Facebook crawler package can help you crawl the posts on public fanspages and groups from Facebook.

Project description
Facebook_Crawler



- The project is developed by TENG-LIN YU(游騰林).
- Please feel free to contact me if you have any suggestions or problems.
Support

Donate is not required to utilize this package, but it would be great to have your support. Either donate, star or share are good to me. Your support will help me keep maintaining and developing in this project
贊助不是使用這個套件的必要條件,但如能獲得你的支持我將會非常感謝。不論是贊助、給予星星或跟朋友分享對我來說都是非常好的支持方式。有你的支持我才能繼續在這個專案中維護和開發新的功能。
What's this?
The project can help us collect the data from Facebook's public Fanspage / group. Here are the three big points of this project:
- You don't need to log in to your account.
- Easy: Just key in the Fanspage/group URL and the target date(to break the while loop).
- Efficient: It collects the data through the requests package directly instead of Selenium.
這個專案可以幫我們從 Facebook 公開的的粉絲頁和公開社團收集資料。以下是本專案的 3 個重點:
- 不需登入: 不需要帳號密碼因此也不用擔心被鎖定帳號
- 簡單: 僅需要粉絲頁/社團的網址和停止的日期(用來跳脫迴圈)
- 高效: 透過 request 直接向伺服器請求資料,不需通過 Selenium
Quickstart
-
Install
pip install -U facebook-crawler
-
Usage
- Facebook Fanspage
import facebook_crawler pageurl= 'https://www.facebook.com/diudiu333' facebook_crawler.Crawl_PagePosts(pageurl=pageurl, until_date='2021-01-01')
- Group
import facebook_crawler groupurl = 'https://www.facebook.com/groups/pythontw' facebook_crawler.Crawl_GroupPosts(groupurl, until_date='2021-01-01')
- Facebook Fanspage
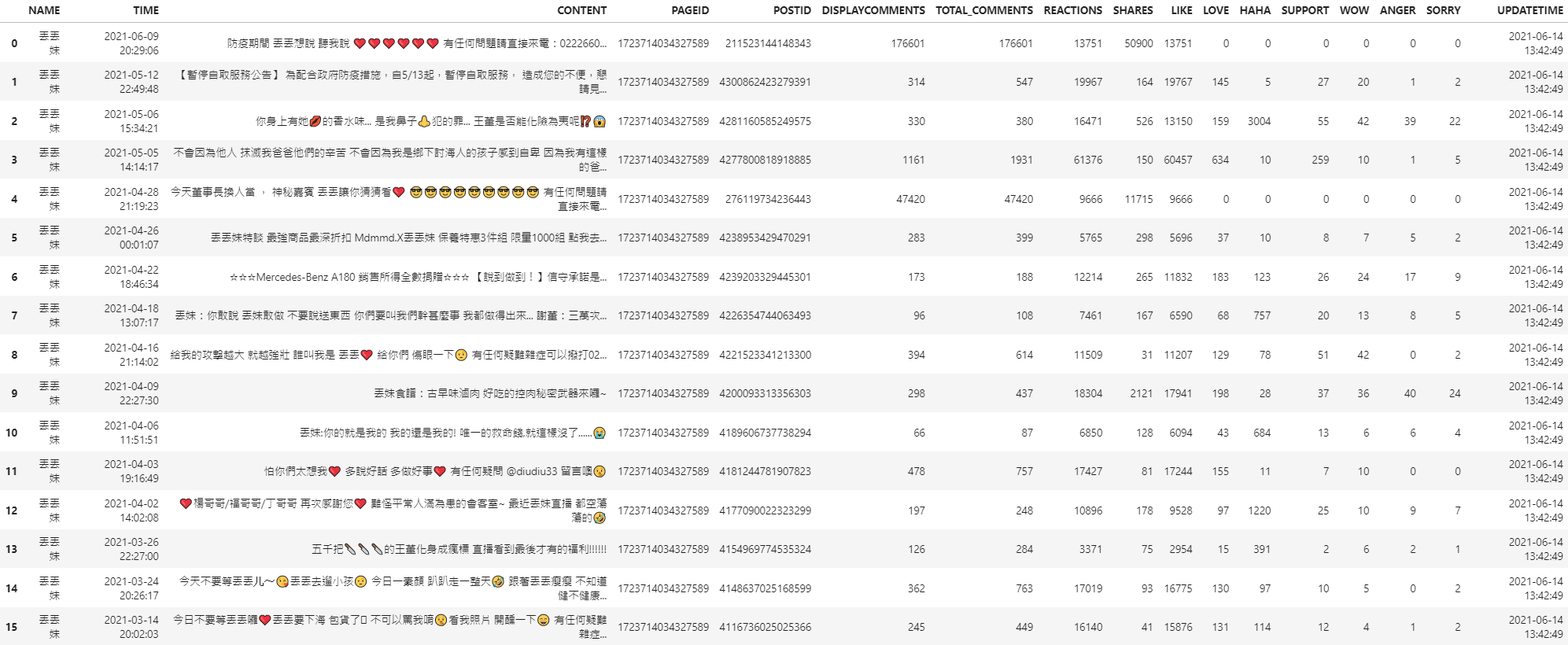

FAQ
-
Could you please release the function that can collect comments content instead of only the number of comments? Please write an E-mail to me and tell me your project goal, thanks!
-
How can I find out the post's link through the data?
You can add the string 'https://www.facebook.com' in front of the POSTID, and it's just its post link. So, for example, if the POSTID is 123456789, and its link is 'https://www.facebook.com/12345679'.
-
Can I directly collect the data in the specific time period?
Nope! It's related to Facebook's website framework. You need to collect the data from the newest post to the older post.
License
- MIT License
- 本專案提供的所有內容均用於教育、非商業用途。本專案不對資料內容錯誤、更新延誤或傳輸中斷負任何責任。
Contact Info
- Author: TENG-LIN YU
- Email: tlyu0419@gmail.com
- Facebook: https://www.facebook.com/tlyu0419
- PYPI: https://pypi.org/project/facebook-crawler/
- Github: https://github.com/TLYu0419/facebook_crawler
Log
- 0.0.26
- Auto changes the cookie after it's expired to keep crawling data without changing IP.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file facebook_crawler-0.0.28.tar.gz.
File metadata
- Download URL: facebook_crawler-0.0.28.tar.gz
- Upload date:
- Size: 8.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.8.2 pkginfo/1.8.2 requests/2.22.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8eeddee3a975e9bcebb06c66e8d5bd4e0cc4802def27e8daa038776bfa545c42
|
|
| MD5 |
d764881f9c6ddad888bab0418fa540c9
|
|
| BLAKE2b-256 |
266fd39078af03936e8fd7af0511aeabd42ae15989cff3810bf6d808fbb96ed5
|
File details
Details for the file facebook_crawler-0.0.28-py3-none-any.whl.
File metadata
- Download URL: facebook_crawler-0.0.28-py3-none-any.whl
- Upload date:
- Size: 8.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.8.2 pkginfo/1.8.2 requests/2.22.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fe58e7718cda597c856c1c0184a7aac91a7e636e26051e59a22a3832c14c21f4
|
|
| MD5 |
9ed2e01ce7f54b0984607d2f684815ab
|
|
| BLAKE2b-256 |
64e4d0d12422d8a74b37a8dc6d4be764cb560fb81ffd668c51882a8035b8ef45
|







