Flinter, a multi-language code linter.


Project description
flint
flint is a source-code static analyzer and quality checker with multiple programming languages support. For fortran, it intends to follow the coding conventions mentioned in OMS Documentation Wiki page.
Many linter software exists, and are giants full of wisdom compared to the midget flint. The goal of flint is to provide a free, quickly installable, and customizable linter for continuous integration.
It also allows to graphically scan the codebase through the interactive circular packing provided by nobvisual (which can greatly help you to monitor the code style enforcement).
Installation
Install flint from PyPI's flinter (because flint was already taken):
pip install flinter
Usage
flint provides a CLI with the following commands:
Usage: flint [OPTIONS] COMMAND [ARGS]...
-------------------- FLINT ---------------------
. - Flint, because our code stinks... -
You are now using the command line interface of Flint, a Fortran linter
created at CERFACS (https://cerfacs.fr), for the EXCELLERAT center of
excellence (https://www.excellerat.eu/).
This is a python package currently installed in your python environment.
Options:
--help Show this message and exit.
Commands:
config Copy the default rule files locally.
database Create database.
lint Prints detailed file linting info.
score Score the formatting of a database, file, or folder (recursive).
stats Dump stats to file.
struct Print structure of the database, directory, or file.
tree Visual representation of the score with circular packing.
flint config
It copies locally the default rules for a given language. For fortran it will look similar to:
# Set active to false is you want to skip rule
# All are regexp rules, meaning you can add new rules simply by editing this file
# test your rule on https://regex101.com/ if needed
regexp-rules:
missing-spaces-on-do:
message: Missing spaces
regexp: do (\w+)=(\S+),(\S+)
replacement: do \1 = \2, \3
active: true
missing-spaces-around-operator:
message: Missing spaces around operator
regexp: (\w|\))({operators})(\w|\()
replacement: \1 \2 \3
active: true
(...)
# These are rules that span over multiple lines, not accessible by regexp
# You want to edit these rules or add your own, two options:
# - ask us.
# - fork the code.
structure-rules:
max-statements-in-context: 50 # Subroutine of function
max-declared-locals: 12
min-varlen: 3
max-varlen: 20
max-arguments: 5
min-arglen: 3
max-arglen: 20
max-nesting-levels: 5
You can rename the file as e.g. my_code_my_rules.yml and customize it for your own perusal on other commands. Simply use the -r optional flag:
flinter (cmd) (options) -r my_code_my_rules.yml
flint database
It allows the creation of a database. A flint database contains the raw data of the parsing process. In terms of data structure, a database is a tree. In the most general case, the root corresponds to the project main directory. Each subdirectory is then its own tree node (it goes recursively). The leaves on this tree are functions/subroutines (note that a function can also be an internal node if it contains a nested function).
Here is a (partial and adapted) example taken from Nek5000.
{
"type": "file",
"name": "Nek5000/tools/prenek/glomod.f",
"path": "Nek5000/tools/prenek/glomod.f",
"size": 4719,
"children": [
{
"type": "subroutine",
"name": "glomod",
"path": "Nek5000/tools/prenek/glomod.f/glomod",
"size": 135,
"children": [],
"struct_rules": {
"too-many-lines": {
"num_lines": 135,
"max_allowed": 50
}
},
"regexp_rules": {
"not-recommended-use-include": [
{
"line_no": 19,
"line": " include 'basicsp.inc'",
"column": 6,
"span": 7
}
],
"intrinsics-should-be-uppercased": [
{
"line_no": 21,
"line": " common /cisplit/ isplit(nelm)",
"column": 6,
"span": 6
}
]
}
},
{
"type": "subroutine",
"name": "frame",
"path": "Nek5000/tools/prenek/glomod.f/frame",
"size": 268,
"children": [],
"struct_rules": {
"too-many-lines": {
"num_lines": 268,
"max_allowed": 50
}
},
"regexp_rules": {}
}
],
"struct_rules": {},
"regexp_rules": {},
"top_depth": 0,
"max_depth": 0,
"start": 0,
"end": 136417,
"start_line": 0,
"end_line": 4719
}
The most relevant keys are struct_rules and regexp_rules. Note how detailed the information of each error is.
A neat option when handling databases is the possibility of getting a portion of it (a subtree):
flint Nek5000/tools/prenek/glomod.f/glomod --database nek5000.json
creates the following file:
{
"type": "subroutine",
"name": "glomod",
"path": "Nek5000/tools/prenek/glomod.f/glomod",
"size": 135,
"children": [],
"struct_rules": {
"too-many-lines": {
"num_lines": 135,
"max_allowed": 50
}
},
"regexp_rules": {
"not-recommended-use-include": [
{
"line_no": 19,
"line": " include 'basicsp.inc'",
"column": 6,
"span": 7
}
],
"intrinsics-should-be-uppercased": [
{
"line_no": 21,
"line": " common /cisplit/ isplit(nelm)",
"column": 6,
"span": 6
}
]
}
}
The option to create a database is recent and was driven by the slowness associated with the parsing of very large codebases (if you have a small codebase, the chances this command is relevant for you are small).
flint lint
It simplifies the reading of regexp errors by printing them as tables in the terminal:
>> flint lint Nek5000/tools/prenek/glomod.f
not-recommended-use-include
+---------+--------+------+-----------------------------+
| line_no | column | span | line |
+---------+--------+------+-----------------------------+
| 19 | 6 | 7 | include 'basicsp.inc' |
+---------+--------+------+-----------------------------+
intrinsics-should-be-uppercased
+---------+--------+------+-------------------------------------+
| line_no | column | span | line |
+---------+--------+------+-------------------------------------+
| 21 | 6 | 6 | common /cisplit/ isplit(nelm) |
+---------+--------+------+-------------------------------------+
flint score
It gives the score in the terminal.
An easily parsable one-liner score is achievable with:
>> flint score Nek5000
Flinter global rating -->|-4.09|<-- (297299 statements)
Instead, you can have a more verbose output:
>> flint score Nek5000 --verbose --depth 1
lvl path rate size (stmt)
0 Nek5000 -4.09 297299
1 Nek5000/short_tests 7.45 3054
.........
1 Nek5000/core -7.10 89601
.........
1 Nek5000/tools -4.53 168593
.........
1 Nek5000/3rd_party 4.45 36051
.........
flint stats
It shows quick statistics of a given codebase.
>> flint stats _outputs/nek5000_db.json --database -q 3
Worst rated files:
Nek5000/tools/prenek/mxm.f: -24.23
Nek5000/core/intp_usr.f: -23.81
Nek5000/core/mxm_wrapper.f: -16.35
Worst rated functions:
Nek5000/tools/postnek/big_post.f/get_velocity: -210.00
Nek5000/tools/postnek/big_post.f/get_coords: -210.00
Nek5000/core/intp_usr.f/intp_do: -123.33
Regexp most common errors:
missing-space-after-punctuation: 76746
intrinsics-should-be-uppercased: 53734
excessive-use-of-space: 35951
Struct most common errors:
short-varnames: 11158
too-many-lines: 3293
too-many-arguments: 1517
Additionally, it is possible to dump the errors counts to a json file:
flint stats _outputs/nek5000_db.json --database -q 3 --dump stats.json
The created file follows the structure of the database, but contains counts instead of error detailed information. You can make some funny data analysis on your code with it!
[
{
"type": "file",
"path": "Nek5000/tools/prenek/glomod.f",
"size": 4719,
"struct_nberr": 7,
"regexp_nberr": 2,
"struct_rules": {
"too-many-lines": 7
},
"regexp_rules": {
"not-recommended-use-include": 1,
"intrinsics-should-be-uppercased": 1
},
"children": [],
"rate": 9.921593557957195
}
]
flint struct
It allows to quickly understand the structure of a codebase by printing it in a tree-like way:
>> flint struct Nek5000
Nek5000
├ type: folder
├ path: Nek5000
├ size: 297299
├ Nek5000/short_tests
│ ├ type: folder
│ ├ path: Nek5000/short_tests
│ ├ size: 3054
│ ├ Nek5000/short_tests/NekTests.py
│ │ ├ type: file
│ │ ├ path: Nek5000/short_tests/NekTests.py
│ │ ├ size: 2119
│ │ ├ start_line: 0
│ │ ├ end_line: 2119
(...)
flint tree
With
flint tree Nek5000
you should get a fancy circular packing view of your codebase, colored by your compliance with the coding style. The process can take some time for large codebases (in this case it is advised to create a database first).
The real heavy computation is the positioning of circles (and I could not optimize this, since this is taken from an external package, sorry). Time rise if your sources are a large heap of highly nested little files.
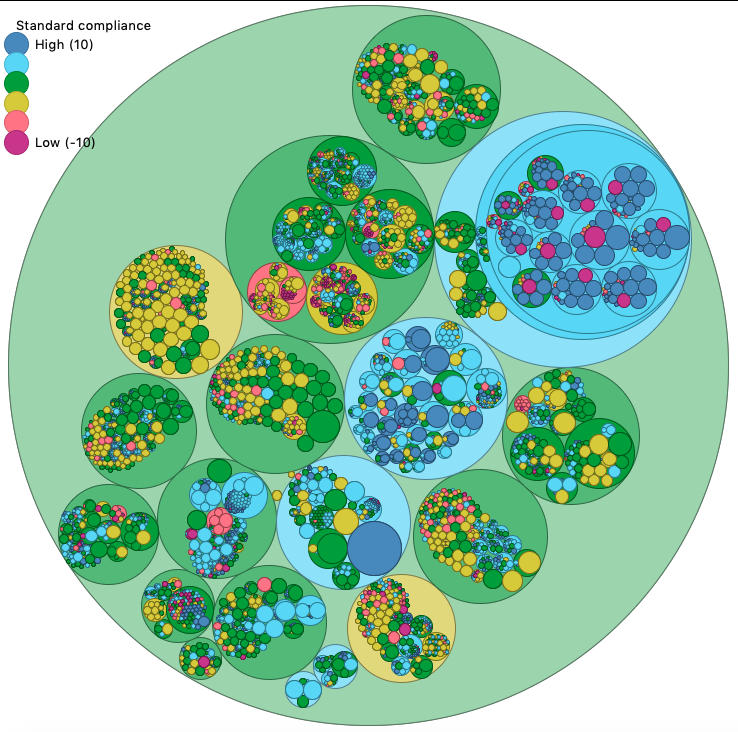
In this circular packing, the relative size of circles is proportional to the number of statements stored inside.
Known bugs
Like any code, flint is a work in progress that still contains occasional bugs. We were able to identify the following (which will be corrected as soon as we can... it may also be your opportunity to contribute):
Python
- size of functions incorrect in some cases
- difficulties handling classes during the parsing
Fortran
- "trailing-whitespaces": "END SUBROUTINE" (wrongly) triggers it
- "one-space-after-comment" line numbers start at 0, whereas in the other cases at 1
Acknowledgement
Flint is a service created in the EXCELLERAT Center Of Excellence, funded by the European community.

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file flinter-0.7.1.tar.gz.
File metadata
- Download URL: flinter-0.7.1.tar.gz
- Upload date:
- Size: 48.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.25.1 setuptools/56.2.0 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.9.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e004bbe8e017064eb059efaea36d7d959b38f7ef2b1233bd199d3cbb54ae8326
|
|
| MD5 |
cf239e340b83e48f87d53581cc9353db
|
|
| BLAKE2b-256 |
73d49abbf62915bab832e08f31d6071ec8a50f62580c02bd992a42a294f64a44
|
File details
Details for the file flinter-0.7.1-py3-none-any.whl.
File metadata
- Download URL: flinter-0.7.1-py3-none-any.whl
- Upload date:
- Size: 29.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.25.1 setuptools/56.2.0 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.9.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4c1db4a94f0fa811eb77c450f04c6a2f072e6e06e64d8ee5b0c3154f25131e67
|
|
| MD5 |
b24f98ff8d4aa462b845d341339f5c58
|
|
| BLAKE2b-256 |
9f672d90f6f7f49f78df0234c600c701b350e8caa29a4222c7398d290c0f0938
|







