Library designed to process text with various filter criteria

Project description
Dekimashita


a library containing a collection of utility functions designed to filter and process text data based on certain criteria. These functions are useful for various text processing tasks, such as removing unwanted characters, extracting specific information, or cleaning input data.
Features ✨
- Alphabetic Filtering: Easily filter out non-alphabetic characters from text data.
- Numeric Filtering: Quickly remove non-numeric characters from text strings.
- Alphanumeric Filtering: Filter text to retain only alphanumeric characters, excluding special symbols.
- Customization: Ability to customize the filtering criteria based on specific requirements.
- TextCleaning: Cleanse input text from unwanted characters to prepare it for further processing or analysis.
- Normalization: Standardize text data by removing irregular characters or symbols
Requirement ⚙️
- Python v3.11.6+
Installation 🛠️
pip install dekimashita
How To Usage 🤔
1. Dekimashita.vdict(data, [chars])
Filter dictionary values recursively, ignoring specified characters.
Args:
data (dict or list): Data (dictionary or list containing dictionaries) to filter.
chars (list): List of characters to filter.
Returns:
dict or list: Filtered data.
⚠️ Sample ⚠️
data = {
"university": {
"name": "Example University",
"location": "City XYZ",
"courses": [
{
"course_id": "CS101",
"title": "Introduction \n to \n Computer \n\n Science",
"lecturer": {
"name": "Dr. Alan\n Smith",
"email": "alan.smith@example.com",
"office": {
"building": "Engineering Tower",
"room_number": "123"
}
},
"students": {
"name": "John Doe",
"student_id": "123456",
"email": "john.doe@example.com",
"grades": {
"assignments": [
{
"assignment_id": "001",
"score": 95,
"comments": "Great job on the assignment!\nKeep up the good work."
},
{
"assignment_id": "002",
"score": 85,
"comments": "Your\n effort is commendable.\r\r However,\nthere is room"
}
],
"final_exam": {
"score": 88,
"comments": "Solid \nperformance overall.\n\rYour understanding of the subject"
}
}
}
}
]
}
}
without Dekimashita filter
import json
data = # data_sample
with open("data.json", "w") as json_file:
json.dump(data, json_file, indent=4)
If you have a very complex dictionary and you write without using the Dekimashita filter you will get results like this
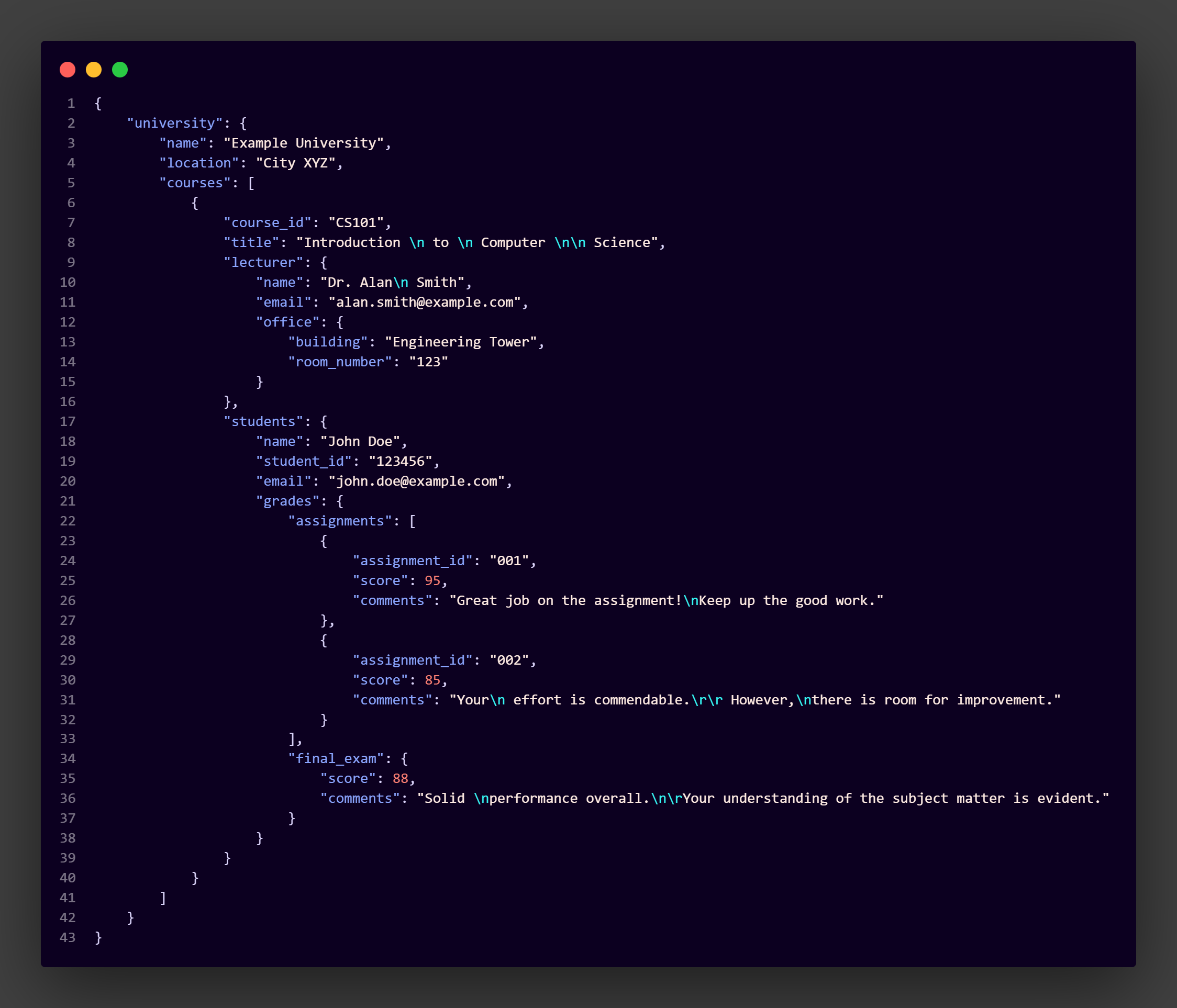
with Dekimashita filter
import json
from dekimashita import Dekimashita
data = # data_sample
clear = Dekimashita.vdict(data, ['\n', '\r'])
with open("data.json", "w") as json_file:
json.dump(clear, json_file, indent=4)
By using the Dekimashita filter you get a clean dictionary like this

2. Dekimashita.vspace(text)
Remove extra spaces from text.
Args:
text (str): Input text.
Returns:
str: Text with extra spaces removed.
sample
from dekimashita import Dekimashita
text = 'moon beautiful isn"t it'
clear = Dekimashita.vspace(text)
print('without Dekimashita filter: '+ text)
print('with Dekimashita filter: ' + clear)
# output
without Dekimashita filter: moon beautiful isn"t it
with Dekimashita filter: moon beautiful isn"t it
3. Dekimashita.valpha(text)
Remove non-alphabetic characters (except a-z, A-Z) from text.
Args:
text (str): Input text.
Returns:
str: Filtered text containing only alphabetic characters.
sample
from dekimashita import Dekimashita
text = 'mo&on b)(*&^%$e!au!t@#$i*f!ul is!!$#n"t i)(*&^t'
clear = Dekimashita.valpha(text)
print('without Dekimashita filter: '+ text)
print('with Dekimashita filter: ' + clear)
# output
without Dekimashita filter: mo&on b)(*&^%$e!au!t@#$i*f!ul is!!$#n"t i)(*&^t
with Dekimashita filter: moon beautiful isnt it
4. Dekimashita.vnum(text)
Remove non-numeric characters from text.
Args:
text (str): Input text.
Returns:
str: Filtered text containing only numeric characters.
sample
from dekimashita import Dekimashita
text = ' mo30on be7aut20iful i05sn"t it'
clear = Dekimashita.vnum(text)
print('without Dekimashita filter: '+ text)
print('with Dekimashita filter: ' + clear)
# output
without Dekimashita filter: mo30on be7aut20iful i05sn"t it
with Dekimashita filter: 3072005
5. Dekimashita.vtext(text)
Remove non-alphanumeric characters (except a-z, A-Z, 0-9) from text.
Double spaces are replaced with a single space.
Args:
text (str): Input text.
Returns:
str: Filtered text containing only alphanumeric characters.
sample
from dekimashita import Dekimashita
text = 'moon \t\t bea^%$#@utiful isn"t it 30705'
clear = Dekimashita.vtext(text)
print('without Dekimashita filter: '+ text)
print('with Dekimashita filter: ' + clear)
# output
without Dekimashita filter: moon bea^%$#@utiful isn"t it 30705
with Dekimashita filter: moon beautiful isnt it 30705
6. Dekimashita.vdir(text, separator)
"""
Remove non-alphanumeric characters (except a-z, A-Z, 0-9) from text.
Convert all letters to lowercase. Replace spaces with a specified separator.
Double separators are replaced with a single separator.
Args:
text (str): Input text.
separator (str): Separator to replace spaces (default is '_').
Returns:
str: Filtered and normalized text.
"""
sample
from dekimashita import Dekimashita
text = 'Moon Beautiful Isn"t It'
clear = Dekimashita.vdir(text)
print('without Dekimashita filter: '+ text)
print('with Dekimashita filter: ' + clear)
# output
without Dekimashita filter: Moon Beautiful Isn"t It
with Dekimashita filter: moon_beautiful_isnt_it
7. Dekimashita.vpath(text, separator)
"""
Remove non-alphanumeric characters (except a-z, A-Z, 0-9) from text.
Convert all letters to lowercase. Replace spaces with a specified separator.
Double separators are replaced with a single separator.
Args:
text (str): Input text.
separator (str): Separator to replace spaces (default is '_').
Returns:
str: Filtered and normalized text.
"""
sample
from dekimashita import Dekimashita
text = 'data/data_statistic/baru/[kategori]/[sub kategori]/[format_type]'
clear = Dekimashita.vpath(text)
print('without Dekimashita filter: '+ text)
print('with Dekimashita filter: ' + clear)
# output
without Dekimashita filter: data/data_statistic/baru/[kategori]/[sub kategori]/[format_type]
with Dekimashita filter: data/data_statistic/baru/kategori/sub_kategori/format_type
8. Dekimashita.v3path(text, separator)
"""
Remove non-alphanumeric characters (except a-z, A-Z, 0-9, '/', '.', ':', '-') from text.
Convert all letters to lowercase. Replace spaces with a specified separator.
Double separators are replaced with a single separator.
Args:
text (str): Input text.
separator (str): Separator to replace spaces (default is '_').
Returns:
str: Filtered and normalized text.
"""
sample
from dekimashita import Dekimashita
text = 's3://ini-path-s3-hehe/data/data_statistic/baru/[kategori]/[sub kategori]/[format_type]'
clear = Dekimashita.v3path(text)
print('without Dekimashita filter: '+ text)
print('with Dekimashita filter: ' + clear)
# output
without Dekimashita filter: s3://ini-path-s3-hehe/data/data_statistic/baru/[kategori]/[sub kategori]/[format_type]
with Dekimashita filter: s3://ini-path-s3-hehe/data/data_statistic/baru/kategori/sub_kategori/format_type
🚀Structure
│ LICENSE
│ README.md
│ setup.py
│
└───dekimashita
dekimashita.py
__init__.py
Author
👤 Rio Dwi Saputra
- Twitter: @ryyo_cs
- Github: @ryyos
- Instagram: @ryyo.cs
- LinkedIn: @rio-dwi-saputra-23560b287




Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dekimashita-0.0.4.tar.gz.
File metadata
- Download URL: dekimashita-0.0.4.tar.gz
- Upload date:
- Size: 9.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3dec8cc2c3416390c57d68ebc1e98066ba7487473a108039ca696927dab8a4e3
|
|
| MD5 |
df936195b4e7f4cd06c7fa366b11378b
|
|
| BLAKE2b-256 |
2c084912259f9990c00a7cdffc4195b4ca386a798d3ff18c3a163b4172464849
|
File details
Details for the file dekimashita-0.0.4-py3-none-any.whl.
File metadata
- Download URL: dekimashita-0.0.4-py3-none-any.whl
- Upload date:
- Size: 9.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5b7b47c1ac5ab01a01cf7336dcf973a37353f8f7f828a2f6ec36e7f1c3dad065
|
|
| MD5 |
df223dd93dd2d9f241f625022a4064fc
|
|
| BLAKE2b-256 |
cad028692a921a2976e9d0dca274c8886441fbf9cb81c8d16d59151525f4e6d3
|







