Generative AI for IPython (enhance your code cells)


Project description
Install | License | Code of Conduct | Contributing
GenAI: generative AI tooling for IPython
🦾 Get GPT help with code, SQL queries, DataFrames, Exceptions and more in IPython.
🌍 Supports all Jupyter environments, including IPython, JupyterLab, Jupyter Notebook, and Noteable.
TL;DR Get started now
%pip install genai
%load_ext genai
Genai In Action
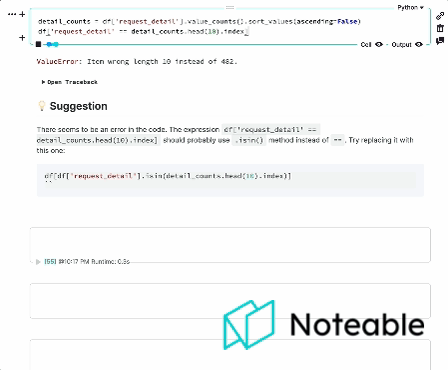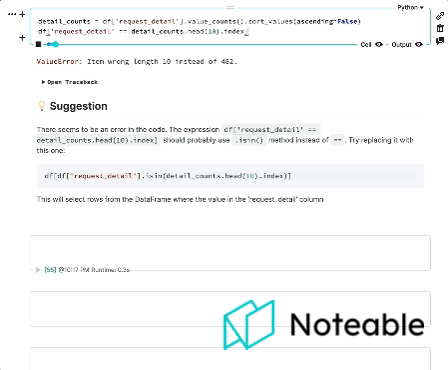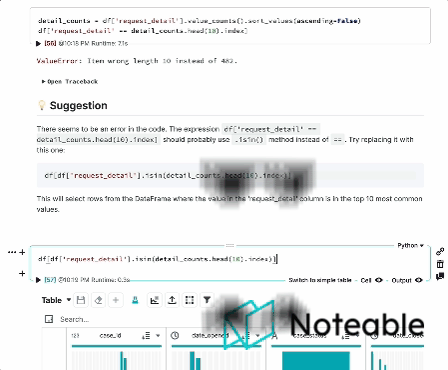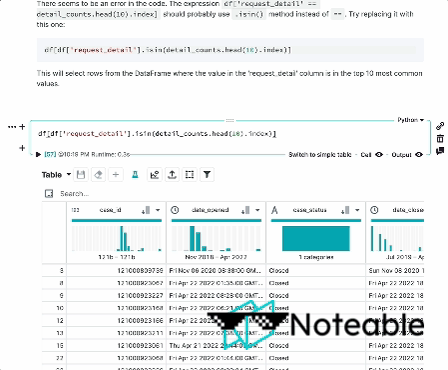
Introduction
We've taken the context from IPython, mixed it with OpenAI's Large Language Models, and are bringing you a more informed notebook experience that works in all Jupyter environments, including IPython, JupyterLab, Jupyter Notebook, and Noteable. 🦾🌏
Requirements
Python 3.8+
Installation
Poetry
poetry add genai
Pip
pip install genai
Loading the IPython extension
Make sure to set the OPENAI_API_KEY environment variable first before using it in IPython or your preferred notebook platform of choice.
%load_ext genai
Features
%%assistmagic command to generate code from natural language- Custom exception suggestions
Custom Exception Suggestions
In [1]: %load_ext genai
In [2]: import pandas as pd
In [3]: df = pd.DataFrame(dict(col1=['a', 'b', 'c']), index=['first', 'second', 'third'])
In [4]: df.sort_values()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[4], line 1
----> 1 df.sort_values()
File ~/.pyenv/versions/3.9.9/lib/python3.9/site-packages/pandas/util/_decorators.py:331, in deprecate_nonkeyword_arguments.<locals>.decorate.<locals>.wrapper(*args, **kwargs)
325 if len(args) > num_allow_args:
326 warnings.warn(
327 msg.format(arguments=_format_argument_list(allow_args)),
328 FutureWarning,
329 stacklevel=find_stack_level(),
330 )
--> 331 return func(*args, **kwargs)
TypeError: sort_values() missing 1 required positional argument: 'by'
💡 Suggestion
The error message is indicating that the sort_values() method of a pandas dataframe is missing a required positional argument.
The sort_values() method requires you to pass a column name or list of column names as the by argument. This is used to determine how the sorting will be performed.
Here's an example:
import pandas as pd
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Carol', 'David', 'Eva'],
'Age': [32, 24, 28, 35, 29],
'Salary': [60000, 40000, 35000, 80000, 45000]
})
# sort by Age column:
df_sorted = df.sort_values(by='Age')
print(df_sorted)
In this example, the by argument is set to 'Age', which sorts the dataframe by age in ascending order. Note that you can also pass a list of column names if you want to sort by multiple columns.
Example
In [1]: %load_ext genai
In [2]: %%assist
...:
...: Can you explain this query to me so I can be sure we're doing the right things?
...:
...: ```sql
...: SELECT
...: COUNT(*) AS num_downloads,
...: DATE_TRUNC(DATE(timestamp), DAY) AS day
...: FROM `bigquery-public-data.pypi.file_downloads`
...: WHERE
...: file.project = 'genai'
...: -- Only query the last 6 months of history
...: AND DATE(timestamp)
...: BETWEEN DATE_TRUNC(DATE_SUB(CURRENT_DATE(), INTERVAL 6 MONTH), MONTH)
...: AND CURRENT_DATE()
...: GROUP BY day
...: ORDER BY day DESC
"This is a SQL query that counts the number of downloads for the 'genai' project on the Python Package Index (PyPI) over the last 6 months, grouped by day. The query selects the count and the date, truncating the date to the day level so that it's easier to read.
Here is a breakdown of each part of the query:
- `SELECT COUNT(*) AS num_downloads, DATE_TRUNC(DATE(timestamp), DAY) AS day`: This selects the count of the number of rows matched by the query as `num_downloads`, and the date truncated to the day level as `day`.
- `FROM `bigquery-public-data.pypi.file_downloads``: This specifies the table to query from.
- `WHERE file.project = 'genai'`: This filters the rows by only including downloads for the 'genai' project.
- `AND DATE(timestamp) BETWEEN DATE_TRUNC(DATE_SUB(CURRENT_DATE(), INTERVAL 6 MONTH), MONTH) AND CURRENT_DATE()`: This filters the rows by only including downloads from the last 6 months. The `DATE_SUB` function subtracts 6 months from the current date (`CURRENT_DATE()`), `DATE_TRUNC` truncates the result to be the start of the month and `DATE` converts the timestamp column to a date so the `BETWEEN` condition can filter rows between the start of 6 months ago and "today."
- `GROUP BY day`: This groups the rows by day so that the counts are aggregated by date.
- `ORDER BY day DESC`: This orders the rows so that the most recent date appears first in the result."
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file genai-2.1.0.tar.gz.
File metadata
- Download URL: genai-2.1.0.tar.gz
- Upload date:
- Size: 16.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.5.1 CPython/3.11.1 Darwin/22.5.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
71abe894703d2a097148fd08152bedd3f320598536317dc0cd9bee69e9f87314
|
|
| MD5 |
6c52365854c7890e86ab42573ef745f3
|
|
| BLAKE2b-256 |
be28ff0de84f38a579b6db12ef003fcc710d4fcc49ad6534fdb7d74d4959d751
|
File details
Details for the file genai-2.1.0-py3-none-any.whl.
File metadata
- Download URL: genai-2.1.0-py3-none-any.whl
- Upload date:
- Size: 16.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.5.1 CPython/3.11.1 Darwin/22.5.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9ae1fc501b0425ad583962b09c1af77b6c04328ba8fbe151954a78f1a180d37e
|
|
| MD5 |
a965b678f111556ad099742f20069482
|
|
| BLAKE2b-256 |
dec72a79b24610e15ecc6d7c421cb7a6701decc0402011099b08659a3a76196a
|







