An unsupervised methodology to implement a diversified under-sampling process to deal with the extremely imbalanced binary classification problem

Project description
Diversified Under-sampling
An unsupervised methodology to implement a diversified under-sampling process to deal with the extremely imbalanced binary classification problem
Here is brief introduction of this under-sampling strategy:
Short version 🔑🔑🔑
What is it for: Binary prediction problems with severe sample imbalance issues
What is the goal: Under-sample data without compromising sample diversity
Who is it for: If you are troubled by sample imbalance problems and the current under-sampling techniques do not give you a good recall rate, you might want to try our solution.
How does it work: Data standardization -> Dimensionality reduction (PCA) -> Cluster analysis (KMeans) -> Under-sample by cluster (condensed nearest neighbour method/random under-sampling)
What are the benefits: Low computational cost with relatively high quality of under-sample results
Long version 📖📖📖
If you are a machine learning engineer, and if you have worked with real world data, you must have faced the extreme sample imbalance problem. It is clear that if you do not handle this problem well, you will end up with a very low recall rate.
Our approach aims to under-sample mathematically redundant samples without losing the diversity of the original samples. Let me explain this, if you are dealing with a binary problem, you are drawing a fine line between the 0-type and the 1-type. And if you want to reduce the size of the large 0 sample group, you care about whether the samples near the fine line are dropped too much so that the line you model later on is not accurate. In other words, you need a way to decrease the 0-type sample size without affecting the sample diversity around the optimal classification line. Our approach achieves this goal.
We start with standardizing data with sklearn's MaxAbsScaler. The method only takes numpy arrays. In order to find a better latent space to preserve the desired diversity, we run the sample data (without label) on PCA and find the optimal number of components. Then we use KMeans to cluster the data based on the PCA results. After that, we under-sample the data by cluster using either the condensed nearest neighbour method or the random under-sampling method. The former is more suitable for clusters with minority type of samples, while the latter is more suitable for clusters without minority type of samples. Finally, we combine the under-sampled data from different clusters and get the final dataset. We also provide some statistics to show the sample balance of the final dataset.
This project requires packages such as sklearn, pandas, numpy, joblib, and imblearn in coding.
Parameters:
Decreasing_ratio_threshold: This parameter controls how many dimensions are used to represent the sample data. The PCA model outputs the explained_variance_ratio, which increases as n_components gets larger. The decreasing_ratio_threshold measures the rate of increase of the explained_variance_ratio. The default value is 0.01.
Cl_upper_num: The maximum number of clusters that will be created by KMeans. The default value is 50.
Accum_wcss_drop_ratio_threshold: We use wcss to evaluate the quality of the unsupervised clustering. If the sum of the wcss drop ratios of two consecutive clusters is less than accum_wcss_drop_ratio_threshold, then we will stop increasing the number of clusters. The default value is 0.01.
Under_sampling_multiplier: This parameter determines how many samples of the majority class will be retained after under-sampling. Imblearn.CondensedNearestNeighbour's parameter n_seeds_S = number of samples of the minority class by cluster * under_sampling_multiplier. If set to 1, then the model will aim to achieve a balanced sample distribution between the two classes. The default value is 1.
N_neighbors: The parameter that imblearn.CondensedNearestNeighbour uses for its n_neighbors value. The default value is None.
Random_multiplier: The value we use to decide how many samples to keep in the random under-sampling process. Random_multiplier should be between 0 and 1. The number of samples kept from the random under-sampling process = Total number of samples by cluster * Random_multiplier. The default value is 0.05.
Demo:
Extract data and transform it into numpy array:
Data instantiation:

Unsupervised classification:
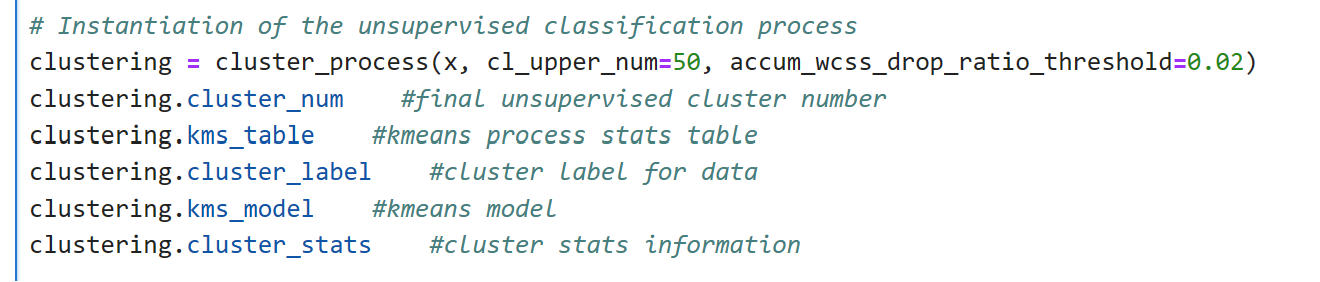
Under-sampling:

Methods:
Sample_data.scale() -> standardizes the input array using MaxAbsScaler. Input: array. Output: array.
Sample_data.pca_diag() -> determines the optimal number of PCA dimensions based on the decreasing_ratio_threshold. Input: array, decreasing_ratio_threshold. Output: PCA process statistics, optimal number of dimensions.
Sample_data.pca_forecast() -> performs PCA transformation on the input array using the optimal number of dimensions. Input: optimal number of dimensions, array. Output: array, PCA model.
Sample_label.show_stats() -> provides descriptive statistics of the label array. Input: label array. Output: descriptive statistics.
cluster_process.clusting_diag() -> finds the best number of clusters based on the accum_wcss_drop_ratio_threshold and performs KMeans clustering on the PCA transformed array. Input: PCA transformed array, cl_upper_num, accum_wcss_drop_ratio_threshold. Output: best number of clusters, KMeans process statistics.
cluster_process.clusting_forecast() -> fits and predicts the KMeans model on the PCA transformed array using the best number of clusters. Input: PCA transformed array, best number of clusters. Output: KMeans cluster label array, KMeans model.
under_sampling.under_sampling_process() -> applies Condensed Nearest Neighbour under-sampling method to the specified clusters in the PCA transformed array with cluster labels and y labels. Input: PCA transformed array with cluster label and y label, list of cluster numbers that need to be under-sampled, under_sampling_multiplier, n_neighbors. Output: under-sampled array (specified clusters only), detailed statistics of the under-sampling process.
under_sampling.random_usampling_process() -> applies random under-sampling method to the specified clusters in the PCA transformed array with cluster labels and y labels. Input: PCA transformed array with cluster label and y label, list of cluster numbers that need to be under-sampled, random_multiplier. Output: under-sampled array (specified clusters only), detailed statistics of the under-sampling process.
Using the methods above, you can manually create your own under-sampling process with more flexible options of algorithms.
Future work:
- Provide different options for data standardization methods;
- Provide different options for dimensionality reduction methods;
- Find a way to automatically determine the optimal value of cl_upper_num;
- Provide different options for unsupervised clustering methods;
- Find a better way to decide the ideal number of clusters for unsupervised clustering;
- Provide different options for under-sampling methods;
- Implement a pipeline mechanism for automatic modeling with optimal objectives;
- Extend the method to handle multi-class problems;
- Find a better way to deal with clusters that do not contain any minority samples rather than random under-sampling only.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file diversampling-0.1.0.tar.gz.
File metadata
- Download URL: diversampling-0.1.0.tar.gz
- Upload date:
- Size: 8.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cad4441a96da43411d3af67bb0de3a92ea648280400123b19b3d6ee7d33cbd69
|
|
| MD5 |
cbc6896bcdf133ceaec267dfbd701946
|
|
| BLAKE2b-256 |
f22aafe8dbe88dd3219a831cb870d097f8b0f2ee648c25d4414a4a1caa865671
|
File details
Details for the file diversampling-0.1.0-py3-none-any.whl.
File metadata
- Download URL: diversampling-0.1.0-py3-none-any.whl
- Upload date:
- Size: 8.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e1bc3ed503eefb03a6ab86b1453938a17c0f86a9054b3f13d8bef3ab2ec33615
|
|
| MD5 |
d2fbf3823312e17e9e78bce8e7d79872
|
|
| BLAKE2b-256 |
2c4605fb8b1c901acd2c76d466d294f992e46b0b2d7745e2756da116fa9b36d4
|







