EvaDB AI-Relational Database System

Project description

Database system for AI-powered apps





Follow EvaDB









EvaDB enables software developers to build AI apps in a few lines of code. Its powerful SQL API simplifies AI app development for both structured and unstructured data. EvaDB's benefits include:
🔮 Easy to connect the EvaDB query engine with your data sources, such as PostgreSQL or S3 buckets, and build AI-powered apps with SQL queries.
| Structured Data Sources | Unstructured Data Sources | Application Data Sources |
|---|---|---|
|
|
|
More details on the supported data sources is available here.
🤝 Query your connected data with a pre-trained AI model from Hugging Face, OpenAI, YOLO, Stable Diffusion, etc.
| Hugging Face | OpenAI | YOLO |
|---|---|---|
|
|
|
More details on the supported AI models is available here
🔧 Create or fine-tune AI models for regression, classification, and time series forecasting.
| Regression | Classification | Time Series Forecasting |
|---|---|---|
|
|
|
More details on the supported AutoML frameworks is available here.
💰 Faster AI queries thanks to AI-centric query optimizations such as caching, batching, and parallel processing.
- Function result caching helps reuse results of expensive AI function calls.
- LLM batching reduces token usage and dollars spent on LLM calls.
- Parallel query processing saves money and time spent on running AI models by better utilizing CPUs and/or GPUs.
- Query predicate re-ordering and predicate push-down accelerates queries over both structured and unstructured data.
More details on the optimizations in EvaDB is available here.
👋 Hey! If you're excited about our vision of bringing AI inside database systems, show some ❤️ by:
- ⭐ starring our GitHub 🐙 Repo
- 📟 joining our Slack Community
- 🐦 following us on Twitter
- 📝 following us on Medium
We would love to learn about your AI app. Please complete this 1-minute form: https://v0fbgcue0cm.typeform.com/to/BZHZWeZm
Quick Links
- Quick Links
- Documentation
- Why EvaDB
- How does EvaDB work
- Illustrative Queries
- Illustrative Apps
- More Illustrative Queries
- Architecture of EvaDB
- Community and Support
- Contributing
- Star History
- License
Documentation
You can find the complete documentation of EvaDB at evadb.ai/docs 📚✨🚀
Why EvaDB
In the world of AI, we've reached a stage where many AI tasks that were traditionally handled by AI or ML engineers can now be automated. EvaDB enables software developers with the ability to perform advanced AI tasks without needing to delve into the intricate details.
EvaDB covers many AI applications, including regression, classification, image recognition, question answering, and many other generative AI applications. EvaDB targets 99% of AI problems that are often repetitive and can be automated with a simple function call in an SQL query. Until now, there is no comprehensive open-source framework for bringing AI into an existing SQL database system with a principled AI optimization framework, and that's where EvaDB comes in.
Our target audience is software developers who may not necessarily have a background in AI but require AI capabilities to solve specific problems. We target programmers who write simple SQL queries inside their CRUD apps. With EvaDB, it is possible to easily add AI features to these apps by calling built-in AI functions in the queries.
How does EvaDB work
- Connect EvaDB to your SQL and vector database systems with the `CREATE DATABASE` and `CREATE INDEX` statements.
- Write SQL queries with AI functions to get inference results:
- Pick a pre-trained AI model from Hugging Face, Open AI, Ultralytics, PyTorch, and built-in AI frameworks for generative AI, NLP, and vision applications;
- or pick from a variety of state-of-the-art ML engines for classic ML use-cases (classification, regression, etc.);
- or bring your custom model built with any AI/ML framework using `CREATE FUNCTION`.
Follow the getting started guide to get on-boarded as fast as possible.
Illustrative Queries
- Get insights about Github stargazers using GPT4.
SELECT name, country, email, programming_languages, social_media, GPT4(prompt,topics_of_interest)
FROM gpt4all_StargazerInsights;
--- Prompt to GPT-4
You are given 10 rows of input, each row is separated by two new line characters.
Categorize the topics listed in each row into one or more of the following 3 technical areas - Machine Learning, Databases, and Web development. If the topics listed are not related to any of these 3 areas, output a single N/A. Do not miss any input row. Do not add any additional text or numbers to your output.
The output rows must be separated by two new line characters. Each input row must generate exactly one output row. For example, the input row [Recommendation systems, Deep neural networks, Postgres] must generate only the output row [Machine Learning, Databases].
The input row [enterpreneurship, startups, venture capital] must generate the output row N/A.
- Build a vector index on the feature embeddings returned by the SIFT Feature Extractor on a collection of Reddit images. Return the top-5 similar images for a given image.
CREATE INDEX reddit_sift_image_index
ON reddit_dataset (SiftFeatureExtractor(data))
USING FAISS
SELECT name FROM reddit_dataset ORDER BY
Similarity(
SiftFeatureExtractor(Open('reddit-images/g1074_d4mxztt.jpg')),
SiftFeatureExtractor(data)
)
LIMIT 5
Illustrative Apps
Here are some illustrative AI apps built using EvaDB (each notebook can be opened on Google Colab):
- 🔮 Sentiment Analysis using LLM within PostgreSQL
- 🔮 ChatGPT-based Video Question Answering
- 🔮 Text Summarization on PDF Documents
- 🔮 Analysing Traffic Flow with YOLO
- 🔮 Examining Emotions of Movie
- 🔮 Image Similarity Search
More Illustrative Queries
- Get a transcript from a video stored in a table using a Speech Recognition model. Then, ask questions on the extracted transcript using ChatGPT.
CREATE TABLE text_summary AS
SELECT SpeechRecognizer(audio) FROM ukraine_video;
SELECT ChatGPT('Is this video summary related to Ukraine russia war', text)
FROM text_summary;
- Train a classic ML model for prediction using the Ludwig AI engine.
CREATE FUNCTION IF NOT EXISTS PredictHouseRent FROM
(SELECT * FROM HomeRentals)
TYPE Ludwig
PREDICT 'rental_price'
TIME_LIMIT 120;
Architecture of EvaDB
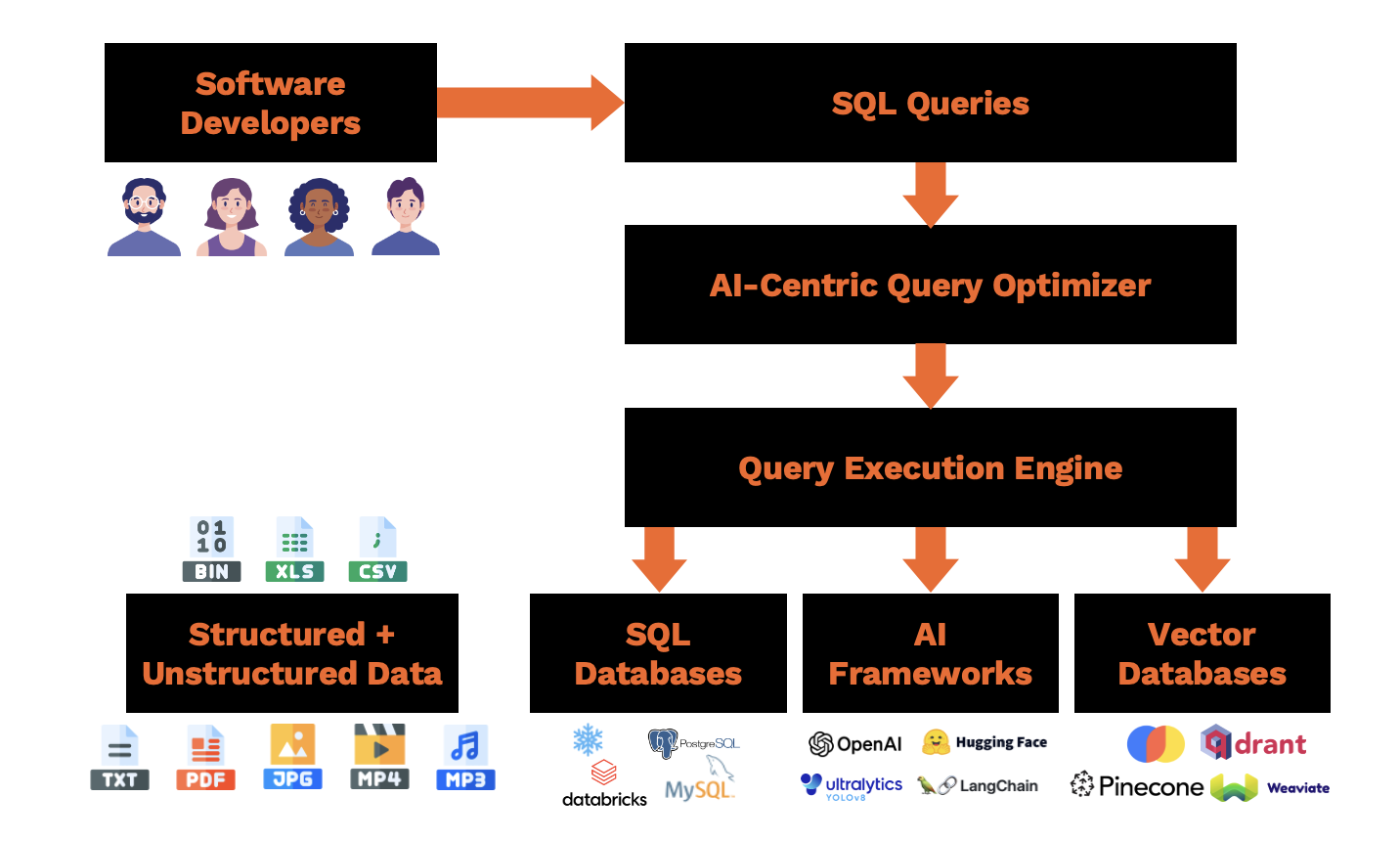
Community and Support
We would love to learn about your AI app. Please complete this 1-minute form: https://v0fbgcue0cm.typeform.com/to/BZHZWeZm
If you run into any bugs or have any comments, you can reach us on our Slack Community 📟 or create a Github Issue :bug:.
Here is EvaDB's public roadmap 🛤️. We prioritize features based on user feedback, so we'd love to hear from you!
Contributing
We are a lean team on a mission to bring AI inside database systems! All kinds of contributions to EvaDB are appreciated 🙌 If you'd like to get involved, here's information on where we could use your help: contribution guide 🤗



Star History

License
Copyright (c) Georgia Tech Database Group. Licensed under an Apache License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file evadb-0.3.9.tar.gz.
File metadata
- Download URL: evadb-0.3.9.tar.gz
- Upload date:
- Size: 292.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eadbee5ae2feb96499fde35b5fc625b8e426899ba71324a018b5efce27fdfd85
|
|
| MD5 |
35a3417da056884e107371018c06081c
|
|
| BLAKE2b-256 |
0bea23fcb3fe9ef24af382c6dffbf0ae8605e2c657427565a4ad19cbe69d5fcc
|
File details
Details for the file evadb-0.3.9-py3-none-any.whl.
File metadata
- Download URL: evadb-0.3.9-py3-none-any.whl
- Upload date:
- Size: 578.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2ecc1788e1ebf6cfa210bc010a33b9674a0716072795540bcf9cd8047d9fc10a
|
|
| MD5 |
00ea892d47e2e97a21c501602f18376a
|
|
| BLAKE2b-256 |
8a5a695a26e8f88d49df6f304a047891cb9e0186ab05ec29cb2379da5565e26a
|







