Data File Elf

Project description
dfelf
由于日常工作需要(有时候还有写blog的需要),总是要处理一些数据文件,很多繁琐的工作希望可以有一个文件精灵来帮我处理,所以就把过去写的小工具重新整理下,形成“数据文件精灵”(“dfelf”)。
“dfelf”为“Data File Elf”的缩写。
因为日常总是需要处理如下文件:
- CSV
- 图片
所以数据文件精灵初步设计可以支持以上三类文件的日常处理需要。
自v0.1.4版本开始支持silent模式,即不进行IO处理、不输出文件,相关方法中增加silent参数,默认值为False。
安装
conda install -c conda-forge poppler
pip install --upgrade dfelf
PDFFileElf
PDF文件精灵用于日常对pdf文件的处理应用。相关方法如下:
- create:抽取一个或多个PDF文件中相关页重新排列组合成一个新的PDF文件;对应的配置设定为create。
PDFFileElf.create(input_obj=None, silent: bool = False, **kwargs)
- image2pdf:将图片文件拼接成一个PDF文件,每个图片为一页;对应的配置设定为image2pdf。
PDFFileElf.image2pdf(input_obj: list = None, silent: bool = False, **kwargs)
- to_image:将PDF文件相关页输出成图片,每一页为一个图片,以页码为文件后续;对应的配置设定为2image。
PDFFileElf.to_image(input_obj: pymupdf.Document = None, silent: bool = False, **kwargs)
- remove:将PDF文件中指定的页面删除后输出PDF文件;对应的配置设定为remove。
PDFFileElf.remove(input_obj: pymupdf.Document = None, silent: bool = False, **kwargs)
- extract_images:将PDF文件中指定的页面或整个PDF文件(当pages配置为空list时,表示整个PDF文件)的图片进行提取;对应的配置设定为extract_images。
PDFFileElf.extract_images(input_obj: pymupdf.Document = None, silent: bool = False, **kwargs)
- extract_fonts:将PDF文件中的字体导出到指定的output目录中。
PDFFileElf.extract_fonts(input_obj=None, silent: bool = False, **kwargs)
- rotate_pages:将PDF文件中指定的页面进行顺时针旋转处理后,把处理后的PDF输出到新的PDF文件中。
PDFFileElf.rotate_pages(input_obj: pymupdf.Document = None, silent: bool = False, **kwargs)
以下方法从0.2.0版本开始废弃,改用create统一实现
- reorganize:抽取PDF文件中相关页重新排列组合成一个新的PDF文件;对应的配置设定为reorganize。 PDFFileElf.reorganize(input_obj=None, silent: bool = False, **kwargs)
- merge:将PDF文件按顺序合并为一个PDF文件;对应的配置设定为merge。 PDFFileElf.merge(input_obj: list = None, silent: bool = False, **kwargs)
另外,remove_watermark未完善,0.2.0版本开始暂时不提供服务
- remove_watermark:将PDF文件中指定的水印文本关键词所在的区域文本清除。 PDFFileElf.remove_watermark(input_obj=None, silent: bool = False, **kwargs)
配置文件设定如下:
{
"create": {
"input": [
{
"file": "input_filename_01",
"pages": []
},
{
"file": "input_filename_02",
"pages": []
}
],
"output": "output_filename"
},
"image2pdf": {
"images": [],
"output": "output_filename"
},
"to_image": {
"input": "input_filename",
"output": "output_filename_prefix",
"format": "png",
"dpi": 200,
"pages": [
1
]
},
"remove": {
"input": "input_filename",
"output": "output_filename",
"pages": [
1
]
},
"extract_images": {
"input": "input_filename",
"output": "output_filename_prefix",
"pages": [
1
]
},
"remove_watermark": {
"input": "input_filename",
"output": "output_filename",
"keywords": []
},
"extract_fonts": {
"input": "input_filename",
"output": "output_directory"
},
"rotate_pages": {
"input": "input_filename",
"output": "output_filename",
"pages": [
"1|90"
]
}
}
自v0.1.4版本开始,PDFFileElf.to_image中的pages设置为“[ ]”(空列表),表示全量输出,即把整个PDF文件的每一页都输出为图片。
自v0.1.5版本开始,支持PDFFileElf.merge
自v0.1.6版本开始,支持PDFFileElf.remove和PDFFileElf.extract_images
自v0.1.13版本开始,支持PDFFileElf.remove_watermark、PDFFileElf.extract_fonts
自v0.2.1版本开始,支持支持PDFFileElf.rotate_pages。
对于PDFFileElf.extract_images的pages配置,若为空list,即"[ ]",表示对整个文件的图片进行提取。
CSVFileElf
CSV文件精灵用于日常对csv文件的处理应用。相关方法如下:
- add:将tags下定义的csv文件,按照key进行匹配,补充相关字段到base的csv文件中;对应的配置设定为add。
CSVFileElf.add(input_obj=None, silent: bool = False, **kwargs)
- join:将files下定义的csv文件,拼接到base的csv文件中;对应的配置设定为join。
CSVFileElf.join(input_obj=None, silent: bool = False, **kwargs)
- exclude:根据exclusion下定义的条件(op支持的操作有:'=', '!=', '>', '>=', '<=', '<'),对input的csv文件内容进行剔除处理;对应的配置设定为exclude。
CSVFileElf.exclude(input_obj=None, silent: bool = False, **kwargs)
- filter:根据filters下定义的条件(op支持的操作有:'=', '!=', '>', '>=', '<=', '<'),对input的csv文件内容进行筛选处理;对应的配置设定为filter。
CSVFileElf.filter(input_obj=None, silent: bool = False, **kwargs)
- split:根据key对input的csv文件进行拆解处理;对应的配置设定为split。
CSVFileElf.split(input_obj=None, silent: bool = False, **kwargs)
- merge:基于on对input的csv文件进行合并处理;对应的配置设定为merge。
CSVFileElf.merge(input_obj=None, silent: bool = False, **kwargs)
配置文件设定如下:
{
'add': {
'base': {
'name': 'base_filename',
'key': 'key_field',
'drop_duplicates': False,
},
'output': {
'name': 'output_filename',
'BOM': False,
'non-numeric': []
},
'tags': [
{
'name': 'tags_filename',
'key': 'key_field',
'fields': ['field A', 'field B'],
'defaults': ['default value of field A', 'default value of field B']
}
]
},
'join': {
'base': 'base_filename',
'output': {
'name': 'output_filename',
'BOM': False,
'non-numeric': []
},
'files': [
{
'name': 'join_filename',
'mappings': {}
}
]
},
'exclude': {
'input': 'input_filename',
'exclusion': [
{
'key': 'field',
'op': '=',
'value': 123
}
],
'output': {
'name': 'output_filename',
'BOM': False,
'non-numeric': []
}
},
'filter': {
'input': 'input_filename',
'filters': [
{
'key': 'field',
'op': '=',
'value': 123
}
],
'output': {
'name': 'output_filename',
'BOM': False,
'non-numeric': []
}
},
'split': {
'input': 'input_filename',
'output': {
'prefix': 'output_filename_prefix',
'BOM': False,
'non-numeric': []
},
'key': 'key_field'
},
'merge': {
'input': ['input_filename_01', 'input_filename_02'],
'output': {
'name': 'output_filename',
'BOM': False,
'non-numeric': []
},
'on': ['field_name'],
'mappings': {}
}
}
对于输出output配置,如果需要输出BOM格式,请把BOM设置为True;若有一些字段需要表达为非数字类字段,以便于在Excel中打开处理的话,请在non-numeric中设置需要处理的相关字段。
自v0.1.7版本开始,支持CSVFileElf.merge
CSVFileElf的处理案例参考



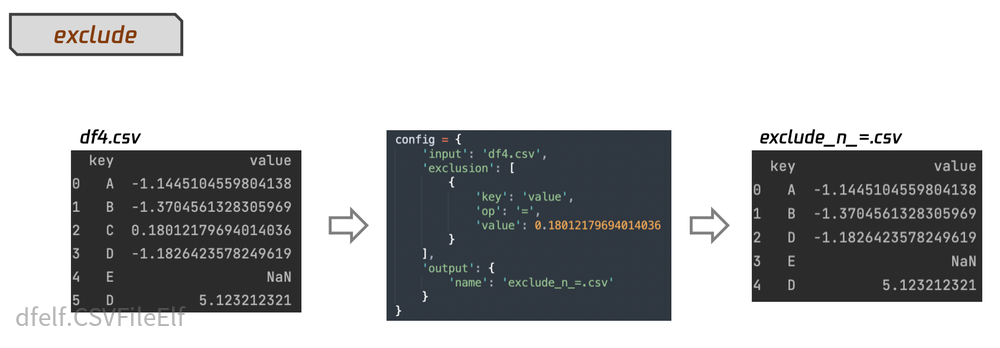


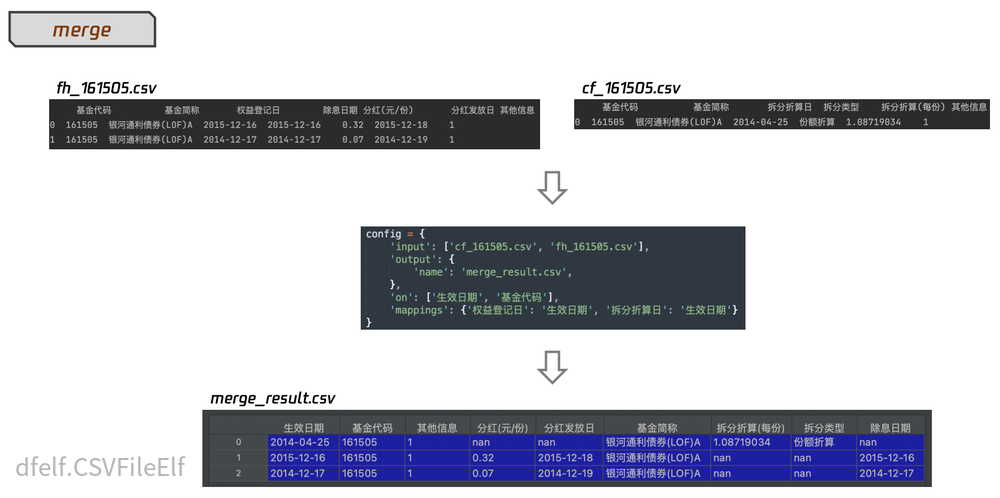
ImageFileElf
Image文件精灵用于日常对图片类文件的处理应用。相关方法如下:
- to_favicon:把图片转化为favicon;对应的配置设定为favicon。
ImageFileElf.to_favicon(input_obj=None, silent: bool = False, **kwargs)
- splice:将input中的图片文件拼接为一张图片;对应的配置设定为splice。
ImageFileElf.splice(input_obj: list = None, silent: bool = False, **kwargs)
- watermark:在指定的x、y坐标中增加水印文字;对应的配置设定为watermark。
ImageFileElf.watermark(input_obj=None, silent: bool = False, **kwargs)
- qrcode:将input的字符串生成二维码;对应的配置设定为qrcode。
ImageFileElf.qrcode(input_obj: str = None, silent: bool = False, **kwargs)
- decode_qrcode:将input的二维码图片解析成字符串,并返回;对应的配置设定为dqrcode。
ImageFileElf.decode_qrcode(input_obj=None, **kwargs)
- to_base64:将input的图片转化为base64字符串,并返回;对应的配置设定为2base64。
ImageFileElf.to_base64(input_obj: bytes = None, **kwargs)
- from_base64:将input的base64字符串转化为图片;对应的配置设定为base64。
ImageFileElf.from_base64(input_obj: str = None, silent: bool = False, **kwargs)
- resize:将input的图片调整尺寸后输出到output;对应的配置设定为resize。
ImageFileElf.resize(input_obj=None, silent: bool = False, **kwargs)
- crop:将input的图片按照loaction裁剪后输出到output;对应的配置设定为crop。当mode为0时,location为left, top, right, bottom构成的数组;当mode为1时,location为left, top, width, right构成的数组。
ImageFileElf.crop(input_obj=None, silent: bool = False, **kwargs)
- fill:将input的图片中loaction的指定区域进行马赛克或者单色填充后输出到output;对应的配置设定为fill。当mode为0时,location为left, top, right, bottom构成的数组;当mode为1时,location为left, top, width, right构成的数组。type为填充方式,M或m表示马赛克填充,单色填充可以用*#8012de*指定到type中实现。
ImageFileElf.fill(input_obj: np.ndarray = None, silent: bool = False, **kwargs)
配置文件设定如下:
{
'favicon': {
'size': -1,
'input': 'input_filename'
},
'splice': {
'output': 'output_filename',
'input': [],
'width': 700,
'gap': 5,
'color': '#ffffff',
'mode': 'v'
},
'watermark': {
'input': 'input_filename',
'output': 'output_filename',
'text': 'Krix.Tam',
'color': 'FFFFFF',
'font': 'arial.ttf',
'font_size': 24,
'x': 5,
'y': 5,
'alpha': 50
},
'2base64': {
'input': 'input_filename',
'css_format': False
},
'base64': {
'input': 'base64 string',
'output': 'output_filename'
},
'qrcode': {
'input': 'string',
'output': 'output_filename',
'border': 2,
'fill_color': "#000000",
'back_color': "#FFFFFF"
},
'dqrcode': {
'input': 'input_filename'
},
'resize': {
'input': 'input_filename',
'output': 'output_filename',
'scale': False,
'width': 28,
'height': 28,
'quality': 100,
'dpi': 1200
},
'crop': {
'input': 'input_filename',
'output': 'output_filename',
'mode': 0,
'location': [0, 0, 5, 5]
},
'fill': {
'input': 'input_filename',
'output': 'output_filename',
'mode': 0,
'location': [0, 0, 5, 5],
'unit': 5,
'type': 'M'
}
}
自v0.1.3版本开始,有如下变更:
ImageFileElf.watermark对color参数支持值为"auto"的设定,表示由程序自动选择水印颜色;颜色选择方法为水印所在位置(x, y)区域高频使用颜色的反转颜色。
ImageFileElf.splice支持水平拼接(设置mode参数为"H"或"h",默认为垂直拼接,即mode参数为"v"或"V")。
自v0.1.4版本开始,支持ImageFileElf.crop、ImageFileElf.fill
自v0.1.6版本开始,ImageFileElf.splice有如下调整:
原配置项images调整为input,即使用与其他方法保持一致的输入配置项名称
配置项mode除了支持水平(h或H)、垂直(v或V)外,新增自动模式,即自动水平(ah,不区分大小写)、自动垂直(av,不区分大小写)的拼接模式,此时参数width将会被忽略。
自v0.1.11版本开始,ImageFileElf.splice配置项mode新增:按照图片最小宽度自动垂直(xv,不区分大小写)或按照最小高度进行自动水平(xh,不区分大小写)的拼接模式,此时参数width将会被忽略。
自v0.1.12版本开始,ImageFileElf.splice新增配置项color,表示边框颜色,默认值为白色。
示例
import os
from dfelf import CSVFileElf
df_elf = CSVFileElf()
config = {
'base': {
'name': os.path.join('sources', 'df1.csv'),
'key': 'key'
},
'output': {
'name': 'test_add.csv'
},
'tags': [
{
'name': os.path.join('sources', 'df3.csv'),
'key': 'key',
'fields': ['new_value'],
'defaults': ['0.0']
}
]
}
df_elf.add(**config)
下面的代码在v0.1.0版本开始,可以获得与上面代码同样的结果:
import os
import pandas as pd
from dfelf import CSVFileElf
df_elf = CSVFileElf()
config = {
'base': {
'key': 'key'
},
'output': {
'name': 'test_add.csv'
},
'tags': [
{
'name': os.path.join('sources', 'df3.csv'),
'key': 'key',
'fields': ['new_value'],
'defaults': ['0.0']
}
]
}
input_df = pd.read_csv(os.path.join('sources', 'df1.csv'), dtype=str)
df_elf.add(input_df, **config)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dfelf-0.2.1-py3-none-any.whl.
File metadata
- Download URL: dfelf-0.2.1-py3-none-any.whl
- Upload date:
- Size: 7.4 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
87c82fd914a18107655a8b8a085e2e5dd756790ccc3021d7fdcf184685a425e2
|
|
| MD5 |
d62ca1751789cb17a9a3eb430f0e2971
|
|
| BLAKE2b-256 |
4568e12781cf3a3f8a8ebe69b5c74ec995972995f3d88f3d0ffcb5436b4072d9
|







