Enhanced Integrated Gradients - a method of attributing the prediction of a deep network to its input features

Project description
Enhanced Integrated Gradients (EIG)

Anupama Jha and Yoseph Barash
Biociphers Lab, Department of CIS and genetics, University of Pennsylvania
Citation
Improving interpretability of deep learning models: splicing codes as a case study. Jha, A., Aicher, J. K., Gazzara, M. R., Singh, D., & Barash, Y. (2019). biorXiv preprint (2019), 700096.
Introduction
Integrated gradients (IG) is a method of attributing the prediction of a deep network to its input features Sundararajan et al.. We introduce Enhanced Integrated Gradients (EIG) that extends IG with three main contributions: non-linear paths, meaningful baselines and class-wide feature significance. These contributions allow us to answer interpretation questions like : Which features distinguish the class of interest from the baseline class? For example, EIG identifies pixels that distinguish image of digit 5 (samples, class of interest) from the image of digit 3 (baseline class).

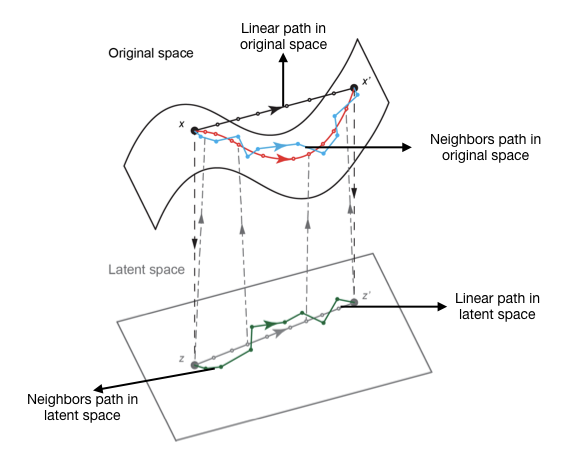
EIG package includes four paths that can be computed in original feature space or an hidden (latent) space. To compute paths in latent space, we assume availability of an autoencoder which can encode samples from original to hidden space and decode samples from hidden to original feature space.
| Path | Description |
|---|---|
| Original space Linear path (O-L-IG) | Linear path computed by linearly interpolating between the sample and the baseline in the original feature space. |
| Hidden space Linear path (H-L-IG) | Linear path computed by linearly interpolating between the sample and the baseline in the hidden space. |
| Original space Neighbors path (O-N-IG) | Neighbors path computed by picking nearest data points between the sample and the baseline in the original feature space. |
| Hidden space Neighbors path (H-N-IG) | Neighbors path computed by picking nearest data points between the sample and the baseline in the hidden space. |
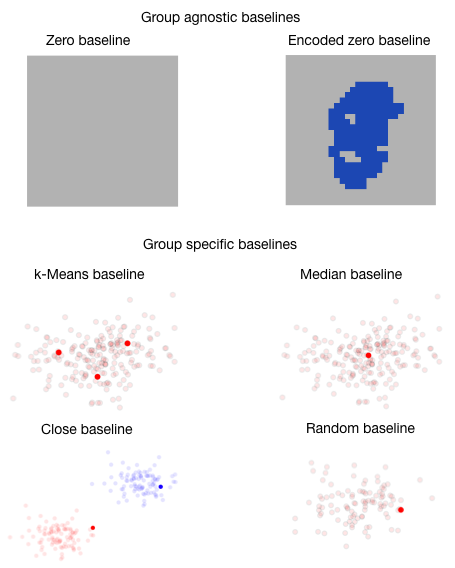
EIG also includes two classes of baselines: group-agnostic and group-specific baselines. The first, group-agnostic baseline does not require any prior biological information to define it. Group-specific baseline uses different methods for selecting reference points from the class of interest (k-means,median, close and random). These baseline points can be chosen either in the original or hidden feature space.
| Baseline | Class | Description |
|---|---|---|
| Zero | Group-agnostic | An all zero vector. |
| Encoded-zero | Group-agnostic | It requires an encoder/decoder to/from latent space such that we can use an all-zero point in the latent space and pass it to through the decoder to generate our baseline. The encoded-zero represents the mean of the data on which the autoencoder was trained. Interpretation with this baseline captures features that deviate from the mean and thus contribute to a sample’s prediction. |
| k-Means | Group-specific | In this approach we cluster the points of the baseline class to k different clusters and then use cluster centroids as baseline points. The number of clusters can be selected by cross-validation.This method gives baseline points that represent different subgroups that might be present in the baseline class. |
| Median | Group-specific | In this approach we compute the euclidean distance of all the points of the baseline class from the median and select the points closest to the median. Points chosen using this method protect the later interpretation against outliers in the baseline class. |
| Close | Group-specific | In this approach we compute the euclidean distance of all the points in the baseline class from all the points in the class of interest and pick points from the baseline class that are close to as ample from the class of interest as its baseline. These baseline points are close to the sample and may thus help capture a minimal set of distinguishing features between the baselines and the points of interest. When using this approach we discard the closest point from the baseline class to avoid extreme outlier points. |
| Random | Group-specific | In this approach we randomly sample one or more points from the baseline class. This serves as the naive method to evaluate the effectiveness of the other methods of selecting baselines |
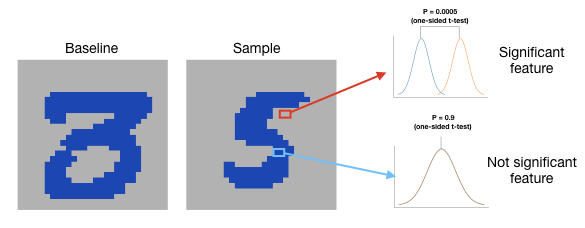
Finally, we include a significance test procedure to identify significant features associated with a prediction task. This procedure first computes the relative ranking of a feature’s attribution across samples belonging to a class of interest. Then, these rankings for a similarly sized random set of samples are computed. The two sets of relative ranking are then compared using a one-sided t-test with Bonferroni correction for multiple testing to identify the set of significant features.
Installation
EIG can be installed using
pip install eig
Examples
The following files contain the examples using EIG paths and baselines. We demonstrate usage of EIG on MNIST digits with a convolutional neural network (CNN) and on splicing data with a feed forward network (DNN).
Please download splicing data from here and place the file in the data folder to run the splicing examples.
| File | Description |
|---|---|
| O-L-IG path with digits CNN | This notebook contains MNIST digit examples with linear path in the original feature space with group specific baselines (median, k-means, close, random) and group agnostic baseline (encoded_zero). |
| H-L-IG path with digits CNN | This notebook contains MNIST digit examples with linear path in the latent feature space with group specific baselines (median, k-means, close, random) and group agnostic baseline (encoded_zero). |
| O-N-IG path with digits CNN | This notebook contains MNIST digit examples with neighbors path in the original feature space with group specific baselines (median, k-means, close, random) and group agnostic baseline (encoded_zero). |
| H-N-IG path with digits CNN | This notebook contains MNIST digit examples with neighbors path in the latent feature space with group specific baselines (median, k-means, close, random) and group agnostic baseline (encoded_zero). |
| O-L-IG path with splicing DNN | This notebook contains splicing examples with linear path in the original feature space with group specific baselines (median, k-means, close, random) and group agnostic baseline (encoded_zero). |
| H-L-IG path with splicing DNN | This notebook contains splicing examples with linear path in the latent feature space with group specific baselines (median, k-means, close, random) and group agnostic baseline (encoded_zero). |
| O-N-IG path with splicing DNN | This notebook contains splicing examples with neighbors path in the original feature space with group specific baselines (median, k-means, close, random) and group agnostic baseline (encoded_zero). |
| H-N-IG path with splicing DNN | This notebook contains splicing examples with neighbors path in the latent feature space with group specific baselines (median, k-means, close, random) and group agnostic baseline (encoded_zero). |


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file eig-0.1.4.tar.gz.
File metadata
- Download URL: eig-0.1.4.tar.gz
- Upload date:
- Size: 30.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.1.0 requests-toolbelt/0.9.1 tqdm/4.38.0 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
87be871962c185bfac3ee64687b04ee3e60eba0df84c24f16d5b772e26cc22af
|
|
| MD5 |
37e50062874615b7c3e19bcc043b91c8
|
|
| BLAKE2b-256 |
69448a0c6a8bac57df19724109434cf9fd96580bea29bf37c1319bb480c68029
|
File details
Details for the file eig-0.1.4-py3-none-any.whl.
File metadata
- Download URL: eig-0.1.4-py3-none-any.whl
- Upload date:
- Size: 56.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.1.0 requests-toolbelt/0.9.1 tqdm/4.38.0 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7cc6ec412050e6227d383432d0ca27418566592777725518fcc48e22a157f4b5
|
|
| MD5 |
3ed4673eb2e6f538e4964a2196b9f0cf
|
|
| BLAKE2b-256 |
4acda5b9f38956d29bb1bfb57e73427c7b7f6aee44bb01bceba9011816690219
|







