Findpapers is an application that helps researchers who are looking for references for their work.

Project description
Findpapers


Findpapers is an application that helps researchers who are looking for references for their work. The application will perform searches in several databases (currently ACM, arXiv, bioRxiv, IEEE, medRxiv, PubMed, and Scopus) from a user-defined search query.
In summary, this tool will help you to perform the process below:
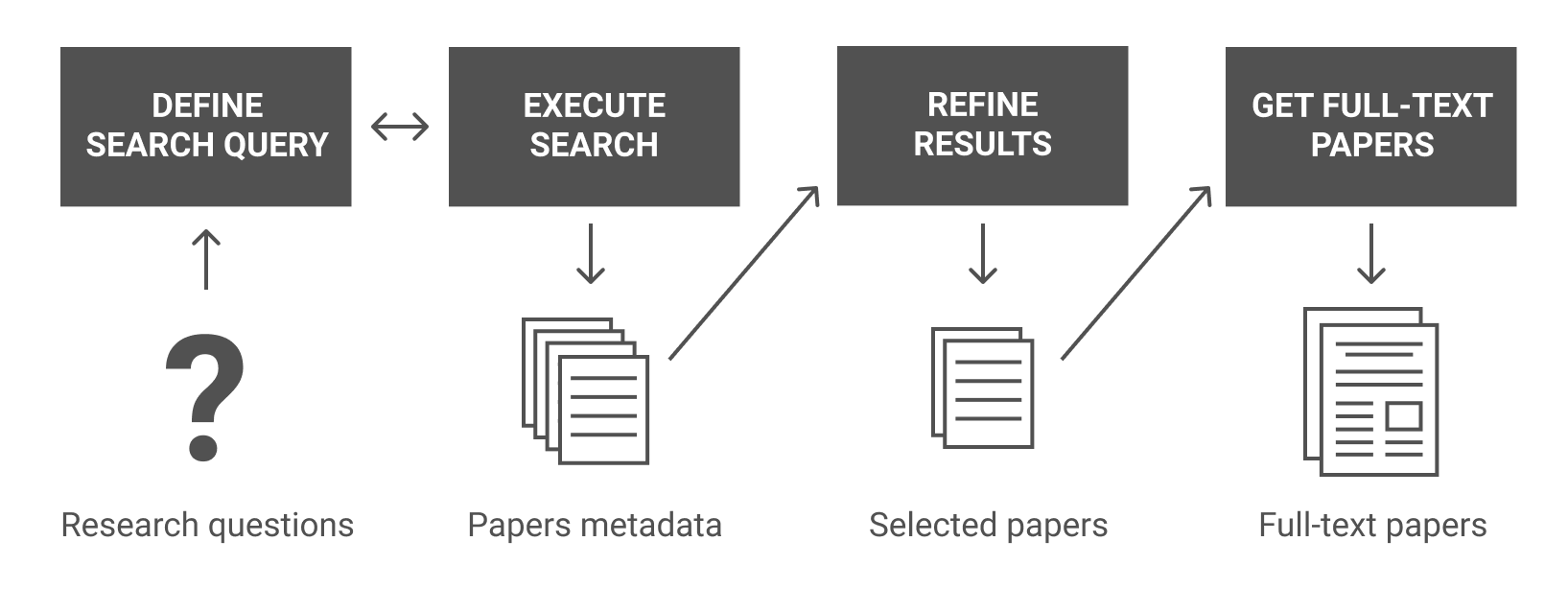
Requirements
- Python 3.7+
Installation
$ pip install findpapers
You can check your Findpapers version running:
$ findpapers version
If you have an old version of the tool and want to upgrade it run the following command:
$ pip install findpapers --upgrade
How to use it?
All application actions are command-line based. The available commands are
-
findpapers search: Search for papers metadata using a query. This search will be made by matching the query with the paper's title, abstract, and keywords. -
findpapers refine: Refine the search results by selecting/classifying the papers -
findpapers download: Download full-text papers using the search results -
findpapers bibtex: Generate a BibTeX file from the search results
You can control the commands logging verbosity by the -v (or --verbose) argument.
In the following sections, we will show how to use the Findpapers commands. However, all the commands have the --help argument to display some summary about their usage, E.g., findpapers search --help.
Search query construction
First of all, we need to know how to build the search queries. The search queries must follow the rules:
-
All the query terms need to be not empty and enclosed by square brackets. E.g., [term a]
-
The query can contain boolean operators, but they must be uppercase. The allowed operators are AND, OR, and NOT. E.g., [term a] AND [term b]
-
All the operators must have at least one whitespace before and after them (tabs or newlines can be valid too). E.g., [term a] OR [term b] OR [term c]
-
The NOT operator must always be preceded by an AND operator E.g., [term a] AND NOT [term b]
-
A subquery needs to be enclosed by parentheses. E.g., [term a] AND ([term b] OR [term c])
-
The composition of terms is only allowed through boolean operators. Queries like "[term a] [term b]" are invalid
We still have a few more rules that are only applicable on bioRxiv and medRxiv databases:
-
On subqueries with parentheses, only 1-level grouping is supported, i.e., queries with 2-level grouping like [term a] OR (([term b] OR [term c]) AND [term d]) are considered invalid
-
Only "OR" connectors are allowed between parentheses, i.e., queries like ([term a] OR [term b]) AND ([term c] OR [term d]) are considered invalid
-
Only "OR" and "AND" connectors are allowed, i.e., queries like [term a] AND NOT [term b] are considered invalid
-
Mixed connectors are not allowed on queries (or subqueries when parentheses are used), i.e., queries like [term a] OR [term b] AND [term b] are considered invalid. But queries like [term a] OR [term b] OR [term b] are considered valid
You can use some wildcards in the query too. Use question mark (?) to replace exactly one character, and use an asterisk (*) to replace zero or more characters:
-
[son?] will match song, sons, ... (But won't match "son")
-
[son*] will match son, song, sons, sonic, songwriting, ...
There are some rules that you'll need to follow when using wildcards:
- Cannot be used at the start of a search term;
- A minimum of 3 characters preceding the asterisk wildcard (*) is required;
- The asterisk wildcard (*) can only be used at the end of a search term;
- Can be used only in single terms;
- Only one wildcard can be included in a search term.
Note: The bioRxiv and medRxiv databases don't support any wildcards, and the IEEE and PubMed databases only support the "*" wildcard.
Let's see some examples of valid and invalid queries:
| Query | Valid? |
|---|---|
| [term a] | Yes |
| ([term a] OR [term b]) | Yes |
| [term a] OR [term b] | Yes |
| [term a] AND [term b] | Yes |
| [term a] AND NOT ([term b] OR [term c]) | Yes |
| [term a] OR ([term b] AND ([term*] OR [t?rm])) | Yes |
| [term a]OR[term b] | No (no whitespace between terms and boolean operator) |
| ([term a] OR [term b] | No (missing parentheses) |
| [term a] or [term b] | No (lowercase boolean operator) |
| term a OR [term b] | No (missing square brackets) |
| [term a] [term b] | No (missing boolean operator) |
| [term a] XOR [term b] | No (invalid boolean operator) |
| [term a] OR NOT [term b] | No (NOT boolean operator must be preceded by AND) |
| [] AND [term b] | No (empty term) |
| [some term*] | No (wildcards can be used only in single terms) |
| [?erm] | No (wildcards cannot be used at the start of a search term) |
| [te*] | No (a minimum of 3 characters preceding the asterisk wildcard is required) |
| [ter*s] | No (the asterisk wildcard can only be used at the end of a search term) |
| [t?rm?] | No (only one wildcard can be included in a search term) |
Basic example (TL;DR)
- Searching for papers:
$ findpapers search /some/path/search.json -q "[happiness] AND ([joy] OR [peace of mind]) AND NOT [stressful]"
- Refining search results:
$ findpapers refine /some/path/search.json
- Downloading full-text from selected papers:
$ findpapers download /some/path/search.json /some/path/papers/ -s
- Generating BibTeX file from selected papers:
$ findpapers bibtex /some/path/search.json /some/path/mybib.bib -s
Advanced example
This advanced usage documentation can be a bit boring to read (and write), so I think it's better to go for a storytelling approach here.
Let's take a look at Dr. McCartney's research. He's a computer scientist interested in AI and music, so he created a search query to collect papers that can help with his research and exported this query to an environment variable.
$ export QUERY="([artificial intelligence] OR [AI] OR [machine learning] OR [ML] OR [deep learning] OR [DL]) AND ([music] OR [s?ng])"
Dr. McCartney is interested in testing his query, so he decides to collect only 20 papers to test whether the query is suitable for his research (the Findpapers results are sorted by publication date in descending order. An important disclaimer about publication dates is that some papers just have the publication year defined. In those cases, the publication date will be set to 01-01-year by Findpapers).
$ findpapers search /some/path/search_paul.json --query "$QUERY" --limit 20
But after taking a look at the results contained in the search_paul.json file, he notices two problems:
- Only one database was used to collect all the 20 papers
- Some collected papers were about drums, but he doesn't like drums or drummers
So he decides to solve these problems by:
- Reformulating his query, and also placing it inside a file to make his life easier (Note that in a text file, you can split your query search into multiple lines. Is it much more comfortable to read, right?).
/some/path/query.txt
([artificial intelligence] OR [AI] OR [machine learning] OR [ML] OR [deep learning] OR [DL])
AND
([music] OR [s?ng])
AND NOT
[drum*]
- Performing the search limiting the number of papers that can be collected by each database.
$ findpapers search /some/path/search_paul.json --query-file /some/path/query.txt --limit-db 4
Now his query returned the papers he wanted, but he realized one thing, no papers were collected from Scopus or IEEE databases. Then he noticed that he needed to pass his Scopus and IEEE API access keys when calling the search command. So he went to https://dev.elsevier.com and https://developer.ieee.org, generated the access keys, and used them in the search.
$ export IEEE_TOKEN=SOME_SUPER_SECRET_TOKEN
$ export SCOPUS_TOKEN=SOME_SUPER_SECRET_TOKEN
$ findpapers search /some/path/search_paul.json --query-file /some/path/query.txt --limit-db 4 --token-ieee "$IEEE_TOKEN" --token-scopus "$SCOPUS_TOKEN"
Now everything is working as he expected, so it's time to do the final papers search. So he defines that he wants to collect only works published between 2000 and 2020. He also decides that he only wants papers collected from ACM, IEEE, and Scopus. And he only wants to papers published on a journal or conference proceedings (Tip: The available publication types on Findpapers are: journal, conference proceedings, book, other. When a particular publication does not fit into any of the other types it is classified as "other", e.g., magazines, newsletters, unpublished manuscripts)
$ findpapers search /some/path/search_paul.json --query-file /some/path/query.txt --token-ieee "$IEEE_TOKEN" --token-scopus "$SCOPUS_TOKEN" --since 2000-01-01 --until 2020-12-31 --databases "acm,ieee,scopus" --publication-types "journal,conference proceedings"
The searching process took a long time, but after many cups of coffee, Dr. McCartney finally has a good list of papers with the potential to help in his research. All the information collected is in the search_paul.json file. He could access this file now and manually filter which works are most interesting for him, but he prefers to use the Findpapers refine command for this.
First, he wants to filter the papers looking only at their basic information.
$ findpapers refine /some/path/search_paul.json
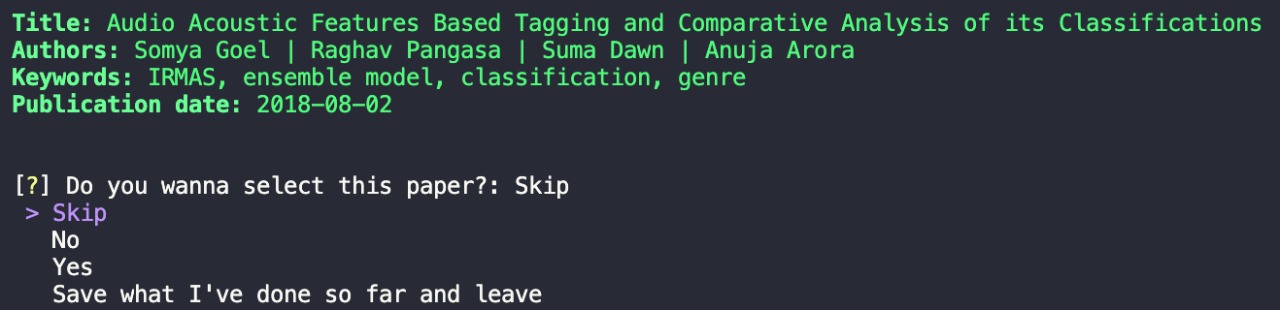
After completing the first round filtering of the collected papers, he decides to do new filtering on the selected ones looking at the paper's extra info (citations, DOI, publication name, etc.) and abstract now. He also chooses to perform some classification while doing this further filtering (tip: he'll need to use spacebar for categories selection). And to help in this process, he also decides to highlight some keywords contained in the abstract.
$ export CATEGORIES_CONTRIBUTION="Contribution:Metric,Tool,Model,Method"
$ export CATEGORIES_RESEARCH_TYPE="Research Type:Validation Research,Solution Proposal,Philosophical,Opinion,Experience,Other"
$ export HIGHLIGHTS="propose, achiev, accuracy, method, metric, result, limitation, state of the art"
$ findpapers refine /some/path/search_paul.json --selected --abstract --extra-info --categories "$CATEGORIES_CONTRIBUTION" --categories "$CATEGORIES_RESEARCH_TYPE" --highlights "$HIGHLIGHTS"
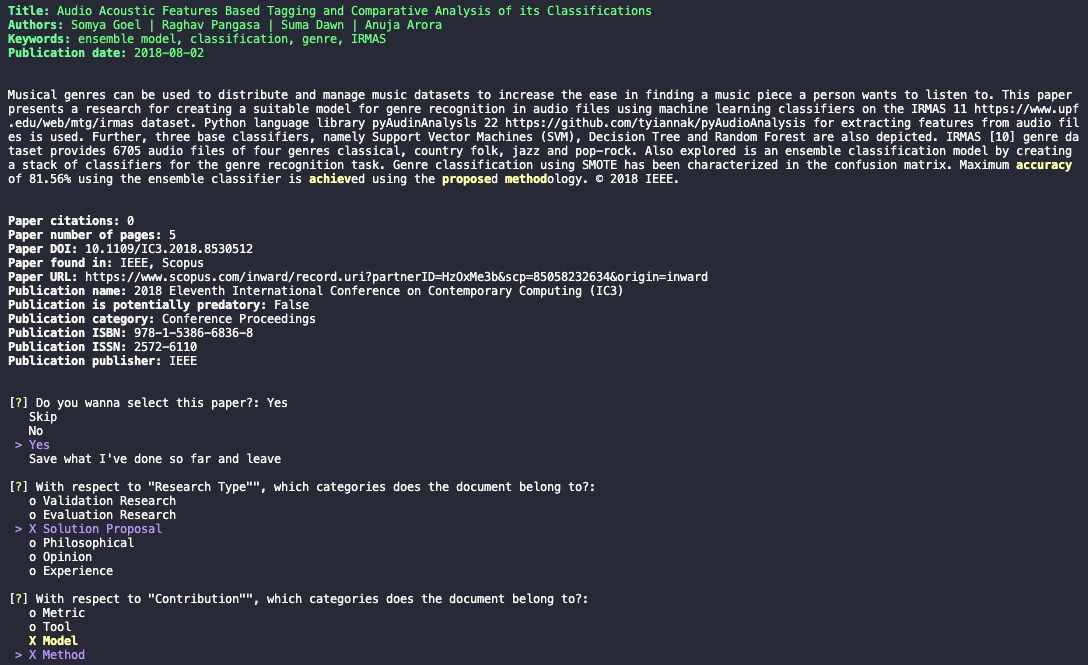
An interesting point to stand out from the tool is that it automatically prevents duplication of papers, merging their information when the same paper is found in different databases. You can see this in the image above, where the Findpapers found the same work on the IEEE and Scopus databases (see "Paper found in" value) and merged the paper information on a single record.
Another interesting extra information given by Findpapers (based on Beall's List) is whether a collected paper was published by a predatory publisher (see "Publication is potentially predatory" value). That is a really good feature, because there is a lot of scientific misinformation out there.
Now that Dr. McCartney has selected all the papers he wanted, he wants to see all of them.
$ findpapers refine /some/path/search_paul.json --selected --abstract --extra-info --list
He wants to see all the removed papers too.
$ findpapers refine /some/path/search_paul.json --removed --abstract --extra-info --list
Then, he decides to download the full-text from all the selected papers which have a "Model" or "Tool" as a contribution.
$ findpapers download /some/path/search_paul.json /some/path/papers --selected --categories "Contribution:Tool,Model"
He also wants to generate the BibTeX file from these papers.
$ findpapers bibtex /some/path/search_paul.json /some/path/mybib.bib --selected --categories "Contribution:Tool,Model"
But when he compared the papers' data in the /some/path/mybib.bib and PDF files in the /some/path/papers folder, he noticed that many papers had not been downloaded.
So when he opened the /some/path/papers/download.log file, he could see the URL of all papers that weren't downloaded correctly. After accessing these links, he noticed that some of them weren't downloaded due to some limitations of Findpapers (currently, the tool has a set of heuristics to perform the download that may not work in all cases). However, the vast majority of papers weren't downloaded because they were behind a paywall. But, Dr. McCartney has access to these papers when he's connected to the network at the university where he works, but unfortunately, he is at home right now.
But he discovers two things that could save him from this mess. First, the university provides a proxy for tunneling requests. Second, Findpapers accepts the configuration of a proxy URL. And of course, he'll use this feature (see the "--proxy" argument on the command bellow).
$ findpapers download /some/path/search_paul.json /some/path/papers --selected --categories "Contribution:Tool,Model" --proxy "https://mccartney:super_secret_pass@liverpool.ac.uk:1234"
Now the vast majority of the papers he has access have been downloaded correctly.
And at the end of it, he decides to download the full-text from all the selected works (regardless of their categorization) and generate their BibTeX file too. And, as he is very happy with the results, he also wants to include a Findpapers entry in the BibTeX file to cite in his work.
$ findpapers download /some/path/search_paul.json /some/path/papers --selected --proxy "https://mccartney:super_secret_pass@liverpool.ac.uk:1234"
$ findpapers bibtex /some/path/search_paul.json /some/path/mybib.bib --selected --findpapers
That's all, folks! We have reached the end of our journey. I hope Dr. McCartney can continue his research and publish his work without any major problems now. You can use findpapers in a more scriptable way too. Check out the search_paul.py file to see how you can do that.
As you could see, all the information collected and enriched by the Findpapers is placed in a single JSON file. From this file, it is possible to create interesting visualizations about the collected data ...
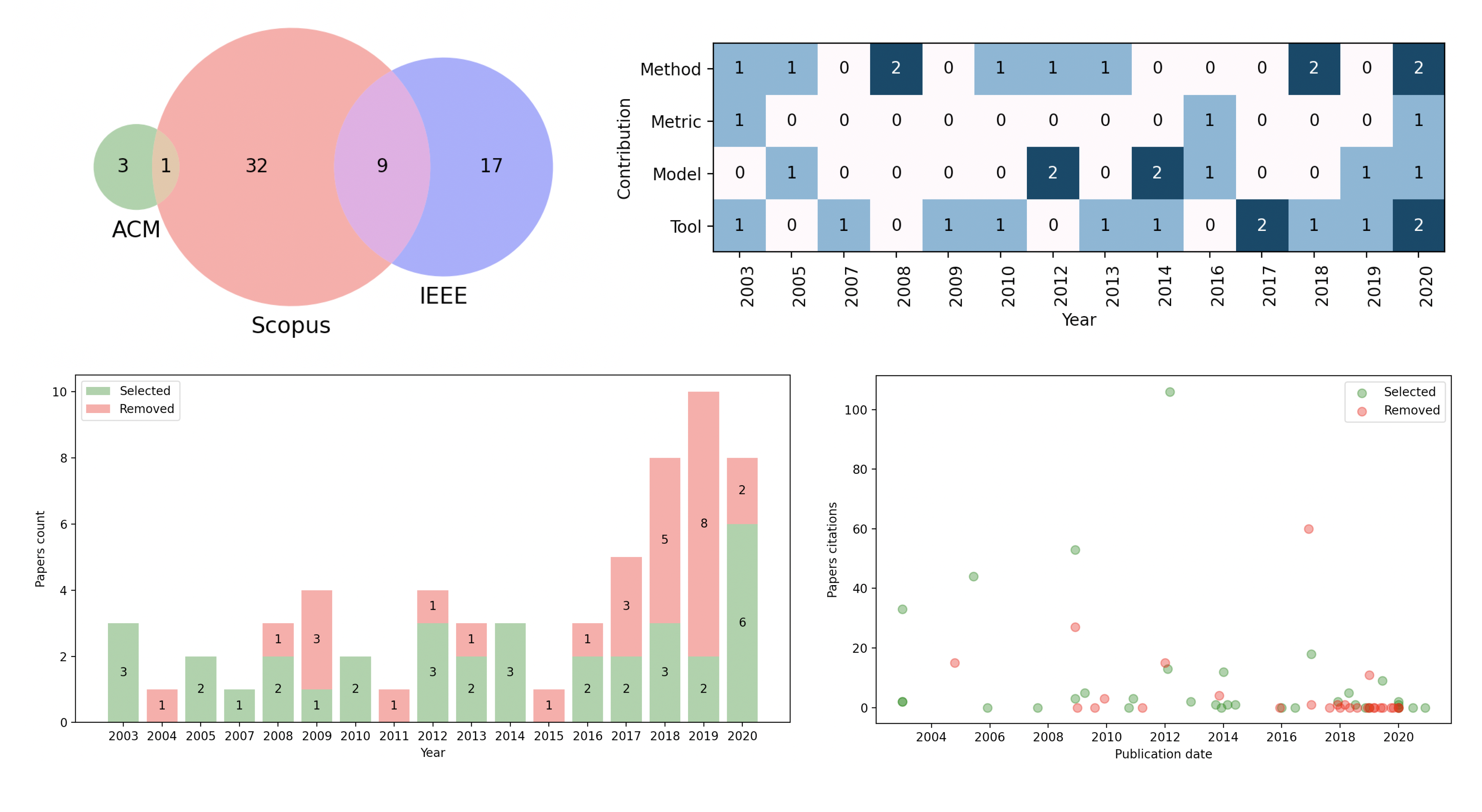
... So, use your imagination! (The samples/charts.py script made the visualization above).
With the story above, we cover all the commands available in Findpapers. I know this documentation is unconventional, but I haven't had time to write a more formal version of the documentation. But you can help us to improve this, take a look at the next section and see how you can do that.
Want to help?
See the contribution guidelines if you'd like to contribute to Findpapers project.
You don't even need to know how to code to contribute to the project. Even the improvement of our documentation is an outstanding contribution.
If this project has been useful for you, please share it with your friends. This project could be helpful for them too.
If you like this project and want to motivate the maintainers, give us a :star:. This kind of recognition will make us very happy with the work that we've done with :heart:
You can also sponsor me :heart_eyes:
Citation
If you want to cite the tool you can use this:
@misc{grosman2020findpapers,
title={{Findpapers: A tool for helping researchers who are looking for related works}},
author={Grosman, Jonatas},
howpublished={\url{https://github.com/jonatasgrosman/findpapers}},
year={2020}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file findpapers-0.6.7.tar.gz.
File metadata
- Download URL: findpapers-0.6.7.tar.gz
- Upload date:
- Size: 96.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.2.2 CPython/3.7.15 Linux/5.15.0-1022-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f5d2bdefb7b85a34eada75adfe5c521a3e01a07c099e8b9beb9010a55cefed4b
|
|
| MD5 |
0c8a02c7a60e259cbfb4d32ee7125656
|
|
| BLAKE2b-256 |
69955137957a6ffd1281f8a1928ada5ff8d7ab5b13605f79b1a20b67a7f12184
|
File details
Details for the file findpapers-0.6.7-py3-none-any.whl.
File metadata
- Download URL: findpapers-0.6.7-py3-none-any.whl
- Upload date:
- Size: 104.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.2.2 CPython/3.7.15 Linux/5.15.0-1022-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6bd872138fb0cad88ddc272ed475df004388b62ac944b2848c0d26afeb831c2b
|
|
| MD5 |
b1da3a84452840b084f4c52e9548d3a4
|
|
| BLAKE2b-256 |
a6def48f1ab15f0146d10fe2a960ee41af55dc905db3b5fa89049ca93d710c07
|







