Read and compare numerical data against reference data using exact, fuzzy or custom comparison operations. Simplify your regression testing pipeline.


Project description

FieldCompare








fieldcompare is a Python package with command-line interface (CLI) that can be used to compare
datasets for (fuzzy) equality. It was designed mainly to serve as a tool to realize regression tests
for research software, and in particular research software that deals with numerical simulations.
In regression tests, the output of a software is compared to reference data that was produced by
the same software at an earlier time, in order to detect if changes to the code cause unexpected
changes to the behavior of the software.
Simulations typically produce discrete field data defined on computational grids, and there exists
a variety of standard and widely-used file formats. fieldcompare natively supports a number of
VTK file formats:
.vtp/.pvtp, .vtu/.pvtu, .vts/ .pvts, .vtr/ .pvtr, .vti/ .pvti as well as Paraview's .pvd.
If meshio is installed, it is used under the hood to provide support for a large number of further
mesh file formats (see here). Besides mesh files, csv files are also
supported, a format that is widely used in simulation frameworks to write out secondary data such
as e.g. error norms and convergence rates.
Independent of the file type and format, fieldcompare reads all fields from those files and allows
you to then check all entries of the fields for equality with custom absolute and relative tolerances.
Programmatically, you can provide and use custom predicates (e.g. "smaller-than"), while the
CLI is currently hardwired to (fuzzy) equality checks, which is the most common use case.
A common issue with regression testing of grid files is that the grid may be written with a different
ordering of points or cells, while the actual field data on the grid may be the same. To this end,
fieldcompare provides the option to make the fields read from a grid unique by sorting the grid
by its point coordinates and cell connectivity. Moreover, one can choose to strip ghost points from
the grid from that may occur, for instance, when merging the data from multiple grid partitions
distributed over different processors.
GitHub Action
If you want to perform regression tests within your GitHub workflow, check out our fieldcompare action, which allows you to do so with minimal effort.
Getting started
Quick start
You can easily install fieldcompare through pip:
pip install fieldcompare[all]
Using the CLI, you can now compare data fields of tabular data (e.g. CSV) against reference data:
echo -e "0.0,0.0\n1.0,1.0\n2.0,2.0\n" > file1.csv
echo -e "0.0,0.0\n1.0,1.0\n2.0,2.001\n" > file2.csv
fieldcompare file file1.csv file1.csv
fieldcompare file file2.csv file1.csv
fieldcompare file file2.csv file1.csv --relative-tolerance 1e-2
In the same way, you can compare data fields in mesh files (e.g. data mapped on an unstructured grid VTK file format):
wget https://gitlab.com/dglaeser/fieldcompare/-/raw/main/test/data/test_mesh.vtu -O mesh1.vtu
wget https://gitlab.com/dglaeser/fieldcompare/-/raw/main/test/data/test_mesh_permutated.vtu -O mesh2.vtu
fieldcompare file mesh1.vtu mesh1.vtu
fieldcompare file mesh2.vtu mesh2.vtu
The default comparison scheme allows for small differences in the fields. Specifically, if the shape of the fields match, given a relative tolerance of $\rho$ and an absolute tolerance of $\epsilon$, two fields of floating-point values will be found equal if for each pair of scalar values $a$ and $b$ the following condition holds (for more details on fuzzy comparisons, see below):
$$ \vert a - b \vert \leq max(\rho \cdot max(\vert a \vert, \vert b \vert), \epsilon) $$
If the field consist of strings or integers, all entries of the fields are compared for exact equality. Note that per default, $\epsilon = 0$, but it can be defined via the command line interface. Many more options are available and can be listed via:
fieldcompare file --help
fieldcompare dir --help
There is also a Python API to customize your comparisons with fieldcompare, see the examples below and/or
the API Documentation.
Installation
As mentioned before, you can install fieldcompare simply via pip
pip install fieldcompare[all]
The suffix [all] instructs pip to also install all optional dependencies (for instance meshio).
Omit this suffix if you want to install only the required dependencies.
For an installation from a local copy, navigate to the top folder of this repository and type
pip install . # minimum installation
pip install .[all] # full installation with all dependencies
To install the latest development version you can also install fieldcompare via pip
directly from the git repository:
pip install "git+https://gitlab.com/dglaeser/fieldcompare#egg=fieldcompare[all]
Command-line interface
The CLI exposes two subcommands, namely file and dir, where the former is used to compare two files
for equality, and the latter can be used to compare all files with matching names in two given directories.
That is, type
fieldcompare file PATH_TO_FILE PATH_TO_REFERENCE_FILE
to compare two files, and
fieldcompare dir PATH_TO_DIR PATH_TO_REFERENCE_DIR
for comparing two directories. The latter command will scan both folders for files with matching names, and then run a file comparison on pairs of matching files. This can be useful if your simulation produces a number of files for which you have references stored in some reference folder, and you want to compare them all in a single command. For more info on the CLI options available, type in
fieldcompare file --help
fieldcompare dir --help
API and examples
The following code snippet reads the fields from two files (assuming their format is supported) and prints a message depending on if the success of their comparison:
from fieldcompare import FieldDataComparator
from fieldcompare.io import read_field_data
fields1 = read_field_data("FILENAME1")
fields2 = read_field_data("FILENAME2")
comparator = FieldDataComparator(fields1, fields2)
result = comparator()
if result:
print("Comparison PASSED")
else:
print(f"Comparison failed, report: '{result.report}'")
There are many more options you may use, and infos you can collect on performed comparisons. In the
folder examples/api you can find
examples with instructions on how to use the API of fieldcompare. For more details, have a look at
the API Documentation.
Contribution Guidelines
Contributions are highly welcome! For bug reports, please file an issue. If you want to contribute with features, improvements or bug fixes please fork this project and open a merge request into the main branch of this repository.
Development and test suite
The test suite is automated through tox. To run all tests and linters run
tox
This runs tox with several different environments. To only test under a specfific environment
use the tox option -e. For example, to test under Python 3.9
tox -e py39
All developer dependencies are listed in requirements.txt and can be installed by
pip install -r requirements.txt
fieldcompare uses the auto-formatting tool black, the linter flake8, and we check
type hints with the static type checker mypy. When running tox, all these checks are
performed.
The main developer branch is main and release versions are tagged and deployed to PyPI
in an automated CI/CD pipeline. Deployment is triggered whenever the package version in
pyproject.toml is increased and the change is merged to main.
License
fieldcompare is licensed under the terms and conditions of the GNU General
Public License (GPL) version 3 or - at your option - any later version. The GPL
can be read online or in the
LICENSES/GPL-3.0-or-later.txt file.
See LICENSES/GPL-3.0-or-later.txt for full copying permissions.
The fuzzy details
Fuzziness is crucial when comparing fields of floating-point values, which are unlikely to be bit-wise identical
to a reference solution when computed on different machines and/or after slight modifications to the code. The
equation for fuzzy equality as was shown above is implemented in the FuzzyEquality predicate of fieldcompare,
which is the default predicate for fields that contain floating-point values.
Per default, the FuzzyEquality predicate uses an absolute tolerance of $\epsilon = 0$, which means that each pair
of scalars is tested by a relative criterion. The default relative tolerance depends on the data type and is chosen
as ulp(1.0), where ulp refers to the unit of least precision.
These are rather strict default values that were selected to minimize the chances of false positives when using
fieldcompare without any tolerance settings. Generally, the tolerances should be carefully chosen for the context
at hand.
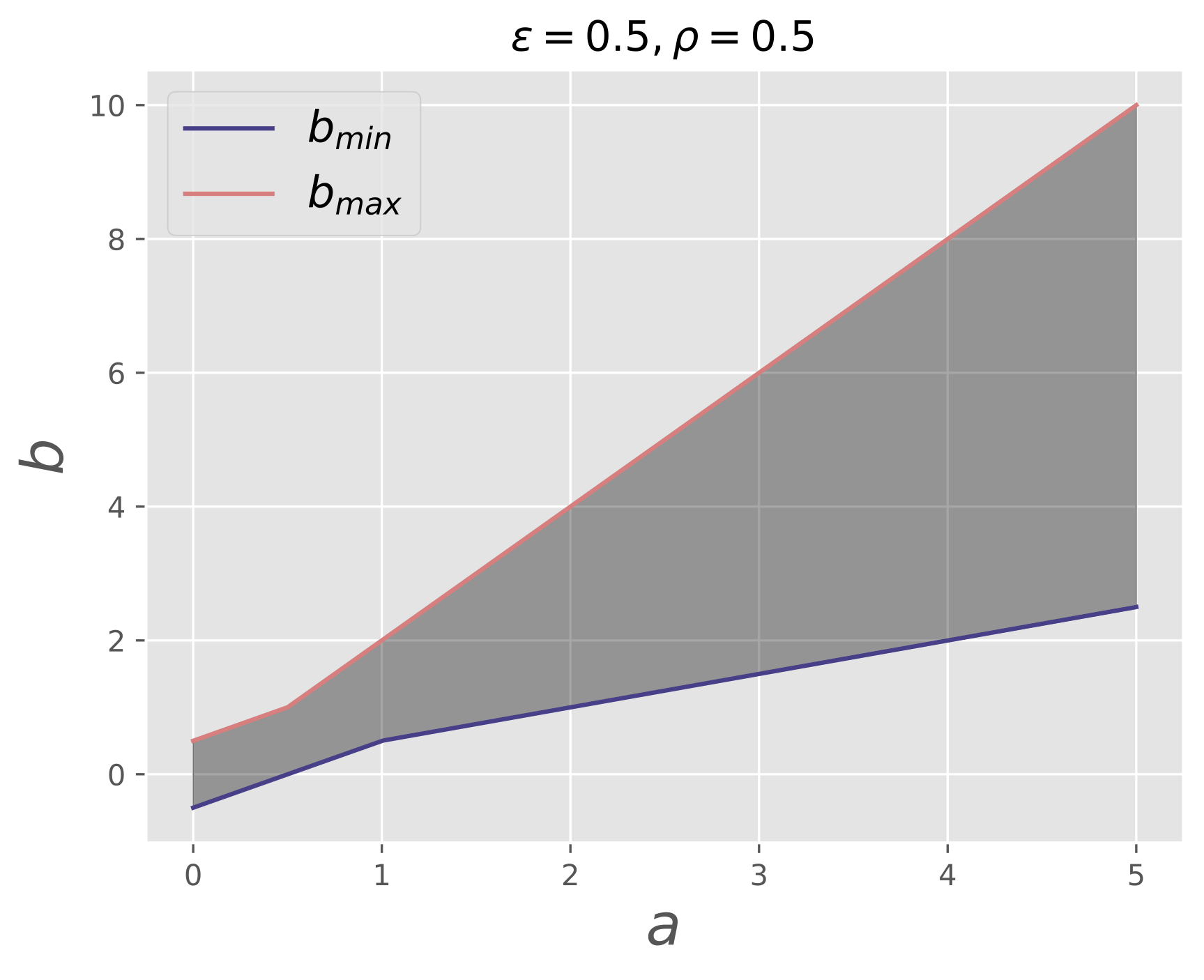
A common issue, in particular in numerical simulations, is that the values in a field may span over several orders of magnitude, which possibly has a negative impact on the precision one can expect from the smaller values. For such scenarios, a suitable choice for the absolute tolerance $\epsilon$ comes into play, which can help to avoid false negatives from comparing the small values in a field, as $\epsilon$ defines a lower bound for the allowed difference between field values. This is illustrated in the plots below, which visualize the pairs of values $(a, b)$ that evaluate fuzzy-equal for different tolerances.
| Custom $\epsilon$ | Default $\epsilon$ |
|---|---|
 |
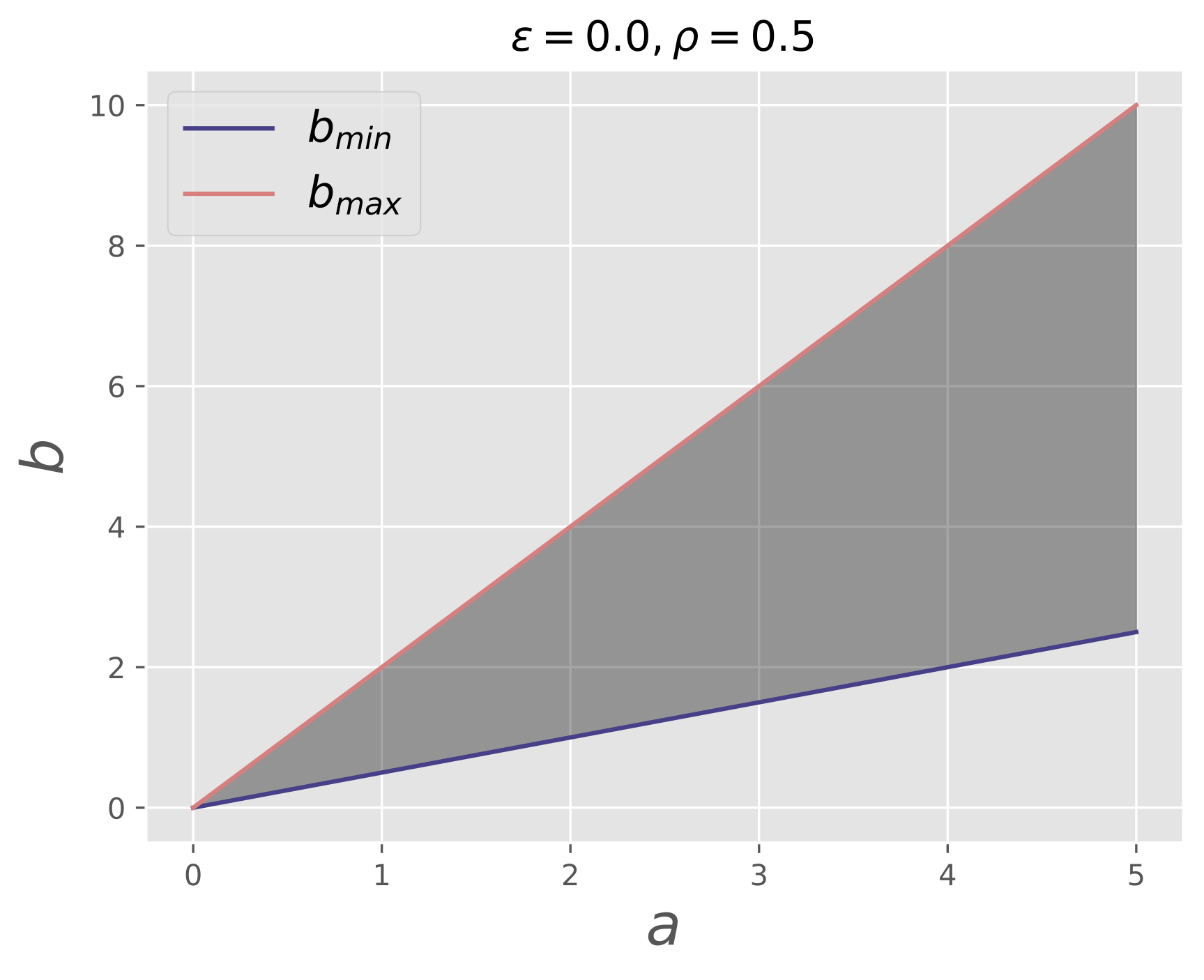 |
In the figures, $b_{min}$ and $b_{max}$ show the minimum and maximum values that are fuzzy-equal to a given
value $a$. As can be seen, while for $\epsilon = 0$ the allowed difference between values goes down to zero as
$a \rightarrow 0$, a constant residual difference is allowed for small values of $a$ in the case of $\epsilon \gt 0$.
A suitable choice for $\epsilon$ depends on the fields to be compared, and when comparing a large number of fields, it
can be cumbersome to define $\epsilon$ for all of them. We found that a useful heuristic is to define $\epsilon$ as
a fraction of the maximum absolute value of both fields as an estimate for the precision that can be expected from the
smaller values. Using the fieldcompare API, this can be achieved with the ScaledTolerance class, which is accepted
by all interfaces receiving tolerances. An example of this is shown below, where we use the predicate_selector argument
of FieldDataComparator to pass in a customized FuzzyEquality:
from fieldcompare import FieldDataComparator
from fieldcompare.io import read_field_data
from fieldcompare.predicates import FuzzyEquality, ScaledTolerance
assert FieldDataComparator(
source=read_field_data("FILENAME1"),
reference=read_field_data("FILENAME2")
)(
predicate_selector=lambda _, __: FuzzyEquality(
abs_tol=ScaledTolerance(base_tolerance=1e-12),
rel_tol=1e-8
)
)
With the above code, the absolute tolerance is computed for a pair of fields $f_1$ and $f_2$ via
$\epsilon = max(mag(f_1), mag(f_2)) \cdot 10^{-12}$, where mag estimates the magnitude as the
maximum absolute scalar value in a field. In the CLI, this functionality is exposed via the
following syntax:
fieldcompare file test_mesh.vtu \
test_mesh_permutated.vtu \
-atol 1e-12*max
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fieldcompare-0.4.0.tar.gz.
File metadata
- Download URL: fieldcompare-0.4.0.tar.gz
- Upload date:
- Size: 119.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bfdcc4ed690f5bba0810a58d243f640cc7c62ae929526761374d38af7fa08c0e
|
|
| MD5 |
8d624473b5379ed0958d3b67adfd550c
|
|
| BLAKE2b-256 |
df3a8f6e0b7ab2ceb9ccdc8c1ad373de4e93e7e27291d0020b8451064a82cbee
|
File details
Details for the file fieldcompare-0.4.0-py3-none-any.whl.
File metadata
- Download URL: fieldcompare-0.4.0-py3-none-any.whl
- Upload date:
- Size: 101.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2745c76b3efa2e128268cb2eca91c422bb1b0ce2dd8555065aac0a6caf3de042
|
|
| MD5 |
51595cb37cca3d1c070c950cf651368b
|
|
| BLAKE2b-256 |
9b8f1edbb26c32e348a0961b9d0268ff83f4db1bca40cd056ebcce6773adfdc4
|







