No project description provided

Project description





DistinctKeywords
This is a utility function to extract semantically distinct keywords. This is an unsupervised method based on word2vec. Current implementation used a word2vec model trained in simplewiki(for English). Other language models and their sources are given below.
Please visit the blog post for more details
Supported Languages (jupyter notebooks available in examples). Please see the word2vec citation to know the models used
- English (default) using custom word2vec trained on simplewiki.
- German (on test. Need support from native speakers).
- French (on test. Need support from native speakers).
- Italian (on test. Need support from native speakers).
- Portuguese (on test. Need support from native speakers).
- Spanish (on test. Need support from native speakers).
Installation Instructions
-
conda create -n keyphrases python=3.8 --no-default-packages
-
conda activate keyphrases
-
pip install distinct-keywords
-
python -m spacy download en_core_web_sm
-
conda install --channel=conda-forge nb_conda_kernels jupyter
-
Optional multi-lingual support
``` import nltk nltk.download('omw') ``` -
jupyter notebook
Getting started
-
Clone the repository
-
Open the examples folder in jupyter notebook. The sub-folders contain the respective language files.
-
Select the language you wanted to try out
Usage
You need to have the respective language files in current directory. Please visit examples folder to download and to know how to use them in parameter.
from distinct_keywords.keywords import DistinctKeywords
doc = """
Supervised learning is the machine learning task of learning a function that
maps an input to an output based on example input-output pairs. It infers a
function from labeled training data consisting of a set of training examples.
In supervised learning, each example is a pair consisting of an input object
(typically a vector) and a desired output value (also called the supervisory signal).
A supervised learning algorithm analyzes the training data and produces an inferred function,
which can be used for mapping new examples. An optimal scenario will allow for the
algorithm to correctly determine the class labels for unseen instances. This requires
the learning algorithm to generalize from the training data to unseen situations in a
'reasonable' way (see inductive bias).
"""
distinct_keywords=DistinctKeywords()
distinct_keywords.get_keywords(doc)
Output
['machine learning',
'pairs',
'mapping',
'vector',
'typically',
'supervised',
'bias',
'supervisory',
'task',
'algorithm',
'unseen',
'training']
Methodology
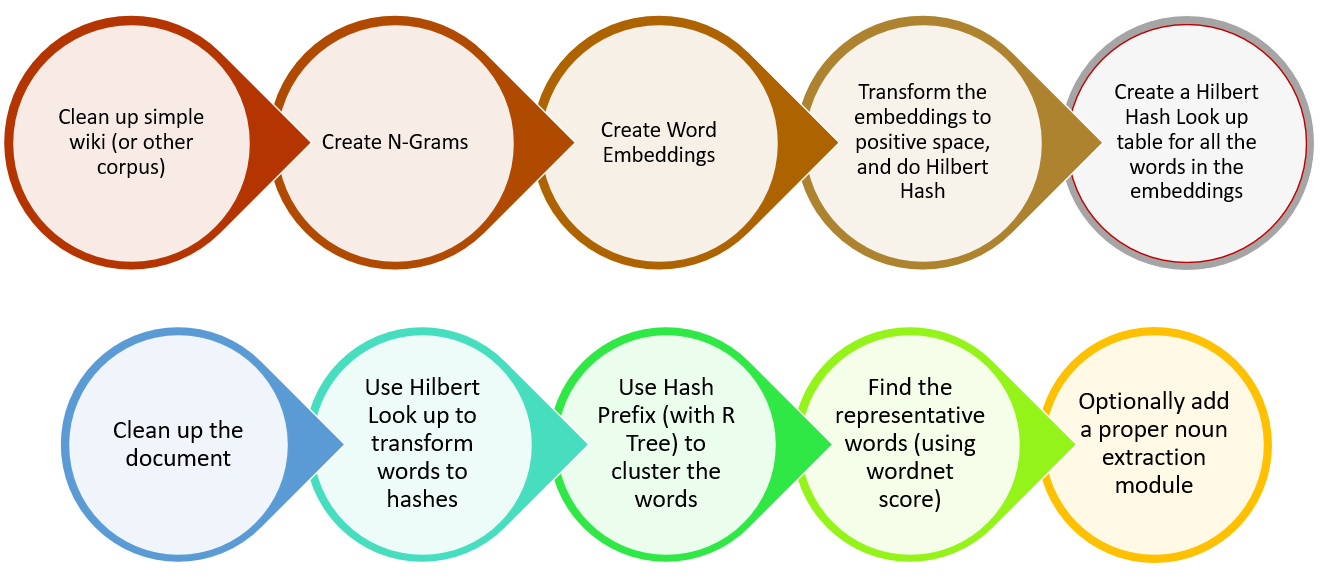
After creating word2vec, the words are mapped to a hilbert space and the results are stored in a key-value pair (every word has a hilbert hash). Now for a new document, the words and phrases are cleaned, hashed using the dictionary. One word from each different prefix is then selected using wordnet ranking from NLTK (rare words are prioritized). The implementation of grouping and look up is made fast using Trie and SortedDict
Benchmarks
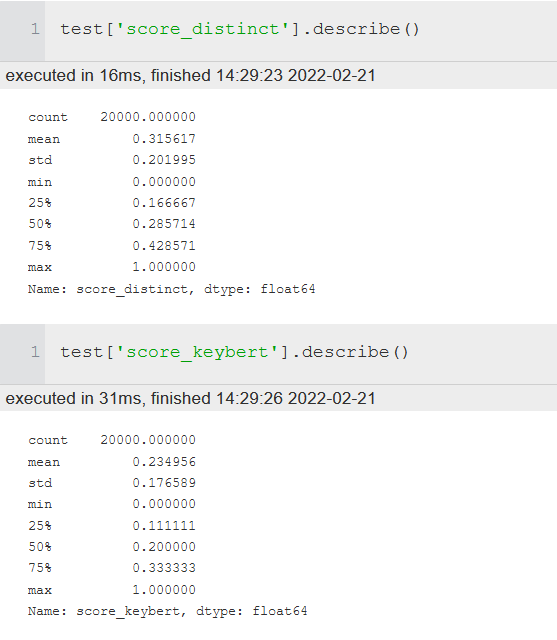
Currently this is tested against KPTimes test dataset (20000 articles). A recall score of 31% is achieved when compared to the manual keywords given in the dataset.
Steps to arrive at the score:
-
Used both algorithms. Keybert was ran with additional parameter top_n=16 as the length of dstinct_keywords at 75% level was around 15.
-
Results of algorithms and original keywords were cleaned (lower case, space removal, character removal, but no lemmatization)
-
Take intersection of original keywords and generated keyword word banks (individual words)
-
For each prediction compare the length of intersecting words with length of total keyword words
Output is given below
Word2vec citations
-
Spanish: Spanish Billion Word Corpus and Embeddings by Cristian Cardellino https://crscardellino.ar/SBWCE/
-
German: @thesis{mueller2015, author = {{Müller}, Andreas}, title = "{Analyse von Wort-Vektoren deutscher Textkorpora}", school = {Technische Universität Berlin}, year = 2015, month = jun, type = {Bachelor's Thesis}, url = {https://devmount.github.io/GermanWordEmbeddings} }
-
French: @misc{fauconnier_2015, author = {Fauconnier, Jean-Philippe}, title = {French Word Embeddings}, url = {http://fauconnier.github.io}, year = {2015}}
-
Italian: Nordic Language Processing Laboratory (NLPL) (http://vectors.nlpl.eu/repository/)
-
Portuguese: NILC - Interinstitutional Nucleus of Computational Linguistics http://nilc.icmc.usp.br/embeddings


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file distinct_keywords-0.29.tar.gz.
File metadata
- Download URL: distinct_keywords-0.29.tar.gz
- Upload date:
- Size: 6.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.62.3 importlib-metadata/4.8.2 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.8.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
529923fa6da888b99487ddefc4ff52ee4b919fb3135165e9f21f1eb8d632f328
|
|
| MD5 |
b6ac523a77c451ffbbc4b4c581942307
|
|
| BLAKE2b-256 |
e75d9915ff698d6a57e053118aaebd9a6679a510fcb4e0fa1f8f1069d692f5a3
|
File details
Details for the file distinct_keywords-0.29-py3-none-any.whl.
File metadata
- Download URL: distinct_keywords-0.29-py3-none-any.whl
- Upload date:
- Size: 6.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.62.3 importlib-metadata/4.8.2 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.8.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2011abdbc4104f17ca7f630c9cd55494800a21debd7cbf9e983f9ec806504eab
|
|
| MD5 |
4607d55f331d17c67a63a4fecce8a0aa
|
|
| BLAKE2b-256 |
6965b8b169e9368a59b55a269b1b93385e84c17952cd8141ea7721d34b487e3b
|







