A decentralized framework to train foundational models

Project description







Demo • Introduction • Framework • Features • Docs • Tutorials • Contributions
FedEm is an open-source library empowering community members to actively participate in the training and fine-tuning of foundational models, fostering transparency and equity in AI development. It aims to democratize the process, ensuring inclusivity and collective ownership in model training.
🎥 Demo
Installation
$ pip install fedem
Introduction
The emergence of ChatGPT captured widespread attention, marking the first instance where individuals outside of technical circles could engage with Generative AI. This watershed moment sparked a surge of interest in cultivating secure applications of foundational models, alongside the exploration of domain-specific or community-driven alternatives to ChatGPT. Notably, the unveiling of LLaMA 2, an LLM generously open-sourced by Meta, catalyzed a plethora of advancements. This release fostered the creation of diverse tasks, tools, and resources, spanning from datasets to novel models and applications. Additionally, the introduction of Phi 2, an SLM by Microsoft, demonstrated that modestly-sized models could rival their larger counterparts, offering a compelling alternative that significantly reduces both training and operational costs.
Yet, amid these strides, challenges persist. The training of foundational models within current paradigms demands substantial GPU resources, presenting a barrier to entry for many eager contributors from the broader community. In light of these obstacles, we advocate for FedEm.
FedEm (Federated Emergence) stands as an open-source library dedicated to decentralizing the training process of foundational models, with a commitment to transparency, responsibility, and equity. By empowering every member of the community to participate in the training and fine-tuning of foundational models, FedEm mitigates the overall computational burden per individual, fostering a more democratic approach to model development. In essence, FedEm epitomizes a paradigm shift, where foundational models are crafted not just for the people, but by the people, ensuring inclusivity and collective ownership throughout the training journey.
FedEm Framework
FedEm proposes a methodology to train a foundational model continuously, utilizing adapters. FedEm can be elaborated in mainly two sections. Decentralization of adapter training using CRFs and large scale updation using continuous pretraining checkpoints.Continuous Relay Finetuning (CRF)
Continuous Relay Finetuning
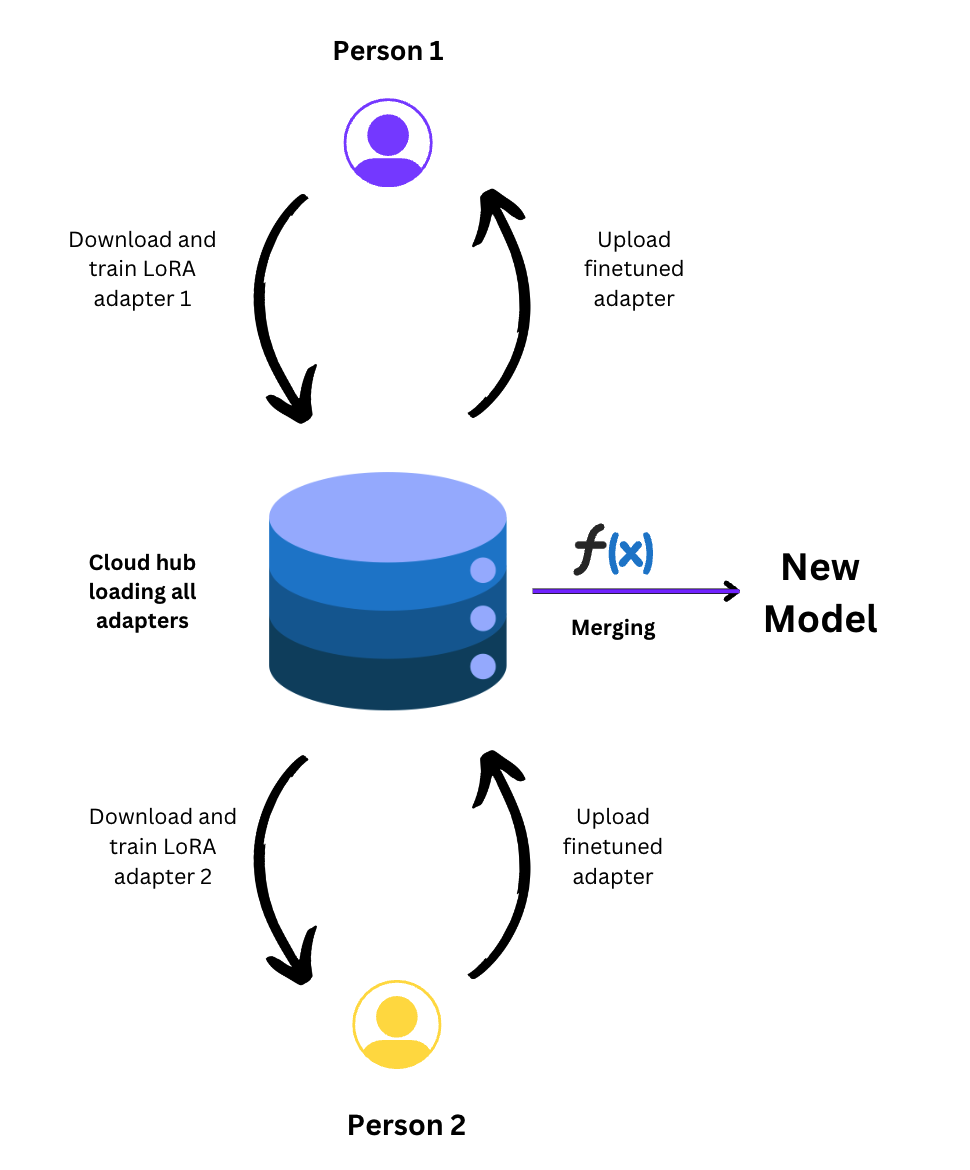
Continuous Pretraining(CPT)
The server-side cloud hub exhibits the capability for perpetual training and deployment of refreshed foundational models at specified intervals, such as monthly or daily cycles. Simultaneously, the CRF adapters engage in iterative refinement against these newly updated models, fostering continual adaptation in response to evolving datasets.
Selective locking of adapters
For continuous relay finetuning, It is important to schedule the adapter training in a fashion that no two clients have the same adapter for training at one point of time. To ensure this access control, we use a time-dependent adapter scheduling. A client downloads an adapter at time T. The adapter will get locked for any other client i.e. cannot be finetuned till one client does not stop finetuning of that adapter. The hub checks periodically in every 5 minutes for access control of adapters. The adapter gets unlocked if any of the following conditions are met:
- time elapsed for finetuning adapter A > 3 hours.
- client pushes the finetuned adapters before 3 hours.
Seshu
Majority, if not all the LLMs, we see today are based on proven Transformer based architectures. And Transfomres have quadratic (in inputs tokens) complexity - therefore slow to train and infer. As a result, new memory and compute efficient attention mechanisms have sprungup, along with Engineering hacks. But, at the end of the day, they are still based on Transformer-based architectures.Further, majority, with the exception of some Chinese LLMs, are English-centric and other languages have a token representation (no pun intended). Often, LLMs have a particulalr tokenizer -- which makes extension to other languages/ domains hard. Vocabulary size and Transfomers Computational Efficiency have an uneasy relationship. Developing SLMs or LLMs is still a compute heavy problem. Therefore, only large consortia with deep pockets, massive talent concentration and GPU farms can afford to build such models.
Client side
Example:
Pre-reqs
- has GPU, registers on HuggingFace/mlsquare for write access
- familair with HuggingFace ecosystem (transfomers, peft, datasets, hub)
- [optional] can donate time or data or both
Actions:
Runs client side script which
- downloads data, pretrains model
- SFTs via LoRA
- pushes the adapter to HuggingFace model hub
Server (who manages the federated learning)
Example:
Pre-reqs
- has (big) GPU(s)
- is familair with HuggingFace ecosystem (transfomers, peft, datasets, hub), databases, ML Enginneering in general
- [optional] can donate time or data or both
Actions:
- Pretrains a multi-lingual Mamba model, publishes a checkpoint
- Evaluated the community contributed adapters in a single-blind fashion, and merges them into the pretrained model
- Does continous pretrainning, and releases checkpoints periodically
Academic Interests
- experiment and identify good federating learning policies
- figure out effective training configurations to PT, CPT, SFT, FedT SLMs and LLMs
- develop new task specific adapters
- contribute your local, vernacular data
- curate datasets
🫶 Contributions:
Fedem is an open-source project, and contributions are welcome. If you want to contribute, you can create new features, fix bugs, or improve the infrastructure. Please refer to the CONTRIBUTING.md file in the repository for more information on how to contribute.
The views expressed or approach being taken - is of the individuals, and they do not represent any organization explicitly or implicitly. Likewise, anyone who wants to contribute their time, compute or data must understand that, this is a community experiment to develop LLMs by the community, and may not result in any significant outcome. On the contrary, this may end up in total failure. The contributors must take this risk on their own.
To see how to contribute, visit Contribution guidelines
Initial Contributors: @dhavala, @yashwardhanchaudhuri, & @SaiNikhileshReddy
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fedem-0.0.7.tar.gz.
File metadata
- Download URL: fedem-0.0.7.tar.gz
- Upload date:
- Size: 25.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ad5722c337f8d5e444808fb1e9c4d4aa962019b81c12c50d7836fb439160846f
|
|
| MD5 |
9b52617f48989280b77e6ba33451bae4
|
|
| BLAKE2b-256 |
29e6a49ea77ee6ace0093d617baaf6278d5eae6198f80883b44b82c4e68bff1e
|
File details
Details for the file fedem-0.0.7-py3-none-any.whl.
File metadata
- Download URL: fedem-0.0.7-py3-none-any.whl
- Upload date:
- Size: 22.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
34121d7d14c9a63d729a8459b2f8f68af1fda9b1fab2577714ce69b1ff5f6953
|
|
| MD5 |
fab7fbb16636e49a20a6abff8aeb5615
|
|
| BLAKE2b-256 |
28e242d1485c806e5ecf79d33c7a471398acd0580311ffbbab0df93f1d0e7a7f
|







