING/NOW' |
| end_at | kafka | job_options | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | kafka | job_options | True | True | 'compute_cluster': '<compute_cluster>' |
| run_parallelism | kafka | job_options | True | True | 'run_parallelism': <integer> |
| content_type | kafka | job_options | True | True | 'content_type': 'AUTO/CSV/...' |
| compression | kafka | job_options | False | True | 'compression': 'AUTO/GZIP/...' |
| column_transformations | kafka | job_options | False | True | 'column_transformations': {'<column>' : '<expression>' , ...} |
| commit_interval | kafka | job_options | True | True | 'commit_interval': '<N MINUTE[S]/HOUR[S]/DAY[S]>' |
| skip_validations | kafka | job_options | False | True | 'skip_validations': ('MISSING_TOPIC') |
| skip_all_validations | kafka | job_options | False | True | 'skip_all_validations': True/False |
| comment | kafka | job_options | True | True | 'comment': '<comment>' |
| table_include_list | mysql | source_options | True | True | 'table_include_list': ('<regexFilter>', ...) |
| column_exclude_list | mysql | source_options | True | True | 'column_exclude_list': ('<regexFilter>', ...) |
| exclude_columns | mysql | job_options | False | True | 'exclude_columns': ('<exclude_column>', ...) |
| column_transformations | mysql | job_options | False | True | 'column_transformations': {'<column>' : '<expression>' , ...} |
| skip_snapshots | mysql | job_options | True | True | 'skip_snapshots': True/False |
| end_at | mysql | job_options | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | mysql | job_options | True | True | 'compute_cluster': '<compute_cluster>' |
| snapshot_parallelism | mysql | job_options | True | True | 'snapshot_parallelism': <integer> |
| ddl_filters | mysql | job_options | False | True | 'ddl_filters': ('<filter>', ...) |
| comment | mysql | job_options | True | True | 'comment': '<comment>' |
| table_include_list | postgres | source_options | False | False | 'table_include_list': ('<regexFilter>', ...) |
| column_exclude_list | postgres | source_options | False | True | 'column_exclude_list': ('<regexFilter>', ...) |
| heartbeat_table | postgres | job_options | False | True | 'heartbeat_table': '<heartbeat_table>' |
| skip_snapshots | postgres | job_options | False | True | 'skip_snapshots': True/False |
| publication_name | postgres | job_options | False | False | 'publication_name': '<publication_name>' |
| end_at | postgres | job_options | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | postgres | job_options | True | True | 'compute_cluster': '<compute_cluster>' |
| comment | postgres | job_options | True | True | 'comment': '<comment>' |
| parse_json_columns | postgres | job_options | False | False | 'parse_json_columns': True/False |
| column_transformations | postgres | job_options | False | True | 'column_transformations': {'<column>' : '<expression>' , ...} |
| snapshot_parallelism | postgres | job_options | True | True | 'snapshot_parallelism': <integer> |
| exclude_columns | postgres | job_options | False | True | 'exclude_columns': ('<exclude_column>', ...) |
| location | s3 | source_options | False | False | 'location': '<location>' |
| date_pattern | s3 | job_options | False | True | 'date_pattern': '<date_pattern>' |
| file_pattern | s3 | job_options | False | True | 'file_pattern': '<file_pattern>' |
| initial_load_pattern | s3 | job_options | False | True | 'initial_load_pattern': '<initial_load_pattern>' |
| initial_load_prefix | s3 | job_options | False | True | 'initial_load_prefix': '<initial_load_prefix>' |
| delete_files_after_load | s3 | job_options | False | True | 'delete_files_after_load': True/False |
| deduplicate_with | s3 | job_options | False | True | 'deduplicate_with': {'COLUMNS' : ['col1', 'col2'],'WINDOW': 'N HOURS'} |
| end_at | s3 | job_options | True | True | 'end_at': '<timestamp>/NOW' |
| start_from | s3 | job_options | False | True | 'start_from': '<timestamp>/NOW/BEGINNING' |
| compute_cluster | s3 | job_options | True | True | 'compute_cluster': '<compute_cluster>' |
| run_parallelism | s3 | job_options | True | True | 'run_parallelism': <integer> |
| content_type | s3 | job_options | True | True | 'content_type': 'AUTO/CSV...' |
| compression | s3 | job_options | False | True | 'compression': 'AUTO/GZIP...' |
| comment | s3 | job_options | True | True | 'comment': '<comment>' |
| column_transformations | s3 | job_options | False | True | 'column_transformations': {'<column>' : '<expression>' , ...} |
| commit_interval | s3 | job_options | True | True | 'commit_interval': '<N MINUTE[S]/HOUR[S]/DAY[S]>' |
| skip_validations | s3 | job_options | False | True | 'skip_validations': ('EMPTY_PATH') |
| skip_all_validations | s3 | job_options | False | True | 'skip_all_validations': True/False |
| exclude_columns | s3 | job_options | False | True | 'exclude_columns': ('<exclude_column>', ...) |
| stream | kinesis | source_options | False | False | 'stream': '<stream>' |
| reader_shards | kinesis | job_options | True | True | 'reader_shards': <integer> |
| store_raw_data | kinesis | job_options | False | True | 'store_raw_data': True/False |
| start_from | kinesis | job_options | False | True | 'start_from': '<timestamp>/NOW/BEGINNING' |
| end_at | kinesis | job_options | False | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | kinesis | job_options | True | True | 'compute_cluster': '<compute_cluster>' |
| run_parallelism | kinesis | job_options | False | True | 'run_parallelism': <integer> |
| content_type | kinesis | job_options | True | True | 'content_type': 'AUTO/CSV...' |
| compression | kinesis | job_options | False | True | 'compression': 'AUTO/GZIP...' |
| comment | kinesis | job_options | True | True | 'comment': '<comment>' |
| column_transformations | kinesis | job_options | True | True | 'column_transformations': {'<column>' : '<expression>' , ...} |
| deduplicate_with | kinesis | job_options | False | True | 'deduplicate_with': {'COLUMNS' : ['col1', 'col2'],'WINDOW': 'N HOURS'} |
| commit_interval | kinesis | job_options | True | True | 'commit_interval': '<N MINUTE[S]/HOUR[S]/DAY[S]>' |
| skip_validations | kinesis | job_options | False | True | 'skip_validations': ('MISSING_STREAM') |
| skip_all_validations | kinesis | job_options | False | True | 'skip_all_validations': True/False |
| exclude_columns | kinesis | job_options | False | True | 'exclude_columns': ('<exclude_column>', ...) |
| table_include_list | mssql | source_options | True | True | 'table_include_list': ('<regexFilter>', ...) |
| column_exclude_list | mssql | source_options | True | True | 'column_exclude_list': ('<regexFilter>', ...) |
| exclude_columns | mssql | job_options | False | True | 'exclude_columns': ('<exclude_column>', ...) |
| column_transformations | mssql | job_options | False | True | 'column_transformations': {'<column>' : '<expression>' , ...} |
| skip_snapshots | mssql | job_options | True | True | 'skip_snapshots': True/False |
| end_at | mssql | job_options | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | mssql | job_options | True | True | 'compute_cluster': '<compute_cluster>' |
| snapshot_parallelism | mssql | job_options | True | True | 'snapshot_parallelism': <integer> |
| parse_json_columns | mssql | job_options | False | False | 'parse_json_columns': True/False |
| comment | mssql | job_options | True | True | 'comment': '<comment>' |
| collection_include_list | mongodb | source_options | True | True | 'collection_include_list': ('<regexFilter>', ...) |
| exclude_columns | mongodb | job_options | False | True | 'exclude_columns': ('<exclude_column>', ...) |
| column_transformations | mongodb | job_options | False | True | 'column_transformations': {'<column>' : '<expression>' , ...} |
| skip_snapshots | mongodb | job_options | True | True | 'skip_snapshots': True/False |
| end_at | mongodb | job_options | True | True | 'end_at': '<timestamp>/NOW' |
| compute_cluster | mongodb | job_options | True | True | 'compute_cluster': '<compute_cluster>' |
| snapshot_parallelism | mongodb | job_options | True | True | 'snapshot_parallelism': <integer> |
| comment | mongodb | job_options | True | True | 'comment': '<comment>' |
Further reading
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dbt-upsolver-1.5.29.tar.gz.
File metadata
- Download URL: dbt-upsolver-1.5.29.tar.gz
- Upload date:
- Size: 48.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
25a242fd46c44d48381dda6a00734feb9082a4cab02872e4a11bca25e2436844
|
|
| MD5 |
2befaf698560f521079cc3e2c005032b
|
|
| BLAKE2b-256 |
bd52b8f7d4a0c0c8d36e04c027cce08bc2782787b00dd3ae4386d301a5943e41
|
File details
Details for the file dbt_upsolver-1.5.29-py3-none-any.whl.
File metadata
- Download URL: dbt_upsolver-1.5.29-py3-none-any.whl
- Upload date:
- Size: 43.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
40e9e531820b776ccec33780aab1cbd8bfee1dd0f355058c0b960f5a2a6685a2
|
|
| MD5 |
13622948cba48f6f7dc9e4c6df8ce660
|
|
| BLAKE2b-256 |
d599c14bef4e288e62f90a55efafd5e961e642928e6cd6d8f7e0d1a4b90b3ecc
|







