DICOM Extraction for Large-scale Image Analysis (DELIA).

Project description

DELIA facilitates data extraction from DICOM files to support large-scale image analysis workflows.
Notable features
- Bulk extraction of images and segmentations from multiple patients' DICOM files. Segmentations must be in DICOM-SEG or RTStruct format.
- Creation of an HDF5 database containing multiple patients' medical images as well as binary label maps (segmentations). The database is then easier to use than DICOMs to perform tasks on medical data, such as training deep neural networks.
- Bulk extraction of radiomics features from multiple patients' DICOM files using pyradiomics. Note that
pyradiomicsis not a dependency ofdeliaand must be installed separately.
Installation
Latest stable version :
pip install delia
Latest (possibly unstable) version :
pip install git+https://github.com/MaxenceLarose/delia
Quick usage preview
Extract images as numpy arrays
from delia.extractors import PatientsDataExtractor
patients_data_extractor = PatientsDataExtractor(path_to_patients_folder="patients")
for patient in patients_data_extractor:
for image_data in patient.data:
array = image_data.image.numpy_array
"""Perform any tasks on images on-the-fly."""
print(array)
Create patients database (HDF5)
from delia.databases import PatientsDatabase
from delia.extractors import PatientsDataExtractor
patients_data_extractor = PatientsDataExtractor(path_to_patients_folder="patients")
database = PatientsDatabase(path_to_database="patients_database.h5")
database.create(patients_data_extractor=patients_data_extractor)
Create radiomics dataset (CSV)
from delia.extractors import PatientsDataExtractor
from delia.radiomics import RadiomicsDataset, RadiomicsFeatureExtractor
patients_data_extractor = PatientsDataExtractor(path_to_patients_folder="patients")
radiomics_dataset = RadiomicsDataset(path_to_dataset="radiomics.csv")
radiomics_dataset.extractor = RadiomicsFeatureExtractor(path_to_params="features_extractor_params.yaml")
radiomics_dataset.create(patients_data_extractor=patients_data_extractor, organ="Heart", image_modality="CT")
Note that pyradiomics is not a dependency of delia and must be installed separately.
Motivation
Digital Imaging and Communications in Medicine (DICOM) is the international standard for medical images and related information. The working group DICOM WG-23 on Artificial Intelligence / Application Hosting is currently working to identify or develop the DICOM mechanisms to support AI workflows, concentrating on the clinical context. Moreover, their future roadmap and objectives includes working on the concern that current DICOM mechanisms might not be adequate to cover some use cases, particularly bulk analysis of large repository data, e.g. for training deep learning neural networks. However, no tool has been developed to achieve this goal at present.
The main purpose of this module is therefore to provide the necessary tools to facilitate the use of medical images in an AI workflow. This goal is accomplished by using the HDF file format to create a database containing patients' medical images as well as binary label maps obtained from the segmentation of these images.
How it works
Main concepts
There are 4 main concepts :
PatientDataModel: It is the primarydeliadata structure. It is a named tuple gathering the image and segmentation data available in a patient record.PatientsDataExtractor: A Python Generator that allows to iterate over several patients and create aPatientDataModelobject for each of them. A sequence ofdeliaand/ormonaitransformations to apply to specific images or segmentations can be specified (see MONAI).PatientsDatabase: An object that is used to create/interact with an HDF5 file (a database!) containing all patients information (images + label maps). ThePatientsDataExtractoris used to populate this database.RadiomicsDataset: An object that is used to create/interact with a csv file (a dataset!) containing radiomics features extracted from images. ThePatientsDataExtractoris used to populate this dataset.
Organize your data
Since this module requires the use of data, it is important to properly configure the data-related elements before using it.
File format
Images files must be in standard DICOM format and segmentation files must be in DICOM-SEG or RTStruct format.
If your segmentation files are in a research file format (.nrrd, .nii, etc.), you need to convert them into the standardized DICOM-SEG or RTStruct format. You can use the pydicom-seg library to create the DICOM-SEG files OR use the itkimage2dicomSEG python module, which provide a complete pipeline to perform this conversion. Also, you can use the RT-Utils library to create the RTStruct files.
Tag values (Optional)
This dictionary is not mandatory for the code to work and therefore its default value is None. Note that if no tag_values dictionary is given, i.e. tag_values = None, then all images will be added to the database.
The tag values are specified as a dictionary that contains the values for the tag specified when creating the PatientsDataExtractor object of the images that need to be extracted from the patients' files. Keys are arbitrary names given to the images we want to add and values are lists of values for the desired tag. The images associated with these tag values do not need to have a corresponding segmentation volume. If none of the descriptions match the series in a patient's files, a warning is raised and the patient is added to the list of patients for whom the pipeline has failed.
Note that the tag values can be specified as a python dictionary or as a path to a json file that contains the desired values. Both methods are presented below.
Using a json file
Create a json file containing only the dictionary of the names given to the images we want to add (keys) and lists of tag values (values). Place this file in your data folder.
Here is an example of a json file configured as expected :
{
"PT": [
"PT WB CORR (AC)",
"PT WB XL CORR (AC)"
],
"CT": [
"CT 2.5 WB",
"AC CT 2.5 WB"
]
}
Using a Python dictionary
Create the organs dictionary in your main.py python file.
Here is an example of a python dictionary instanced as expected :
tag_values = {
"PT": [
"PT WB CORR (AC)",
"PT WB XL CORR (AC)"
],
"CT": [
"CT 2.5 WB",
"AC CT 2.5 WB"
]
}
Structure your patients directory
It is important to configure the directory structure correctly to ensure that the module interacts correctly with the data files. The patients folder, must be structured as follows. Note that all DICOM files in the patients' folder will be read.
|_📂 Project directory/
|_📄 main.py
|_📂 data/
|_📄 tag_values.json
|_📂 patients/
|_📂 patient1/
|_📄 ...
|_📂 ...
|_📂 patient2/
|_📄 ...
|_📂 ...
|_📂 ...
Import the package
The easiest way to import the package is to use :
import delia
You can explicitly use the objects sub-modules :
from delia.databases import PatientsDatabase
from delia.extractors import PatientsDataExtractor
from delia.radiomics import RadiomicsDataset, RadiomicsFeatureExtractor
Use the package
Example using the PatientsDatabase class
This file can then be executed to obtain an hdf5 database.
from delia.databases import PatientsDatabase
from delia.extractors import PatientsDataExtractor
from delia.transforms import (
PETtoSUVD,
ResampleD
)
from monai.transforms import (
CenterSpatialCropD,
Compose,
ScaleIntensityD,
ThresholdIntensityD
)
patients_data_extractor = PatientsDataExtractor(
path_to_patients_folder="data/patients",
tag_values="data/tag_values.json",
transforms=Compose(
[
ResampleD(keys=["CT_THORAX", "PT", "Heart"], out_spacing=(1.5, 1.5, 1.5)),
CenterSpatialCropD(keys=["CT_THORAX", "PT", "Heart"], roi_size=(1000, 160, 160)),
ThresholdIntensityD(keys=["CT_THORAX"], threshold=-250, above=True, cval=-250),
ThresholdIntensityD(keys=["CT_THORAX"], threshold=500, above=False, cval=500),
ScaleIntensityD(keys=["CT_THORAX"], minv=0, maxv=1),
PETtoSUVD(keys=["PT"])
]
)
)
database = PatientsDatabase(path_to_database="data/patients_database.h5")
database.create(
patients_data_extractor=patients_data_extractor,
tags_to_use_as_attributes=[(0x0008, 0x103E), (0x0020, 0x000E), (0x0008, 0x0060)],
overwrite_database=True
)
The created HDF5 database will then look something like :
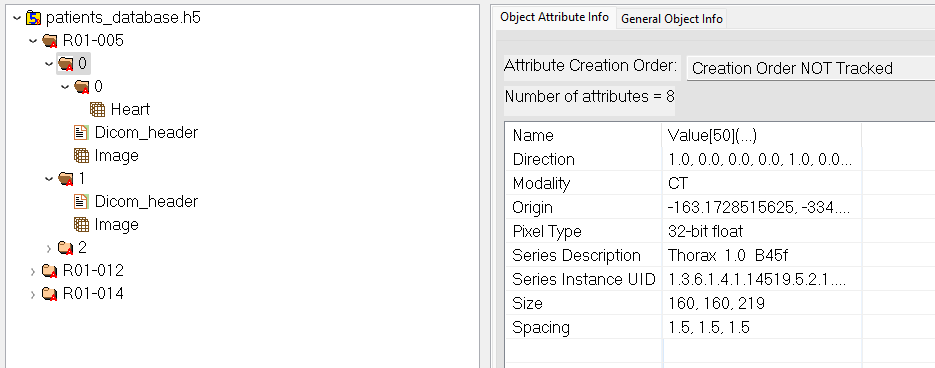
Example using the PatientsDataExtractorclass
This file can then be executed to perform on-the-fly tasks on images.
from delia.extractors import PatientsDataExtractor
from delia.transforms import Compose, CopySegmentationsD, PETtoSUVD, ResampleD
import SimpleITK as sitk
patients_data_extractor = PatientsDataExtractor(
path_to_patients_folder="data/patients",
tag_values="data/tag_values.json",
transforms=Compose(
[
ResampleD(keys=["CT_THORAX", "Heart"], out_spacing=(1.5, 1.5, 1.5)),
PETtoSUVD(keys=["PT"]),
CopySegmentationsD(segmented_image_key="CT_THORAX", unsegmented_image_key="PT")
]
)
)
for patient_dataset in patients_data_extractor:
print(f"Patient ID: {patient_dataset.patient_id}")
for patient_image_data in patient_dataset.data:
dicom_header = patient_image_data.image.dicom_header
simple_itk_image = patient_image_data.image.simple_itk_image
numpy_array_image = sitk.GetArrayFromImage(simple_itk_image)
"""Perform any tasks on images on-the-fly."""
print(numpy_array_image.shape)
Need more examples?
You can find more in the examples folder.
A deeper look into the PatientsDataExtractor object
The PatientsDataExtractor has 4 important variables: a path_to_patients_folder (which dictates the path to the folder that contains all patient records), a tag (which specifies which tag to use when choosing which images need to be extracted, if no value is given, this defaults to SeriesDescription), a tag_values (which dictates the images that needs to be extracted from the patient records) and transforms that defines a sequence of transformations to apply on images or segmentations. For each patient/folder available in the path_to_patients_folder, all DICOM files in their folder are read. If the specified tag's value of a certain volume match one of the descriptions present in the given tag_values dictionary, this volume and its segmentation (if available) are automatically added to the PatientDataModel. Note that if no tag_values dictionary is given (tag_values = None), then all images (and associated segmentations) will be added to the database.
The PatientsDataExtractor can therefore be used to iteratively perform tasks on each of the patients, such as displaying certain images, transforming images into numpy arrays, or creating an HDF5 database using the PatientsDatabase. It is this last task that is highlighted in this package, but it must be understood that the data extraction is performed in a very general manner by the PatientsDataExtractor and is therefore not limited to this single application. For example, someone could easily develop a Numpydatabase whose creation would be ensured by the PatientsDataExtractor, similar to the current PatientsDatabase based on the HDF5 format.
TODO
- Generalize the use of arbitrary tags to choose images to extract. At the moment, the only tag available is
series_descriptions. - Find which DICOM tags act in unusual ways such as having data associated with .repval and .value which differ by more than just their type. For now, both are used to obtain the same value in delia/readers/patient_data/factories/patient_data_factories.py (152-155) and delia/readers/image/dicom_reader.py (113-116).
- Allow for more comprehensive use of tags such as using AND, OR and NOT between tags and their values.
- Loosen monai version requirements (monai==1.0.1) to allow for more recent versions. This needs a redefinition of the way transforms are applied.
License
This code is provided under the Apache License 2.0.
Citation
@misc{delia,
title={DELIA: DICOM Extraction for Large-scale Image Analysis},
author={Maxence Larose},
year={2022},
publisher={Université Laval},
url={https://github.com/MedPhysUL/delia},
}
Contact
Maxence Larose, B. Ing., maxence.larose.1@ulaval.ca
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file delia-1.2.7.tar.gz.
File metadata
- Download URL: delia-1.2.7.tar.gz
- Upload date:
- Size: 48.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cfcf1f832c5c6a57474f768e77def9c017f5032a6f813b0cbc1a8fcd08d4adeb
|
|
| MD5 |
b9a684dcb47cc3358828e207b072098b
|
|
| BLAKE2b-256 |
05ca8d443299d1101f7d49d9685f476803207db76db404ef4167639fc334fd90
|
File details
Details for the file delia-1.2.7-py3-none-any.whl.
File metadata
- Download URL: delia-1.2.7-py3-none-any.whl
- Upload date:
- Size: 68.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0e5e2461bfb32f6d0f89d5ee7dc38c854d5c24e9a604d217794f43bef7c3fa9b
|
|
| MD5 |
ee084c227a522c2791741129076ae24f
|
|
| BLAKE2b-256 |
b1a038d31549e384e7d89ec388374953413ebf264a90e6961643308bdd43d4b9
|







