Geoclustering using H3 hexagons

Project description
Geoscan


DBSCAN (density-based spatial clustering of applications with noise) is a clustering technique used to group points that
are closely packed together. Compared to other clustering methodologies, it doesn't require you to indicate the number
of clusters beforehand, can detect clusters of varying shapes and sizes and is strong at finding outliers that don't
belong to any cluster, hence a great candidate for geospatial analysis of card transactions and fraud detection.
This, however, comes with a serious price tag: DBSCAN requires all points to be compared
to every other points in order to find dense neighborhoods where at least minPts points can be found within a
epsilon radius.
Here comes GEOSCAN, our novel approach to DBSCAN algorithm for geospatial clustering, leveraging uber H3 library to only group points we know are in close vicinity (according to H3 precision) and relying on GraphX to detect dense areas at massive scale. With such a framework, Financial services institutions can better understand user shopping behaviours and detect anomalous transactions in real time.
Usage
There are 2 modes our framework can be executed, distributed and pseudo-distributed.
Distributed
Working fully distributed, we retrieve clusters from an entire dataframe using the Spark Estimator interface,
hence fully compliant with the Spark Pipeline framework (model can be serialized / deserialized).
In this mode, the core of GEOSCAN algorithm relies on GraphX to detect points having distance < epsilon and a degree > minPoints.
See the next section for an explanation of our algorithm.
Usage
from geoscan import Geoscan
geoscan = Geoscan() \
.setLatitudeCol("latitude") \
.setLongitudeCol("longitude") \
.setPredictionCol("cluster") \
.setEpsilon(100) \
.setMinPts(3)
model = geoscan.fit(points_df)
| parameter | description | default |
|---|---|---|
| epsilon | the minimum distance in meters between 2 points | 50 |
| minPts | the minimum number of neighbours within epsilon | 3 |
| latitudeCol | the latitude column | latitude |
| longitudeCol | the longitude column | longitude |
| predictionCol | the resulted prediction column | predicted |
As the core of GEOSCAN logic relies on the use of H3 polygons, it becomes natural to leverage the same for model
inference instead of bringing in extra GIS dependencies for expensive point in polygons queries. Our model consists
in clusters tiled with hexagons of a given resolution (driven by the epsilon parameter) that can easily be joined to our original dataframe.
Model inference is fully supported as per the Estimator interface
model.transform(points_df)
Note that when saving model to distributed file system, we converted our shapes into GeoJson RFC 7946 format so that clusters could be loaded as-is into GIS databases or any downstream application or libraries.
from geoscan import GeoscanModel
model.save('/tmp/geoscan_model/distributed')
model = GeoscanModel.load('/tmp/geoscan_model/distributed')
Model can always be returned as a GeoJson object directly
model.toGeoJson()
Finally, it may be useful to extract clusters as a series of H3 tiles that could be used outside a spark environment or outside GEOSCAN library.
We expose a getTiles method that fills all our polygons with H3 tiles of a given dimension, allowing shapes to spill over additional layers should
we want to also "capture" neighbours points.
model.getTiles(precision, additional_layers)
This process can be summarized with below picture. Note that although a higher granularity would fit a polygon better, the number of tiles it generates will grow exponentially.
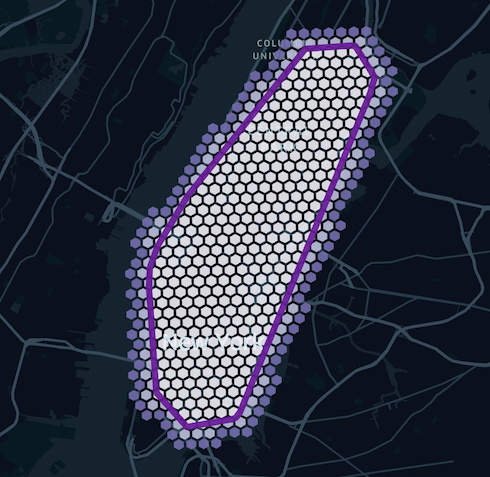
Pseudo Distributed
It is fairly common to extract personalized clusters (e.g. for each user), and doing so sequentially would be terribly inefficient.
For that purpose, we extended our GEOSCAN class to support RelationalGroupedDataset and train multiple models in parallel, one for each group attribute.
Although the implementation is different (using in-memory scalax.collection.Graph instead of distributed GraphX),
the core logic remains the same as explained in the next section and should yield the same clusters given a same user.
Usage
One must provide a new parameter groupedCol to indicate our framework how to group dataframe and train multiple models in parallel.
from geoscan import GeoscanPersonalized
geoscan = Geoscan() \
.setLatitudeCol("latitude") \
.setLongitudeCol("longitude") \
.setPredictionCol("cluster") \
.setGroupedCol("user") \
.setEpsilon(100) \
.setMinPts(3)
model = geoscan.fit(points_df)
Note that the output signature differs from the distributed approach since we cannot return a single model but a collection of GEOJSON objects
model.toGeoJson().show()
+--------------------+--------------------+
| user| cluster|
+--------------------+--------------------+
|72fc865a-0c34-409...|{"type":"FeatureC...|
|cc227e67-c6d1-40a...|{"type":"FeatureC...|
|9cafdb6d-9134-4ee...|{"type":"FeatureC...|
|804c7fa2-8063-4ba...|{"type":"FeatureC...|
|65bd17be-b030-44a...|{"type":"FeatureC...|
+--------------------+--------------------+
Note that standard transform and getTiles methods also apply in that mode. By tracking how tiles change overtime,
this framework can be used to detect user changing behaviour as represented in below animation using synthetic data.
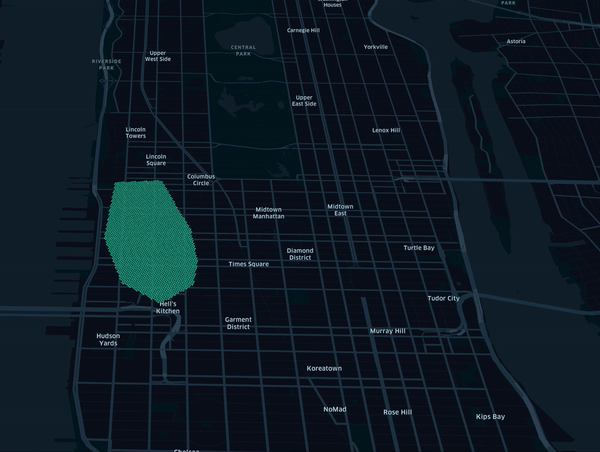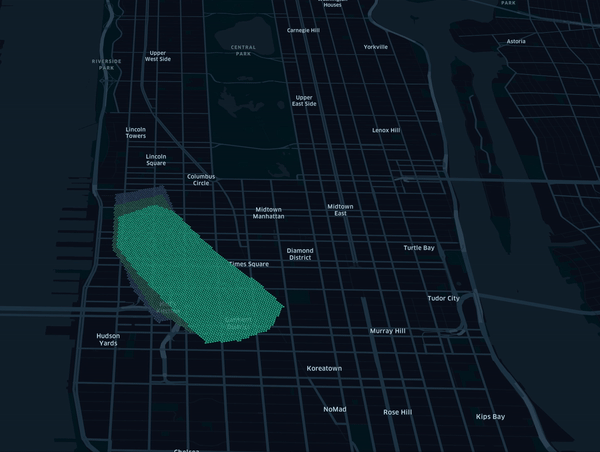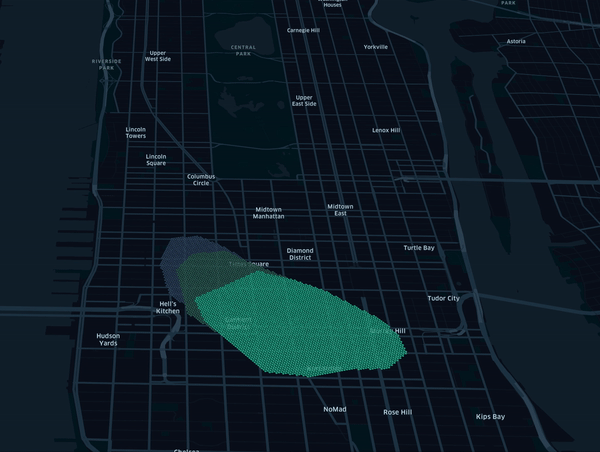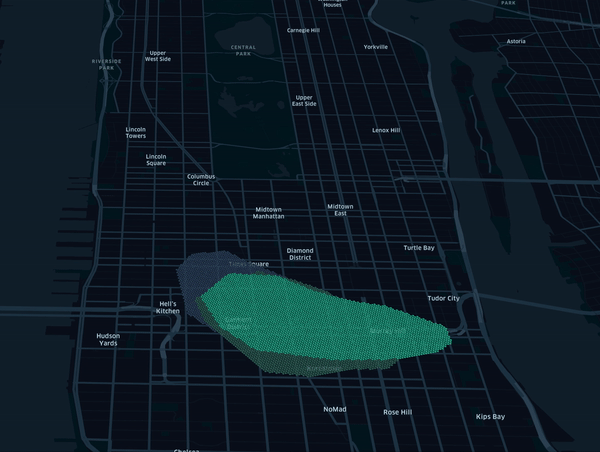
Installation
Compile GEOSCAN scala library that can be uploaded onto a Databricks cluster (DBR > 9.1). Activate shaded profile
to include GEOSCAN dependencies as an assembly jar if needed
mvn clean package -Pshaded
Alternatively (preferred), install dependency from maven central directly in your spark based environment.
<dependency>
<groupId>com.databricks.labs</groupId>
<artifactId>geoscan</artifactId>
<version>0.1</version>
</dependency>
For python users, install the dependencies from pypi in addition to the above scala dependency.
pip install geoscan==0.1
Release process
Once a change is approved, peer reviewed and merged back to master branch, a project admin will be able to promote
a new version to both maven central and pypi repo as a manual github action.
See release.yaml github action.
Project support
Please note that all projects in the /databrickslabs github account are provided for your exploration only, and are not formally supported by Databricks with Service Level Agreements (SLAs). They are provided AS-IS and we do not make any guarantees of any kind. Please do not submit a support ticket relating to any issues arising from the use of these projects.
Any issues discovered through the use of this project should be filed as GitHub Issues on the Repo. They will be reviewed as time permits, but there are no formal SLAs for support.
Author
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file geoscan-0.2.8-py3-none-any.whl.
File metadata
- Download URL: geoscan-0.2.8-py3-none-any.whl
- Upload date:
- Size: 6.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
99c2d835e0c6054bd363bc765f280bc496247d46ba8a50f58f091fd31cfc6c46
|
|
| MD5 |
b806e3b6b2f69abaa7948c9fcf4038d9
|
|
| BLAKE2b-256 |
8cae2be37f3a7bb6451397e591a296c44a578aea08a96618f94f8b08ed9cc179
|







