A highly automated machine learning Python framework for data-driven geochemistry discovery


Project description






Documentation: https://geochemistrypi.readthedocs.io
Source Code: https://github.com/ZJUEarthData/geochemistrypi
Geochemistry π is an open-sourced highly automated machine learning Python framework dedicating to build up MLOps level 1 software product for data-driven geochemistry discovery on tabular data.
Core capabilities are:
- Continous Training
- Machine Learning Lifecycle Management
- Model Inference
Key features are:
- Easy to use: The automation of data mining process provides the users with simple number options to choose.
- Extensible: It allows appending new algorithms through Scikit-learn with automatic hyper parameter searching by FLAML and Ray.
- Traceable: It integrates MLflow to build special storage mechanism to streamline the end-to-end machine learning lifecycle.
Latest Update: follow up by clicking Starred and Watch on our GitHub repository, then get email notifications of the newest features automatically.
The following figure is the simplified overview of Geochemistry π:
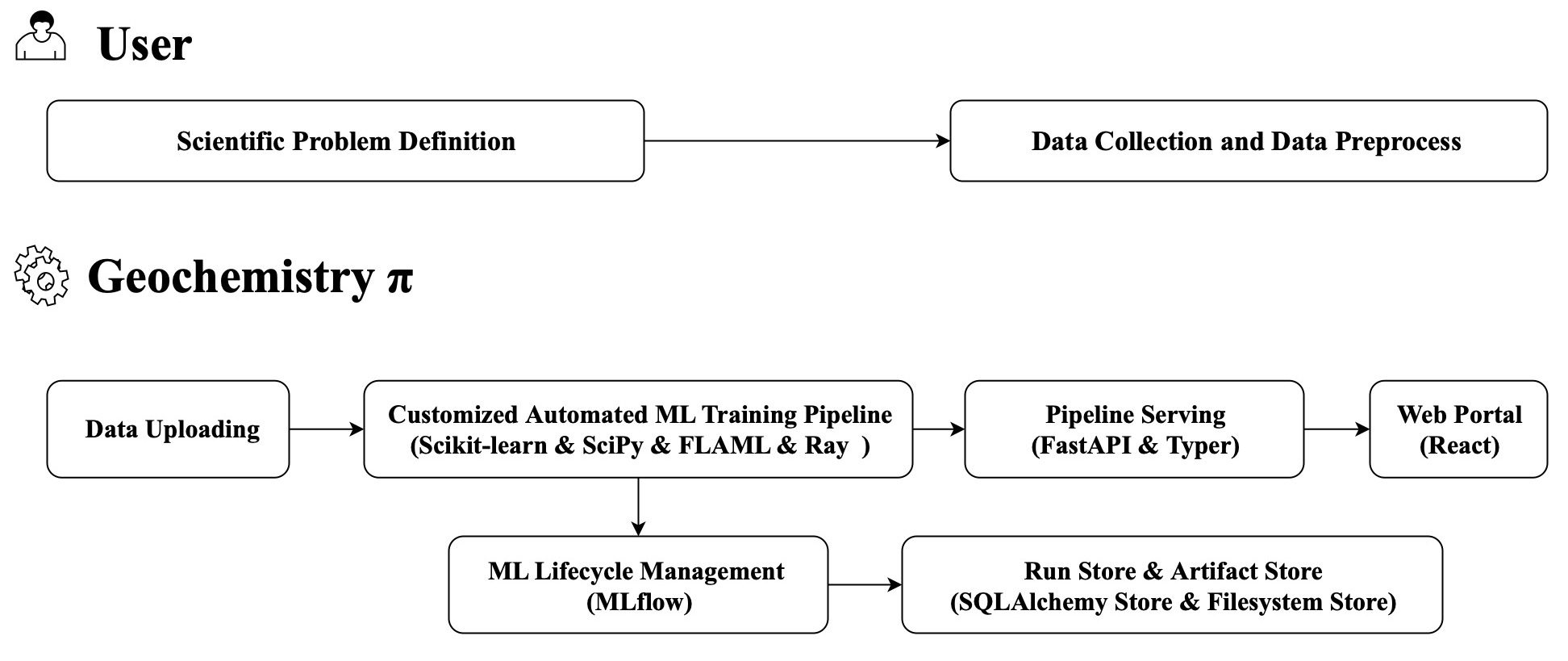
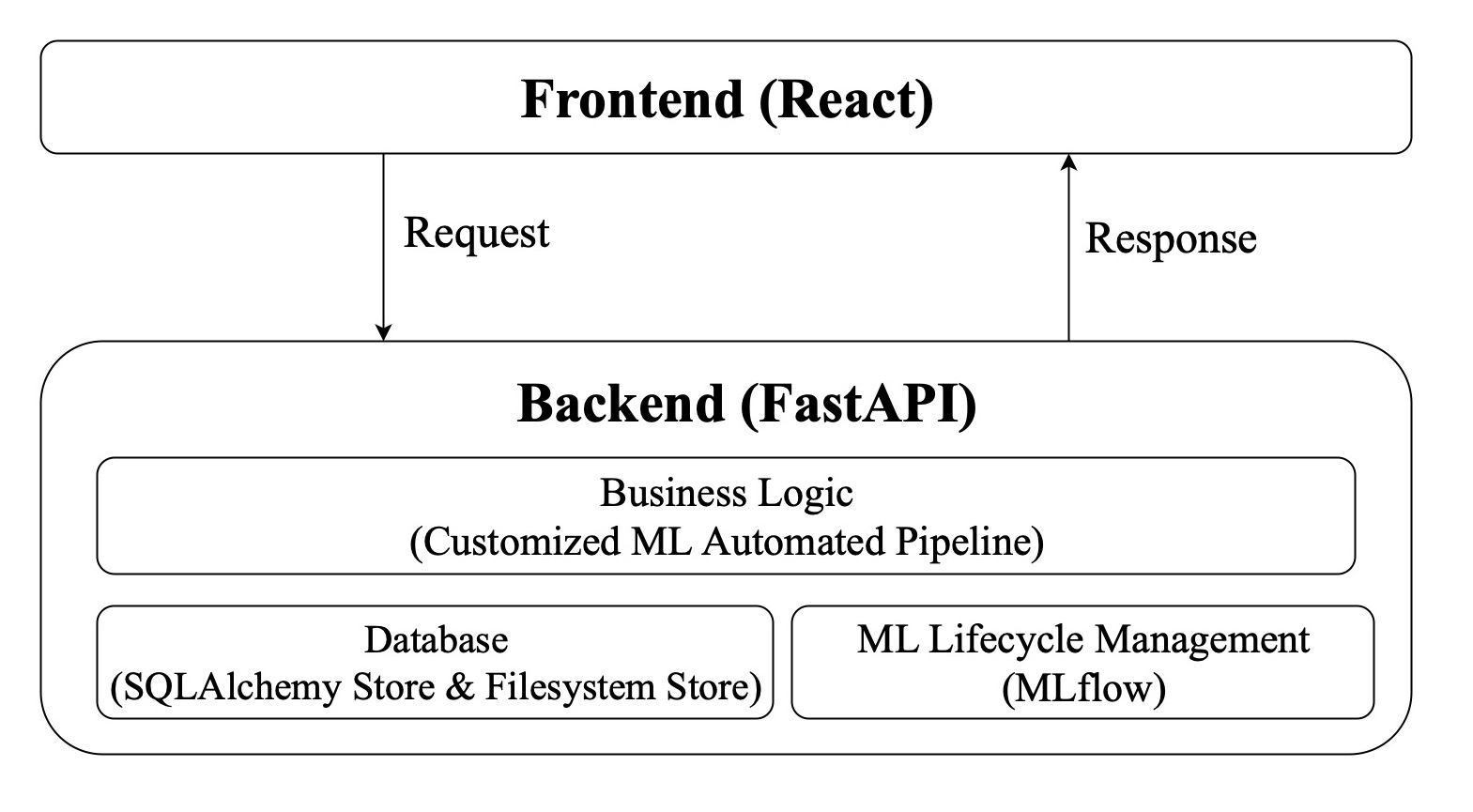
The following figure is the frontend-backend separation architecture of Geochemistry:
Quick Installation
One instruction to download on command line, such as Terminal on macOS, Power Shell on Windows.
pip install geochemistrypi
One instruction to download on Jupyter Notebook or Google Colab.
!pip install geochemistrypi
Check the latest version of our software:
geochemistrypi --version
Note: For more detail on installation, please refer to our online documentation in Installation Manual under the section of FOR USER. Over there, we highly recommend to use virtual environment (Conda) to avoid dependency version problems.
Quick Update
One instruction to update the software to the latest version on command line, such as Terminal on macOS, Power Shell on Windows.
pip install --upgrade geochemistrypi
One instruction to download on Jupyter Notebook or Google Colab.
!pip install --upgrade geochemistrypi
Check the latest version of our software:
geochemistrypi --version
Example
How to run: After successfully downloading, run this instruction on command line / Jupyter Notebook / Google Colab whatever directory it is.
Case 1: Run with built-in data set for testing
On command line:
geochemistrypi data-mining
On Jupyter Notebook / Google Colab:
!geochemistrypi data-mining
Note: There are four built-in data sets corresponding to four kinds of model pattern.
Case 2: Run with your own data set without model inference
On command line:
geochemistrypi data-mining --data your_own_data_set.xlsx
On Jupyter Notebook / Google Colab:
!geochemistrypi data-mining --data your_own_data_set.xlsx
Note: Currently, .xlsx and .csv files are supported. Please specify the path your data file exists. For Google Colab, don't forget to upload your dataset first.
Case 3: Implement model inference on application data
On command line:
geochemistrypi data-mining --training your_own_training_data.xlsx --application your_own_application_data.xlsx
On Jupyter Notebook / Google Colab:
!geochemistrypi data-mining --training your_own_training_data.xlsx --application your_own_application_data.xlsx
Note: Please make sure the column names (data schema) in both training data file and application data file are the same. Because the operations you perform via our software on the training data will be record automatically and subsequently applied to the application data in the same order.
The training data in our pipeline will be divided into the train set and test set used for training the ML model and evaluating the model's performance. The score includes two types. The first type is the scores from the prediction on the test set while the second type is cv scores from the cross validation on the train set.
Case 4: Activate MLflow web interface
On command line:
geochemistrypi data-mining --mlflow
On Jupyter Notebook / Google Colab:
!geochemistrypi data-mining --mlflow
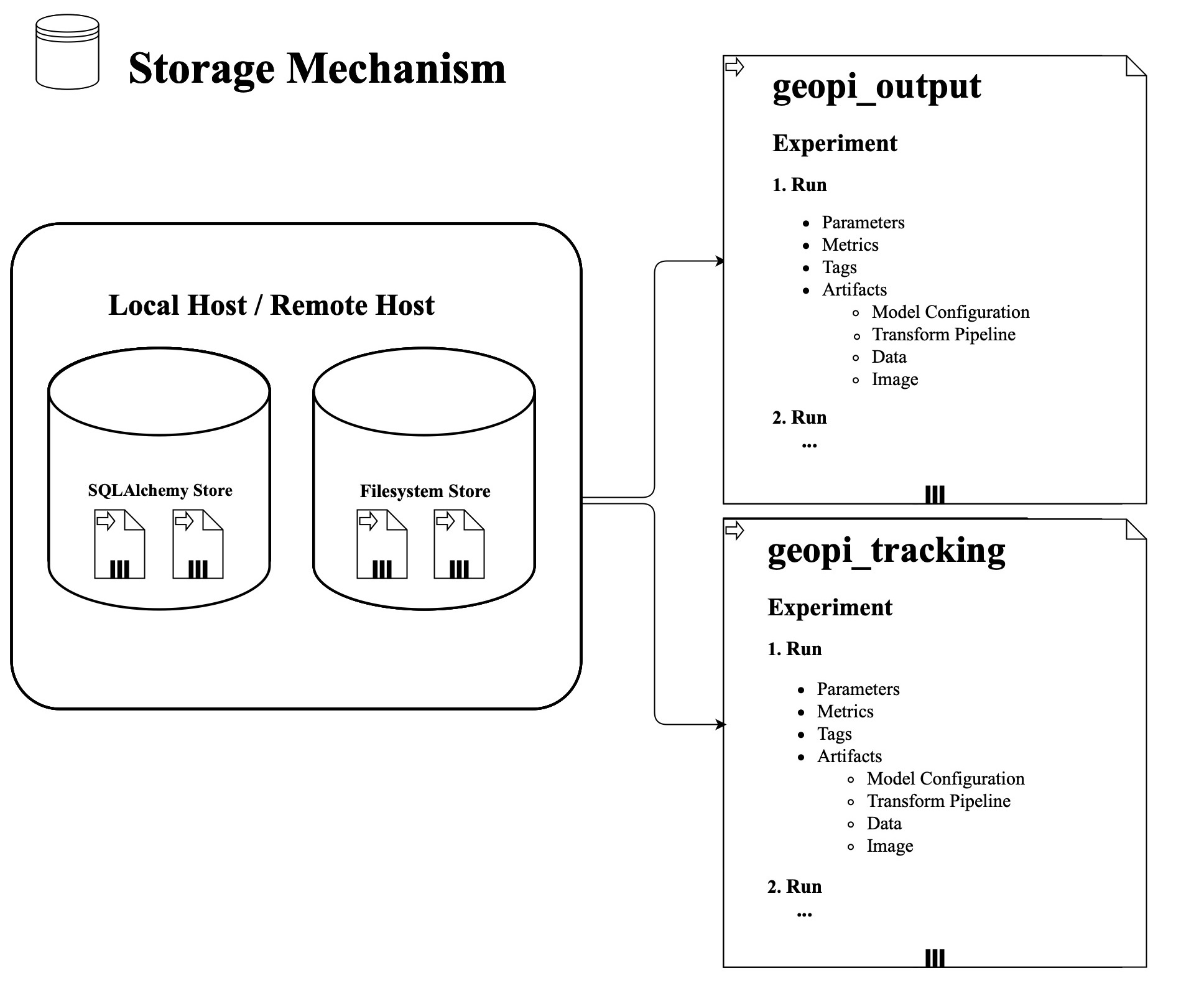
Note: Once you run our software, there are two folders (geopi_output and geopi_tracking) generated automatically. Make sure the directory where you execute using the above command should have the genereted file geopi_tracking.
Copy the URL shown on the console into any browser to open the MLflow web interface. The URL is normally like this http://127.0.0.1:5000. Search MLflow online to see more operations and usages.
For more details: Please refer to:
- Manual v1.1.0 for Geochemistry π - Beta (International - Google drive)
- Manual v1.1.0 for Geochemistry π - Beta (China - Tencent Docs)
- Geochemistry π - Download and Run the Beta Version (International - Youtube)
- Geochemistry π - Download and Run the Beta Version (China - Bilibili)
Roadmap
First Phase
It works as a software application with a command-line interface (CLI) to automate data mining process with frequently-used machine learning algorithms and statistical analysis methods, which would further lower the threshold for the geochemists.
The highlight is that through choosing simple number options, the users are able to implement a full cycle of data mining without knowledge of SciPy, NumPy, Pandas, Scikit-learn, FLAML, Ray packages.
The following figure is the activity diagram of automated ML pipeline in Geochemistry π:
Its data section provides feature engineering based on arithmatic operation. It allows the users to have a statistic analysis on the data set as well as on the imputation result, which is supported by the combination of Monte Carlo simulation and hypothesis testing.
Its models section provides both supervised learning and unsupervised learning methods from Scikit-learn framework, including four types of algorithms, regression, classification, clustering, and dimensional reduction. Integrated with FLAML and Ray framework, it allows the users to run AutoML easily, fastly and cost-effectively on the built-in supervised learning algorithms in our framework.
The following figure is the hierarchical architecture of Geochemistry π:

Second Phase
Currently, we are building three access ways to provide more user-friendly service, including web portal, CLI package and API. It allows the user to perform continuous training and model inference by automating the ML pipeline and machine learning lifecycle management by unique storage mechanism in different access layers.
The following figure is the system architecture diagram:
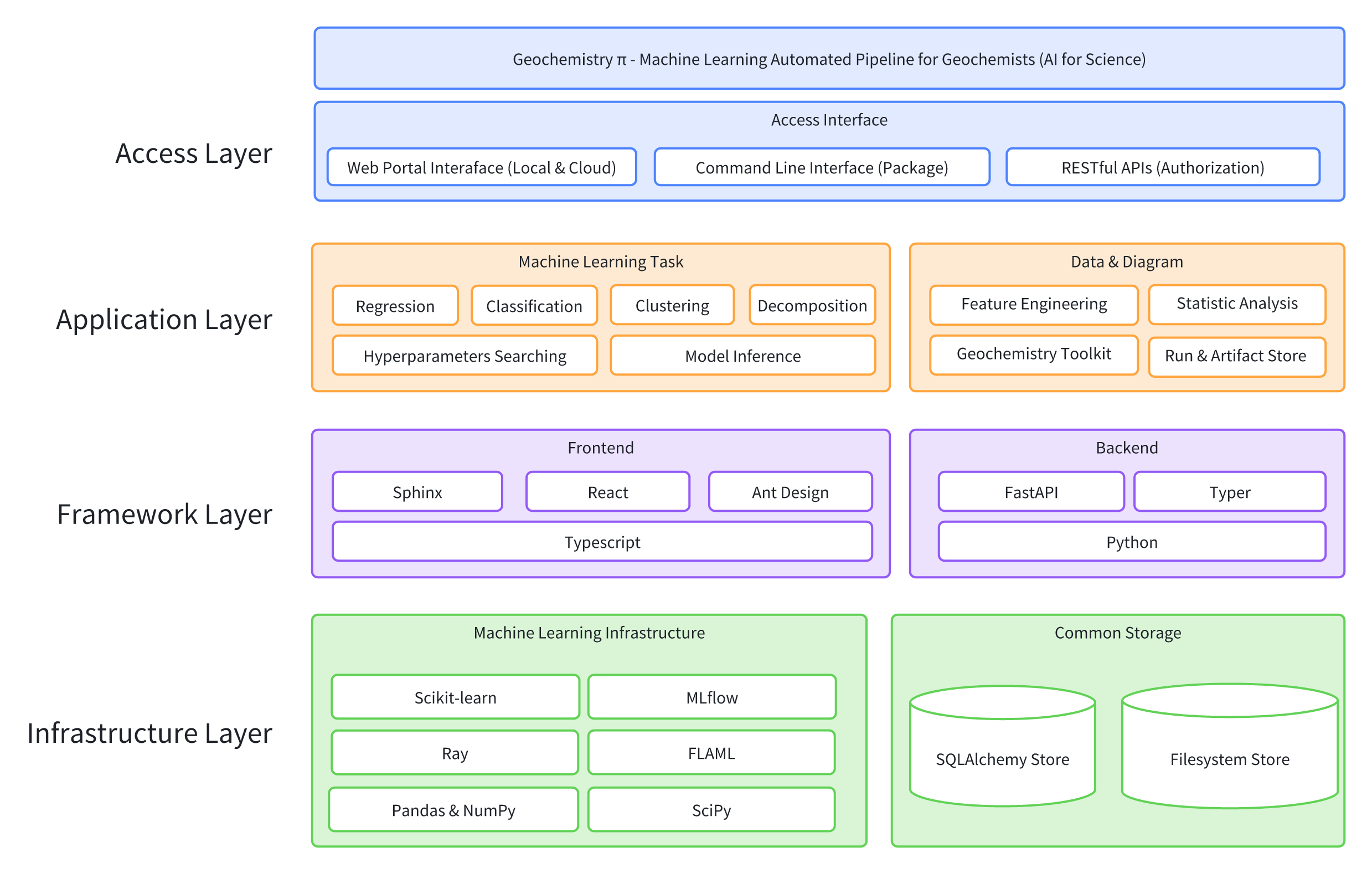
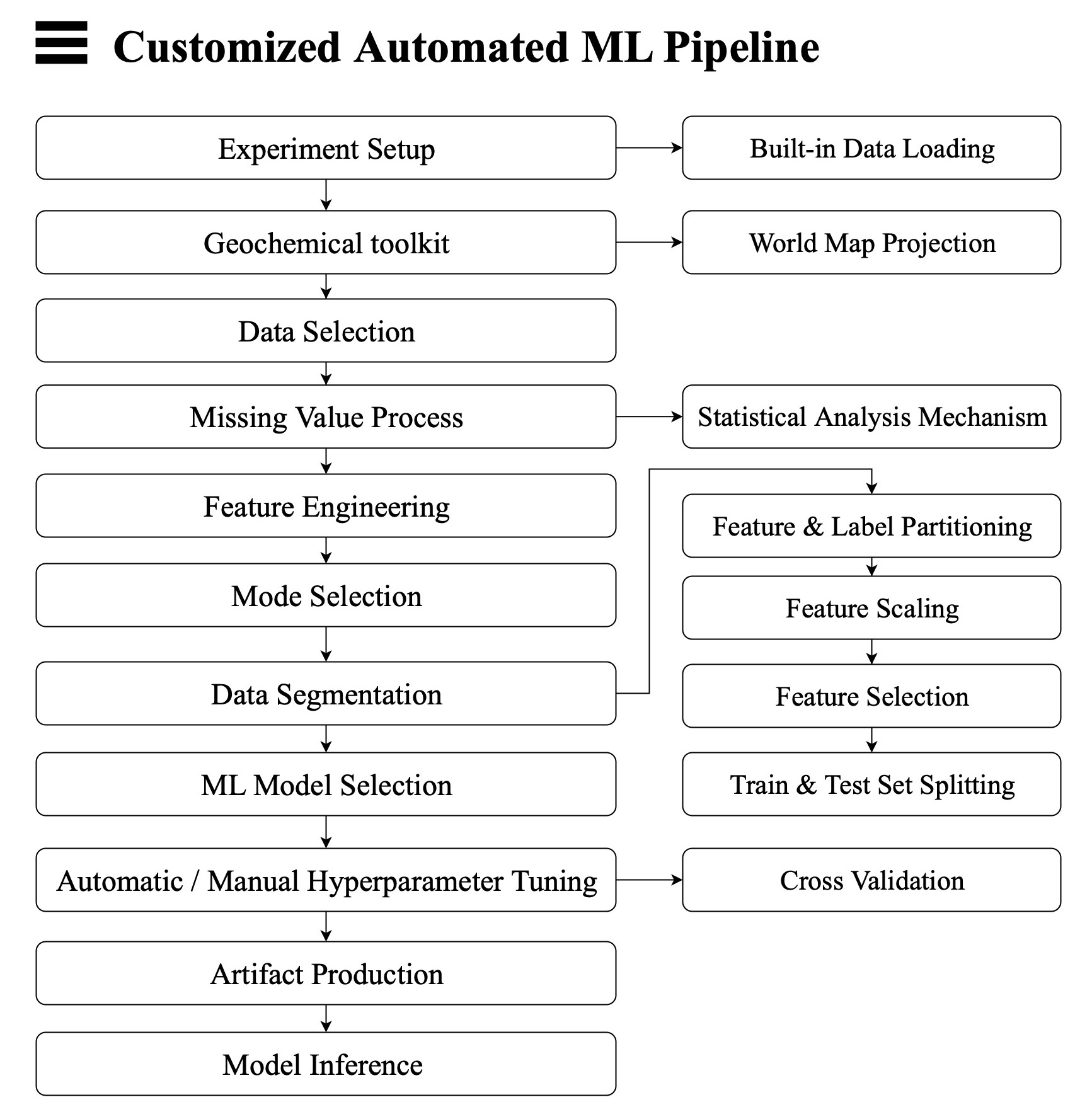
The following figure is the customized automated ML pipeline:
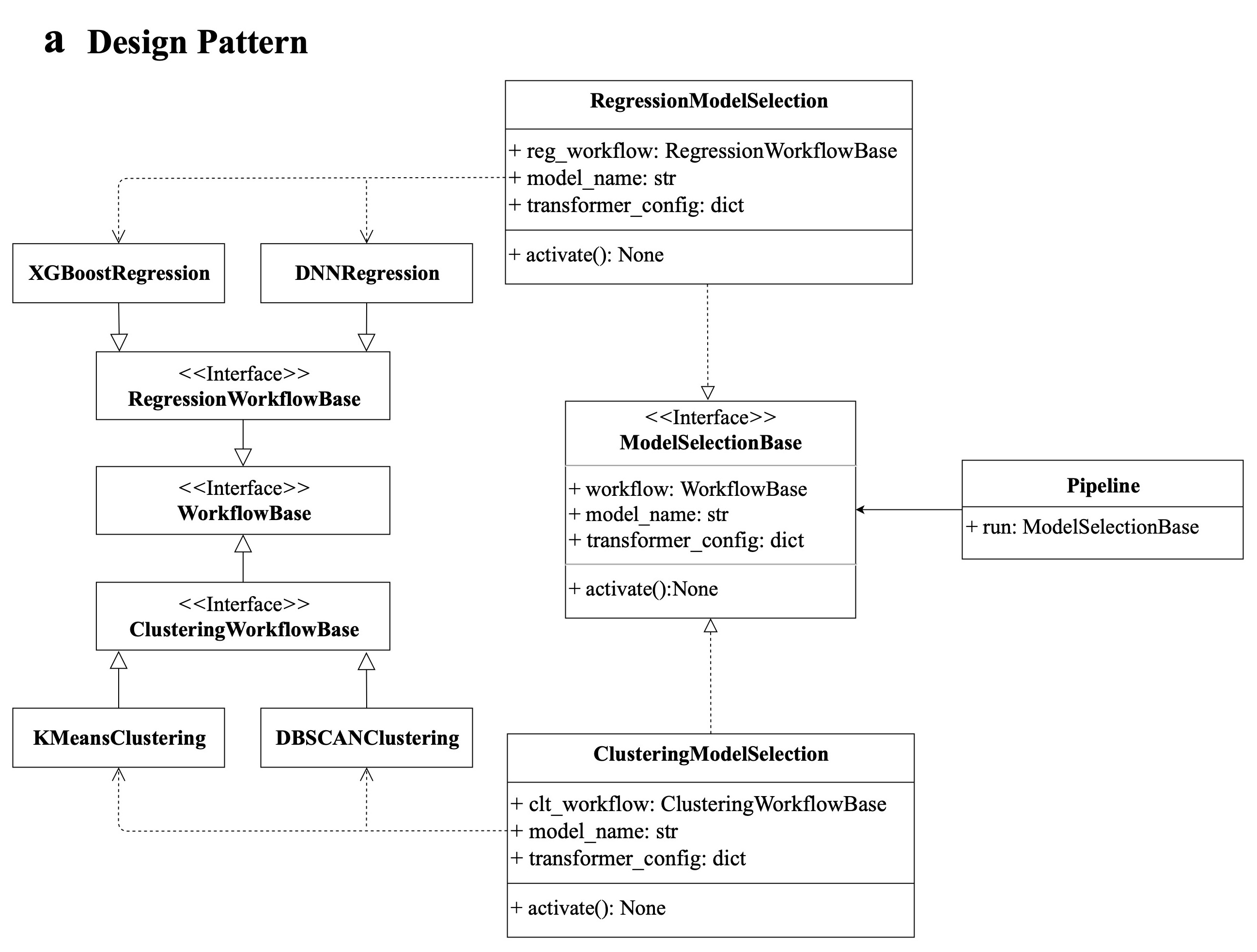
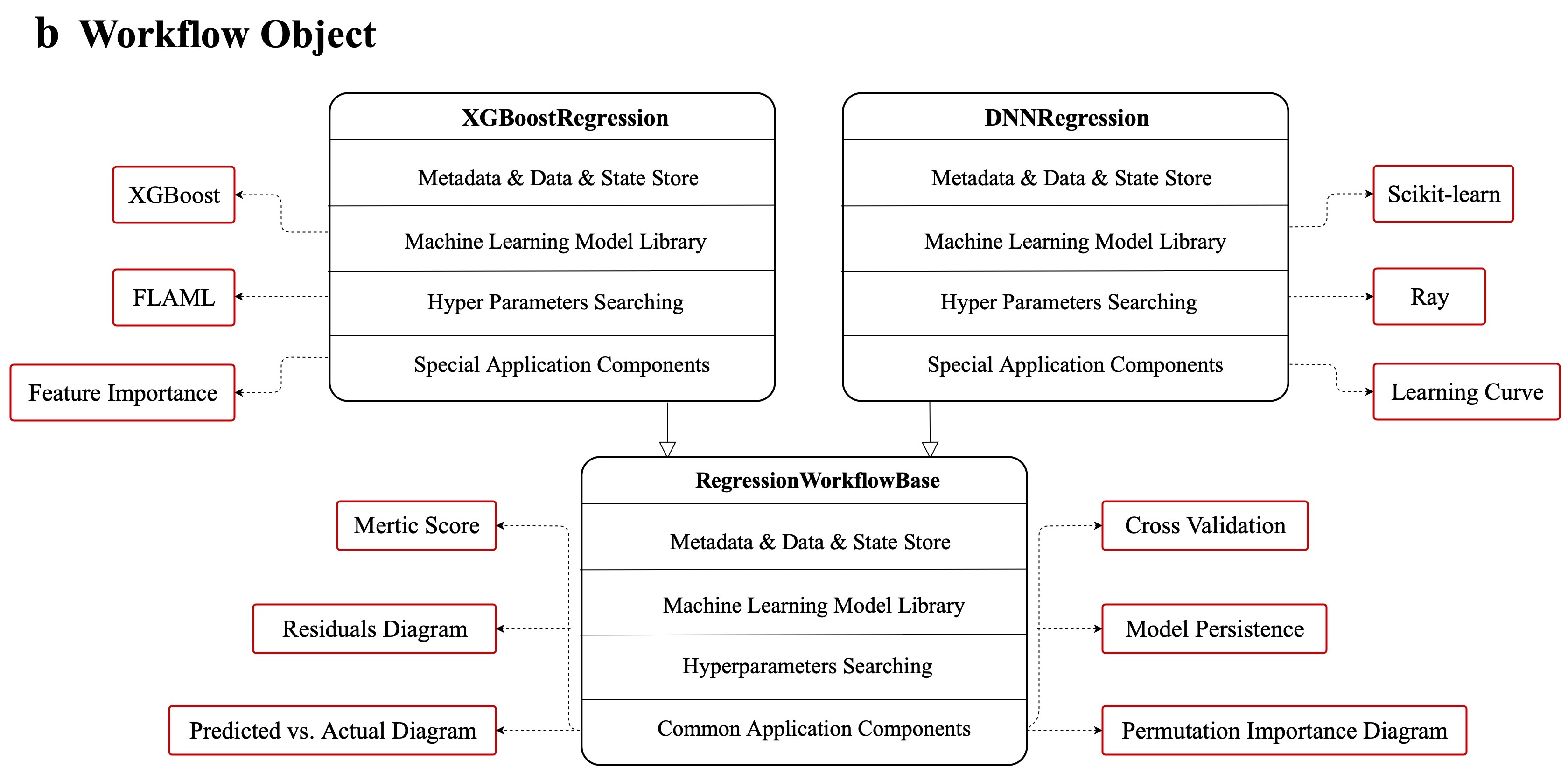
The following figure is the design pattern hierarchical architecture:
The following figure is the storage mechanism:
The whole package is under construction and the documentation is progressively evolving.
Team Info
Leader:
- Can He (Sany, National University of Singapore, Singapore) Email: sanyhew1097618435@163.com
Technical Group:
- Jianming Zhao (Jamie, Zhejiang University, China)
- Jianhao Sun (Jin, China University of Geosciences, Wuhan, China)
- Kaixin Zheng (Hayne, Sun Yat-sen University, China)
- Jianing Wang (National University of Singapore, Singapore)
- Yongkang Chan (Kill-virus, Lanzhou University, China)
- Mengying Ye (Mary, Jilin University, China)
- Mengqi Gao (China University of Geosciences, Beijing, China)
- Chengtu Li(Trenki, Henan Polytechnic University, Beijing, China)
Product Group:
- Yang Lyu (Daisy, Zhejiang University, China)
- Wenyu Zhao (Molly, Zhejiang University, China)
- Keran Li (Kirk, Chengdu University of Technology, China)
- Aixiwake·Janganuer (Ayshuak, Sun Yat-sen University, China)
- Bailun Jiang (EPSI / Lille University, France)
- Yucheng Yan (Andy, University of Sydney, Australia)
- Ruitao Chang (China University of Geosciences Beijing, China)
- Zhenglin Xu (Garry, Jilin University, China)
- Junchi Liao(Roceda, University of Electronic Science and Technology of China, China)
Join Us :)
The recruitment of research interns is ongoing !!!
Key Point: All things are done online, remote work (*^▽^*)
What can you learn?
- Learning the full cycle of data mining (Scikit-learn, Ray, Mlflow) on tabular data, including the algorithms in regression,classification, clustering, and decomposition.
- Learning to be a qualified Python developer, including any Python programing contents towards data mining, basic software engineering techniques like frontend (React, Typescript, Ant Design scaffold) and backend (SQL & NoSQL database, RESFful API, FastAPI) development, and cooperation tools like Git.
What can you get?
- Research internship proof and reference letter after working for >> 100 hours.
- Chance to pay a visit to Hangzhou, China, sponsored by ZJU Earth Data.
- Chance to be guided by the experts from IT companies in Silicon Valley and Hangzhou.
- Bonus depending on your performance.
Current Working Pattern:
- Online working and cooperation
- Three weeks per working cycle -> One online meeting per working cycle
- One cycle report (see below) per cycle - 5 mins to finish
Even if you are not familiar with topics above, but if you are interested in and have plenty of time to do it. That's enough. We have a full-developed training system to help you, as a newbie of data mining or Python developer, learn steps by steps with seniors until you can make a significant contribution to our project.
More details about the project? Please refer to: English Page: https://person.zju.edu.cn/en/zhangzhou Chinese Page: https://person.zju.edu.cn/zhangzhou#0
Do you want to contribute to this open-source program? Contact with your CV: sanyhew1097618435@163.com
In-house Materials
Materials are in both Chinese and English. Others unshown below are internal materials.
- Guideline Manual – Geochemistry π (International - Google drive)
- Guideline Manual – Geochemistry π (China - Tencent Docs)
- Learning Steps for Newbies – Geochemistry π (International - Google drive)
- Learning Steps for Newbies - Geochemistry π (China - Tencent Docs)
- Code Specification v2.1.2 - Geochemistry π (International - Google drive)
- Code Specification v2.1.2 - Geochemistry π (China - Tencent Docs)
- Cycle Report - Geochemistry π (International - Google drive)
- Cycle Report - Geochemistry π (China - Tencent Docs)
In-house Videos
Technical record videos are on Bilibili and Youtube synchronously while other meeting videos are internal materials. More Videos will be recorded soon.
- ZJU_Earth_Data Introduction (Geochemical Data, Python, Geochemistry π) - Prof. Zhang
- How to Collaborate and Provide Bug Report on Geochemistry π Through GitHub - Can He (Sany)
- Geochemistry π - Download and Run the Beta Version
- How to Create and Use Virtual Environment on Geochemistry π - Can He (Sany)
- How to use Github-Desktop in conflict resolution - Qiuhao Zhao (Brad)
- Virtual Environment & Packages On Windows - Jianming Zhao (Jamie)
- Git Workflow & Coordinating Synchronization - Jianming Zhao (Jamie)
Contributors
- Shengxin Wang (Samson, Lanzhou University, China)
- Qiuhao Zhao (Brad, Zhejiang University, China)
- Anzhou Li (Andrian, Zhejiang University, China)
- Dan Hu (Notre Dame University, United States)
- Xunxin Liu (Tante, China University of Geosciences, Wuhan, China)
- Fang Li (liv, Shenzhen University, China)
- Xin Li (The University of Manchester, United Kingdom)
- Ting Liu (Kira, Sun Yat-sen University, China)
- Xirui Zhu (Rae, University of York, United Kingdom)


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for geochemistrypi-0.5.0-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 146fadc4d77d0826ecc24fb0332877cef4629d25b28f33dca652a95cd708cd83 |
|
| MD5 | a1f0a6814244966fc1816c5df003b04b |
|
| BLAKE2b-256 | f8443aaa990acb2b6ed43c25eff667c85c040df266987ddf4fa6ff6c7d6220f3 |







