Exhaustive Feature Selection

Project description
ExhauFS
Exhaustive feature selection for classification and survival analysis. Please cite this paper if you are using ExhauFS in your work:
Nersisyan S, Novosad V, Galatenko A, Sokolov A, Bokov G, Konovalov A, Alekseev D, Tonevitsky A. ExhauFS: exhaustive search-based feature selection for classification and survival regression. bioRxiv. 2021 Aug 04. doi: 10.1101/2021.08.03.454798.
Table of Contents
Introduction
Installation
Tutorial
Running ExhauFS
Functions and classes
Introduction
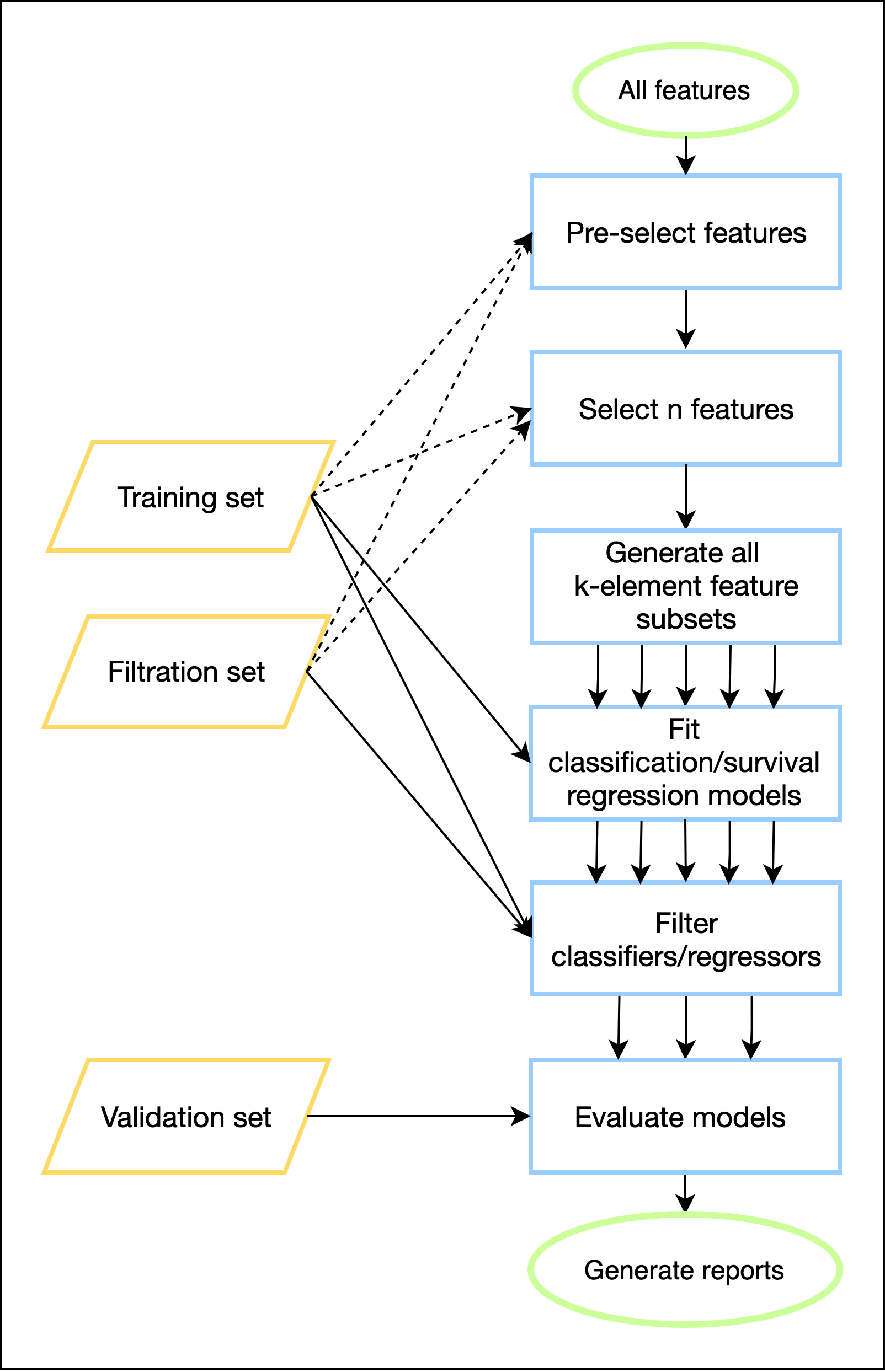
The main idea behind ExhauFS is the exhaustive search of feature subsets to construct the most powerful classification and survival regression models. Since computational complexity of such approach grows exponentially with respect to combination length, we first narrow down features list in order to make the search practically feasible. Briefly, a pipeline is implemented as follows:
- Feature pre-selection: filter features by specified method.
- Feature selection: select "best" n features for exhaustive search.
- Exhaustive search: iterate through all possible k-element feature subsets and fit classification/regression models.
- Evaluation: evaluate each model and make summary of all passed feature subsets
Input data can consist from different batches (datasets), and each dataset should be labeled by one of the following types:
- Training set: samples from training datasets will be used for tuning classification/regression models. At least one such dataset is required; if multiple given, the union will be used.
- Filtration set: all tuned models will be first evaluated on training and filtration sets. If specified thresholds for accuracy are reached, model will be evaluated on validation (test) sets. The use of filtration sets is optional.
- Validation (test) set: performance of models that passed filtration thresholds then evaluated on validation sets. At least one such dataset is required; if multiple given, model will be evaluated on all test sets independently.
Installation
Prerequisites:
Make sure you have installed all of the following prerequisites on your development machine:
- python3.6+
- pip3
ExhauFS installation:
pip3 install exhaufs
Tutorial
In this section we illustrate the main functionality of ExhauFS, and together with that show how to reproduce the results present in the manuscript.
A toy example (classification)
We illustrate ExhauFS basics by using a small cervical cancer toy dataset with 72 samples and 19 features. All necessary data for this example can be found in tutorial/cervical_cancer directory.
We start from data.csv and annotation.csv files: the first one contains data matrix and the
second one maps each sample to class label and dataset type (training or validation). In this
example we brute force all existing feature triples - this information is reflected in n_k.csv
file (n = 19 is the total number of features). Prior to ExhauFS run we should also create
a configuration file. Here we use random forest classifier and standard accuracy metrics
(config_for_build_classifiers.json). Since all 19 features are used, we do not specify any
feature selector and pre-selector. In order to get only highly accurate classifiers, we impose
0.9 threshold on the minimum of sensitivity (TPR) and specificity (TNR) on the training set.
Now we are ready to execute ExhauFS:
exhaufs build classifiers -c config_for_build_classifiers.json
Output files are located in results_build_classifiers directory.
In this example, we focus only on two reports:
This file contains accuracy metrics for all models which passed 0.9 threshold filtration on the training set. The file is sorted according to the classifier accuracy on the training set, so we can see that almost all models have sensitivity and specificity equal to 1.0. Among these models there are multiple cases with particularly high accuracy on the validation set, e.g.
Here we see a number of occurrences of each feature in the set of constructed models which passed 0.9 accuracy threshold. The most important features could be picked, e.g., by taking rows with FDR < 0.05.
Let us take a closer look to the particular classifier built on
perception_vulnerability, socialSupport_instrumental and empowerment_desires features.
To do that, we should create an
additional configuration file with features_subset parameter set to the desired
triple (config_for_summary_classifiers.json). To run ExhauFS in the summary mode,
simply execute the following command:
exhaufs summary classifiers -c config_for_summary_classifiers.json
Note, that we do not specify any feature selection/pre-selection or accuracy threshold parameters for the summary mode. The most important of generated files are:
report.txt: accuracy scores for the training and the validation datasets.ROC_CervicalCancerBehaviorRisk_Training.pdf: ROC curve for the training set. The red dot stands for actual sensitivity and specificity. For example, the classifier does not work ideally on the training set despite AUC equals 1.ROC_CervicalCancerBehaviorRisk_Validation.pdf: ROC curve for validation set.
Breast cancer (classification)
As a real-life example of the classification module of the tool we used multi-cohort breast cancer dataset.
The objective is to predict whether a patient will have cancer recurrence within first 5 years after the surgery
based on gene expression profile in the removed tumor (see our manuscript for the details).
Configuration and output files for this example are
located in tutorial/breast_cancer folder, input data can be downloaded here. The microarray data are split into independent training, filtration and validation sets.
The following options are used (config_for_build_classifiers.json):
"feature_pre_selector": "f_test"- this is for pre-selection of genes whose expression distribution is similar in training and filtration datasets (the batch effect removal approach)."feature_selector": "t_test"- top n most differentially expressed genes are selected. Additional option"use_filtration": truemeans that Student's t-test will be applied to the union of training and filtration sets."preprocessor": "StandardScaler"- prior classifier fitting, data are centered and scaled (z-score transformation)."model": "SVC"- Support Vector machine Classifier (SVC) is used. Additional arguments are used to specify linear kernel, normalization for unbalanced classes and a cross-validation grid for penalty parameter (C) estimation.
Classifier construction with the given n_k.csv file could be done by the same command
as in the previous toy example (however, this will take several days to finish).
Here we review two output reports which were not covered in the toy example:
For each n, k pair the number of classifiers which passed the 0.65 accuracy threshold on the training and the filtration sets is presented (num_training_reliable). All these classifiers were evaluated on the validation set; num_validation_reliable and percentage_reliable columns contain the fraction of these classifiers which also passed 0.65 accuracy threshold on the validation set. For all values of k above 10 we see almost 100% passability, which means the absence of overfitting and successful victory over the batch effects (all classifiers which demonstrated reliable performance on the training and the filtration sets were also good on the validation one).
This is a technical though useful file: the list of pre-selected genes is sorted according to the rate of
differential expression (t_test feature selection). Each pipeline iteration begins from
the selection of the first n entries from this file.
As in the previous toy example, let us take a closer look to the single gene signature
(see config_for_summary_classifiers.json). The following output files were not
covered in the toy example:
feature_importances.pdf(contains coefficients of the linear SVM classifier)model.pkl(Python-pickled classifier and pre-processor objects)
ExhauFS also allows one to evaluate constucted classifiers on time-to-event data.
For example, let us evaluate the same ten-gene signature on
additional RNA-seq TCGA-BRCA dataset. To do that, we should include to desired feature
subset and pickled model path to the configuration file (config_for_km_plot.json).
The analysis could be done by running
exhaufs km_plot -c config_for_km_plot.json
This will generate the Kaplan-Meier plot (results_km_plot/KM_TCGA-BRCA_Validation.pdf).
Colorectal cancer (survival regression)
As a real-life example of the regression part of the tool we used colorectal cancer dataset.
Transformed data and config used for pipeline can be found here.
Same with classification, the main objective was to analyse contribution of different feature [pre]selection techniques and accuracy scores using Cox Regression as a main model.
We achieved best results using concordance_index as a feature selector and as a main scoring function.
Again, same with classification, firstly we need to make n, k grid table for the pipeline.
As a result of exhaufs estimate regressors -c confifg_for_estimate_regressors.json --max_estimated_time 3 --max_k 20 we got the estimated_times.csv table with n/k grid and predicted running time for each pair of values.
Same with examples above, we can build regression models or make summary for one specific set of features as follows:
exhaufs build regressors -c confifg_for_build_regressors.jsonwill produce same files as for classification task.exhaufs summary regressors -c confifg_for_summary_regressors.jsonwill produce a detailed report for the specified set of features and also a Kaplan-Meier plots for each dataset type.
Where confifg_for_build_regressors.json and confifg_for_summary_regressors.json can be found in the tutorial/colorectal_cancer directory.
Running ExhauFS
Step 1: data preparation
Before running the tool, you should prepare three csv tables containing actual data, its annotation and n / k grid. Both for classification and survival analysis data table should contain numerical values associated with samples (rows) and features (columns):
Example
| Feature 1 | Feature 2 | |
|---|---|---|
| Sample 1 | 17.17 | 365.1 |
| Sample 2 | 56.99 | 123.9 |
| ... | ||
| Sample 98 | 22.22 | 123.4 |
| Sample 99 | 23.23 | 567.8 |
| ... | ||
| Sample 511 | 10.82 | 665.8 |
| Sample 512 | 11.11 | 200.2 |
Annotation table format is different for classification and survival analysis. For classification it should contain binary indicator of sample class (e.g., 1 for recurrent tumor and 0 for non-recurrent), dataset (batch) label and dataset type (Training/Filtration/Validation).
It is important that Class = 1 represents "Positives" and Class = 0 are "negatives", otherwise accuracy scores may be calculated incorrectly.
Note that annotation should be present for each sample listed in the data table in the same order:
Example
| Class | Dataset | Dataset type | |
|---|---|---|---|
| Sample 1 | 1 | GSE3494 | Training |
| Sample 2 | 0 | GSE3494 | Training |
| ... | |||
| Sample 98 | 0 | GSE12093 | Filtration |
| Sample 99 | 0 | GSE12093 | Filtration |
| ... | |||
| Sample 511 | 1 | GSE1456 | Validation |
| Sample 512 | 1 | GSE1456 | Validation |
For survival analysis, annotation table should contain binary event indicator and time to event:
Example
| Event | Time to event | Dataset | Dataset type | |
|---|---|---|---|---|
| Sample 1 | 1 | 100.1 | GSE3494 | Training |
| Sample 2 | 0 | 500.2 | GSE3494 | Training |
| ... | ||||
| Sample 98 | 0 | 623.9 | GSE12093 | Filtration |
| Sample 99 | 0 | 717.1 | GSE12093 | Filtration |
| ... | ||||
| Sample 511 | 1 | 40.5 | GSE1456 | Validation |
| Sample 512 | 1 | 66.7 | GSE1456 | Validation |
Table with n / k grid for exhaustive feature selection:
n is a number of selected features, k is a length of each features subset.
If you are not sure what values for n k to use, see Step 3: defining a n, k grid
Example
| n | k |
|---|---|
| 100 | 1 |
| 100 | 2 |
| ... | ... |
| 20 | 5 |
| 20 | 10 |
| 20 | 15 |
Step 2: creating configuration file
Configuration file is a json file containing all customizable parameters for the model (classification and survival analysis)
Available parameters
🔴!NOTE! - All paths to files / directories can be either relative to the configuration file directory or absolute paths
-
data_pathPath to csv table of the data. -
annotation_pathPath to csv table of the data annotation. -
n_k_pathPath to a n/k grid file. -
output_dirPath to directory for output files. If it doesn't exist, it will be created. -
feature_pre_selector
Name of feature pre-selection function from feature pre-selectors section. -
feature_pre_selector_kwargs
Object/Dictionary of keyword arguments for feature pre-selector function. -
feature_selector
Name of feature selection function from feature selectors section. -
feature_selector_kwargs
Object/Dictionary of keyword arguments for feature selector function. Booleanuse_filtrationindicates whether to use Filtration dataset besides Training dataset for the selector function. -
preprocessorName of class for data preprocessing from sklearn.preprocessing. -
preprocessor_kwargsObject/Dictionary of keyword arguments for preprocessor class initialization.
If you are usingsklearnmodel, usekwargsparameters from the documentation of the model. -
model
Name of class for classification / survival analysis from Classifiers / Regressors section. -
model_kwargsObject/Dictionary of keyword arguments for model initialization.
If you are usingsklearnmodel, usekwargsparameters from the documentation of the model. -
model_CV_rangesObject/Dictionary defining model parameters which should be cross-validated. Keys are parameter names, values are lists for grid search. -
model_CV_foldsNumber of folds for K-Folds cross-validation. -
scoring_functionsList with names for scoring functions (from Accuracy scores section) which will be calculated for each model. If you need to pass parameters to the function (e.g.yearin dynamic auc score), you can use object {"name":function name, "kwargs":parameters object}. -
main_scoring_functionKey from scoring_functions dict defining the "main" scoring function which will be optimized during cross-validation and will be used for model filtering. -
main_scoring_thresholdA number defining threshold for model filtering: models with score below this threshold on training/filtration sets will not be further evaluated. -
n_processesNumber of processes / threads to run on. -
random_stateRandom seed (set to an arbitrary integer for reproducibility). -
verboseIf true, print running time for each pair of n, k.
Step 3: defining a n, k grid
To estimate running time of the exhaustive pipeline and define adequate n / k values you can run:
exhaufs estimate regressors|classifiers -c <config_file> --max_k <max_k> --max_estimated_time <max_estimated_time>
where
config_fileis the path to json configuration file.max_kis the maximum length of each features subset.max_estimated_timeis the time constraint (in hours) for a pipeline running time on one pair of (n, k).
Above script calculates maximum possible values n / k for each k=1...max_k such that pipeline running time for each pair (n, k) is less then max_estimated_time
Step 4: running the exhaustive pipeline
When input data, configuration file and n / k grid are ready,
the exhaustive pipeline can be executed as follows -
- Classifiers:
exhaufs build classifiers -c <config_file>
- Regressors:
exhaufs build regressors -c <config_file>
This will generate multiple files in the specified output folder:
models.csv: this file contains all models (classifiers or regressors) which passed the filtration together with their quality metrics.summary_n_k.csv: for each pair of n, k three numbers are given: number of models which passed the filtration, number of models which showed reliable performance (i.e., passed quality thresholds) on the validation set and their ratio (in %). Low percentage of validation-reliable models together with high number of filtration-reliable models is usually associated with overfitting.summary_features.csv: for each pair (n, k), for each feature, percentage of models carrying this feature is listed (only models which passed the filtration are considered).
Step 5: generating report for a single model
To get detailed report on the specific model (== specific set of features):
- Create configuration file (use ./examples/make_(classifier | regressor)_summary/config.json as a template) and set following key parameters:
data_path- path to dataset used for search of classifiers or regressorsannotation_path- path to annotation fileoutput_dir- path to output directory for detailed reportfeatures_subset- set of features belonging to the classifier or regressor of interest;saving_format- either "tiff" or "pdf": format of the saved plots documents;
-
- For classifier run
exhaufs summary classifiers -c <config_file> - For regressor run
exhaufs summary regressors -c <config_file>
- For classifier run
- Check the detailed report in the
output_dir
If you also have time-to-event data for classification problem, you can make Kaplan-Meier plots based on the classifier predictions.
To do so you can run exhaufs km_plot -c <config_file> and check the output_dir directory.
You can also specify KM_x_label and KM_y_label in the config to change plot axis names.
Functions and classes
Feature pre-selectors
-
from_file
Pre-select features from a given file
name: from_file
kwargs:{ "sep": " " }
-
f_test
Pre-select features without difference between different datasets and types
name: f_test
Feature selectors
-
from_file
Select first n features from a given file
name: from_file
kwargs:{ "sep": " " }
-
t_test
Select n features with the lowest p-values according to t-test
name: t_test
kwargs:{ "use_filtration": false // whether to use filtration dataset with training dataset }
-
spearman_correlation
Select n features with the highest correlation with target label
name: spearman_correlation
kwargs:{ "use_filtration": false // whether to use filtration dataset with training dataset }
-
median
Select n features with the highest median value
name: median
kwargs:{ "use_filtration": false // whether to use filtration dataset with training dataset }
Classification specific selectors:
-
l1_logistic_regression
Select n features with the highest concordance index on one-factor Cox regression.
name: l1_logistic_regression
kwargs:{ "C_low": 0, // minumum inverse l1 penalizer value "C_high": 1000000, // maximum inverse l1 penalizer value "max_iter": 1000, // maximum number of iteration until non-convergance error "use_filtration": false // whether to use filtration dataset with training dataset }
Regression specific selectors:
-
cox_concordance
Select n features with the highest concordance index on one-factor Cox regression.
name: cox_concordance
kwargs:{ "use_filtration": false // whether to use filtration dataset with training dataset }
-
cox_dynamic_auc
Select n features with the highest time-dependent auc on one-factor Cox regression.
name: cox_dynamic_auc
kwargs:{ "year": 3, // time at which to calculate auc "use_filtration": false // whether to use filtration dataset with training dataset }
-
cox_hazard_ratio
Select n features with the highest hazard ratio on one-factor Cox regression.
name: cox_hazard_ratio kwargs:
{ "use_filtration": false // whether to use filtration dataset with training dataset }
-
cox_likelihood
Select n features with the highest log-likelihood on one-factor Cox regression.
name: cox_likelihood
kwargs:{ "use_filtration": false // whether to use filtration dataset with training dataset }
-
l1_cox
Select n features with sparse L1-penalized Cox model.
name: l1_cox
kwargs:{ "p_low": 0, // minumum l1 penalizer value "p_high": 1000000, // maximum l1 penalizer value "max_iter": 1000, // maximum number of iteration until non-convergance error "use_filtration": false // whether to use filtration dataset with training dataset }


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file exhaufs-0.94-py3-none-any.whl.
File metadata
- Download URL: exhaufs-0.94-py3-none-any.whl
- Upload date:
- Size: 48.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.25.1 setuptools/47.1.0 requests-toolbelt/0.9.1 tqdm/4.58.0 CPython/3.8.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
11a40b2d53ebe81ba7583b8ff9fec415ef17b986b6b0772e1344ce4403977d17
|
|
| MD5 |
35eb0b8120c1fb723943fba5f27d1ae6
|
|
| BLAKE2b-256 |
167a2e8411ef702606365b9fa30f913ac538f9b9a2b259a63da81a7447e679b5
|







